目录
- ElasticSearch安装与介绍
- Elastic Stack简介
- Elasticsearch
- Logstash
- Kibana
- Beats
- ElasticSearch快速入门
- 简介
- 下载
- 单机版安装
- 启动ElasticSearch
- 错误分析
- 错误情况1
- 错误情况2
- 错误情况3
- ElasticSearch-Head可视化工具
- 通过Docker方式安装
- 通过Chrome插件安装
- ElasticSearch中的基本概念
- 索引
- 文档
- 映射
- 文档类型
- RESTful API
- 创建非结构化索引
- 创建空索引
- 删除索引
- 插入数据
- 更新数据
- 删除索引
- 搜索数据
- 根据id搜索数据
- 搜索全部数据
- 关键字搜索数据
- DSL搜索
- 全文搜索
- 聚合
ElasticSearch安装与介绍
Elastic Stack简介
如果你没有听说过Elastic Stack,那你一定听说过ELK,实际上ELK是三款软件的简称,分别是Elasticsearch、Logstash、Kibana组成,在发展的过程中,又有新成员Beats的加入,所以就形成了Elastic Stack。所以说,ELK是旧的称呼,Elastic Stack是新的名字。

全系的Elastic Stack技术栈包括:
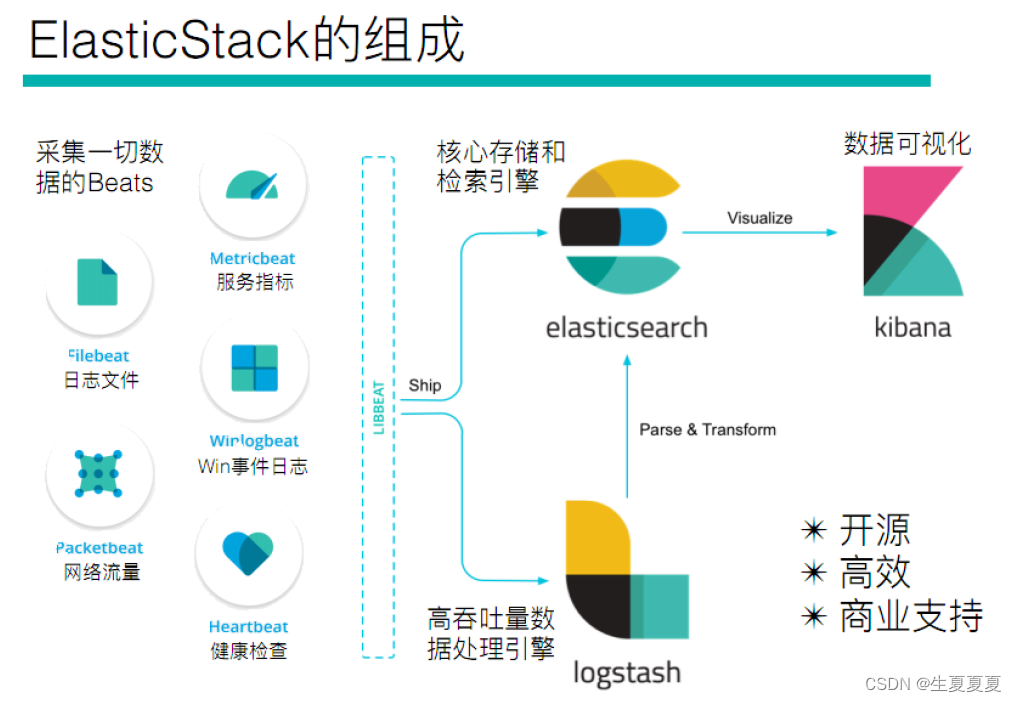
Elasticsearch
基于java,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
Logstash 基于java,是一个开源的用于收集,分析和存储日志的工具。
Kibana
Kibana 基于nodejs,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch
提供的日志分析友好的Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
Beats是elastic公司开源的一款采集系统监控数据的代理agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动。
Beats由如下组成:
- Packetbeat:是一个网络数据包分析器,用于监控、收集网络流量信息。
- Filebeat:用于监控、收集服务器日志文件。
- Metricbeat:可定期获取外部系统的监控指标信息,其可以监控、收集 Apache、 MySQL、Nginx、等服务;
Beats和Logstash其实都可以进行数据的采集,但是目前主流的是使用Beats进行数据采集,然后使用 Logstash进行数据的分割处理等,早期没有Beats的时候,使用的就是Logstash进行数据的采集。
