点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【目标检测和Transformer】交流群

GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds
论文链接:https://arxiv.org/abs/2305.16404
代码:https://github.com/vLAR-group/GrowSP
Overall Pipeline: 
图1: GrowSP整体流程
1. Introduction
近年来,三维点云处理在计算机视觉和机器学习领域引起了广泛的关注。然而,现有的点云分割方法通常需要大量标注好的训练数据,这在实践中限制了它们的应用范围。针对这一问题,我们在最新的CVPR论文中提出了一种全新的无监督三维点云语义分割方法 GrowSP。我们的方法利用superpoints以及渐进式扩张superpoints的方式实现了在3D场景中自动发掘语义信息。实验结果表明,我们的方法在多个三维点云数据集上取得了令人印象深刻的性能,且无需任何人工监督信号或者预训练模型等。
我们相信,这项研究对于解决三维点云处理中的监督学习问题具有里程碑意义,并且将在实际应用中产生广泛的影响。我们的贡献主要包括以下三点:
针对真实世界点云,首次提出了一个完全无监督的3D语义分割框架,无需人工标注或任何预训练;
引入了一种简单的superpoints扩张策略,引导网络逐渐学习高级语义信息;
在多个真实3D场景数据集上展示出了有前景的语义分割效果,显著地优于将2D适配到3D的方法和3D自监督预训练方法。
3. Method
3.1 Overview
本文将无监督3D语义分割作为一个3D特征学习和聚类的问题来处理。如图2所示,首先将点云输入backbone提取逐点feature;然后依靠几何构建initial superpoints,获取superpoint features;superpoints会进一步合并成为语义基元,根据语义基元产生pseudo labels用于训练backbone。在此过程中,随着训练的进行,backbone输出的特征具备的语义信息会越来越丰富,依照输出features的相似性对superpoints进行合并,实现superpoints growing。
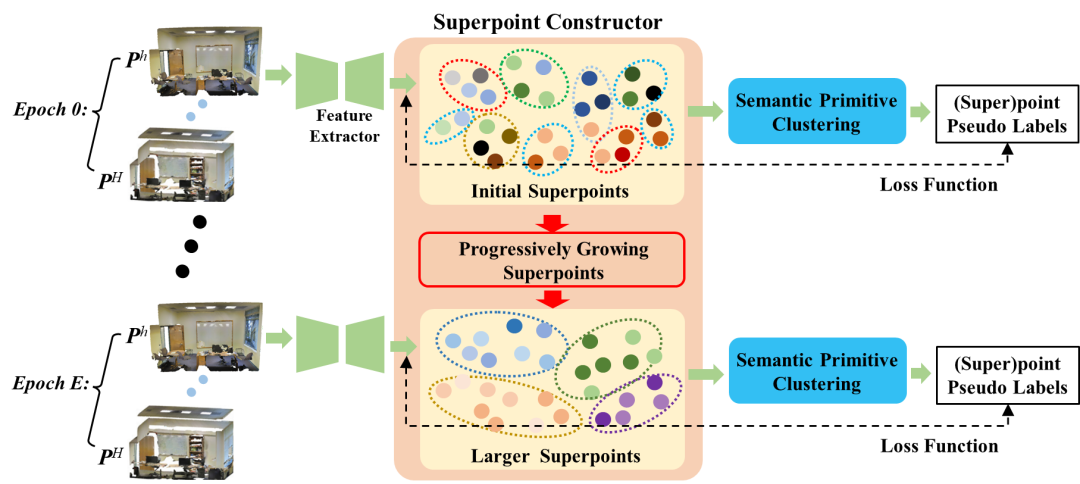
图2: GrowSP框架结构
GrowSP框架包括以下三个核心部分:
1) Superpoints Constructor:构建初始的superpoints,将几何,空间位置或RGB (if available) 相似的点组合成superpoints;
