有导师学习神经网络以其良好的学习能力广泛应用于各个领域中,其不仅可以解决拟合回归问题,亦可以用于模式识别、分类识别。将继续介绍两种典型的有导师学习神经网络(GRNN和PNN),并以实例说明其在分类识别中的应用。
1 理论基础
1.1 广义回归神经网络(GRNN)概述
1.GRNN的结构
GRNN最早是由Specht提出的,是RBF神经网络的一个分支,是一种基于非线性回归理论的前馈式神经网络模型。
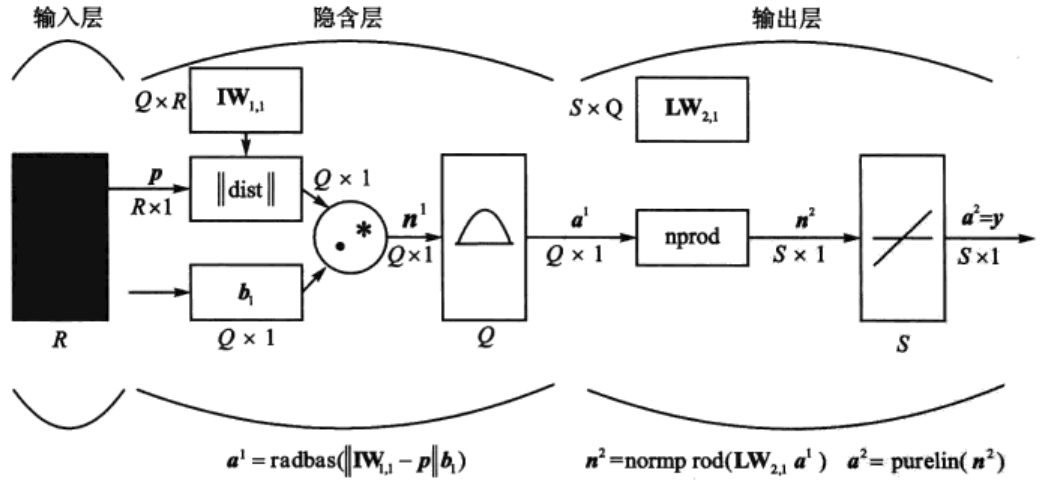 图1
GRNN的结构
图1
GRNN的结构


GRNN的结构如图1所示,一般由输入层、隐含层和输出层组成。输入层仅将样本变量送入隐含层,并不参与真正的运算。隐含层的神经元个数等于训练集样本数,该层的权值函数为欧式距离函数(用||dist||表示),其作用为计算网络输入与第一层的权值IW1,1之间的距离,b1为隐含层的阈值。隐含层的传递函数为径向基函数,通常采用高斯函数作为网络的传递函数。网络的第三层为线性输出层,其权函数为规范化点积权函数(用nprod表示),计算网络的向量为n²,它的每个元素就是向量a1和权值矩阵LW2,1每行元素的点积再除以向量a1的各元素之和得到的,并将结果n²提供给线性传递函数a2=purelin(n²),计算网络输出。
图1
GRNN的结构
2.GRNN的学习算法
GRNN的学习算法与RBF神经网络的学习算法类似,但在输出层部分区别较大。下面将详细描述GRNN的学习算法及步骤。
(1)确定隐含层神经元径向基函数中心
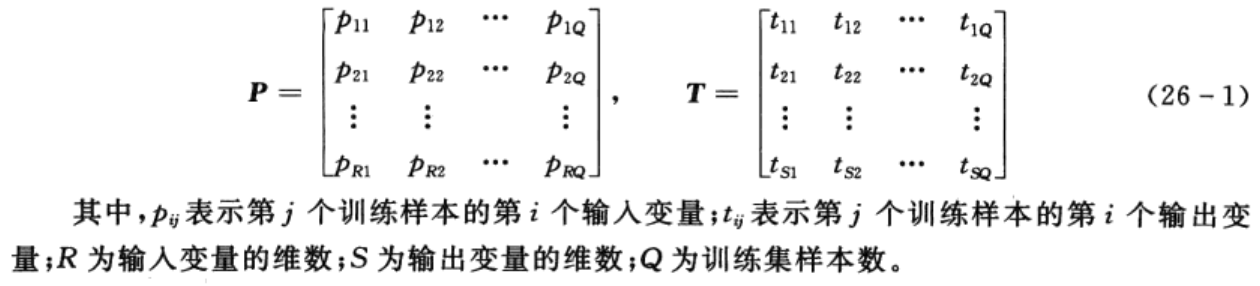
不失一般性,设训练集样本输入矩阵P和输出矩阵T分别为
与RBF神经网络相同,隐含层的每个神经元对应一个训练样本,即Q个隐含层神经元对应的径向基函数中心为
![]()
(2)确定隐含层神经元阈值
为了简便起见,Q个隐含层神经元对应的阈值为
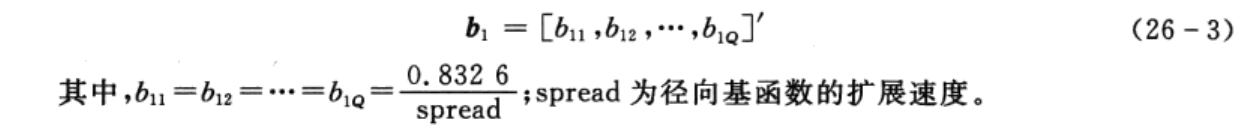
(3)确定隐含层与输出层间权值
当隐含层神经元的径向基函数中心及阈值确定后,隐含层神经元的输出便可以由式(26-4)计算:

与RBF神经网络不同的是,GRNN中隐含层与输出层间的连接权值W取为训练集输出矩阵,即
![]()
(4)输出层神经元输出计算
当隐含层与输出层神经元间的连接权值确定后,根据图26-1所示,便可以计算出输出层神经元的输出,即
