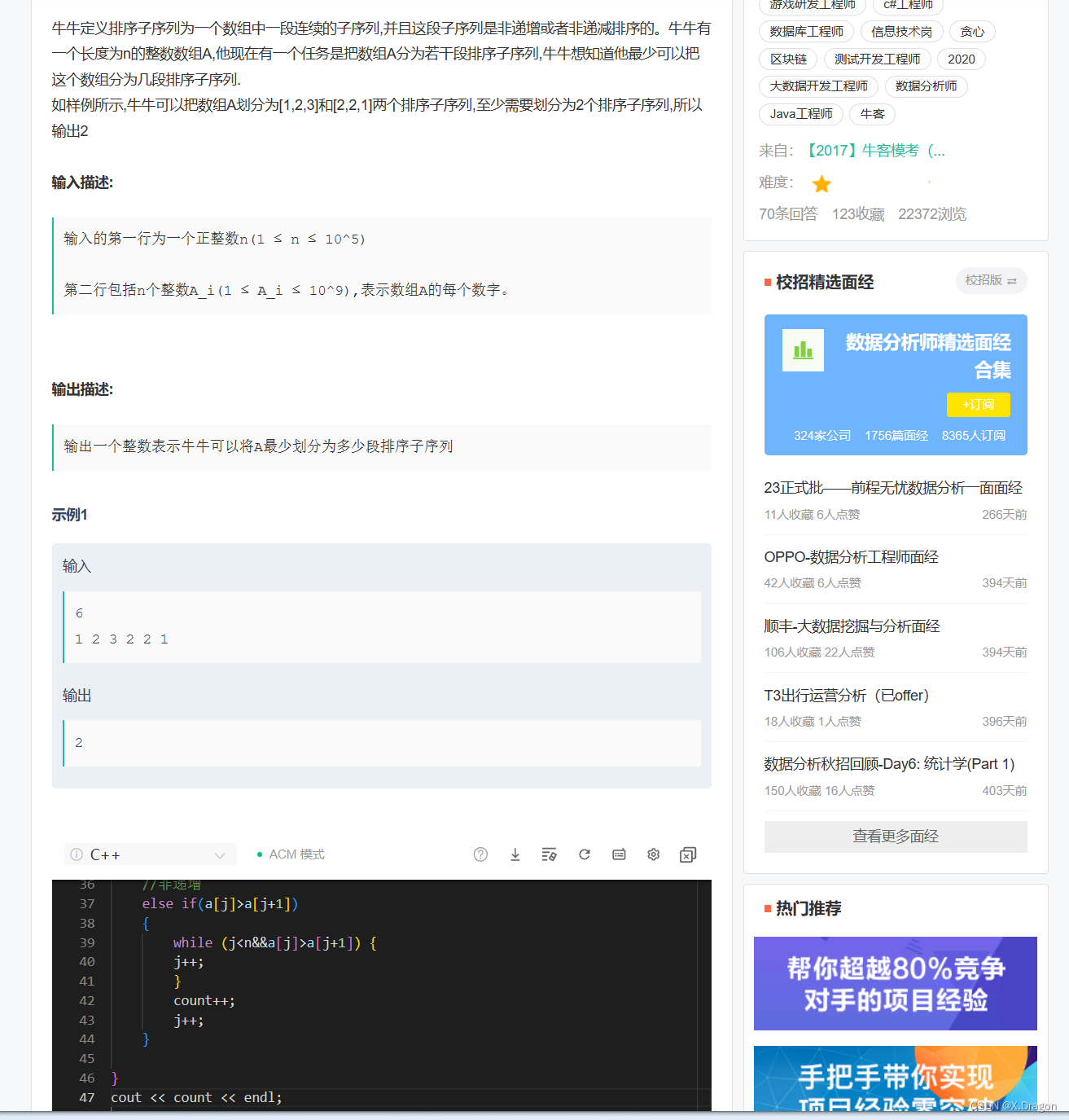
Bytebase 第一次完成融资后写了一篇文章,主要讲了从行业层面做 Bytebase 的逻辑。一年过去了,这一年我们所处的开源/infra/数据库/企业服务赛道从热点归于平静,尤其在国内,又习惯性地反应过度,直接降到冰点。但从全球来看,整体行业其实是在继续加速发展的,年初我们的一篇「苍狼白鹿,星霜几度|万字长文回顾 2022 年数据库行业」在中英文渠道都获得了不少的关注,而今年我们能写出的内容还能更加的丰富。而今天这篇文章想讲一段个人的经历,回到做 Bytebase 的初心。也算是到年底了,给这一年来支持我们的朋友和用户一份回顾和展望吧,Enjoy。
正文
2015 年某一天下午,Google 加州山景城总部 CL2 一楼,Google 云数据库工程团队所在地。彼时一个工程师正盯着屏幕,校对着一组亟待修复的数据库实例,准备采取下一步行动。「啪」,沐浴在加州阳光下的金手指敲下了按键,指令立马顺着 Google 错综复杂的网络,横穿大半个美国,飞奔到了千里之外的爱荷华数据中心。眼看着待办任务上又划掉了一项,工程师习惯性地往后靠了靠座椅。只是紧接着几秒之后,就看到他把头伸到了屏幕前,双眼瞪大,紧盯着眼前的文字:
Instance XXX has been successfully deleted.