2) Superpoints Growing:随着神经网络的不断训练,其输出特征逐渐具有high-level信息,依靠特征相似度,对单个3D场景进行superpoints扩张,逐步涵盖语义相近的区域;
3) Semantic Primitive Clustering:数据集种包含的superpoints会进一步合并为一些简单的语义元素或基。
3.2 Superpoints Constructor
该模块的目的是构建initial superpoints, 提供一些语义信息的先验,主要用于在训练初期引导网络的学习。对于数据集中每个3D场景,该模块会将场景点云划分为多个空间上连通的区域,这些区域内的几何形状和RGB是一致的。本文结合了两种手工设计的superpoints划分方法:VCCS和Region Growing,划分得到的superpoints如图3所示。

图3: Superpoint样例图
3.3 Superpoints Growing
该模块是GrowSP框架的主要部分。初始构建的superpoints基于几何,位置和RGB等信息约束神经网络在后续步骤对这些low-level一致的点输出一致的特征,这可以促使网络学习语义,这一约束在训练的初期非常有效。
进一步地,为了使其学习到更加high-level的语义,我们依照特征相似度,对每一个3D场景进行superpoints growing。Growing的过程是在单个场景中进行的,将每个initial superpoints包含的per-point features平均,作为superpoint features。对单个场景内的superpoints依照features相似度聚类,实现superpoints的扩张,如图4所示。
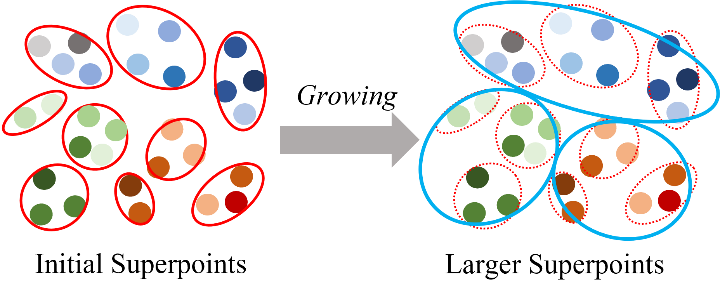
图4: Superpoints Growing
3.4 Semantic Primitive Clustering
以上两个步骤只是构建和增强superpoints,并未产生语义类别。在这一步,我们对整个数据集的superpoint features (在网络训练初期是initial superpoints,后期是growing后的superpoints) 进行聚类。实验发现,当聚类数多于最终类别数可以避免错误地将不同类的superpoints聚集在一起,并且会带来performance提升。于是我们将superpoints聚合为多个基础的语义单元,同时产生pseudo labels用于训练backbone。训练结束后再将语义基元聚合成类别,聚合方法是简单地K-means。