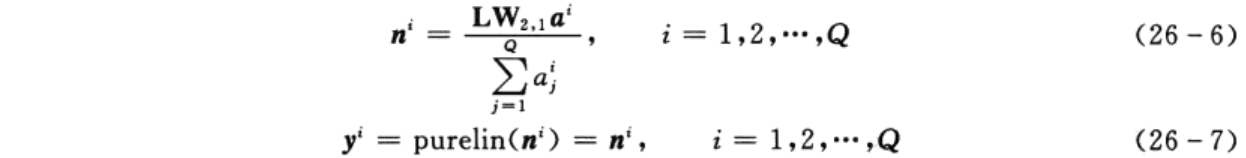
3.GRNN的特点
与BP神经网络相比,GRNN具有如下优点:
(1)网络的训练是单程训练而不需要迭代。
(2)隐含层神经元个数由训练样本自适应确定。
(3)网络各层之间的连接权重由训练样本唯一确定,避免了BP神经网络在迭代中的权值修改。
(4)隐含层节点的激活函数采用对输入信息具有局部激活特性的高斯函数,使得对接近于局部神经元特征的输入具有很强的吸引力。
4.GRNN的MATLAB工具箱函数
函数newgrnn用于创建一个GRNN,其调用格式如下:
net= newgrnn(P,T,spread)
其中,P为网络输入向量;T为网络目标向量;spread为径向基函数的扩展速度(默认为1.0); net为创建好的GRNN。
1.2 概率神经网络(PNN)概述
1.PNN的结构
PNN是一种前馈型神经网络,由Specht在1989年提出,他采用Parzen提出的由高斯函数为基函数来形成联合概率密度分布的估计方法和贝叶斯优化规则,构造了一种概率密度分类估计和并行处理的神经网络。因此,PNN既具有一般神经网络所具有的特点,又具有很好的泛化能力及快速学习能力。
PNN的结构如图2所示,与GRNN类似,由输入层、隐含层及输出层组成。与GRNN不同的是,PNN的输出层采用竞争输出代替线性输出,各神经元只依据Parzen方法来求和估计各类的概率,从而竞争输入模式的响应机会,最后仅有一个神经元竞争获胜,这样获胜神经元即表示对输入模式的分类。
在数学上,PNN的结构合理性可由Cover定理证明,即对于一个模式问题,在高维数据空间中可能解决在低维空间不易解决的问题。这就是PNN隐含层神经元较多的原因,即隐含层空间维数较高。隐含层空间的维数和网络性能有着直接的关系,维数越高,网络的逼近精度就越高,但带来的负面后果是网络复杂度也随之提高。
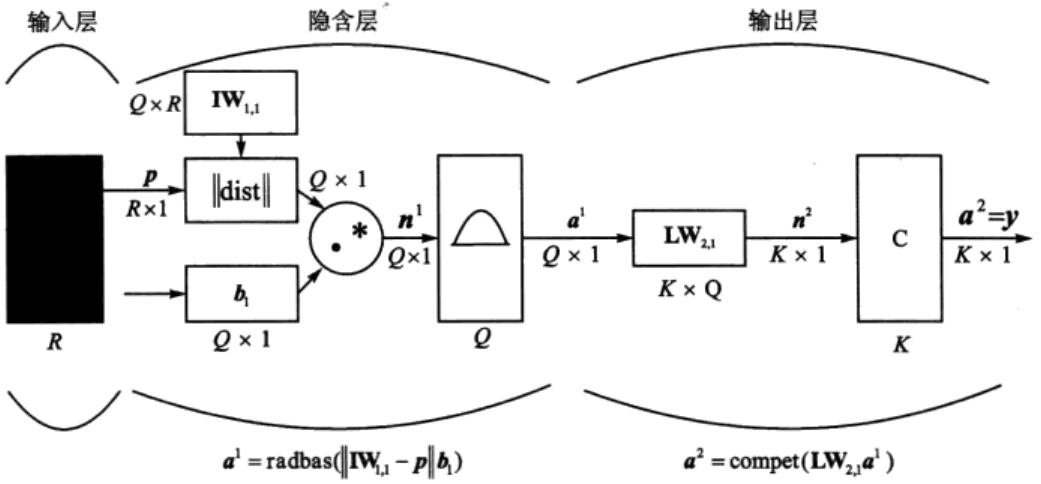
图2 PNN的结构
2.PNN的学习算法
PNN的学习算法与GRNN的学习算法较为接近,仅在输出层部分有细微差别。下面将详细描述PNN的学习算法及步骤。
(1)确定隐含层神经元径向基函数中心
不失一般性,设训练集样本输入矩阵P和输出矩阵T分别为
与GRNN相同,隐含层的每个神经元对应一个训练样本,即Q个隐含层神经元对应的径向基函数中心为
![]()
(2)确定隐含层神经元阈值
为了简便起见,Q个隐含层神经元对应的阈值为