升迁,跳槽,转行,这些都可以作为职业生涯的分割点。而对我来说,一个重要的分割点,就是 2015 年这个敲下指令的瞬间,因为在这一刻,我也不幸毕业,加入了误删过生产数据库的大军。多年以后,我依然能很清晰地回忆出之后的每一个行动细节,先是后背立马冒出冷汗,呆滞了几十秒的时间,脑海快速检索各种急救方案,无果之后,从工位起身,走到 TL 旁边,强装镇定地告诉对方自己刚误删了数据库。TL 沉思了片刻,然后说到,这个是有版本管理的,可以尝试恢复一下?我被一下子点醒,慌乱之中,居然忘了这套当年 Google 云创始团队写的基于 Bigtable 上的 Megastore 上的 VFS,存储性能虽然糟糕,但是实现了强悍的增量变更和版本化,所以撤销误删数据库,只要一个简单的版本回退,相当容易。

劫后余生后,可能伤疤也是战士的功勋章,我承担起了更多管理数据库的职责,再加上业务本身的发展,万级,十万级,一直到 2018 年离开 Google 的时候,我负责的已经是全球数一数二体量的数据库实例集群。而接下来的一站,则是回到中国,加入当时如日中天的蚂蚁金服,也延续我在 Google 的数据库老本行,负责蚂蚁内部的数据库平台。蚂蚁的数据库平台业务主要分为三块,一个是面向 DBA 的运维管理平台,一个是面向业务研发和 DBA 协同的开发者平台,还有一个是做数据库诊断的智能平台。通过这几个平台,收拢了所有蚂蚁内部开发者和 DBA 们对数据库的变更和运维操作。

虽然自己不再像在 Google 那样,在一线操作数据库,但压力却又高了一个数量级。毕竟负责的平台要保驾护航的,是那些支撑着支付宝,余额宝,花呗这些国民级应用的核心数据库。一开始加入时,团队同学先给我这个外来和尚科普了下国内等保的概念,然后指着屏幕上的数据库列表告诉我,看,这几个都是最高等保级别的,一定要好好看着,可都是能要了公司命的!到后来渐渐和大家混熟后,他们再给我讲当年出了严重的数据库事故后,7x24 连轴转,享受着全程被所有总裁们站在身后围观的待遇。

置身于这样的环境中,偶尔我也会产生一种似乎能手握着一家千亿美金估值公司命脉的错觉,但下一秒马上被钉钉里的告警通知拉回打工人的现实。蚂蚁的技术水位整体比不上 Google,但这套内部的数据库平台,有些方面却还是领先的(最近不又中了一篇 SIGMOD)。毕竟业务场景是工具平台最好的试炼,蚂蚁支撑的业务事关民生,金融,保险,蚂蚁在业务层面的创新力也强于 Google。数据库平台团队,每天就在被各种变态的业务场景蹂躏中走向成熟。但饶是如此,身为局中人,自己当然也知道平台本身的各种不完善。记得有一次线上 P1 故障,就是因为一个危险操作按钮,没有加二次确认,导致了 DBA 的误操作。蚂蚁内部的故障是要定责的,定责又是和绩效挂钩的。所以到了故障复盘会那天,业务方和数据库团队坐在一起,前面的基本都是铺垫,最后定责的那一刻才是高潮,开始互相甩锅。但锅总有甩不掉的时候,我在数据库团队呆了一年,而这一年里背的故障,比我其余整个职业生涯加起来的还要多。但当我告别团队的时候,却还是由衷地感谢大家,没有提前终结我在蚂蚁的生涯。
数据库团队之后,我被调去了开发者工具部门,后来又去了生产力协同平台。不同部门有各自的精彩和挑战,但在数据库团队时的压力无疑是最大的。在巨大的压力面前,会暴露出更真实的人性,有些是负面的,但也有不少的善意。比如我们和业务团队掰扯故障定责败了,就把故障带回到数据库团队内部消化。到了内部一切还是好商量的,DBA,平台,引擎这几块的主管在一起,盘一下身上已经背的故障,再结合今年团队的情况,匀一下。蚂蚁的技术在整个业界其实还是挺领先的,但是蚂蚁的业务总又是走在技术的前面,许多时候都是没条件先硬上。所以故障分完,马上大家都还是要背靠背去支援前线的业务。这样一年下来,数据库团队背的故障数总是遥遥领先。到了这里,就又体现了老板们的管理智慧,因为还是会给数据库团队一些照顾,如果真的按照故障数打绩效,那数据库团队基本就年年认领 3.25 了。