ElasticSearch快速入门
简介
官网
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
ElasticSearch是Elastic Stack的核心,同时Elasticsearch 是一个分布式、RESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
下载
到官网下载: Elastic
选择对应版本的数据,这里我使用的是Linux来进行安装,所以就先下载好ElasticSearch的Linux安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.8.0-linux-x86_64.tar.gz
单机版安装
因为ElasticSearch不支持Root用户直接操作,因此我们需要创建一个es用户
# 添加新用户
useradd es
# 创建elk目录
cd /opt/elk
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.8.0-linux-x86_64.tar.gz
# 解压缩
tar -zxvf elasticsearch-8.8.0-linux-x86_64.tar.gz
#重命名
mv elasticsearch-8.8.0 elsearch
因为刚刚我们是使用root用户操作的,所以我们还需要更改一下/soft文件夹的所属,改为es用户
chown es.es /opt/elk -R
然后在切换成es用户进行操作
# 切换用户
su - es
然后我们就可以对我们的配置文件进行修改了
# 进入到 elsearch下的config目录
cd /opt/elk/elsearch/config
然后找到下面的配置
#打开配置文件
vim elasticsearch.yml
#设置ip地址,任意网络均可访问
network.host: 0.0.0.0
#关闭安全功能
xpack.security.enable: true ==> xpack.security.enable: false
在Elasticsearch中如果,network.host不是localhost或者127.0.0.1的话,就会认为是生产环境,会对环境的要求比较高,我们的测试环境不一定能够满足,一般情况下需要修改2处配置,如下:
# 修改jvm启动参数
vim conf/jvm.options
#根据自己机器情况修改
-Xms128m
-Xmx128m
然后在修改第二处的配置,这个配置要求我们到宿主机器上来进行配置
# 到宿主机上打开文件
vim /etc/sysctl.conf
# 增加这样一条配置,一个进程在VMAs(虚拟内存区域)创建内存映射最大数量
vm.max_map_count=655360
