1. 概念
1.1. 事务
1.1.1. 系统处理的抽象工作单元
1.1.1.1. 与数据库事务不同
1.1.1.2. 单个工作单元可能包含许多数据库事务
1.1.2. 系统存在的原因
1.1.2.1. 如果一个系统只能处理一种事务,那么它就是专用系统
1.1.2.2. 混合工作负载是系统能处理的不同事务类型的组合
1.2. 系统
1.2.1. 用户处理事务所需的一套完备且相互依赖的硬件、应用程序和服务
1.2.1.1. 单个应用程序
1.2.1.2. 庞大的多层应用程序和服务器网络
1.2.2. 即使在瞬时冲击、持续压力或正常处理工作被失效的组件破坏的情况下,稳健的系统也能够持续处理事务
1.2.2.1. 指服务器或应用程序仍能保持运行
1.2.2.2. 更多地是指用户仍然可以完成工作
1.3. 冲击
1.3.1. 对系统快速施加大量的访问流量
1.3.1.1. “用锤子猛击”系统
1.3.2. 一万个新会话在一分钟内全都挤过来,任何服务实例都难以招架
1.4. 压力
1.4.1. 长时间持续地对系统施加访问流量
1.4.2. 信用卡处理系统的容量不足以满足所有顾客的需求,因此其响应速度变得十分缓慢
1.5. 失效
1.5.1. 系统不再响应
1.6. 长时间
1.6.1. 两次代码部署的间隔时间
1.7. 劳损
1.7.1. 压力产生劳损
1.7.2. 来自信用卡处理系统的压力,会导致劳损波及系统的其他部分,进而导致系统运行异常
1.7.2.1. Web服务器的内存使用率升高
1.7.2.2. 数据库服务器的I/O占用率超出正常范围
1.7.2.3. 系统的其他部分发生异常
1.8. 失误
1.8.1. 软件出现内部错误
1.8.2. 原因
1.8.2.1. 潜在的软件缺陷
1.8.2.2. 在边界或外部接口处发生的不受控制的状况
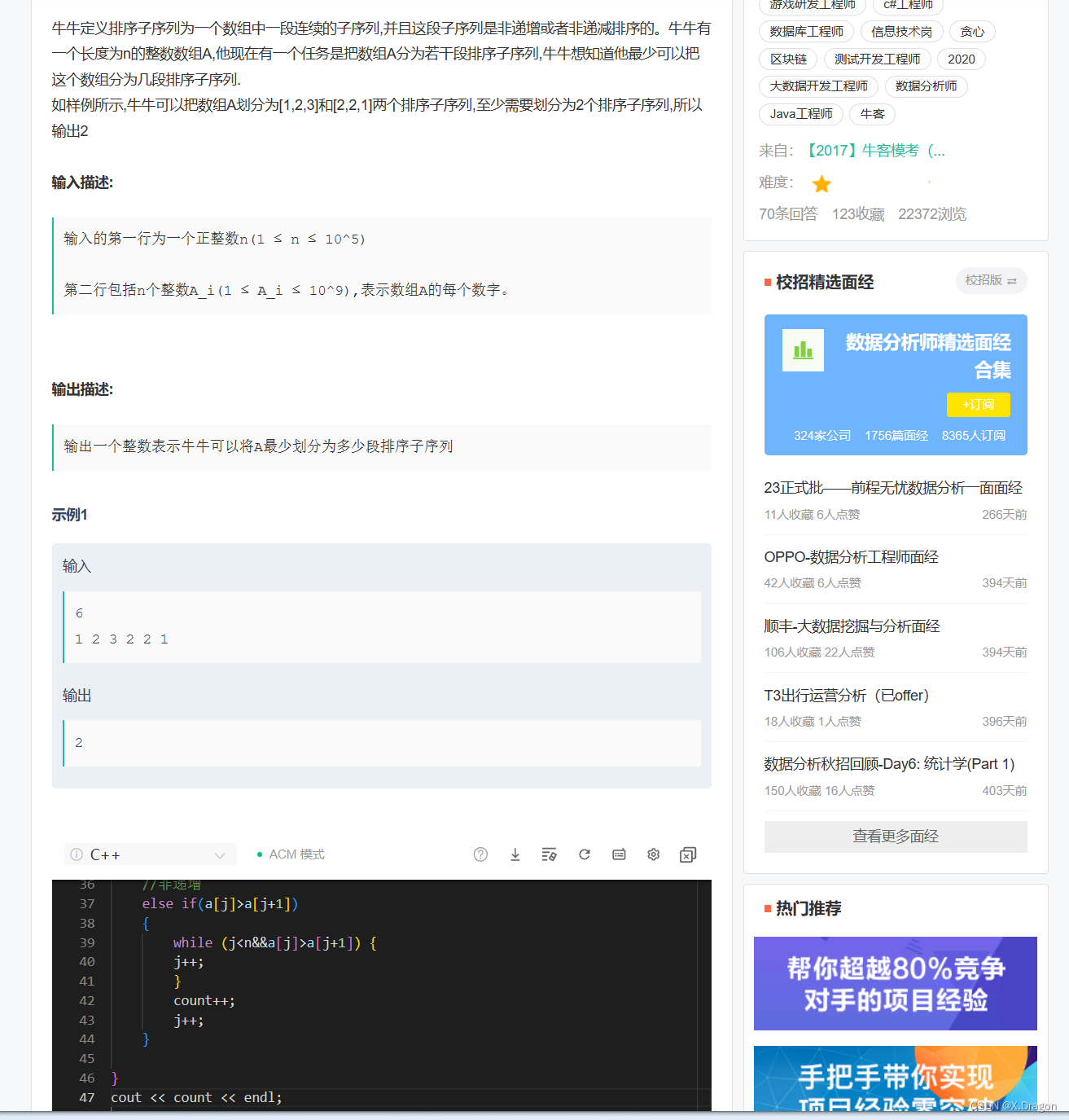
1.9. 错误
1.9.1. 明显的错误行为
2. 没有保持杞人忧天的心态
2.1. 陷入了对新兴技术和先进架构的兴奋之中而不能自拔
3. 威胁系统寿命的主要敌人
3.1. 内存泄漏
3.2. 数据增长
3.3. 会在生产环境中摧毁系统,却很少能在测试中被发现
4. 墨菲定律
4.1. 凡是没有被测试出的问题,将来都会发作
4.1.1. 在实验室里不会发生而在现实世界中发生的事情,通常不是好事情
4.1.2. 只有连续运行7天之后,系统才会显露内存泄漏问题,而如果没有提前测试,那么系统在上线7天后就会遭遇内存泄漏
4.1.3. 负载测试服务供应商每小时收取一大笔金额,所以没有人会请他们一次将负载测试连续运行一周
4.2. 测试使问题浮出水面,从而使人们可以修复系统
5. 应用程序在开发环境中运行的时长永远不足以暴露关乎系统寿命的缺陷
5.1. 发现它们的唯一方法就是运行自己编写的寿命测试
5.1.1. 运行JMeter、Marathon或其他负载测试工具
5.1.2. 让脚本每天有几个小时不怎么向系统发送请求,来模拟半夜的低峰时段
