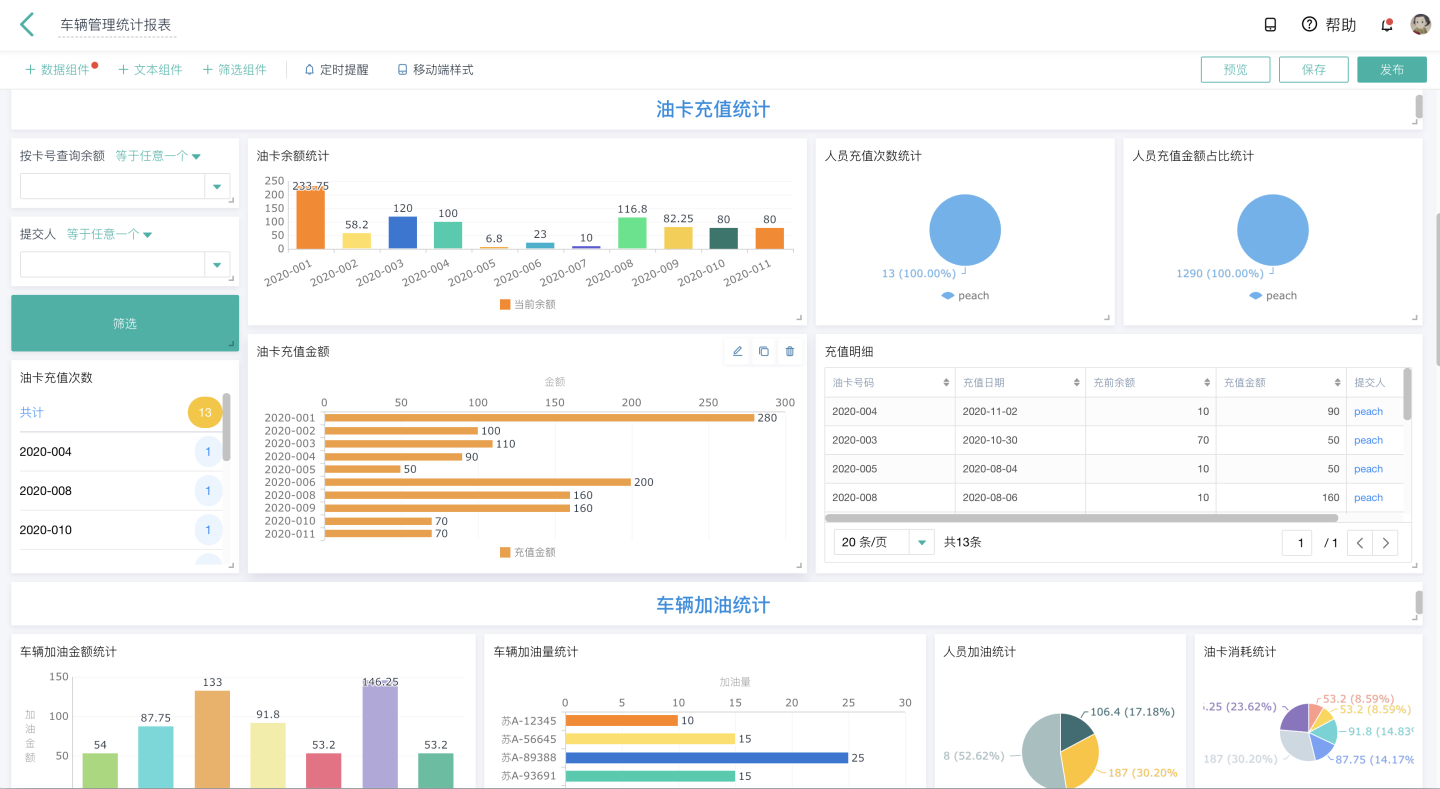
一、KNN算法概述
KNN:K-Nearest-Neighbor算法,即K值为邻近。KNN是最简单的分类算法之一,同时,也是最常用的分类算法之一。KNN算法是有监督学习中的分类算法。
二、原理
基于基于iris数据集,具体经历下面四步流程:
①载入数据,对数据进行预处理 (缺失值处理、标准化等,其中iris数据集数据全面,无需进行缺失值处理)。
②计算待分类点到其他每个样本点的距离。
③对每个距离进行排序,然后选择出距离最小的K个点。
④对K个点所属的类别进行比较,根据少数服从多数的原则,将待分类点归入在K个点中占比最高的那一类。
三、相关基础知识的扩展
(1)对缺失值补全的方法,此处采用对缺失值填充当列数据的平均值的方法
# 缺失值处理
for i in iris_dataset.columns:
if not np.all(pd.notnull(iris_dataset[i])):
iris_dataset[i].fillna(iris_dataset[i].mean())(2)距离计算公式,包括闵式距离(含欧式距离、曼哈顿距离和切比雪夫距离)、标准化欧式距离(排除数据量纲的影响)、余弦距离、杰卡德距离(求交集、并集间距离)、汉明距离(密码学常用,求字符串间距离)、马氏距离(求分布数据距离)。下面详细介绍闵式距离。
闵氏距离又叫做闵可夫斯基距离,是欧氏空间中的一种测度,被看做是欧氏距离的一种推广,欧氏距离是闵可夫斯基距离的一种特殊情况。定义式:
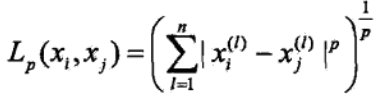
闵可夫斯基距离公式中:
当时,即为欧氏距离:勾股定理计算的点之间的直接距离
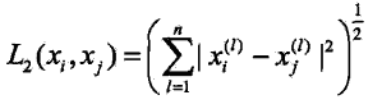
当时,即为曼哈顿距离:点在标准坐标系上的绝对轴距之和
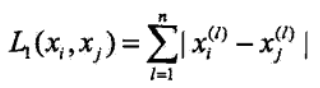
当时,即为切比雪夫距离:各坐标轴数据差的最大值
![]()
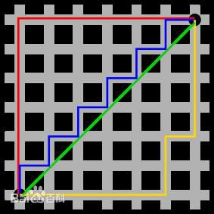
图中绿色代表欧氏距离,红线代表曼哈顿距离,其他三条折线也表示了曼哈顿距离,这三条折线的长度是相等的。