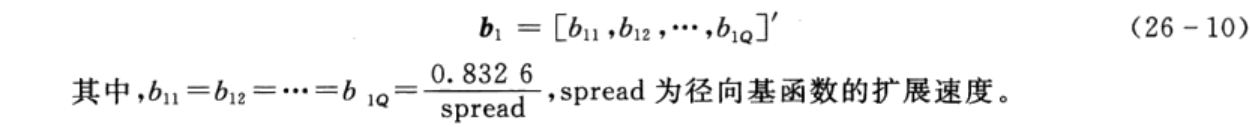
(3)确定隐含层与输出层间权值
当隐含层神经元的径向基函数中心及阈值确定后,隐含层神经元的输出便可以由式(26-11)计算:
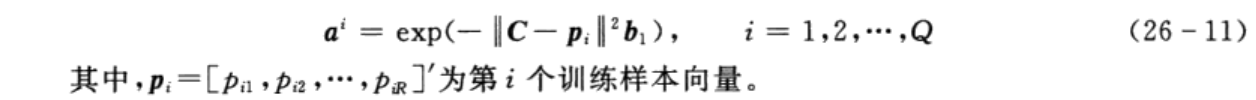
与RBF神经网络不同的是,PNN中隐含层与输出层间的连接权值W取为训练集输出矩阵,即
![]()
(4)输出层神经元输出计算
当隐含层与输出层神经元间的连接权值确定后,根据图2所示,便可以计算出输出层神经元的输出,即
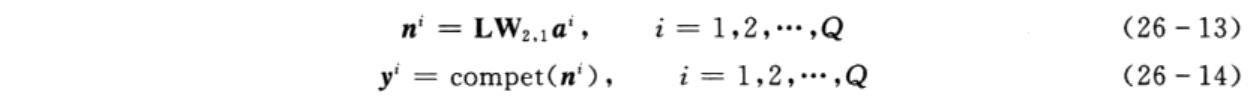
3.PNN的MATLAB工具箱函数
函数newpnn用于创建一个PNN,其调用格式如下:
net=newpnn(P,T,spread)
其中,P为网络输入向量;T为网络目标向量;spread为径向基函数的扩展速度(默认为0.1);net为创建好的RBF网络。
2 案例背景
2.1 问题描述
植物的分类与识别是植物学研究和农林业生产经营中的重要基础工作,对于区分植物种类、探索植物间的亲缘关系、阐明植物系统的进化规律具有重要意义。目前常用的植物种类鉴别方法是利用分类检索表进行鉴定,但该方法花费时间较多,且分类检索表的建立是一件费时费力的工作,需要投入大量的财力物力。
叶片是植物的重要组成部分,叶子的外轮廓是其主要形态特征。在提取叶子形态特征的基础上,利用计算机进行辅助分类与识别成为当前的主要研究方向,同时也是研究的热点与重点。
现采集到150组不同类型鸢尾花(Setosa、Versicolour和Virginica)的4种属性:萼片长度、萼片宽度、花瓣长度和花瓣宽度,样本编号与4种属性的关系如图3所示(其中,样本编号1~50为Setosa, 51~100为Versicolour, 101~150为Virginica)。从图中大致可以看出,花瓣长度、花瓣宽度与鸢尾花类型间有较好的线性关系,而萼片长度、萼片宽度与鸢尾花类型间呈现出非线性的关系。
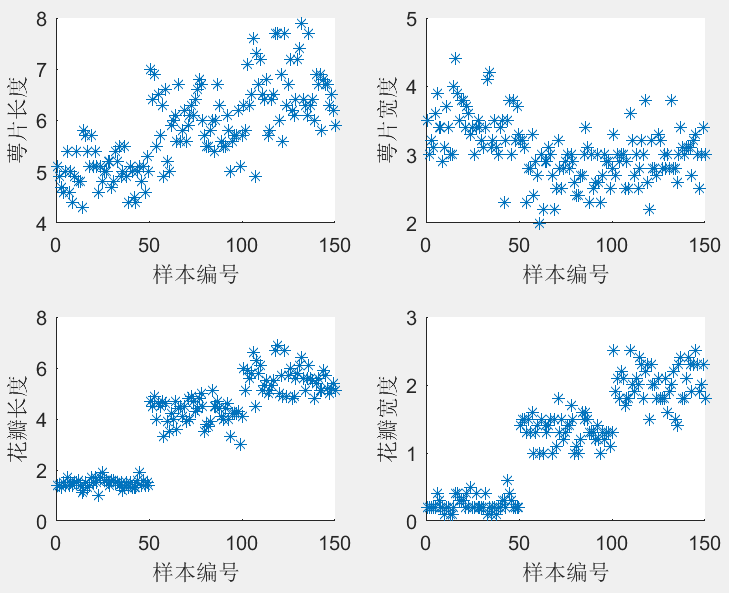
图3
样本编号与4种属性的关系
现要求:
(1)利用GRNN和PNN分别建立鸢尾花种类识别模型,并对模型的性能进行评价。
(2)利用GRNN和PNN分别建立各个属性及属性组合与鸢尾花种类间的识别模型,并与(1)中所建模型的性能及运算时间进行对比,从而探求各个属性及属性组合与鸢尾花种类的相关程度。
