作者:猛码Memmat
目录
- Abstract
- 1. Introduction
- Task
- Model
- Data engine
- Dataset
- Responsible AI
- Experiments
- Release
- 2. Segment Anything Task
- Task
- Pre-training
- Zero-shot transfer
- Related tasks
- Discussion
- 3. Segment Anything Model
- Image encoder
- Prompt encoder
- Mask decoder
- Resolving ambiguity
- Efficiency
- Losses and training
- 4. Segment Anything Data Engine
- Assisted-manual stage
- Semi-automatic stage
- Fully automatic stage
- 5. Segment Anything Dataset
- Images
- Masks
- Mask quality
- Mask properties.
- 6. Segment Anything RAI Analysis
- Geographic and income representation
- Fairness in segmenting people
- 7. Zero-Shot Transfer Experiments
- Implementation
- 7.1 Zero-Shot Single Point Valid Mask Evaluation
- Task
- Datasets
- Results
- 7.2 Zero-Shot Edge Detection
- Approach
- Results
- 7.3 Zero-Shot Object Proposals
- Approach
- Results
- 7.4 Zero-Shot Instance Segmentation
- Approach
- Results
- 7.5 Zero-Shot Text-to-Mask
- Approach
- Results
- 7.6 Ablations
- 8. Discussion
- Foundation models
- Compositionality
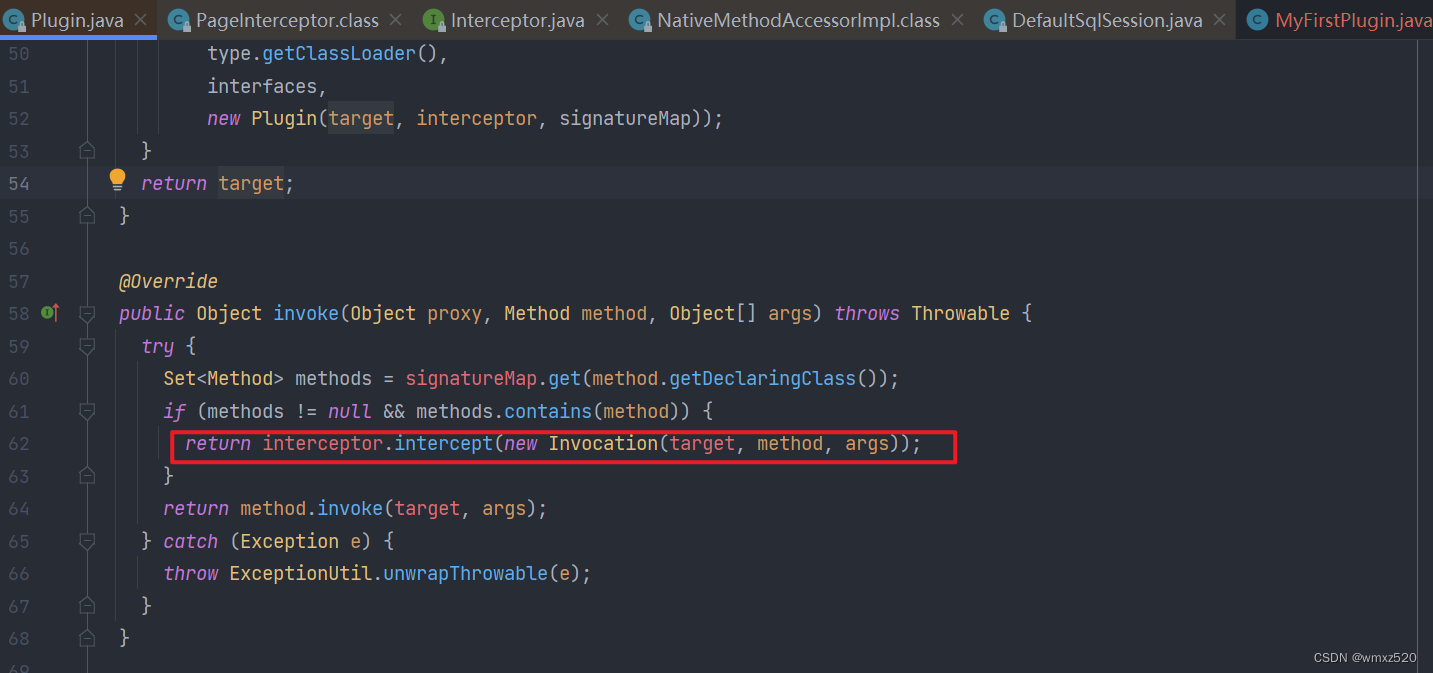
- Limitations
- Conclusion
- Acknowledgments
- References
- Appendix
- A. Segment Anything Model and Task Details
- Image encoder
- Prompt encoder
- Lightweight mask decoder
- Making the model ambiguity-aware
- Losses
- Training algorithm
- Training recipe
- B. Automatic Mask Generation Details
- Cropping
- Filtering
- Postprocessing
- Automatic mask generation model
- SA-1B examples
- C. RAI Additional Details
- Inferring geographic information for SA-1B
- Inferring geographic information for COCO and Open Images.
- Inferring income information
- Fairness in segmenting people
- Fairness in segmenting clothing
- D. Experiment Implementation Details
- D.1. Zero-Shot Single Point Valid Mask Evaluation
- Datasets
- Point sampling
- Evaluation
- Baselines
- Single point ambiguity and oracle evaluation
- D.2. Zero-Shot Edge Detection
- Dataset and metrics
- Method
- Visualizations
- D.3. Zero-Shot Object Proposals
- Dataset and metrics
- Baseline
- Method
- D.4. Zero-Shot Instance Segmentation
- Method
- D.5. Zero-Shot Text-to-Mask
- Model and training
- Generating training prompts
- Inference
- D.6. Probing the Latent Space of SAM
- E. Human Study Experimental Design
- Models
- Datasets
- Methodology
- Results
- F. Dataset, Annotation, and Model Cards
- F.1. Dataset Card for SA-1B
- F.2. Data Annotation Card
- G. Annotation Guidelines

Abstract

the largest segmentation dataset to date (by far)
我们介绍了Segment Anything (SA)项目:一个用于图像分割的新任务、模型和数据集。在数据收集循环中使用我们高效的模型,我们构建了迄今为止(到目前为止)最大的分割数据集,在1100万张授权和隐私尊重的图像上拥有超过10亿个面具。该模型被设计和训练为可提示的,因此它可以将zero-shot转移到新的图像分布和任务。我们评估了它在许多任务上的能力,发现它的零镜头表现令人印象深刻——经常与之前的完全监督结果竞争,甚至更好。我们在https://segment-anything.com上发布了片段任何模型(SAM)和对应的1B掩模和11M图像数据集(SA-1B),以促进对计算机视觉基础模型的研究。
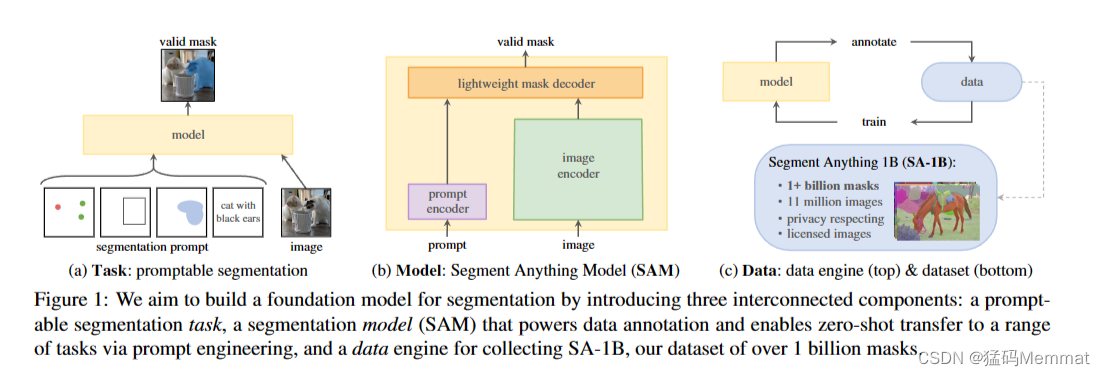
我们的目标是通过引入三个相互连接的组件来构建一个分割的基础模型:一个提示分割任务,一个分割模型(SAM),它为数据注释提供动力,并通过提示工程实现零镜头传输到一系列任务,以及一个用于收集SA-1B的数据引擎,我们的数据集超过10亿个掩码。
1. Introduction



