目的
checkpoint作为flink保障任务稳健运行的一个重要机制,在日常使用和flink
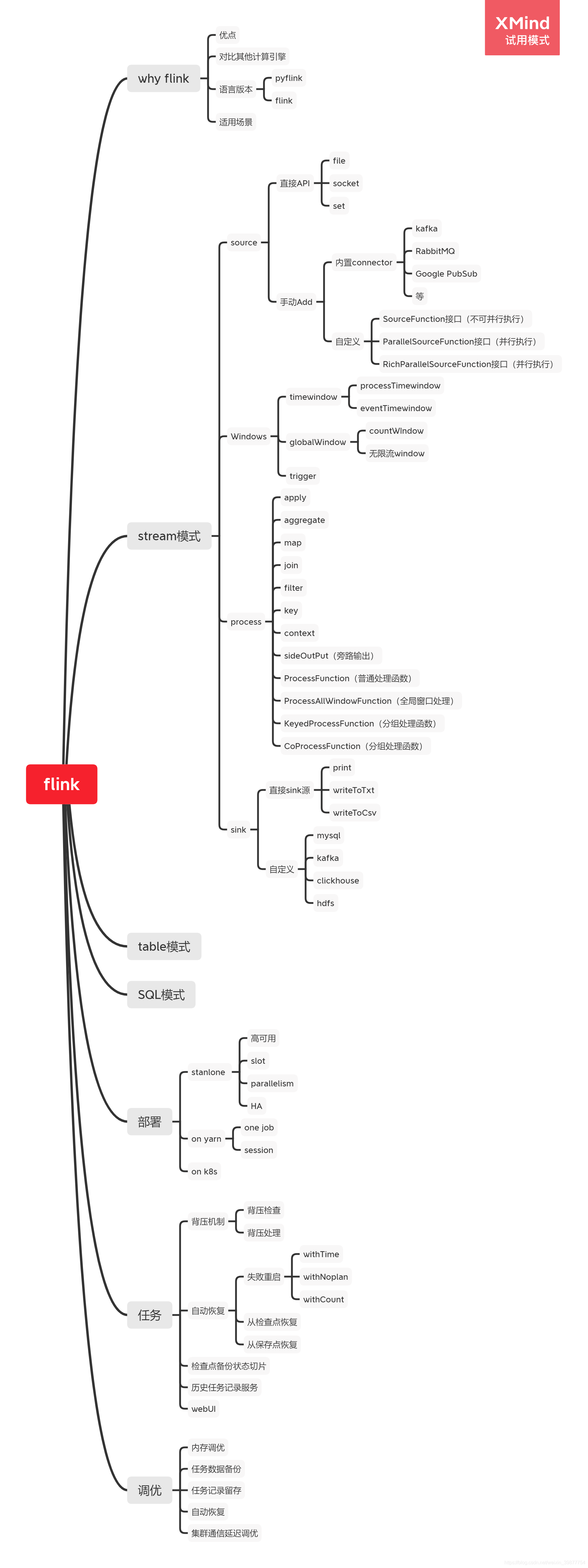
学习框架图
简单创建一个FlinkKafkaConsumer
kafka是大数据中常用的消息存储中间件,也是flink任务中最常用的source源之一,因此flink 也为 kafka提供了内置的连接接口 FlinkKafkaConsumer。flink可以在FlinkKafkaConsumer上配合check point 机制实现了exactly one模式,其中的使用逻辑与我们常用搞得kafka消费者不同。
创建一个FlinkKafkaConsumer:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "cdh3:9092, cdh4:9092, cdh5:9092"); # 设置
properties.setProperty("group.id", "cliu01"); # 设置kafka的消费组
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("userCenterUserInfo", new SimpleStringSchema(), properties);FlinkKafkaConsumer的运行模式
1. setStartFromEarliest -> 从最早的数据消费:
说明:直接从连接的kafka集群中可读数据中offset最小的那条数据开始读取。(通常来说就是kafka未被清楚数据中最早的那条开始读取处理)
模式选用示例:
kafkaConsumer.setStartFromEarliest();2. setStartFromSpecificOffsets -> 从指定的偏移量开始消费数据:
说明:比较常用的一种模式,指定kafka集群上每个提供服务的节点 对应的起始偏移量。flink将从各个节点的指定偏移量进行数据读取。
获取某个消费组当前在kafka的消费位置,可以在公司提供的kafka运维工具上查看 或者在kafka的集群上执行以下命令(从其他kafka命令介绍的博客薅的示例):
kafka-consumer-groups.sh --bootstrap-server master:9092 --describe --group {你的消费组名称}结果如下:
current-offset:表示kafka集群记录到的消费组当前消费到的位置。
log-end-offset:表示kafka集群接收到的所有消息的偏移量。
lag:当前消费组的数据积压情况。(log-end-offset 减去 current-offset )
模式选用示例:
Map<KafkaTopicPartition, Long> kafkaOffsetInfo = new HashMap(){{
put(new KafkaTopicPartition("topic名称", 分片Id1), 分片Id1上的偏移量信息);
put(new KafkaTopicPartition("topic名称", 分片Id2), 分片Id2上的偏移量信息);
put(new KafkaTopicPartition("topic名称", 分片Id3), 分片Id3上的偏移量信息);
}};
kafkaConsumer.setStartFromSpecificOffsets(kafkaOffsetInfo);
3.setStartFromGroupOffsets -> 从消费组的偏移量开始消费
说明:flink开启检查点之后默认的消费模式。因为kafka的二段提交机制,通常在启用checkpoint功能的flink任务的消费组偏移量 等于 flink生成检查点时的偏移量。所以该模式等价于从上个保存成功的检查点时的消费位置进行消费。
示例:
kafkaConsumer.setStartFromGroupOffsets();
4.setStartFromTimestamp -> 从指定时间戳之后消费数据
说明:指定的时间戳需要比当前时间迟,通常在指定时间进行项目上线的时候进行使用。是kakfa自带的消费模式。
示例:
kafkaConsumer.setStartFromTimestamp(1621872000000L); #毫秒时间戳 从kafka在2021-05-25 00:00:00之后接收到的数据开始消费 5.setStartFromLatest -> 从最新位置消费数据
说明:无
示例:
kafkaConsumer.setStartFromLatest();预告
接下会更新flink的exactly-once精准一次是如何实现的。









![[游戏开发]Unity多边形分割为三角形_耳切法](https://img-blog.csdnimg.cn/b86c110722c545159014f12e409ae1a3.png)