其实前面提到和业务团队开复盘会的互相甩锅也是调侃,身为平台技术团队的我们也知道,自己一开始 YY 出来的轮子都是方的,业务团队都是硬着头皮开着方轮子的车,踏上征途,再在旅程中一点点把轮子磨圆。一路颠簸,不时抛锚,偶尔翻车,但大家一边骂骂咧咧,一边还是一起把车扶起来,继续赶路。有人问我,国内做 infra 有什么优势,能想到的还是那服基建狂魔的祖传药方,场景多,人心齐,脑子活,干劲足。
没有圆模子的车间只能生产方的轮子,那就一边赶路一边把轮子磨圆,越磨越圆,纵情向前。
团队间日常撕的虽狠,但一起扛过了一场场硬仗,发现最终沉淀下的还是战友般的信任。大家团结一心,努力工作,为自己,为家庭,也为世界带来更多微小而美好的改变。支付宝,支托付,蚂蚁对内对外最强调的都是信任二字。确实只要信任的招牌不倒,队伍就能重新集结,业务一时被锤,也有重整的一天。
虽然我负责的业务没有被捶,但后来我还是从蚂蚁跑路了,因为自己想要做一款工具,就是 Bytebase。一直说做产品要从自身的痛点出发,光这点,Bytebase 是完美符合的。Bytebase 是一款面向研发和 DBA 协同的数据库开发者工具,放眼整个业界,这也是一个新品类,因为是我从蚂蚁三段跨界经历,数据库,开发者工具,生产力协同中提炼出来的。但说到底这还是一个数据库领域专业性很强的工具,而设计内核基于的是在 Google 以及蚂蚁数据库团队经历的痛点。
把这个设计内核掰开来看就是两半,一半是 Care,一半是 Fear。
Care 的部分,在于我看到但凡要和数据库打交道的一线同学,无论是业务研发还是 DBA,都有点像部队里扫雷的工兵,任务风险高,但部队要推进,又不得不做。Google,蚂蚁的工兵装备倒是挺完善了,虽然也是险象丛生,但踩雷了还能幸存。但其他公司,扫雷的任务还是要做,可是又没有基本的作业装备,那我希望 Bytebase 就能成为他们的出门装备,帮助他们高效安全地作业。 Fear 的部分,在于我身为技术负责人,也害怕数据库误操作导致的毁灭性打击。我在 Google 算是逃过一劫,但是每当想起,我还是会后怕,假设那个数据库真的被删掉无法恢复了,对于我自己,我的主管,整个产品甚至公司品牌会带来多大的负面影响。在蚂蚁数据库团队,所幸团队给力,否则也有可能因为数据库误操作引发公共事件,而我作为主管,也很可能要承担责任,被扫地出门。有经验的技术负责人一定是希望尽量统一数据库操作入口,数据库规范和操作变更流程的,以避免诸如 #删库跑路 导致的团灭。所以对于技术负责人,我也希望 Bytebase 能成为落地他们这些想法的工具。

而说到 #删库跑路,它之所以能成为梗甚至破圈,也是因为它能先在广大程序员群体产生共情,因为有经验的程序员都知道带上#删库跑路的徽章是一个概率事件,要做的就是如何把这个风险降到尽可能的低:
- 个人养成良好的操作习惯,降低 20% 概率
- 公司建立标准化的操作流程及培训体系,降低 20% 概率
- 技术架构简单,降低 20% 概率
- 文档清晰,降低 20% 概率
而通过引入专业的数据库开发工具,把理念和流程通过工具进行承载,减少甚至完全避免手工直接操作数据库的机会,则又能降低至少 50% 的概率。