2.2 解题思路及步骤
依据问题描述中的要求,实现GRNN及PNN的模型建立及性能评价,大体上可以分为以下几个步骤,如图4所示。
1.产生训练集/测试集
在产生训练集及测试集时,除了考虑训练集及测试集样本数的大小,还应考虑异常样本对模型性能的影响,对于异常样本应进行剔除。常用的异常样本剔除方法有观察法、统计法、聚类法等。
2.创建GRNN
利用MATLAB自带的神经网络工具箱函数可以方便地创建GRNN,具体程序参见第3节。
3.创建PNN
利用MATLAB自带的神经网络工具箱函数可以方便地创建PNN,具体程序参见第3节。
4.仿真测试
模型建立后,将测试集的输入变量送入模型,模型的输出便是对应的预测结果。
5.性能评价
通过计算测试集预测类别与真实类别间的误差,可以对模型的泛化能力进行评价。同时,通过对比不同属性及属性组合与鸢尾花类别间的相关性,可以在模型精度与运算速度上做出折中选择。
3 MATLAB程序实现
利用MATLAB神经网络工具箱提供的函数,可以方便地在MATLAB环境下实现上述步骤。
%% 清空环境变量
clear all
clc
%% 训练集/测试集产生
% 导入数据
load iris_data.mat
figure
subplot(2,2,1)
scatter(1:150,features(:,1),'*')
xlabel('样本编号')
ylabel('萼片长度')
subplot(2,2,2)
scatter(1:150,features(:,2),'*')
xlabel('样本编号')
ylabel('萼片宽度')
subplot(2,2,3)
scatter(1:150,features(:,3),'*')
xlabel('样本编号')
ylabel('花瓣长度')
subplot(2,2,4)
scatter(1:150,features(:,4),'*')
xlabel('样本编号')
ylabel('花瓣宽度')
% 随机产生训练集和测试集
P_train = [];
T_train = [];
P_test = [];
T_test = [];
for i = 1:3
temp_input = features((i-1)*50+1:i*50,:);
temp_output = classes((i-1)*50+1:i*50,:);
n = randperm(50);
% 训练集——120个样本
P_train = [P_train temp_input(n(1:40),:)'];