5.1.3. 暴露连接池和防火墙的超时问题
5.2. 至少要测试那些重要的组件,用测试替身替代其余组件
5.3. 生产环境便自动成为寿命测试环境
5.3.1. 那里肯定存在软件缺陷
6. 糟糕的稳定性会带来巨大的损失
6.1. 对交易系统来说,单笔交易中断就可能造成高达100万美元的损失
6.2. 在线零售商获得每位顾客的成本高达150美元。如果每小时有5000位独立访客,假设其中10%最终选择别家,就会浪费7.5万美元的营销资金
6.3. 声誉损失虽然不那么触手可及,但企业在这方面所承受的痛苦是一样的
7. 要使系统获得良好的稳定性,不一定非得支付巨额的费用
7.1. 当构建系统的架构、设计甚至底层实现时,许多决策点对系统的最终稳定性具有很大的影响力
7.2. 高度稳定的设计与不稳定的设计投入成本通常是相同的
8. 系统失效方式
8.1. 突发的冲击和过度的压力都会引发灾难性系统失效
8.2. 系统的某些组件会先于其他组件失效
9. 系统失效应对
9.1. 查看每个外部调用、每个I/O操作、每次对资源的使用和每个预期结果,并询问“这里都有可能出什么错”,同时思考可能出现的各种冲击和压力
9.1.1. 除了关乎生死的关键系统和火星探测器,对其他任何系统来说,蛮力法显然都是不切实际的
9.2. 一旦接受“系统必然会失效”这一事实,就有能力使系统对特定的失效做出相应的反应
9.2.1. 汽车工程师创造出的碰撞缓冲区
9.2.1.1. 为保护乘客而首先被撞毁的区域
9.2.2. 可以为系统创建一种安全失效模式,这种模式包含被损坏区域,并且为系统其他部分提供保护
9.2.2.1. 这种自我保护决定了整个系统的韧性
10. 裂纹阻断器
10.1. 先确定系统的哪些特性是必不可少的
10.1.1. 然后内建系统失效方式,防止重要特性出现裂纹
10.2. 如果不设计系统失效方式,那么系统就会出现各种不可预测的问题,一旦出现,这些问题通常都是危险
10.3. 系统架构的耦合度越高,编程差错蔓延的机会就越大
10.3.1. 多度耦合且高度复杂的系统,会为裂纹提供更多的蔓延途径
10.3.2. 紧耦合会加速裂纹的蔓延
10.4. 低耦合的架构可以起到减震器的作用,这能减少编程差错的影响
10.5. 裂纹始于对SQLException异常的处理失误,但在其他许多环节上能够阻止其蔓延
10.5.1. 可以将资源池配置为在可用资源被耗尽时能创建更多的连接资源
10.5.2. 可以将其配置为当所有连接资源被占用时,短暂地阻塞资源请求者
10.5.3. 在RMI的套接字上设置超时时间
10.5.3.1. 默认情况下,RMI调用永远不会超时
10.5.3.2. 被阻塞的那些调用方会一直等待从CF系统的EJB中读取它们期待的响应
10.5.4. CF系统服务器本身可以分隔出多个服务组
10.5.4.1. 其中一个服务组出现的问题就不会拖垮CF系统的所有用户
10.5.5. CF系统本可以通过请求-回复这样的消息队列方式来构建
10.5.5.1. 调用方知道可能永远不会收到回复,因此它必须将其作为处理协议本身的一部分来处理