在网络规模的数据集上预训练的大型语言模型正在以强大的零次和少次泛化彻底改变NLP。这些“基础模型”[8]可以泛化到训练过程中看不到的任务和数据分布。这种功能通常通过提示工程实现,在提示工程中,使用手工制作的文本提示语言模型为手头的任务生成有效的文本响应。当使用来自网络的丰富文本语料库进行缩放和训练时,这些模型的零镜头和少镜头性能与相比惊人地好(甚至在某些情况下匹配)微调模型[10,21]。经验趋势表明,这种行为随着模型规模、数据集大小和总训练计算而改善[56,10,21,51]。
基础模型也在计算机视觉中进行了探索,尽管程度较轻。也许最突出的插图是对齐来自网络的配对文本和图像。例如,CLIP[82]和ALIGN[55]使用对比学习来训练对齐两种模式的文本和图像编码器。经过训练后,经过设计的文本提示可以实现对新颖视觉概念和数据分布的零概率泛化。这样的编码器还可以有效地与其他模块组合以实现下游任务,例如图像生成(例如DALL·E[83])。虽然在视觉和语言编码器方面已经取得了很大的进展,但计算机视觉包括了超出这一范围的广泛问题,并且对于其中许多问题,不存在丰富的训练数据。
在这项工作中,我们的目标是建立一个图像分割的基础模型。也就是说,我们寻求开发一个可提示的模型,并使用支持强大泛化的任务在广泛的数据集上对其进行预训练。有了这个模型,我们的目标是用快速工程解决一系列新的数据分布上的下游分割问题。
该计划的成功取决于三个组成部分:任务、模型和数据。为了开发它们,我们解决了以下关于图像分割的问题:
- 什么任务可以实现零射击泛化?
- 相应的模型架构是什么?
- 哪些数据可以支持这个任务和模型?
这些问题错综复杂,需要全面解决。我们首先定义一个可提示的分割任务,它足够普遍,可以提供强大的预训练目标,并支持广泛的下游应用。这项任务需要一个支持灵活提示的模型,并可以在提示时实时输出分割掩码,以允许交互式使用。为了训练我们的模型,我们需要一个多样化的、大规模的数据源。不幸的是,没有网络规模的数据源进行分割;为了解决这个问题,我们构建了一个“数据引擎”,即在使用我们的高效模型来辅助数据收集和使用新收集的数据来改进模型之间进行迭代。接下来,我们将介绍每个相互连接的组件,然后是我们创建的数据集和证明我们方法有效性的实验。
Task

在NLP和最近的计算机视觉中,基础模型是一个有前途的发展,它可以通过使用“提示”技术对新数据集和任务执行零次和少次学习。受此工作的启发,我们提出了可提示分割任务,其目标是在给定任何分割提示时返回有效的分割掩码(见图1a)。提示符简单地指定要在图像中分割什么,例如,提示符可以包括标识对象的空间或文本信息。有效输出掩码的要求意味着,即使提示符是模糊的,并且可能指向多个对象(例如,衬衫上的一个点可能表示衬衫或穿衬衫的人),输出也应该是这些对象中至少一个的合理掩码。我们使用提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。
Model

可提示的分割任务和实际使用的目标对模型体系结构施加了约束。特别是,该模型必须支持灵活的提示,需要实时平摊计算掩码以允许交互使用,并且必须能够识别歧义。令人惊讶的是,我们发现一个简单的设计满足了所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,预测分割掩码。我们把这个模型称为分段任意模型(Segment Anything model),或SAM(见图1b)。通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,可以使用不同的提示重用相同的图像嵌入(及其成本摊销)。给定图像嵌入,提示编码器和掩码解码器在网络浏览器中从提示符中预测掩码,时间为~ 50ms。我们主要关注点、框和掩码提示,并使用自由形式的文本提示来呈现初始结果。为了使SAM能够识别歧义,我们将其设计为为单个提示预测多个掩码,允许SAM自然地处理歧义,例如衬衫vs.人的示例。
Data engine

为了实现对新数据分布的强泛化,我们发现有必要在一个大而多样的掩码集上训练SAM,而不是任何已经存在的分割数据集。虽然基础模型的典型方法是在线获取数据[82],但掩码自然并不丰富,因此我们需要一种替代策略。我们的解决方案是构建一个“数据引擎”,即我们与模型在循环数据集注释共同开发我们的模型(见图1c)。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM帮助注释者注释掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以自动为对象的一个子集生成掩码,方法是提示它可能的对象位置,而注释器则专注于注释剩余的对象,这有助于增加掩码的多样性。在最后阶段,我们用前景点的规则网格提示SAM,平均每张图像产生约100个高质量蒙版。
Dataset

我们最终的数据集SA-1B,包括来自11M个许可和隐私保护图像的超过1b个掩码(见图2)。SA-1B,使用我们的数据引擎的最后阶段完全自动收集,比任何现有的分割数据集[66,44,117,60]拥有400倍多的掩码,并且我们广泛验证,掩码具有高质量和多样性。我们希望SA-1B能够成为一种有价值的资源,用于建立新的基础模型。
Responsible AI

在使用SA-1B和SAM时,我们研究并报告潜在的公平性问题和偏见。SA-1B中的图像跨越了地理和经济上不同的国家,我们发现SAM在不同人群中的表现相似。总之,我们希望这将使我们的工作在现实用例中更加公平。我们在附录中提供了模型和数据集卡。
Experiments

我们广泛地评估SAM。首先,使用不同的23个分割数据集的新套件,我们发现SAM从单个前景点生成高质量的掩码,通常仅略低于手动注释的地面真相。其次,我们在使用提示工程的零镜头传输协议下的各种下游任务上发现了持续强大的定量和定性结果,包括边缘检测、对象建议生成、实例分割和文本到掩码预测的初步探索。这些结果表明,SAM可以在即时工程中开箱即用,解决涉及SAM训练数据之外的对象和图像分布的各种任务。然而,正如我们在§8中所讨论的,改进的空间仍然存在。
Release

我们将发布SA-1B数据集用于研究目的,并在https://segment-anything.com上允许开放许可证(Apache 2.0)下提供SAM。我们还通过在线演示展示了SAM的功能。


来自我们新引入的数据集SA-1B的覆盖蒙版示例图像。SA-1B包含11M个不同的、高分辨率的、授权的和隐私保护的图像和1.1个高质量的分割掩码。这些面具是由SAM自动标注的,我们通过人工评分和大量实验验证,它们是高质量和多样性的。我们根据每个图像的蒙版数量对图像进行分组,以实现可视化(平均每张图像约有100个蒙版)。
2. Segment Anything Task

