文章目录
- Information Extraction 步骤
- Named Entity Recognition (NER)
- Typical Entity Tags 典型实体标签
- IO tagging
- IOB tagging
- 神经网络做 NER
- Relation Extraction
- Rule-based
- Supervised Relation Extraction
- Semi-supervised
- Semantic Drift 语义漂移
- Distant supervision 远程监督
- Unsupervised Relation Extraction ("OpenlE")
- Evaluation
- Other Information Extraction 任务
- Temporal Expression Extraction
- Event Extraction


Information Extraction 步骤

- Named Entity Recognition (NER): 命名实体识别
- Relation Extraction: 关系提取

Named Entity Recognition (NER)


Typical Entity Tags 典型实体标签

- 命名实体识别中可能遇到歧义的问题(这种问题在 POS tagging 里面也很普遍):

- 为了消除歧义,我们需要结合上下文。

- 虽然在 POS 中我们可以使用 HMM,但是在 NER 任务中却不适合这么做:
隐马尔可夫模型(Hidden Markov Models, HMM)是一种可以用来处理序列数据的模型,它在一些NLP任务中表现得非常好,比如词性标注。然而,HMM有一些局限性,使得它在处理命名实体识别中的歧义问题时可能不会表现得很好。原因如下:
-
一阶马尔可夫性质:HMM假设序列中的每个状态(在NER任务中,这些状态可能是实体标签)仅依赖于前一个状态。这意味着HMM不能直接捕获超过一步的上下文信息。然而,实际上,一个词的实体类型可能依赖于更广的上下文。 例如,“苹果”在“我喜欢吃Apple”和“我喜欢使用Apple产品”这两个句子中具有不同的实体类型,但是这个信息无法通过仅看前一个词的HMM捕获。
-
无法处理复杂的特征:HMM通常使用比较简单的特征,例如前一个词或前一个标签。然而,NER任务可能需要复杂的特征,例如词的词性,词的位置,以及词在句子中的其他词的关系等。这些特征无法直接在HMM中使用。
-
独立输出假设:HMM假设给定隐藏状态序列,观测状态(在NER任务中,这些可能是词)是独立的。这意味着它不能直接模拟词与词之间的依赖关系。然而,在实际文本中,词与词之间往往有强烈的依赖关系。
IO tagging
- 我们可以使用
IO tagging来解决上述的问题
在命名实体识别(Named Entity Recognition,NER)中,IO标注(IO Tagging)是一种常见的标注策略。在这种策略中,只有两种标签:I(Inside)和O(Outside)。 以下是它们的含义:
- “I”:表示该词是某个命名实体的一部分。
- “O”:表示该词不是任何命名实体的一部分。
比如在句子 “Apple is based in California” 中,如果我们的目标是识别组织名(ORG)和地名(GPE), 那么可能的IO标注就是 “I-ORG O O O I-GPE”。

- 但是 IO Tagging 的缺点就是:

- 这是因为 IO标注 无法标识一个实体的开始和结束。
- 举个例子,考虑这个句子:“Apple and Microsoft are tech companies.” 如果我们使用IO标注,那么“Apple and Microsoft”就会被标注为“I I I”,这样就无法确定“Apple”、“and”、“Microsoft”是一个实体还是三个实体。
- 同样,对于一个包含多个词的单一实体,如“San Francisco”,IO标注也会给出“I I”的标注,与上面的情况看起来是一样的,无法区分它们是一个实体还是两个实体。
IOB tagging