# 让配置生效
sysctl -p
启动ElasticSearch
首先我们需要切换到 elsearch用户
su - es
然后在到bin目录下,执行下面
# 进入bin目录
cd /opt/elk/elsearch/bin
# 后台启动
./elasticsearch -d
启动成功后,访问下面的URL
http://192.168.40.150:9200/
如果出现了下面的信息,就表示已经成功启动了
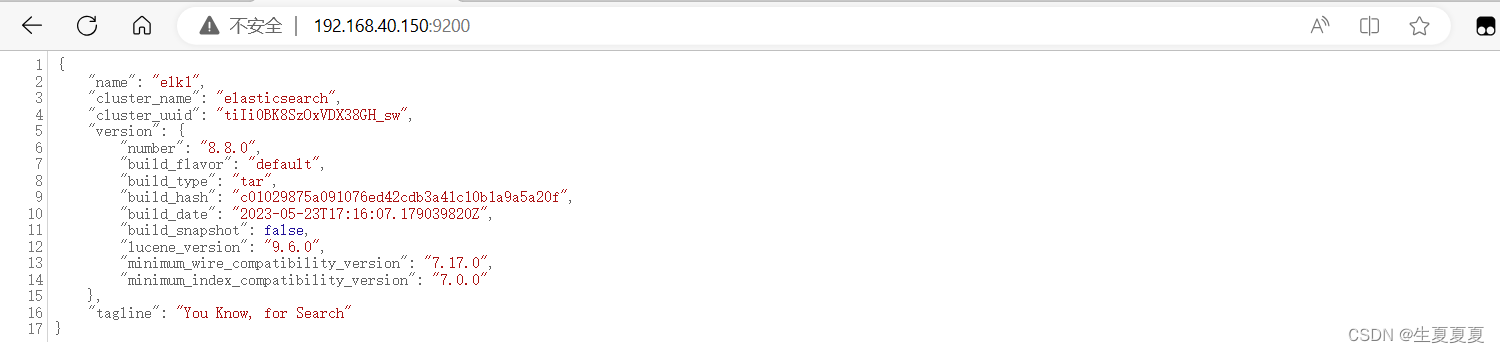
如果你在启动的时候,遇到过问题,那么请参考下面的错误分析~
错误分析
错误情况1
如果出现下面的错误信息
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:111)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:178)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:393)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:127)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)
For complete error details, refer to the log at /soft/elsearch/logs/elasticsearch.log
[root@e588039bc613 bin]# 2020-09-22 02:59:39,537121 UTC [536] ERROR CLogger.cc@310 Cannot log to named pipe /tmp/elasticsearch-5834501324803693929/controller_log_381 as it could not be opened for writing
2020-09-22 02:59:39,537263 UTC [536] INFO Main.cc@103 Parent process died - ML controller exiting
就说明你没有切换成 elsearch用户,因为不能使用root操作
su - elsearch用户
错误情况2
[1]:max file descriptors [4096] for elasticsearch process is too low, increase to at least[65536]
解决方法:切换到root用户,编辑limits.conf添加如下内容
vi /etc/security/limits.conf