我们从NLP中获得灵感,其中下一个令牌预测任务用于基础模型预训练,并通过提示工程[10]解决各种下游任务。为了建立一个分割的基础模型,我们的目标是定义一个具有类似功能的任务。
Task

我们首先将提示符的思想从NLP转换为分割,其中提示符可以是一组前景/背景点,一个粗略的框或掩码,自由形式的文本,或者通常情况下,指示图像中要分割的内容的任何信息。那么,提示分割任务是在给定任何提示时返回一个有效的分割掩码。“有效”掩码的要求仅仅意味着,即使提示符是模糊的,并且可能涉及多个对象(例如,回想一下衬衫vs.人的例子,请参见图3),输出也应该是这些对象中至少一个的合理掩码。这一需求类似于期望语言模型对模棱两可的提示符输出一致的响应。我们选择这个任务是因为它导致了一个自然的预训练算法和一个通过提示将零镜头转移到下游分割任务的通用方法。
Pre-training

提示分割任务提出了一种自然的预训练算法,该算法为每个训练样本模拟一系列提示(例如,点、框、掩码),并将模型的掩码预测与实际情况进行比较。我们从交互式分割[109,70]中采用了这种方法,尽管与交互式分割的目标是在足够的用户输入后最终预测有效的掩码不同,我们的目标是始终预测任何提示的有效掩码,即使提示是模糊的。这确保了预训练的模型在涉及歧义的用例中是有效的,包括我们的数据引擎§4所要求的自动注释。我们注意到,在这项任务中表现良好具有挑战性,需要专门的建模和训练损失选择,我们将在§3中讨论。
Zero-shot transfer

直观地说,我们的预训练任务赋予了模型在推理时对任何提示作出适当响应的能力,因此可以通过设计适当的提示来解决下游任务。例如,如果有一个猫的边界盒检测器,猫实例分割可以通过提供检测器的盒子输出作为我们的模型的提示来解决。一般来说,大量的实际分割任务都可以作为提示。除了自动数据集标记之外,我们还在§7的实验中探索了五个不同的示例任务。
Related tasks

分割是一个广泛的领域:有交互式分割[57,109],边缘检测[3],超像素化[85],对象建议生成[2],前景分割[94],语义分割[90],实例分割[66],泛视分割[59]等。我们的提示分割任务的目标是生产

每一列显示SAM从单个模糊点提示符(绿色圆圈)生成的3个有效掩码。

一个能力广泛的模型,可以适应许多(虽然不是全部)现有的和新的分割任务通过及时的工程。这种能力是任务泛化[26]的一种形式。注意,这与以前的多任务分割系统不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义、实例和全景分割[114,19,54],但训练和测试任务是相同的。在我们的工作中,一个重要的区别是,为提示分割训练的模型可以在推理时作为一个更大的系统中的组件执行一个新的、不同的任务,例如,为了执行实例分割,提示分割模型与现有的对象检测器相结合。
Discussion

提示和组合是强大的工具,可以以可扩展的方式使用单个模型,潜在地完成模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如CLIP[82]是DALL·E[83]图像生成系统的文本图像对齐组件。我们预计,由提示工程等技术驱动的可组合系统设计,将比专门为固定任务集训练的系统能够实现更广泛的应用程序。从组合的角度比较提示分割和交互式分割也很有趣:虽然交互式分割模型是在设计时考虑到人类用户的,但为提示分割训练的模型也可以组成一个更大的算法系统,正如我们将演示的那样。
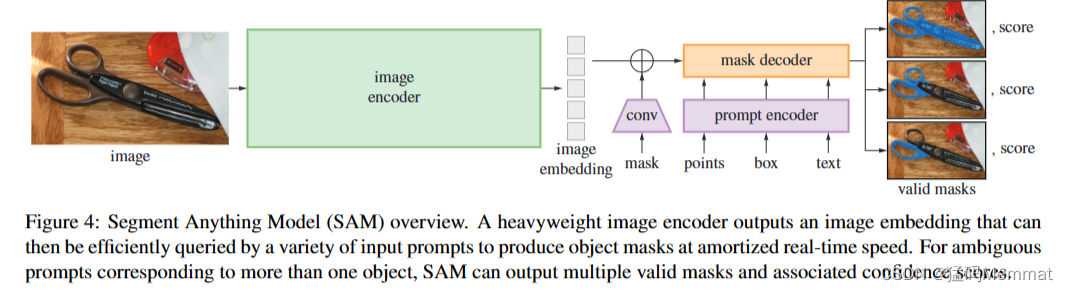
分段任意模型(SAM)概述。一个重量级图像编码器输出一个图像嵌入,然后可以通过各种输入提示有效地查询,以平摊实时速度生成对象掩码。对于对应于多个对象的模糊提示,SAM可以输出多个有效掩码和相关的置信度分数。
3. Segment Anything Model

接下来我们描述分段任意模型(SAM)用于提示分段。SAM有三个组成部分,如图4所示:一个图像编码器,一个灵活的提示编码器和一个快速的掩码解码器。我们建立在Transformer视觉模型[14,33,20,62]的基础上,对(平摊的)实时性能进行了特定的权衡。我们在这里对这些组件进行高层次的描述,详细内容见§a。
Image encoder

受可扩展性和强大的预训练方法的激励,我们使用MAE[47]预训练视觉转换器(ViT)[33]最小限度地适应于处理高分辨率输入[62]。图像编码器对每张图像运行一次,可以在提示模型之前应用。
Prompt encoder

我们考虑两组提示:稀疏提示(点、框、文本)和密集提示(掩码)。我们通过位置编码[95]表示点和框,并对每种提示类型和自由形式的文本使用CLIP现成的文本编码器[82]进行学习嵌入。密集提示(即掩码)使用卷积嵌入,并与图像嵌入元素相加。
Mask decoder

掩码解码器有效地将图像嵌入、提示嵌入和输出令牌映射到掩码。该设计受到[14,20]的启发,采用了对变压器解码器块[103]的修改,然后是动态掩码预测头。我们改进的解码器块在两个方向上使用提示自注意和交叉注意(提示到图像嵌入和反之亦然)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,MLP将输出令牌映射到动态线性分类器,然后计算每个图像位置的掩码前景概率。
Resolving ambiguity

对于一个输出,如果给出模棱两可的提示,模型将平均多个有效掩码。为了解决这个问题,我们修改了模型,以预测单个提示符的多个输出掩码(见图3)。我们发现3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多有三种深度:整体、部分和子部分)。在训练中,我们只用最少的道具

掩码损失[15,45,64]。为了对面具进行排名,模型预测每个面具的置信度分数(即估计的IoU)。
Efficiency

整个模型设计很大程度上是由效率驱动的。给定预先计算的图像嵌入,提示编码器和掩码解码器在CPU上的web浏览器中运行,时间约为50毫秒。这种运行时性能使我们的模型实现了无缝、实时的交互式提示。
Losses and training

我们使用[14]中使用的焦点损失[65]和骰子损失[73]的线性组合来监督掩模预测。我们使用混合的几何提示(文本提示参见§7.5)来训练提示分割任务。按照[92,37],我们通过在每个掩码中随机抽取11轮提示来模拟交互式设置,允许SAM无缝集成到我们的数据引擎中。
4. Segment Anything Data Engine

