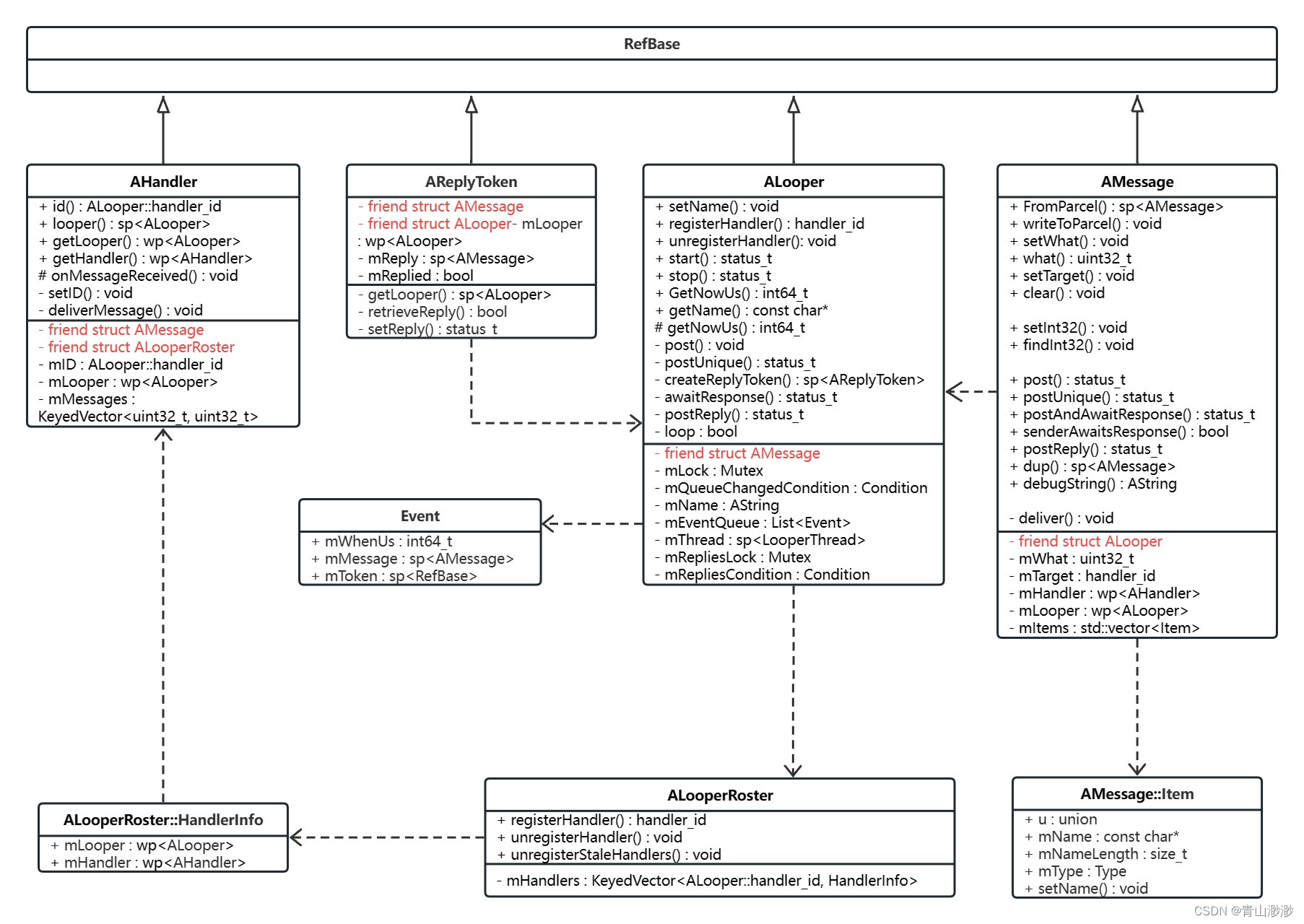
mysql select执行流程如图所示

server侧
在8.0之前server存在查询语句对应数据的缓存,不过在实际使用中比较鸡肋,对于更新比较频繁、稍微改点查询语句都会导致缓存无法用到
解析
解析sql语句为mysql能够直接执行的形式。通过词法分析识别表名、字段名等关键字,语法分析判断是否满足mysql语法
执行
-
预处理阶段
- 检查语句表、字段是否存在
- 拓展*符号为所有列
-
优化阶段
确定执行计划,依据最小IO、CPU成本来进行选择最优的索引、表关联顺序以及尝试优化where子句
-
执行阶段
负优化的情况
- 统计信息不完整或者不准确。比如mysql mvcc可能会导致表行统计不准确
- 执行计划成本不等同于实际执行成本。比如说虽然某执行计划要读取非常多的页面数据,但是可能这些数据已经在内存里面了,那么实际成本反而更低
- mysql最优与开发者最优可能存在偏差。比如开发者希望执行时间越短越好,可是mysql只是基于其成本模型去选择
- 不考虑其他并发执行查询
- 存在固定规则
- 不考虑不受其控制的操作成本。比如自定义函数
- 有时候无法估算所有可能的执行计划
主键查询执行
对于语句SELECT * FROM t WHERE id = 1
- 根据优化器选择的const访问类型调用innodb引擎接口
- 引擎找不到主键id=1的记录,就会报错
- 若能找到就会交给执行器,执行器判断是否符合查询条件,如果符合就会发送客户端,不符合就跳过该记录
全表扫描执行
对于语句SELECT * FROM t WHERE name = 'apple'
- 根据优化器选择的all访问类型调用引擎接口
- 引擎全表扫描,读取记录交给server判断是否符合条件,符合条件server就会将记录发送客户端(客户端等待所有记录到达之后才会显示)
- 直到所有记录扫描完毕
索引下推执行
索引下推能减少二级索引查询的回表操作
对于联合索引a、b,有语句SELECT * FROM t WHERE a > 1 AND b = 2
- server调用引擎定位到第一条a>1的数据
- 引擎直接判断(而不是交给server判断)该数据是否b=2,若不满足,跳过;满足,直接返回给server
innoDB侧

缓存查询
在innoDB中存在buffer pool进行缓存表和索引数据。在查询中会检查查询的数据是否存在buffer pool,若存在直接返回,若不在则会继续查询
磁盘查询
如果是索引查询,那就按照B+树查询方式进行查询。如果是全表扫描,那就取出所有数据
Ref
- https://xiaolincoding.com/mysql/base/how_select.html
- https://pdai.tech/md/db/sql-mysql/sql-mysql-execute.html
- https://www.cnblogs.com/hoxis/p/10006871.html
- https://maimai.cn/article/detail?fid=1764866067&efid=0JFLnz3d_OGsnu4PbEUkFA
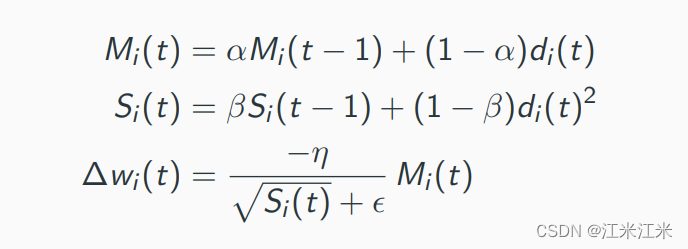




![[游戏开发]Unity多边形分割为三角形_耳切法](https://img-blog.csdnimg.cn/b86c110722c545159014f12e409ae1a3.png)