IOB(或BIO)标注(IOB Tagging)是一种常见的标注策略。在这种策略中,有三种标签:B(Begin),I(Inside),O(Outside)。以下是它们的含义:
- “B”: 表示该词是某个命名实体的开始。
- “I”: 表示该词是某个命名实体的一部分,但不是开始。
- “O”: 表示该词不是任何命名实体的一部分。
例如,在句子 “Apple is based in California” 中,如果我们的目标是识别组织名(ORG)和地名(GPE),那么可能的IOB标注就是 “B-ORG O O O B-GPE”。
相比IO标注策略,IOB标注策略可以更好地处理相邻的并且类型相同的命名实体。例如,在句子 “Apple and Google are tech companies” 中,“Apple” 和 “Google” 可以被分别标注为 “B-ORG” 和 “B-ORG”,从而区分为两个不同的实体。
- 也就是说,如果有两个相邻的实体名,而且这两个实体名如果是属于同一个实体比如
san francisco那么其中的san会被标注为B-ORG而francisco则会被标注为I-ORG这样来表示这两个属于同一个实体,而如果是两个不相关的实体,比如Microsoft Apple就会被标注为B-ORG和B-ORG表示两个不同的实体
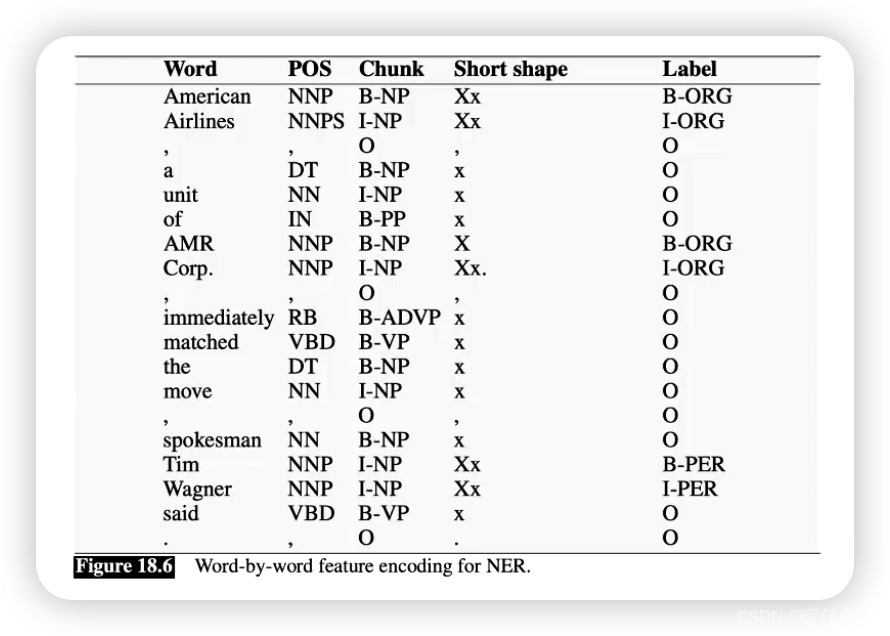
Steve Jobs founded Apple Inc. in 1976
Steve - B-PER
Jobs - I-PER
founded - O
Apple - B-ORG
Inc. - I-ORG
in - O
1976 - B-TIME