由于分割掩码在互联网上并不丰富,我们构建了一个数据引擎来收集我们的1.1B掩码数据集SA-1B。数据引擎有三个阶段:(1)模型辅助的手动注释阶段,(2)混合了自动预测掩码和模型辅助注释的半自动阶段,以及(3)我们的模型在没有注释器输入的情况下生成掩码的全自动阶段。接下来我们将详细介绍每一个。
Assisted-manual stage

在第一阶段,类似于经典的交互式分割,一组专业的注释人员使用SAM支持的基于浏览器的交互式分割工具,通过单击前景/背景对象点来标记掩码。蒙版可以使用像素精确的“笔刷”和“橡皮擦”工具来细化。我们的模型辅助注释直接在浏览器中实时运行(使用预先计算的图像嵌入),从而实现真正的交互式体验。我们没有对标记对象施加语义约束,注释者可以自由地标记“stuff”和“things”[1]。我们建议注释者标记他们可以命名或描述的对象,但没有收集这些名称或描述。标注者被要求按突出的顺序标注对象,并被鼓励在一个蒙版花费30秒以上的时间来标注下一个图像。

在这一阶段的开始,SAM使用公共分割数据集进行训练。在足够的数据标注后,仅使用新标注的掩码重新训练SAM。随着越来越多的掩模被收集,图像编码器从ViT-B缩放到ViT-H,其他架构细节也在进化;我们总共重新训练了我们的模型6次。随着模型的改进,每个掩码的平均注释时间从34秒减少到14秒。我们注意到,14秒比COCO的掩码标注快6.5倍[66],仅比极值点的边界框标注慢2倍[76,71]。随着SAM的改进,每张图像的平均掩码数量从20个增加到44个。总的来说,我们在这个阶段从12万张图片中收集了430万个面具。
Semi-automatic stage

在这个阶段,我们的目标是增加面具的多样性,以提高我们的模型分割任何东西的能力。为了将注释器集中在不太突出的对象上,我们首先自动检测自信掩码。然后,我们向注释者展示了预先填充了这些蒙版的图像,并要求他们注释任何其他未注释的对象。为了检测可信掩码,我们使用通用的“对象”类别在所有第一阶段掩码上训练了一个边界盒检测器[84]。在此阶段,我们在180k图像中收集了额外的590万个面具(总共1020万个面具)。与第一阶段一样,我们定期对新收集的数据重新训练我们的模型(5次)。每个掩码的平均注释时间回到了34秒(不包括自动掩码),因为这些对象的标签更具挑战性。每张图片的平均蒙版数量从44个增加到72个(包括自动蒙版)。
Fully automatic stage

在最后一个阶段,注释是完全自动的。这是可行的,因为我们的模型有两个主要的增强。首先,在这一阶段的开始,我们收集了足够多的面具来极大地改进模型,包括前一阶段的各种面具。第二,在这个阶段,我们已经开发了模糊感知模型,它允许我们在模糊的情况下预测有效的掩码。具体来说,我们使用32×32规则点网格来提示模型,并为每个点预测一组可能对应于有效对象的掩码。对于识别歧义的模型,如果一个点位于一个部件或子部件上,我们的模型将返回子部件、部分和整个对象。利用模型中的IoU预测模块来选择有信心的面具;此外,我们仅识别和选择了稳定的掩码(如果将概率图阈值设为0.5−δ和0.5 + δ会产生相似的掩码,则我们认为掩码是稳定的)。最后,在选择自信和稳定的掩码后,应用非最大抑制(non- maximum suppression, NMS)对重复数据进行过滤。为了进一步提高较小蒙版的质量,我们还处理了多个重叠的放大图像作物。关于这一阶段的更多细节,请参见§B。我们对数据集中的所有11M张图像应用了全自动蒙版生成,总共生成了1.1亿个高质量的蒙版。接下来,我们描述并分析结果数据集SA-1B。
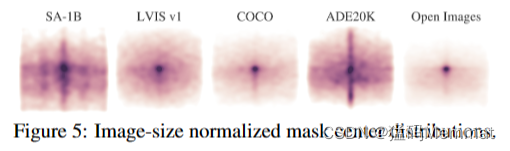
5. Segment Anything Dataset

我们的数据集SA-1B由11M个不同的、高分辨率的、授权的和保护隐私的图像和1.1个由我们的数据引擎收集的高质量分割掩码组成。我们将SA-1B与现有数据集进行比较,并分析掩模质量和性能。我们正在发布SA-1B,以帮助计算机视觉基础模型的未来发展。我们注意到SA-1B将在有利的许可协议下发布,用于某些研究用途,并保护研究人员。
Images

我们从一家直接与摄影师合作的提供商那里获得了一组新的1100万张图片的授权。这些图像是高分辨率的(平均为3300×4950像素),由此产生的数据大小可能会带来可访问性和存储方面的挑战。因此,我们将发布下采样图像,并将其最短边设置为1500像素。即使在降采样之后,我们的图像的分辨率也明显高于许多现有的视觉数据集(例如,COCO[66]图像的像素为480×640)。请注意,目前大多数模型都在低分辨率输入上运行。在公布的图片中,人脸和车牌被模糊处理。
Masks

我们的数据引擎生产了11亿个口罩,其中99.1%是全自动生成的。因此,自动掩模的质量是至关重要的。我们将它们直接与专业注释进行比较,并查看各种掩码属性与突出的分割数据集进行比较。正如下面的分析和§7的实验所证明的那样,我们的主要结论是,我们的自动掩模对于训练模型来说是高质量和有效的。基于这些发现,SA-1B只包含自动生成的掩码。
Mask quality

为了评估蒙版质量,我们随机抽取了500张图片(约50k个蒙版),并请我们的专业注释人员提高这些图片中所有蒙版的质量。注释者使用我们的模型和像素精确的“笔刷”和“橡皮擦”编辑工具来完成这些操作。这个过程产生了一对自动预测和专业校正的面具。我们计算了每对情侣之间的欠条,发现94%的情侣欠条超过90%(97%的情侣欠条超过75%)。相比之下,先前的工作估计IoU之间的注释一致性为85-91%[44,60]。我们在§7中的实验通过人类评分证实,相对于各种数据集,掩码质量都很高,并且在自动掩码上训练我们的模型几乎与使用数据引擎生成的所有掩码一样好。
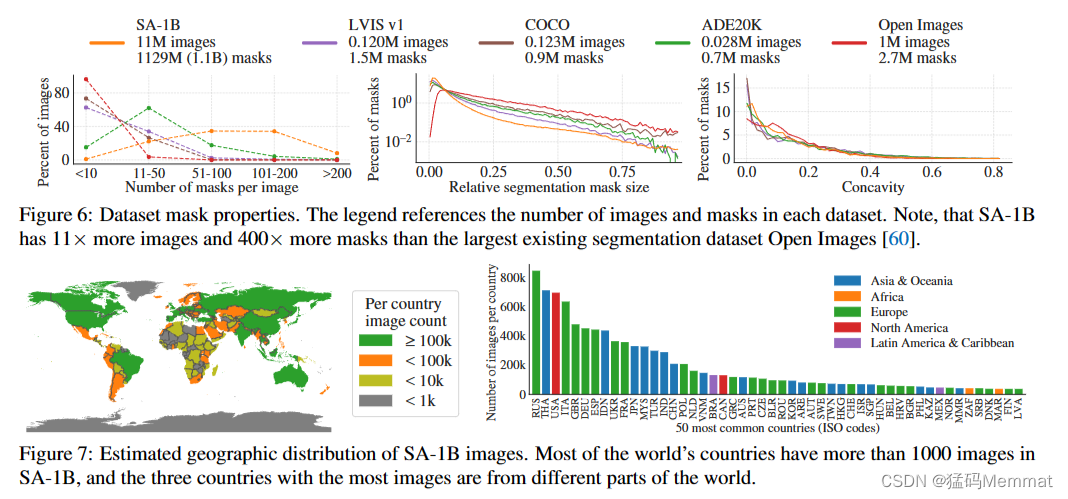
数据集掩码属性。图例引用了每个数据集中的图像和掩码的数量。请注意,SA-1B比现有最大的分割数据集Open images多11倍的图像和400倍的掩码
SA-1B图像的估计地理分布。世界上大多数国家的SA-1B图像数量都在1000张以上,其中图片数量最多的三个国家来自世界不同地区。
Mask properties.