四、使用KNN算法预测iris数据集
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 载入数据
iris = load_iris()
# 创建DF
iris_dataset = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# iris_dataset['target'] = iris['target']
# iris_dataset['species'] = iris.target_names[iris['target']]
# 缺失值处理
for i in iris_dataset.columns:
if not np.all(pd.notnull(iris_dataset[i])):
iris_dataset[i].fillna(iris_dataset[i].mean())
# 数据集拆分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
# 标准化处理
scaler = preprocessing.StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
# 模型训练
knn = KNeighborsClassifier(n_neighbors=9, algorithm='auto')
estimator = knn.fit(x_train, y_train)
# 模型评估,预测值
y_predict = estimator.predict(x_test)
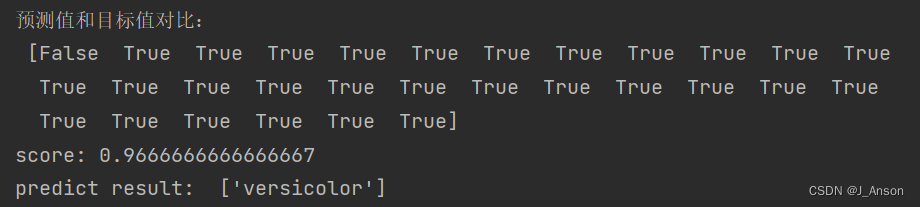
print("预测值和目标值对比:\n", y_predict == y_test)
# 准确率
score = estimator.score(x_test, y_test)
print("score:", score)
# 预测
test_pre = estimator.predict([[1, 0.002, 0.00465, 1]])
print("predict result: ", iris.target_names[test_pre])
运行结果: