一、背景
经常写爬虫的同学,肯定知道 Cloud Flare 的五秒盾。当你没有使用正常的浏览器访问网站的时候,它会返回如下这段文字:
Checking your browser before accessing xxx.This process is automatic. Your browser will redirect to your
requested content shortly.Please allow up to 5 seconds… 即使你把 Headers 带完整,使用代理 IP,也会被它发现。
二、示例
直接查看原始的网页源代码,可以看到,需要的数据就在源代码里面,说明这些数据都是后端渲染的,不是异步加载。
我们使用 requests,带上完整的请求头来访问这个网站,效果如下图所示:
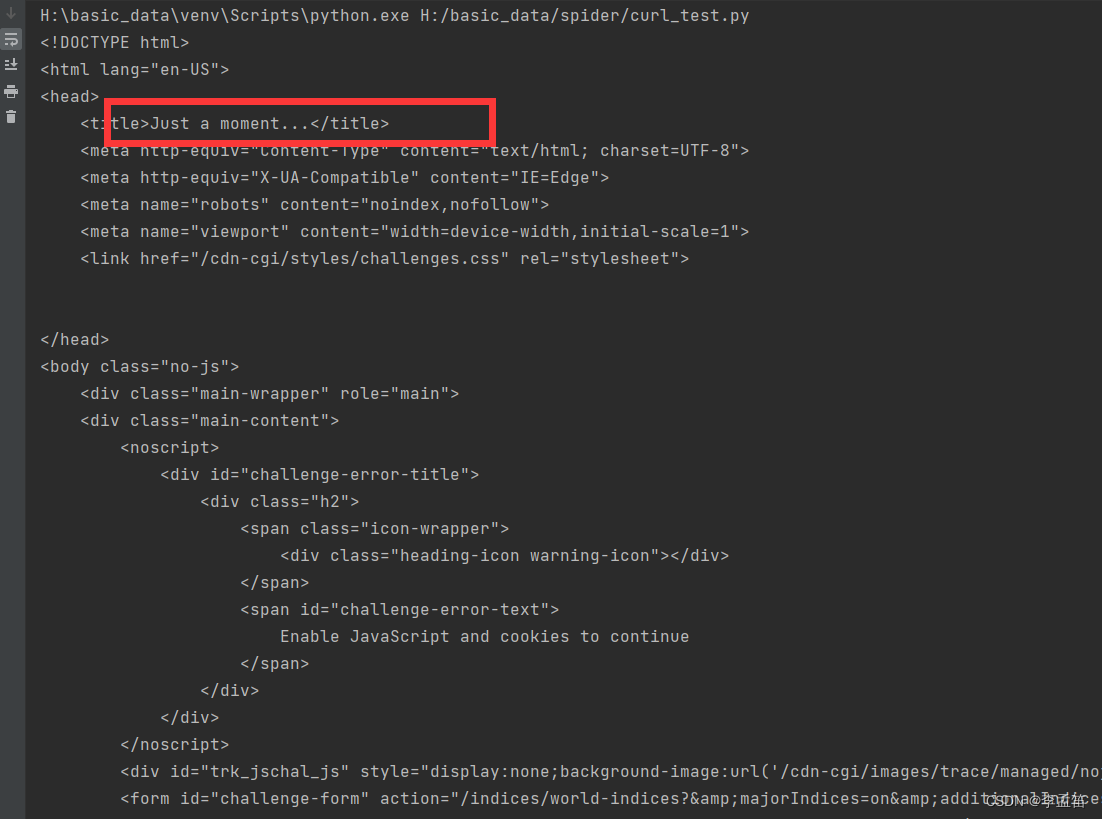
起初还以为是网站响应时间太长,但是加了等待时间依然不会得到正确的数据。很明显网站识别到了爬虫行为,成功把爬虫请求挡住了。很多情况下这是时候就已经束手无策了,因为这是爬虫的第一次请求就被挡住了,所以网站不是检测的 IP 或者访问频率,所以即使用代理 IP 也无济于事。而现在即使带上了完整的请求头都能被发现,那还有什么办法绕过这个检测呢?