在图5中,我们绘制了SA-1B中对象中心的空间分布,与最大的现有分割数据集进行了比较。所有数据集中都存在常见的摄影师偏见。我们观察到SA-1B相比于两个分布最相似的数据集LVIS v1[44]和ADE20K[117]具有更大的图像角落覆盖率,而COCO[66]和Open Images V5[60]具有更突出的中心偏倚。在图6(图例)中,我们通过大小来比较这些数据集。SA-1B拥有比第二大的Open images多11倍的图像和400×more掩码。平均而言,它比Open Images有36倍多的掩码。在这方面最接近的数据集ADE20K,每张图像仍然有3.5×fewer掩码。图6(左)为掩模环绕图像分布图。接下来,我们看看图6(中间)中图像相对掩码大小(掩码面积除以图像面积的平方根)。正如预期的那样,由于我们的数据集每张图像有更多的掩码,它也倾向于包括更大比例的中小型相对大小的掩码。最后,为了分析形状复杂性,我们看图6(右)中的掩模凹度(1减去掩模面积除以掩模凸包面积)。由于形状复杂性与掩码大小相关,我们通过首先从分类掩码大小中执行分层采样来控制数据集的掩码大小分布。我们观察到掩模的凹面分布与其他数据集的凹面分布大致相似。
6. Segment Anything RAI Analysis

接下来,我们通过调查使用SA-1B和SAM时潜在的公平性问题和偏见,对我们的工作进行负责任的AI (RAI)分析。我们关注SA-1B的地理和收入分配,以及SAM在受保护属性之间的公平性。我们还在§F中提供了数据集、数据注释和模型卡。
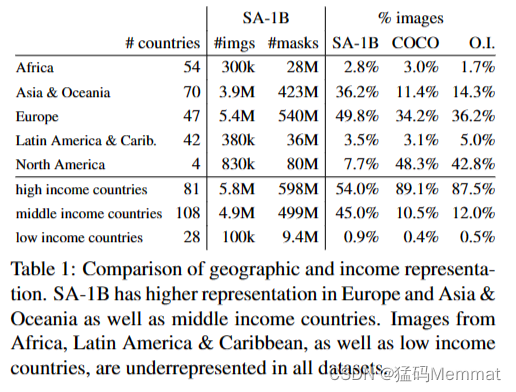
地域和收入代表性的比较。SA-1B在欧洲、亚洲和大洋洲以及中等收入国家有较高的代表性。来自非洲、拉丁美洲和加勒比以及低收入国家的图像在所有数据集中均未得到充分体现。
Geographic and income representation

我们推断国家图像是使用标准方法拍摄的(见§C)。在图7中,我们可视化了SA-1B中每个国家的图像计数(左)和拥有最多图像的50个国家(右)。我们注意到,排名前三的国家来自世界不同地区。接下来,在表1中,我们比较了SA-1B、COCO[66]和Open Images[60]的地理和收入表现。SA-1B在欧洲、亚洲和大洋洲以及中等收入国家的图像比例更高。所有数据集都没有充分代表非洲和低收入国家。我们注意到,在SA-1B中,包括非洲在内的所有区域都至少有2800万个掩码,比之前任何数据集的掩码总数多10倍。最后,我们观察到,每张图像的平均面具数量(未显示)在不同地区和收入之间相当一致(每张图像94-108)。
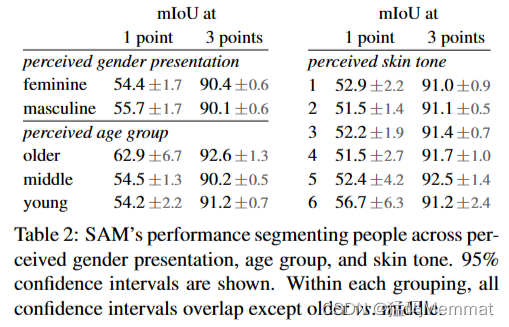
SAM的表现根据感知的性别表现、年龄组和肤色来划分人们。显示95%置信区间。在每个分组中,除了老年人和中年人之外,所有置信区间都重叠。
Fairness in segmenting people

我们通过测量组间SAM的表现差异,调查感知性别表现、感知年龄组和感知肤色的潜在公平问题。我们使用MIAP (More Inclusive Annotations for People)[87]数据集来表示性别和年龄,使用专有数据集来表示肤色(见§C)。我们的评估使用模拟交互式分割,随机抽样1点和3点(见§D)。表2(左上)显示了感知性别表现的结果。我们注意到,女性在检测和分割数据集中的代表性不足[115],但观察到SAM在各组间的表现相似。我们在表2(左下)中重复了对感知年龄的分析,并注意到那些被认为更年轻和更年长的人在大规模数据集中的代表性不足[110]。SAM在那些被认为年龄较大的人身上表现最好(尽管置信区间很大)。最后,我们重复了表2(右)中对感知肤色的分析,注意到在大规模数据集中,表观肤色较浅的人被证明代表过多,而肤色较深的人代表不足[110]。由于MIAP不包含感知到的肤色注释,我们使用了一个专有数据集,该数据集包含感知到的Fitzpatrick皮肤类型[36]的注释,其范围从1(最浅的肤色)到6(最深的肤色)。虽然方法有所不同,但我们没有发现组间有显著差异。我们相信我们的发现源于任务的性质,并且承认当SAM被用作更大系统的组件时可能会产生偏差。最后,在§C中,我们将分析扩展到服装细分,在那里我们发现了跨感知性别呈现的偏见迹象。
7. Zero-Shot Transfer Experiments

在本节中,我们将介绍SAM(分段任意模型)的零镜头转移实验。我们考虑五个任务,其中四个与用于训练SAM的提示分割任务有显著不同。这些实验评估SAM在数据集和任务上没有看到ing训练(我们对“零投篮转移”的使用遵循了CLIP中的用法[82])。数据集可能包括新颖的图像分布,例如水下或以自我为中心的图像(例如图8),据我们所知,这些图像没有出现在SA-1B中。

我们的实验从测试提示分割的核心目标开始:从任何提示生成有效的掩码。我们强调单前景点提示的挑战性场景,因为它比其他更具体的提示更有可能模棱两可。接下来,我们提出了一系列实验,穿越低、中、高水平的图像理解,并大致平行于该领域的历史发展。具体来说,我们提示SAM(1)执行边缘检测,(2)分割所有内容,即对象提议生成,(3)分割检测到的对象,即。实例分割和(4),作为概念证明,从自由形式的文本中分割对象。这四个任务与SAM训练的提示分割任务有很大不同,并通过提示工程实现。我们的实验以消融研究结束。
Implementation