T_train = [T_train temp_output(n(1:40),:)'];
% 测试集——30个样本
P_test = [P_test temp_input(n(41:50),:)'];
T_test = [T_test temp_output(n(41:50),:)'];
end
%% 模型建立
result_grnn = [];
result_pnn = [];
time_grnn = [];
time_pnn = [];
for i = 1:4
for j = i:4
p_train = P_train(i:j,:);
p_test = P_test(i:j,:);
%% GRNN创建及仿真测试
t = cputime;
% 创建网络
net_grnn = newgrnn(p_train,T_train);
% 仿真测试
t_sim_grnn = sim(net_grnn,p_test);
T_sim_grnn = round(t_sim_grnn);
t = cputime - t;
time_grnn = [time_grnn t];
result_grnn = [result_grnn T_sim_grnn'];
%% PNN创建及仿真测试
t = cputime;
Tc_train = ind2vec(T_train);
% 创建网络
net_pnn = newpnn(p_train,Tc_train);
% 仿真测试
Tc_test = ind2vec(T_test);
t_sim_pnn = sim(net_pnn,p_test);
T_sim_pnn = vec2ind(t_sim_pnn);
t = cputime - t;
time_pnn = [time_pnn t];
result_pnn = [result_pnn T_sim_pnn'];
end
end
%% 性能评价
% 正确率accuracy
accuracy_grnn = [];
accuracy_pnn = [];
time = [];
for i = 1:10
accuracy_1 = length(find(result_grnn(:,i) == T_test'))/length(T_test);
accuracy_2 = length(find(result_pnn(:,i) == T_test'))/length(T_test);