# ElasticSearch添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
错误情况3
[2]: max number of threads [1024] for user [elsearch] is too low, increase to at least
[4096]
也就是最大线程数设置的太低了,需要改成4096
#解决:切换到root用户,进入limits.d目录下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf
#修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
ElasticSearch-Head可视化工具
由于ES官方没有给ES提供可视化管理工具,仅仅是提供了后台的服务,elasticsearch-head是一个为ES开发的一个页面客户端工具,其源码托管于Github,地址为 传送门
head提供了以下安装方式
- 源码安装,通过npm run start启动(不推荐)
- 通过docker安装(推荐)
- 通过chrome插件安装(推荐)
- 通过ES的plugin方式安装(不推荐)
通过Docker方式安装
#拉取镜像
docker pull salgat/elasticsearch-head
#启动容器
docker run -d --name elasticsearch-head -p 9100:9100 salgat/elasticsearch-head
注意:
由于前后端分离开发,所以会存在跨域问题,需要在服务端做CORS的配置,如下:
vim elasticsearch.yml
# 新加
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
通过chrome插件的方式安装不存在该问题
通过Chrome插件安装
打开chrome的应用商店,即可安装 传送门

我们也可以新建索引
建议:推荐使用chrome插件的方式安装,如果网络环境不允许,就采用其它方式安装。
ElasticSearch中的基本概念
索引
- 索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。
- 可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
- Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
文档
-
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
-
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。