神经网络做 NER
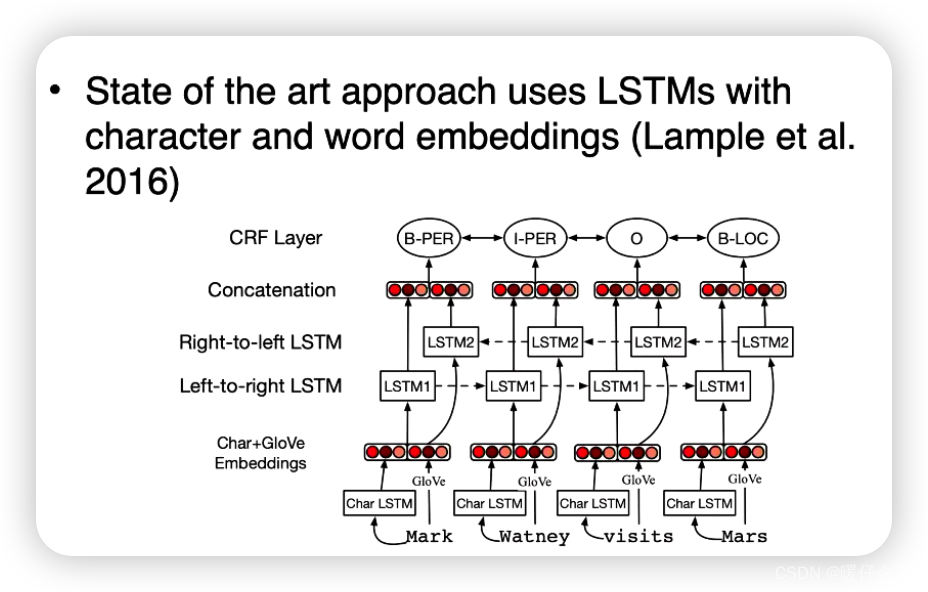
神经网络在命名实体识别(NER)任务中的应用已经取得了显著的成功。以下是一种常见的使用神经网络进行NER的方法:
-
预处理:将输入文本分割成单词或令牌(tokens)。可能需要做一些其他的预处理步骤,如小写化或词干化。
-
词嵌入:将每个单词转换为一个密集向量,这个向量可以捕获单词的语义信息。这可以通过使用预训练的词嵌入模型(如Word2Vec或GloVe)来完成。 预训练的模型已经在大量的文本上进行了训练,可以捕获到丰富的词汇知识。
-
序列编码:使用一种可以处理序列数据的神经网络模型,如循环神经网络(RNN)、长短期记忆(LSTM)或门控循环单元(GRU)等来处理词嵌入序列。这种模型可以捕获单词之间的顺序关系。
-
解码:对于每个单词,基于其上下文编码来预测其标签。这通常通过在序列编码的顶部添加一个全连接层和一个softmax函数来实现。 每个标签都会有一个softmax分数,表示该单词属于每个可能的实体类别的概率。
Relation Extraction
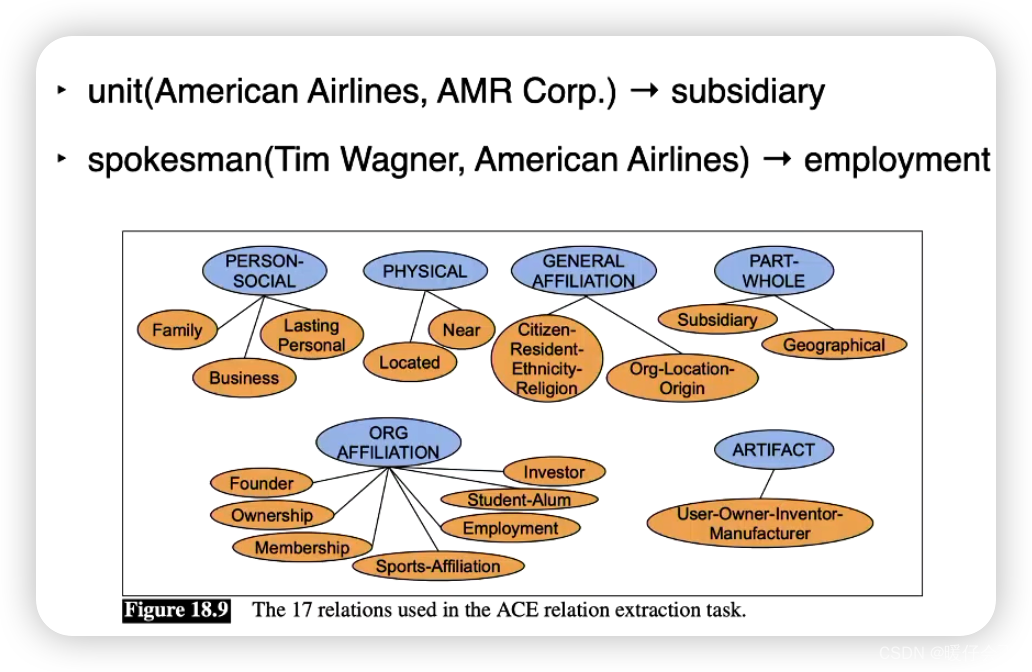
关系抽取(Relation Extraction)是自然语言处理(NLP)中的一个关键任务,其目标是从文本中识别并抽取出实体之间的预定义关系。 例如,在句子 “Barack Obama was born in Hawaii.” 中,我们可以抽取出关系 (“Barack Obama”, “born in”, “Hawaii”)。


Rule-based

Supervised Relation Extraction


- 这个例子中,由于我们已经通过 NER 确定出了所有的
entity,现在的任务是,将这些entity组合之后进行二分类,判断他们之间是不是有relation - positive 代表有关系,negative 代表没有
- 对于有关系的,我们再对关系进行分类