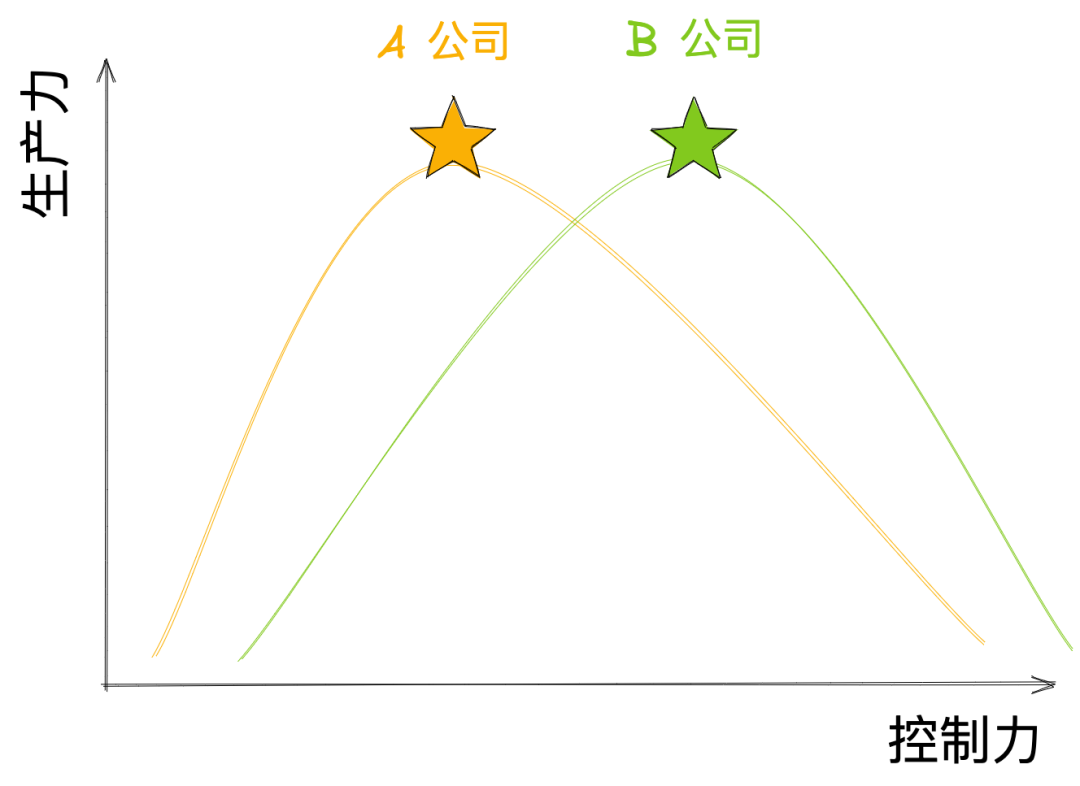
而说到引入工具,我在蚂蚁的平台部门,无论是做数据库工具,开发者工具还是协同工具,当把新工具推广到业务线的时候,总是会迎来反弹。一线的业务研发总会觉得,前线业务已经忙不过来了,平台部门又在搞什么幺蛾子来卡我们。现实中,许多被引入的平台工具确实是只重视了管控,但忽略了一线的使用感受,反而拖累了整体的生产力。 所以当我们在设计 Bytebase 的时候,最核心的任务是去做中央管控和业务线灵活度之间的平衡。用户引入 Bytebase 的目的是希望提高全局的总生产力,所以管控/流程这些都是需要的,但不同公司达到最高生产力的控制点是不一样的,所以 Bytebase 也留了一定的调节空间,让不同公司可以做不同的配置。
同行还有投资人常会问我 2 个问题
- Bytebase 这个场景很窄,为什么选了它 - 这个问题,说服有难度,因为没有相似的经历可以共情。Bytebase 的初心,既始于我带着一线研发帽子的 care,也源自我换成技术主管帽子的 fear,两者交织起来,点燃了内心冲动的 flare。
- Bytebase 这个东西国外没有对标,为什么你们能做 - 这个问题,我其实也反感回答。因为对方直接上来假设了 infra 类工具只有国外团队可以无中生有,却忽略了我们团队已被国内外最严苛场景千锤百炼的事实。
限制中国 infra 团队走向全球的往往不是客观的条件,而是主观的成见。
从 Google 删库,到蚂蚁跑路,这一串的经历不仅赋予了我设计 Bytebase 的思路,也给了我足够的底气。因为我知道整个数据库开发工具领域目前的上限在哪里,Google 也不是在所有地方做的都是最好的,蚂蚁和阿里也有不少走在业界的最前沿。
而中西合璧的 Bytebase 还能把整个领域带到一个新的高度,帮助全球不同的团队在他们各自的倒 V 型曲线上,找到数据库开发生产力的最高点。
Stay young, be simple, sometimes naive.

💡 你可以访问官网,免费注册云账号,立即体验 Bytebase。