每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。
映射
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射(mapping),一般由用户自己定义规则。
文档类型
- 在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。
- 每个文档可以有不同的结构。
- 不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型。
RESTful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
创建非结构化索引
在Lucene中,创建索引是需要定义字段名称以及字段的类型的,在Elasticsearch中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在Elasticsearch底层会进行结构化操作,此操作对用户是透明的。
创建空索引
PUT /haoke
{
"settings": {
"index": {
"number_of_shards": "2", #分片数
"number_of_replicas": "0" #副本数
}
}
}
删除索引
#删除索引
DELETE /haoke
{
"acknowledged": true
}
插入数据
URL规则:
POST /{索引}/{类型}/{id}
POST /haoke/_doc/1001
#数据
{
"id":1001,
"name":"张三",
"age":20,
"sex":"男"
}
使用谷歌插件advanced reset client操作成功后
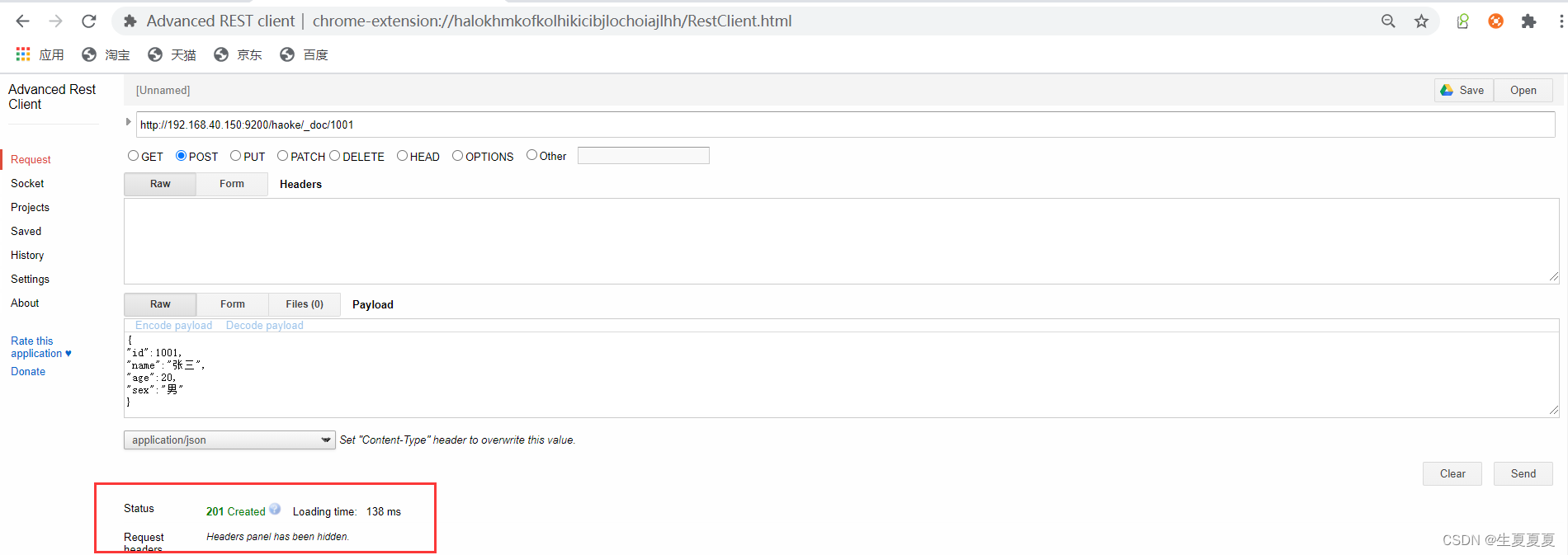
我们通过ElasticSearchHead进行数据预览就能够看到我们刚刚插入的数据了
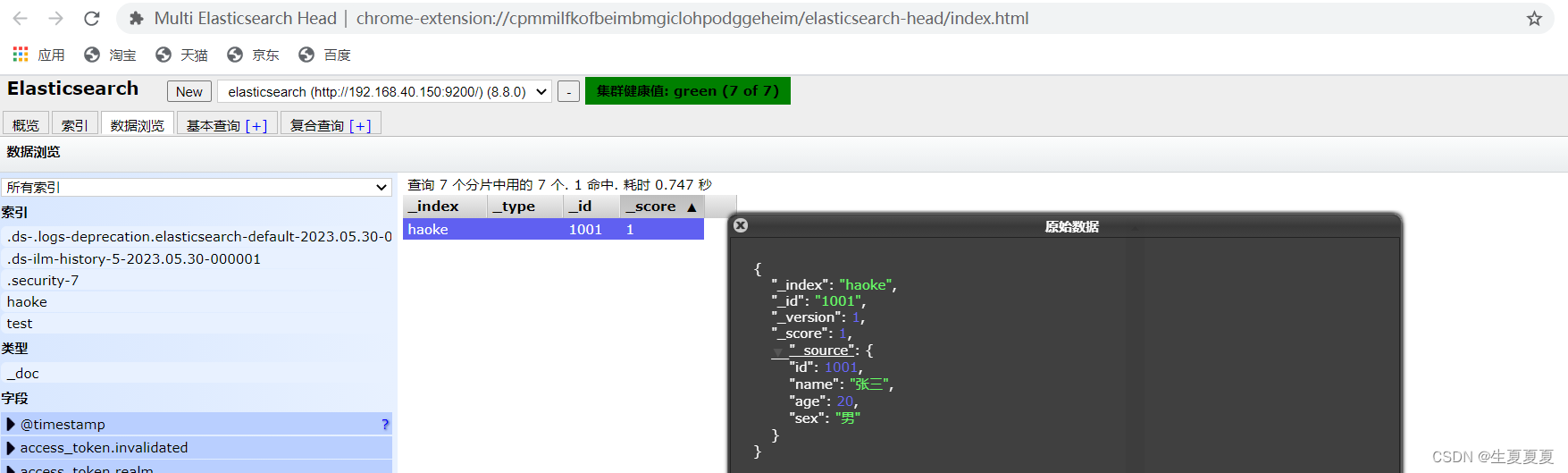
说明:非结构化的索引,不需要事先创建,直接插入数据默认创建索引。
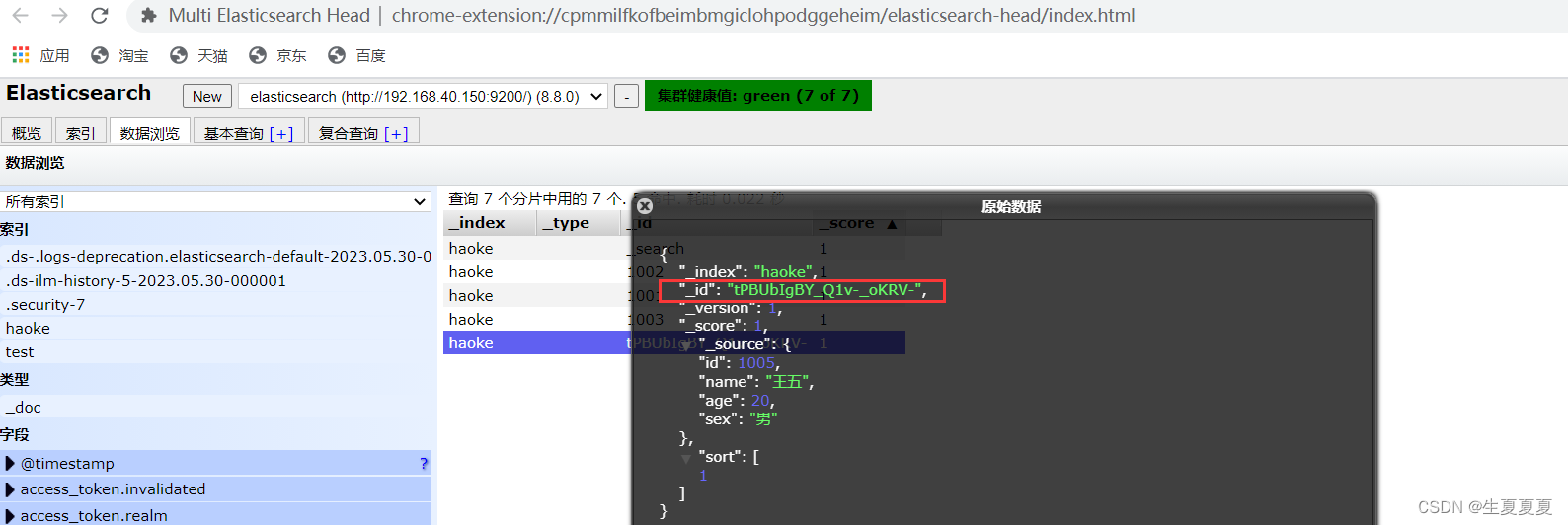
不指定id插入数据:
更新数据
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新。
PUT /haoke/_doc/1001
{
"id":1001,
"name":"大漂亮",
"age":21,
"sex":"女"
}
更新结果如下:
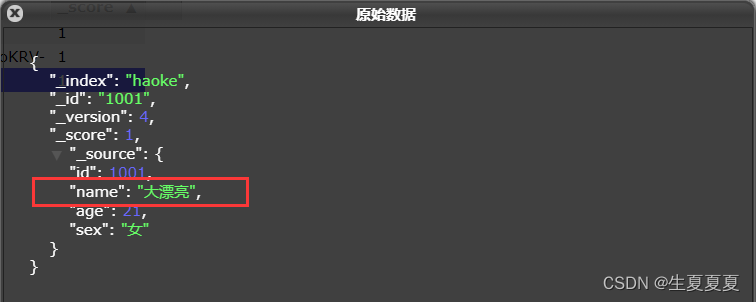
可以看到数据已经被覆盖了。问题来了,可以局部更新吗? – 可以的。前面不是说,文档数据不能更新吗?