除非另有说明:(1)SAM使用MAE[47]预训练的ViT-H[33]图像编码器;(2)SAM在SA-1B上进行训练,注意到该数据集仅包括来自数据引擎最后阶段的自动生成掩码。所有其他模型和训练细节,如超参数,请参考§A。
7.1 Zero-Shot Single Point Valid Mask Evaluation
Task

我们评估从单个前景点分割一个对象。这个任务是不恰当的,因为一个点可以指向多个对象。大多数数据集中的地面真相掩码并没有列举所有可能的掩码,这可能会使自动度量不可靠。因此,我们用一项人类研究补充了标准mIoU度量(即预测的和真实掩模之间的所有白条的平均值),其中注释者将掩模质量从1(无意义)评价为10(像素完美)。看到§D。1, E,和G的额外细节。
默认情况下,我们从地面真相掩码的“中心”(掩码内部距离变换的最大值)采样点,遵循交互分割中的标准评估协议[92]。由于SAM能够预测多个掩码,我们默认只评估模型中最可信的掩码。基线都是单掩码方法。我们主要与RITM[92]进行比较,RITM是一种强交互分段器,与其他强基线相比,它在我们的基准上表现最好[67,18]。
Datasets

我们使用一个新编译的23个数据集的套件,具有不同的图像分布。图8列出了数据集,并显示了每个数据集的示例(详情见附录表7)。我们使用所有23个数据集进行mIoU评估。对于人体研究,我们使用图9b中列出的子集(由于此类研究的资源需求)。这个子集包括两个数据集,根据自动指标,SAM优于和低于RITM。

来自23个不同的分割数据集的样本,用于评估SAM的零射击转移能力。
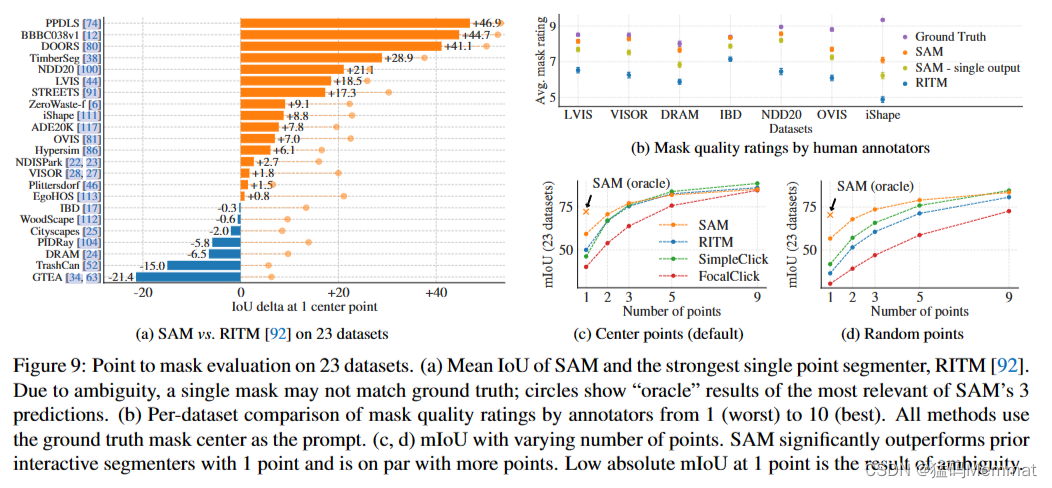
指向23个数据集的掩码评估。(a) SAM和最强单点分段RITM的平均欠条[92]。由于模糊性,单个面具可能与地面真相不匹配;圆圈表示SAM的3个预测中最相关的“神谕”结果。(b)注释者对掩码质量评级从1(最差)到10(最好)的每个数据集的比较。所有方法都使用地面真相掩蔽中心作为提示。(c, d)不同点数的mIoU。SAM以1分的成绩显著优于之前的交互式分段器,并与更多的分数持平。在1点处的低绝对mIoU是模糊的结果。
Results

首先,我们使用mIoU对23个数据集的完整套件进行自动评估。我们将图9a中的每个数据集结果与RITM进行比较。SAM在23个数据集中的16个数据集上产生了更高的结果,高达47个IoU。我们还提出了一个“神谕”结果,其中SAM的3个掩码通过与地面真相进行比较来选择最相关的掩码,而不是选择最可信的掩码。这揭示了歧义对自动评估的影响。特别是,在oracle执行歧义解析的情况下,SAM在所有数据集上都优于RITM。
人体研究结果如图9b所示。误差条是平均掩码评级的95%置信区间(所有差异均显著;详情见§E)。我们观察到,注释器对SAM掩码质量的评价始终高于最强基线RITM。使用单一输出掩码的SAM的消隐、“不识别歧义”版本的评分始终较低,但仍然高于RITM。SAM的平均评级在7到9之间,这与定性评级准则相对应:“高分(7-9):物体是可识别的,错误小而罕见(例如,缺少一个小的、严重模糊的断开连接的组件,……)。”这些结果表明SAM已经学会从单点分割有效的掩码。请注意,对于像DRAM和IBD这样的数据集,SAM在自动指标上表现较差,但它在人类研究中始终获得较高的评分。

图9c显示了附加的基线SimpleClick[67]和FocalClick[18],它们获得了比RITM和SAM更低的单点性能。随着点数从1增加到9,我们观察到方法之间的差距减小了。当任务变得更容易时,这是预期的;此外,SAM也没有针对非常高的IoU制度进行优化。最后,在图9d中,我们将默认的中心点采样替换为随机点采样。我们观察到SAM和基线之间的差距越来越大,SAM在两种采样方法下都能获得类似的结果。
7.2 Zero-Shot Edge Detection

BSDS500的零镜头边缘预测。SAM没有被训练去预测边缘地图,也没有在训练期间访问BSDS图像或注释。
BSDS500上的零拍摄转移到边缘检测
Approach

我们使用BSDS500[72,3]评估了SAM在经典的低层次边缘检测任务上的性能。我们使用了一个简化版的自动蒙版生成管道。具体来说,我们用前景点的16×16规则网格提示SAM,结果是768个预测掩码(每点3个)。网管移除冗余的掩码。然后,使用未阈值掩码概率映射的Sobel滤波和标准的轻量级后处理计算边缘映射,包括边缘NMS(见§D.2)。
Results

我们在图10中可视化代表性的边缘映射(参见图15了解更多)。定性地说,我们观察到,即使SAM没有经过边缘检测训练,它也能产生合理的边缘图。与地面真相相比,SAM预测了更多的边,包括BSDS500中没有注释的敏感边。这种偏差在表3中定量地反映出来:50%精密度(R50)的召回率很高,但以精密度为代价。SAM自然落后于最先进的方法,这些方法学习BSDS500的偏差,即要压制的边缘。尽管如此,SAM与HED108等开创性的深度学习方法相比表现良好,并且明显优于先前的零次传输方法,尽管公认已经过时。
7.3 Zero-Shot Object Proposals
Approach

接下来,我们在对象建议生成的中层任务上评估SAM[2,102]。该任务在目标检测研究中发挥了重要作用,是一项重要的研究课题
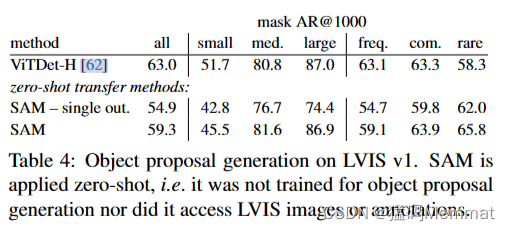
在LVIS v1上生成对象建议。SAM采用的是zero-shot,即它没有经过对象建议生成的训练,也没有访问LVIS图像或注释。