由于本文以完全无监督的方式进行语义分割,所产生的类别标签只能用于区分不同的类,而和ground truth的标签序号不一致,所以在测试时会使用Hungarian matching修正标签序号。
4. Experiments
为了验证算法可行性,本文在两个常用的室内数据集S3DIS,ScanNet和一个室外数据集SemanticKITTI上评估了算法性能。
4.1 Evaluation on S3DIS
本文首先在S3DIS上与baselines进行了比较,选择了适配2D无监督语义分割算法PICIE[2]和IIC[5]到3D,以及对原始点云信息(xyzrgb) 进行K-means聚类三种作为baselines。从表1&2可以看出,本文方法都要优于上述baselines,并且在Area5上取得了非常接近全监督训练的PointNet的效果。
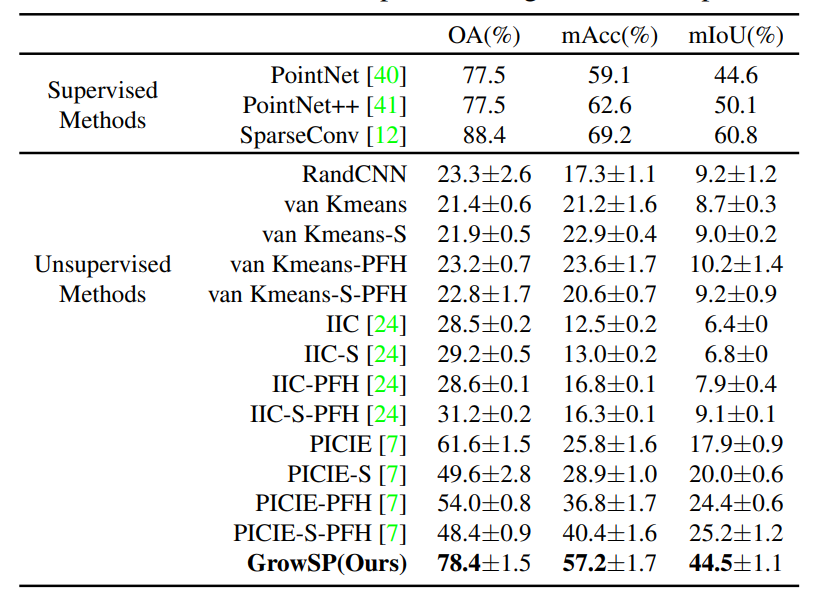
表1: S3DIS-Area5数值结果对比
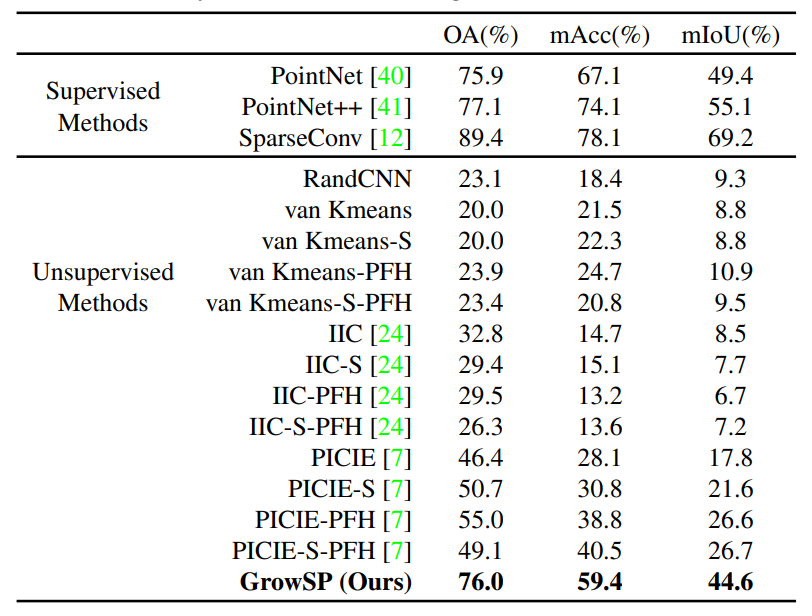
表2: S3DIS 6-fold交叉验证
图5是在S3DIS数据集上可视化的对比,并且图6&7展示了Training和inference的一组demo video。

图5: S3DIS可视化对比
图6: S3DIS training demo
图7: S3DIS inference demo
4.2 Evaluation on ScanNet
其次,本文也评估了在ScanNet数据集上的表现。如表3&4所示,ScanNet上也大幅超越baselines。图8展示了ScanNet上的可视化效果,同样图9&10是ScanNet上一组demo。
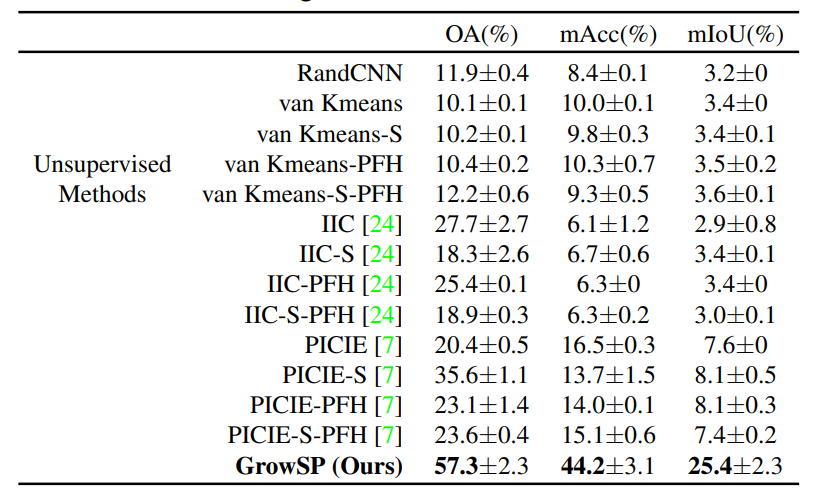
表3:ScanNet验证集数值结果对比
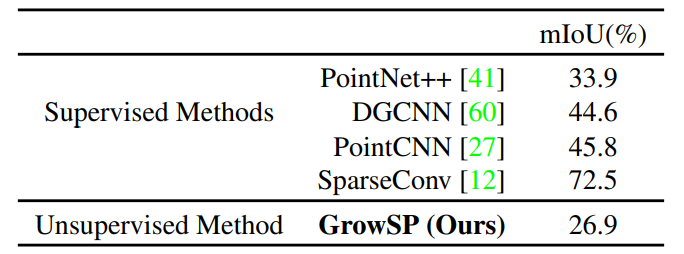
表4:ScanNet在线测试集数值结果对比
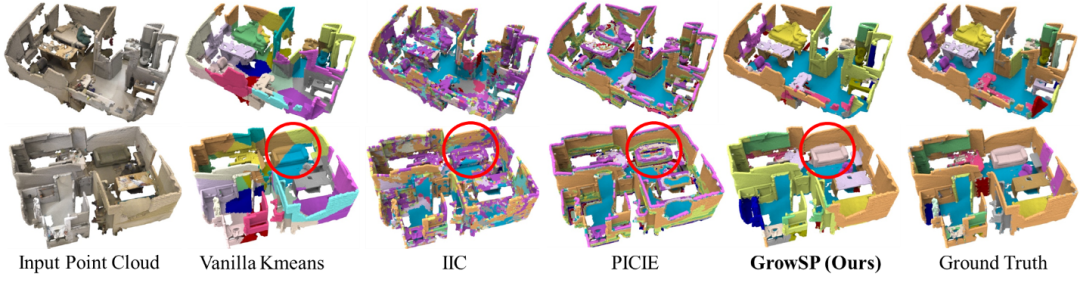
图8: ScanNet可视化对比
图9: ScanNet training demo
图10: S3DIS inference demo
4.3 Evaluation on SemanticKITTI
接下来,我们评估GrowSP在室外数据集SemanticKITTI上的表现,由于LiDAR数据的疏密不均问题,构建superpoints会比室内困难,最终我们还是取得了接近全监督PointNet的结果。
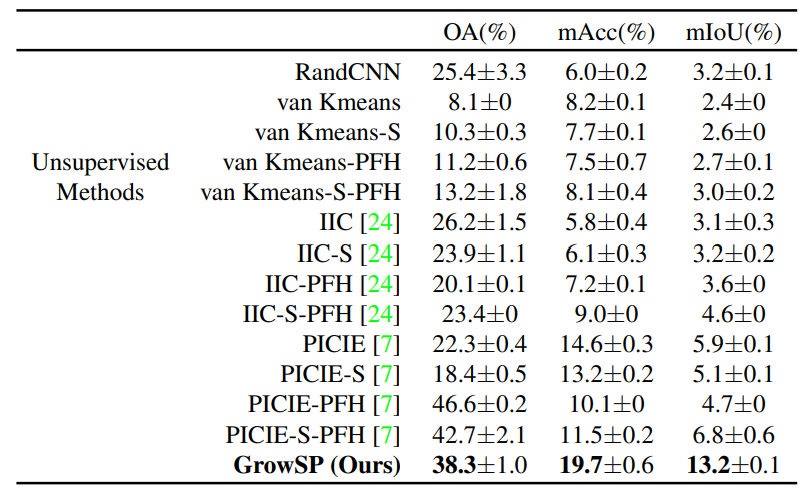