Semi-supervised

- 进行 supervised learning 需要的数据集需要大量标注,但是标注非常昂贵,因此可以使用半监督的方式,进行模型训练

它主要用于克服监督式关系抽取需要大量标注数据的问题。半监督关系抽取方法使用一小部分标注数据和大量未标注数据来进行训练。
一种常见的半监督关系抽取方法是自举(Bootstrapping)。自举方法一开始使用一小部分标注数据(种子实例)进行训练,然后使用训练好的模型去预测未标注数据中的关系。这些预测被认为是正确的,并添加到训练集中。然后,模型使用更新后的训练集进行再训练。这个过程反复进行,直到模型收敛或者达到预设的迭代次数。
例如,假设我们有一个种子实例 “Barack Obama was born in Hawaii”,我们可以首先训练一个模型来识别 "was born in" 这种关系。然后,我们使用这个模型去预测其他句子中的关系,如果模型预测 “Steve Jobs was born in San Francisco” 中存在 "was born in" 这种关系,那么我们就把这个实例添加到训练集中,然后进行再训练。
Semantic Drift 语义漂移
语义漂移(Semantic Drift)是一种在半监督学习中常见的问题,特别是在自举(Bootstrapping)过程中。这是因为在自举过程中,模型在每次迭代中都会通过将预测的实例添加到训练集中来更新它的训练数据。
语义漂移指的是当模型开始从初始种子实例中学习一种关系,然后逐渐开始学习到与初始关系不同的其他关系的情况。 这通常是由于模型预测错误导致的,即模型错误地认为一个实例表示了目标关系,并将其添加到训练集中,从而改变了训练数据的分布。
举个例子,假设我们在进行关系抽取的任务中,目标是找出 "was born in" 的关系。我们初始的种子实例可能是 “Steve Jobs was born in San Francisco”。然而,如果模型在某一次迭代中错误地将 “Apple was founded in Cupertino” 识别为 "was born in" 的关系并将其加入到训练集中,那么模型可能开始学习到 "founded in" 这种关系,这就产生了语义漂移。

Distant supervision 远程监督

远程监督(Distant Supervision)是一种用于关系抽取的弱监督学习方法。远程监督的核心思想是,如果两个实体在知识库(例如Freebase, Wikidata等)中存在某种关系,那么所有包含这两个实体的句子都可以被视为这种关系的实例。
例如,如果我们知道在知识库中,“Barack Obama” 和 “Hawaii” 之间有一个 “出生地” 的关系,那么任何提到 “Barack Obama” 和 “Hawaii” 的句子,如 “Barack Obama was born in Hawaii” 或者 “Hawaii is the birthplace of Barack Obama”,都可以被视为 “出生地” 关系的实例。
使用远程监督方法,我们可以从未标注的文本和知识库中自动构建大规模的关系抽取训练集。然而,远程监督方法也有一个显著的问题,即错误标注问题(也被称为远程监督假设的不足)。 因为并非所有包含两个有关系实体的句子都表示这种关系,这可能导致许多错误标注的实例。例如,句子 “Barack Obama went on vacation in Hawaii” 并不表示 “出生地” 的关系,但是在远程监督的假设下,它可能被错误地标注为一个 "was born in" 关系的实例。
Unsupervised Relation Extraction (“OpenlE”)

无监督的关系抽取(Unsupervised Relation Extraction),例如OpenIE (Open Information Extraction),是一种不依赖标记数据,直接从未标记的文本中抽取实体关系的方法。
OpenIE旨在从文本中抽取一种形式的 (subject, relation, object) 三元组。这种方法的优点是它可以抽取任意种类的关系,而不仅仅是预先定义好的关系类型。然而,这也意味着它可能抽取出大量不太有用的或者噪音较大的关系。
OpenIE的工作流程通常包括以下几个步骤:
-
句子分割和词语标注:首先,将文本分割成句子,并进行词性标注和命名实体识别。
-
句法解析:接着,对每个句子进行句法解析,通常是依存句法解析。
-
关系抽取:然后,根据句法解析的结果抽取出 (subject, relation, object) 三元组。通常,subject 和 object 是句子中的命名实体,relation 是它们之间的动词短语。
-
三元组筛选:最后,可以通过一些启发式规则或者基于学习的方法来筛选或者评分三元组,以提高结果的质量。
值得注意的是,OpenIE方法通常需要大量的计算资源,因为它需要处理大量的句子和句法解析树。此外,由于它的无监督性质,所以它的结果可能包含大量的噪音,需要后续的处理来提高可用性。
Evaluation

-
对于命名实体识别(NER)和关系抽取任务,常用的评估方法包括精确度(Precision)、召回率(Recall)和 F1 分数(F1-Score)。
-
这些指标都是基于真正例(True Positives,TP)、假正例(False Positives,FP)和假反例(False Negatives,FN)的概念来定义的。
-
对于关系抽取任务,评估时需要考虑实体对和它们的关系都正确才算预测正确。例如,如果一个关系是 (“Barack Obama”, “born in”, “Hawaii”),但模型预测的是 (“Barack Obama”, “live in”, “Hawaii”),那么这被视为一个错误的预测。
Other Information Extraction 任务
Temporal Expression Extraction

Event Extraction