开拓系统中的中间步骤(例如,[102,41,84])。为了生成对象建议,我们运行一个稍微修改过的自动掩码生成管道,并将掩码输出为建议(参见§D.3)。
我们在LVIS v1[44]上计算标准平均召回(AR)指标。我们专注于LVIS,因为它的大量类别提供了一个具有挑战性的测试。我们将其与作为ViTDet[62]检测器实现的强基线进行比较(级联掩码R-CNN [48,11] vith)。我们注意到这个“基线”对应于“探测器伪装成提议生成器”(DMP)方法[16],这是一个真正苛刻的比较。
Results

在表4中,我们毫不意外地看到,使用ViTDet-H的检测作为对象建议(即,游戏AR的DMP方法[16])总体上表现最好。然而,SAM在几个指标上做得非常好。值得注意的是,它在中型和大型对象以及罕见和常见对象上优于ViTDet-H。事实上,SAM只在小对象和频繁对象上表现不如ViTDet-H,其中ViTDet-H可以很容易地学习LVIS特定的注释偏差,因为它是在LVIS上训练的,不像SAM。我们还与SAM(“单挑”)的消除歧义意识版本进行了比较,它在所有AR指标上的表现都明显比SAM差。
7.4 Zero-Shot Instance Segmentation
Approach

转到更高层次的视觉,我们使用SAM作为实例分段器的分段模块。实现很简单:我们运行一个对象检测器(之前使用的ViTDet),并用它的输出框提示SAM。这演示了在一个更大的系统中组合SAM。
Results

表5比较了SAM和ViTDet在COCO和LVIS上预测的掩模。看看掩模AP指标,我们观察到两个数据集上的差距,其中SAM相当接近,尽管肯定落后于ViTDet。通过可视化输出,我们观察到SAM掩模通常在质量上优于ViTDet,具有更清晰的边界(见§D.4和图16)。为了调查这一观察结果,我们进行了一项额外的人体研究,要求注释人员对之前使用的ViTDet面具和SAM面具进行1到10级的质量评分。在图11中,我们观察到SAM在人体研究中的表现始终优于ViTDet。
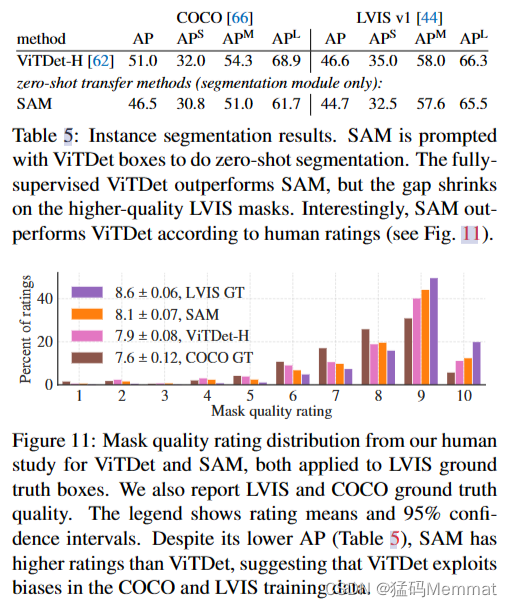
实例分割结果。SAM被ViTDet框提示进行零镜头分割。完全监督的ViTDet优于SAM,但在更高质量的LVIS口罩上差距缩小了。有趣的是,根据人类评分,SAM优于ViTDet(见图11)。
掩模质量评级分布来自我们对ViTDet和SAM的人类研究,两者都应用于LVIS地面真理盒。我们还报告LVIS和COCO地面真相质量。图例显示了评级均值和95%置信区间。尽管其AP较低(表5),SAM的评分高于ViTDet,这表明ViTDet利用了COCO和LVIS训练数据中的偏差。

我们假设在COCO上,掩码AP差距较大,地面真相质量相对较低(由人类研究证实),ViTDet学习了COCO掩码的特定偏差。SAM作为一种零概率方法,无法利用这些(通常不受欢迎的)偏差。LVIS数据集具有更高质量的地面真相,但仍然存在特定的特质(例如,掩模不包含孔,它们是构造上的简单多边形)和模态掩模与模态掩模的偏差。同样,SAM没有接受过学习这些偏见的训练,而ViTDet可以利用它们。
7.5 Zero-Shot Text-to-Mask
Approach

最后,我们考虑一个更高级的任务:从自由形式的文本中分割对象。这个实验是SAM处理文本提示能力的概念证明。虽然我们在之前的所有实验中都使用了完全相同的SAM,但对于这个SAM的训练过程进行了修改,使其能够识别文本,但以一种不需要新的文本注释的方式进行。具体来说,对于每个人工收集的面积大于1002的掩模,我们提取CLIPimage嵌入。然后,在训练过程中,我们将提取的CLIP图像嵌入作为SAM的第一次交互提示。这里的关键观察是,由于CLIP的图像嵌入被训练为与文本嵌入对齐,所以我们可以使用图像嵌入进行训练,但使用文本嵌入进行推理。也就是说,在推理时,我们通过CLIP的文本编码器运行文本,然后将生成的文本嵌入作为提示给SAM(见§D.5)。

Zero-shot text-to-mask。SAM可以使用简单而细致的文本提示。当SAM不能做出正确的预测时,额外的点提示可以提供帮助。
Results

我们在图12中显示了定性结果。SAM可以根据简单的文本提示(如“车轮”)和短语(如“海狸齿格栅”)来分割对象。当SAM仅从文本提示中未能选择正确的对象时,通常会增加一个点来修复预测,类似于[31]。
7.6 Ablations

我们使用单中心点提示协议在我们的23数据集套件上执行了几次消融。回想一下,单个点可能是模糊的,而且模糊可能无法在基本事实中表示,因为每个点只包含一个掩码。由于SAM是在零镜头传输设置下运行的,因此SAM的顶级掩码与数据注释准则产生的掩码之间可能存在系统偏差。因此,我们额外报告了与地面真相(“神谕”)有关的最佳掩模。
图13(左)显示了SAM在数据引擎阶段累积数据训练时的性能。我们观察到每一个阶段mIoU都在增加。当进行所有三个阶段的训练时,自动面具的数量远远超过手动和半自动面具。为了解决这个问题,我们发现在训练过程中对手动和半自动口罩进行10倍的过采样会得到最好的结果。这种设置使培训变得复杂。因此,我们测试了仅使用自动生成的掩码的第四种设置。使用这些数据,SAM的性能仅略低于使用所有数据(~ 0.5 mIoU)。因此,默认情况下,我们只使用自动生成的掩码来简化训练设置。
在图13(中)中,我们看看数据量的影响。完整的SA-1B包含11M图像,我们将其均匀地细分为1M和0.1M用于消融。在0.1M图像上,我们观察到在所有设置下,mIoU都有很大的下降。然而,对于1M图像,大约占整个数据集的10%,我们观察到的结果与使用整个数据集相当。这个数据制度仍然包括大约100M个掩码,对于许多用例来说可能是一个实用的设置。
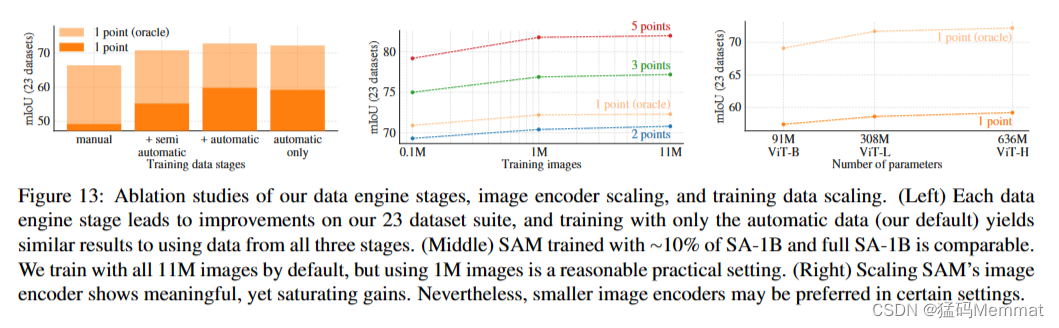
消融研究我们的数据引擎阶段,图像编码器缩放,和训练数据缩放。(左)每个数据引擎阶段都会对我们的23个数据集套件进行改进,只使用自动数据(我们的默认值)进行训练,产生的结果与使用所有三个阶段的数据相似。(中)SAM使用~ 10%的SA-1B和完整的SA-1B进行训练是相当的。我们默认使用所有11M张图像进行训练,但使用1M张图像是一个合理的实际设置。(右)缩放SAM的图像编码器显示有意义的,但饱和增益。然而,在某些设置下,更小的图像编码器可能是首选。