accuracy_grnn = [accuracy_grnn accuracy_1];
accuracy_pnn = [accuracy_pnn accuracy_2];
end
% 结果对比
result = [T_test' result_grnn result_pnn]
accuracy = [accuracy_grnn;accuracy_pnn]
time = [time_grnn;time_pnn]
%% 绘图
figure(1)
plot(1:30,T_test,'bo',1:30,result_grnn(:,4),'r-*',1:30,result_pnn(:,4),'k:^')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'测试集预测结果对比(GRNN vs PNN)';['正确率:' num2str(accuracy_grnn(4)*100) '%(GRNN) vs ' num2str(accuracy_pnn(4)*100) '%(PNN)']};
title(string)
legend('真实值','GRNN预测值','PNN预测值')
figure(2)
plot(1:10,accuracy(1,:),'r-*',1:10,accuracy(2,:),'b:o')
grid on
xlabel('模型编号')
ylabel('测试集正确率')
title('10个模型的测试集正确率对比(GRNN vs PNN)')
legend('GRNN','PNN')
figure(3)
plot(1:10,time(1,:),'r-*',1:10,time(2,:),'b:o')
grid on
xlabel('模型编号')
ylabel('运行时间(s)')
title('10个模型的运行时间对比(GRNN vs PNN)')
legend('GRNN','PNN')
说明:
(1)借助函数cputime可以计算出程序(段)运行的时间,以衡量程序的运行速度及性能好坏,具体用法请参考帮助文档。
(2)函数round的作用是四舍五入取整,具体用法请参考帮助文档。
(3)函数ind2vec用于将代表类别的下标矩阵转换为对应的矢量矩阵,函数vec2ind的作用与函数ind2vec的作用相反,将矢量矩阵转换为对应的代表类别的下标矩阵。
(4)result_grnn和result_pnn均为30行10列的矩阵,分别对应表1中的10个模型。