实际上,要绕过这个5秒盾非常简单,只需要使用一个第三方库,叫做cloudscraper。我们可以使用pip来安装:
pip install cloudscraper
#更新最新版本 pip install cloudscraper -U
安装完成以后,只需要使用3行代码就能绕过 Cloud Flare 的5秒盾:
import cloudscraper
#创建实例 scraper = cloudscraper.create_scraper()
resp = scraper.get(‘目标网站’).text
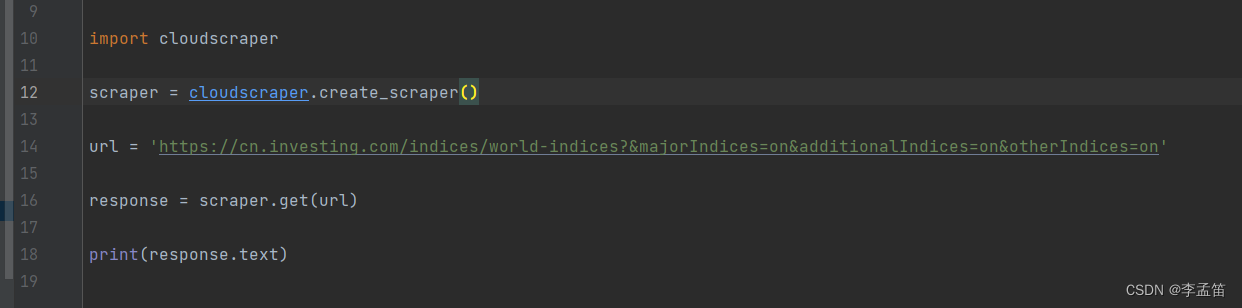
以上面的网站为例:
输出结果:
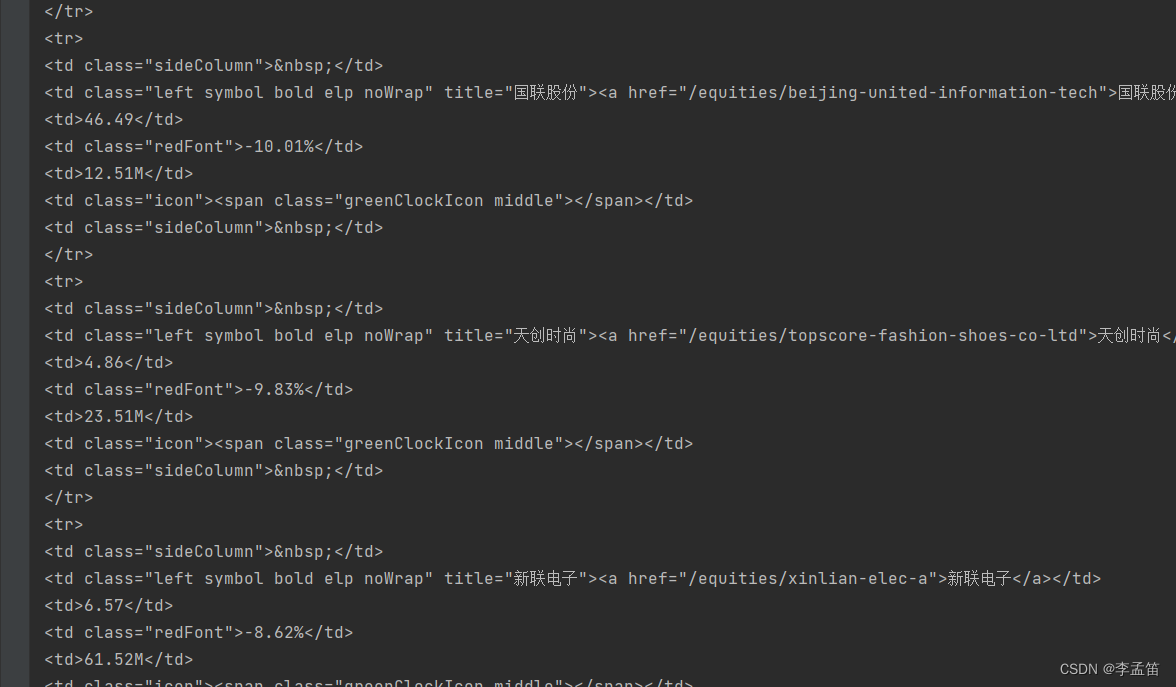
可以看到明文数据已经可以正常返回了。
#三、在scrapy中间件使用
在 middlewares.py 文件中配置:
class CloudScraperMiddleware:
def process_response(self, request, response, spider):
if response.status == 403:
url = request.url
req = spider.scraper.get(url, headers={'referer': url})
return HtmlResponse(url=url, body=req.text, encoding="utf-8", request=request)
return response
spider.py 中使用:
import cloudscraper
# 启用中间件
custom_settings = {
"DOWNLOADER_MIDDLEWARES": {
'testspider.middlewares.CloudScraperMiddleware': 520,
}
}
def __init__(self, **kwargs):
# 创建实例
self.scraper = cloudscraper.create_scraper()
#四、总结
还有一个库(cfscrape)和cloudscraper用法一模一样,但是经过测试抓取上面这个网站,该库失败。
CloudScraper 非常强大,它可以突破 Cloud Flare 免费版各个版本的五秒盾。而且它的接口和 requests
保持一致。原来用 requests 怎么写代码,现在只需要把requests.xxx改成scraper.xxx就可以了。
另外由于是使用免费接口,会存在少部分网站使用达不到理想效果。而且有时候会报警告:

这种情况只需要重试即可。