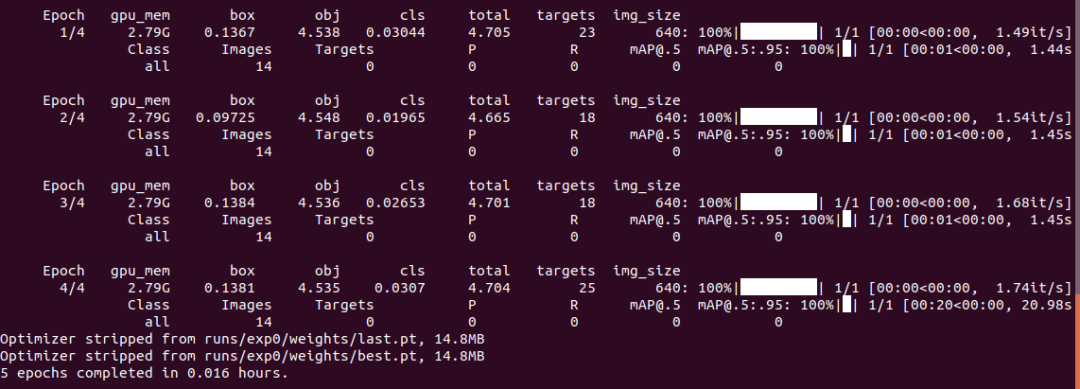
对于输入的序列 ![]() 来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对
来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对![]() 进行计算,这大大提高了对
进行计算,这大大提高了对![]() 特征进行提取(即获得
特征进行提取(即获得![]() )的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:
)的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:

由上图可以看到,通过对输入I分别乘以矩阵![]() ,我们便得到了三个矩阵
,我们便得到了三个矩阵![]() ,然后通过后续计算得到注意力矩阵
,然后通过后续计算得到注意力矩阵![]() ,进而得到输出
,进而得到输出![]() 。
。
以上便是Self-attention的主要原理。如果你想更加深入地理解和掌握自注意力机制的理论基础和运算细节,
在Transformer及BERT模型中用到的Multi-headed Self-attention结构与之略有差异,具体体现在:如果将前文中得到的![]() 整体看做一个“头”,则“多头”即指对于特定的
整体看做一个“头”,则“多头”即指对于特定的 ![]() 来说,需要用多组
来说,需要用多组![]() 与之相乘,进而得到多组
与之相乘,进而得到多组![]() 。如下图所示:
。如下图所示:

多头自注意力示意
如上图所示,以右侧示意图中输入的 ![]() 为例,通过多头(这里取head=3)机制得到了三个输出
为例,通过多头(这里取head=3)机制得到了三个输出![]() ,为了获得与a1对应的输出
,为了获得与a1对应的输出![]() ,在Multi-headed Self-attention中,我们会将这里得到的
,在Multi-headed Self-attention中,我们会将这里得到的![]() 进行拼接(向量首尾相连),然后通过线性转换(即不含非线性激活层的单层全连接神经网络)得到
进行拼接(向量首尾相连),然后通过线性转换(即不含非线性激活层的单层全连接神经网络)得到![]() 。对于序列中的其他输入也是同样的处理过程,且它们共享这些网络的参数。
。对于序列中的其他输入也是同样的处理过程,且它们共享这些网络的参数。
以上便是对Transformer及BERT模型中用到的多头自注意力机制的简要介绍,接下来的文章将介绍Transformer及BERT模型。