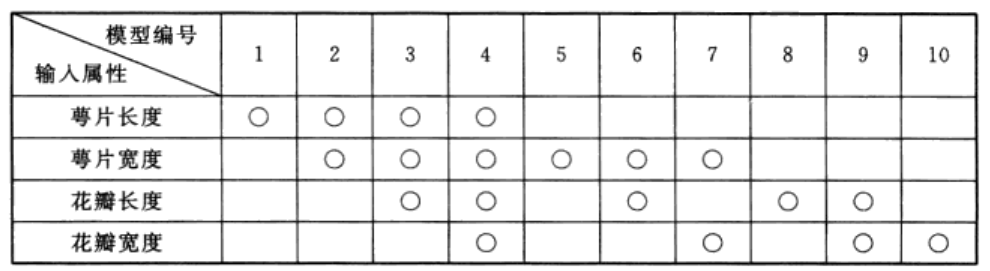
其中,“O”表示对应的输入属性参与模型的建立。
(5)accuracy为2行10列的矩阵,其第1行对应基于GRNN的10个模型的测试集正确率,其第2行对应基于PNN的10个模型的测试集正确率。
(6)time为2行10列的矩阵,其第1行对应基于GRNN的10个模型的创建及仿真测试时间,其第2行对应基于PNN的10个模型的创建及仿真测试时间。
4 结果分析
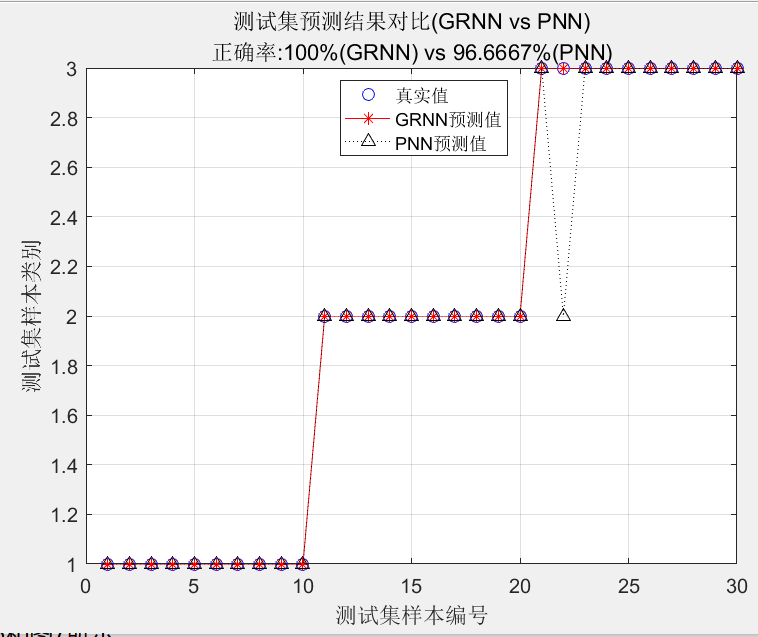
由于训练集和测试集是随机产生的,每次运行时的结果亦会有所不同。某次程序运行结果如图5、图6和图7所示。
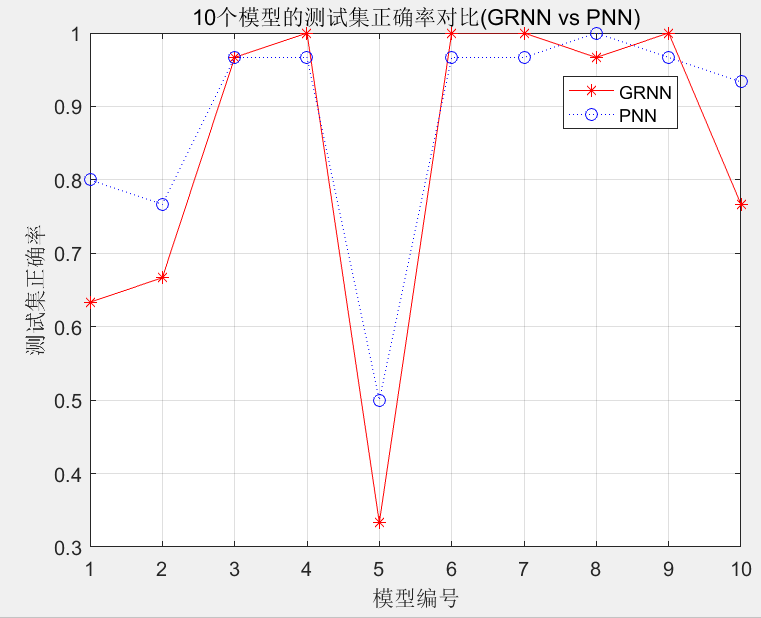

从图中不难发现:
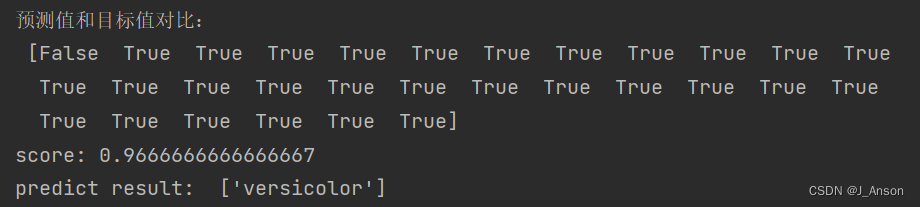
(1)GRNN和PNN模型具有良好的泛化能力,测试集预测正确率分别达96.67%和100%
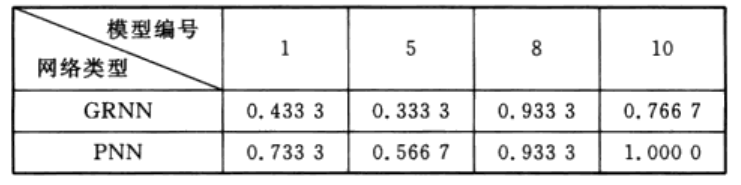
(2)如表1所列,利用4个属性(萼片长度、萼片宽度、花瓣长度、花瓣宽度)建立的模型编号分别为1、5、8、10。表2描述了与之对应的GRNN和PNN模型的测试集正确率。
由表2中可以清晰地看出,萼片宽度单独建立的GRNN模型(模型编号分别为1和5)性能不佳,确率只有43.3和33.3%; 利用花瓣长度和花瓣宽度单独建立的GRNN 模型(模型编号分别为8和10)性能较好,正确率分别达93.3%和76.7%与之对应的PNN模型结果亦呈现类似的规律,这表明萼片长度和萼片宽度与鸢尾花类别的相关性较小,而花瓣长度和花瓣宽度与鸢尾花类别的相关性较大,该结论与图3中呈现的规律一致。
(3)与GRNN相比,PNN模型的泛化能力较好,测试集的正确率较高。同时,GRNN和PNN模型的运行时间相当,10个模型的平均运行时间在50ms左右,远快于BP神经网络。
5 总结
GRNN及PNN具有良好的泛化性能,且与BP神经网络等不同,其权值和阈值由训练样本一步确定,无须迭代,计算量小。因此,其在各个领域得到了广泛的应用。与RBF神经网络相同,spread值对于GRNN和PNN的性能影响较大,此处不再赘述。近年来,不少专家和学者开始致力于改善GRNN和PNN的结构,并与其他算法相结合,取得了更加令人满意的结果。