表5: SemanticKITTI验证集数值对比
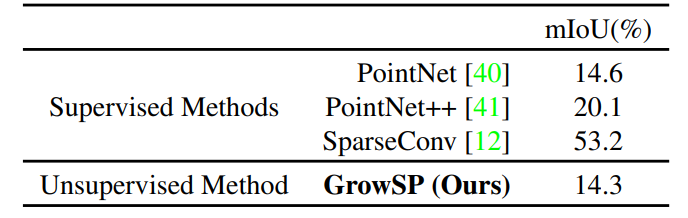
表6:SemanticKITTI在线测试集数值对比
图11&12展示了SemanticKITTI数据集的Training和inference的一组demo video。
图11: SemanticKITTI training demo
图12: SemanticKITTI inference demo
5. Conclusion
最后总结一下,我们提出了首个3D场景上的无监督语义分割框架。主要利用superpoints的逐步扩张来学习高级语义,以及语义基元聚合来避免训练初期不同类别的错误聚合,训练后可以直接用于分割点云,在室内室外多个数据集上都展示出了很有前景的效果,同时也留有大量提升空间和可拓展性。
Reference
[1] Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. CVPR, 2021
[2] Jang Hyun Cho, Utkarsh Mall, Kavita Bala, and Bharath Hariharan. PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering. CVPR, 2021.
[3] Saining Xie, Jiatao Gu, Demi Guo, Charles R Qi, Leonidas Guibas, and Or Litany. Pointcontrast: Unsupervised pretraining for 3d point cloud understanding. ECCV, 2020.
[4] Ji Hou, Benjamin Graham, Matthias Nießner, and Saining Xie. Exploring data-efficient 3d scene understanding with contrastive scene contexts. CVPR, 2021.
[5] Xu Ji, Andrea Vedaldi, and Joao Henriques. Invariant information clustering for unsupervised image classification and segmentation. ICCV, 2019.
点击进入—>【目标检测和Transformer】交流群
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()