其实是这样的:在内部,依然会查询到这个文档数据,然后进行覆盖操作,步骤如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
#注意:这里多了_update标识
POST /haoke/_update/1001
{
"doc":{
"age":66
}
}

可以看到,数据已经是局部更新了
删除索引
在Elasticsearch中,删除文档数据,只需要发起DELETE请求即可,不用额外的参数
DELETE /haoke/_doc/1001

如果删除一条不存在的数据,会响应404
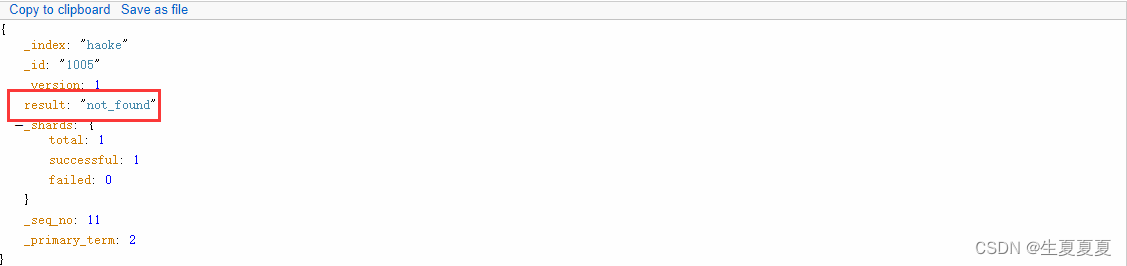
删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。【相当于批量操作】
搜索数据
根据id搜索数据
GET /haoke/_doc/tPBUbIgBY_Q1v-_oKRV-
#返回的数据如下
{
_index: "haoke"
_id: "tPBUbIgBY_Q1v-_oKRV-"
_version: 1
_seq_no: 4
_primary_term: 1
found: true
_source: {
id: 1005
name: "王五"
age: 20
sex: "男"
}-
}
搜索全部数据
GET /haoke/_search
注意,使用查询全部数据的时候,默认只会返回10条

关键字搜索数据
#查询年龄等于20的用户
GET /haoke/_search?q=age:20
结果如下:

DSL搜索
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
POST /haoke/_search
#请求体
{
"query" : {
"match" : { #match只是查询的一种
"age" : 20
}
}
}
实现:查询年龄大于30岁的男性用户。
POST /haoke/user/_search
#请求数据
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"must": {
"match": {
"sex": "男"
}
}
}
}
}
查询出来的结果

全文搜索
POST /haoke/_search
#请求数据
{
"query": {
"match": {
"name": "lh ttd lyj"
}
}
}

高亮显示,只需要在添加一个 highlight即可
POST /haoke/_search
#请求数据
{
"query": {
"match": {
"name": "lh"
}
}
"highlight": {
"fields": {
"name": {}
}
}
}

聚合
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
POST /haoke/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}
结果如下,我们通过年龄进行聚合

从结果可以看出,年龄20的有2条数据,21、35、50、80的各有一条数据。