最后,图13(右)显示了使用vitb、vitl和vith图像编码器的结果。vith比vitb有显著改善,但仅比vitl有轻微提高。进一步的图像编码器缩放目前看来没有成效。
8. Discussion
Foundation models

自机器学习早期以来,预先训练的模型已经适应了下游任务[99]。近年来,随着对规模的日益重视,这种范式变得越来越重要,这种模型最近被(重新)称为“基础模型”:即“在大规模的广泛数据上训练,并适应广泛的下游任务”的模型[8]。我们的工作与这个定义很好地相关,尽管我们注意到图像分割的基础模型本质上是有限的范围,因为它代表了计算机视觉的一个重要但分数的子集。我们还将我们的方法的一个方面与[8]进行了对比,[8]强调了自监督学习在基础模型中的作用。虽然我们的模型是用自监督技术(MAE[47])初始化的,但它的绝大多数能力来自于大规模的监督训练。在数据引擎可以扩展可用注释的情况下,监督训练提供了一种有效的解决方案。
Compositionality

预先训练的模型可以提供新的能力,甚至超出训练时的想象。一个突出的例子是CLIP[82]如何在较大的系统中作为组件使用,如DALL·E[83]。我们的目标是用SAM使这种组合变得简单。我们的目标是通过要求SAM为广泛的分割提示预测有效的掩码来实现这一点。其效果是在SAM和其他组件之间创建一个可靠的接口。例如,MCC[106]可以很容易地使用SAM对感兴趣的物体进行分割,并从单个RGB-D图像中实现对未见物体的强泛化进行3D重建。在另一个例子中,SAM可以通过可穿戴设备检测到的注视点来提示,从而实现新的应用程序。由于SAM能够推广到以自我为中心的图像等新领域,这样的系统不需要额外的训练就能工作。
Limitations

虽然SAM总体上表现良好,但并不完美。它可能会错过精细的结构,有时会产生小的不连接的组件,并且不能像“放大”这样计算密集型的方法那样清晰地产生边界,例如[18]。一般来说,我们期望专用的交互式分割方法在提供许多点时优于SAM,例如[67]。与这些方法不同,SAM是为通用性和使用广度而设计的,而不是高IoU交互式分割。此外,SAM可以实时处理提示,但当使用重型图像编码器时,SAM的整体性能不是实时的。我们对文本掩码任务的尝试是探索性的,并不完全健壮,尽管我们相信通过更多的努力可以改进它。虽然SAM可以执行许多任务,但目前尚不清楚如何设计简单的提示符来实现语义和全景分割。最后,还有一些领域特定的工具,例如[7],我们希望它们在各自的领域中优于SAM。
Conclusion

Segment Anything项目是将图像分割提升到基础模型时代的一种尝试。我们的主要贡献是一个新的任务(提示分割),模型(SAM)和数据集(SA-1B),使这一飞跃成为可能。SAM是否达到了基础模型的地位,仍然要看它在社区中是如何使用的,但不管我们期待这项工作的前景,超过1B个掩模的发布,以及我们的快速分割模型将有助于铺平前进的道路。
Acknowledgments

我们要感谢Aaron Adcock和Jitendra Malik的有益讨论。我们感谢Vaibhav Aggarwal和Yanghao Li帮助我们扩展模型。我们感谢Cheng-Yang Fu, jiao Hu和Robert Kuo对数据注释平台的帮助。我们感谢Allen Goodman和Bram Wasti在优化我们模型的web版本方面的帮助。最后,我们感谢Morteza Behrooz、Ashley Gabriel、Ahuva Goldstand、Sumanth Gurram、Somya Jain、Devansh Kukreja、Joshua Lane、Lilian Luong、Mallika Malhotra、William Ngan、Omkar Parkhi、Nikhil Raina、Dirk Rowe、Neil Sejoor、Vanessa Stark、Bala Varadarajan和Zachary Winstrom在制作演示、数据集查看器和其他资产和工具方面的帮助。
References


Appendix

A. Segment Anything Model and Task Details
Image encoder

通常,图像编码器可以是输出C×H×W图像嵌入的任何网络。受可扩展性和强预训练的激励,我们使用MAE[47]预训练的视觉转换器(ViT)[33],它具有最小的适应性来处理高分辨率输入,特别是具有14×14窗口注意力和四个等间距全局注意力块的ViT- h /16,如下[62]。图像编码器的输出是输入图像的16×缩小嵌入。由于我们的运行时目标是实时处理每个提示,因此我们可以提供大量的图像编码器flop,因为它们只对每张图像计算一次,而不是每个提示。
遵循标准实践(例如,[40]),我们使用通过重新缩放图像和填充较短一侧获得的输入分辨率1024×1024。因此,图像嵌入是64×64。为了降低信道维数,按照[62],我们使用1×1卷积得到256个信道,然后使用3×3卷积也得到256个信道。每个卷积后面都有一个层归一化[4]。
Prompt encoder

稀疏提示符映射到256维向量嵌入,如下所示。一个点被表示为点的位置编码[95]和两个学习嵌入之一的和,这两个嵌入表明这个点是在前景还是在背景。盒子由嵌入对表示:(1)盒子左上角的位置编码与表示“左上角”的学习嵌入求和;(2)盒子结构相同,但使用表示“右下角”的学习嵌入。最后,为了表示自由格式的文本,我们使用CLIP[82]中的文本编码器(一般情况下任何文本编码器都是可能的)。在本节的剩余部分中,我们将重点讨论几何提示,并在§D.5中深入讨论文本提示。
密集提示符(即掩码)与图像具有空间对应关系。我们以比输入图像低4倍的分辨率输入掩模,然后使用两个2×2,分别使用输出通道4和16的stride-2卷积将额外的分辨率降低4倍。最后一个1×1卷积将信道维度映射到256。每一层由GELU激活[50]和层归一化分开。

然后按元素添加蒙版和图像嵌入。如果没有掩码提示,则在每个图像嵌入位置添加表示“无掩码”的学习嵌入。
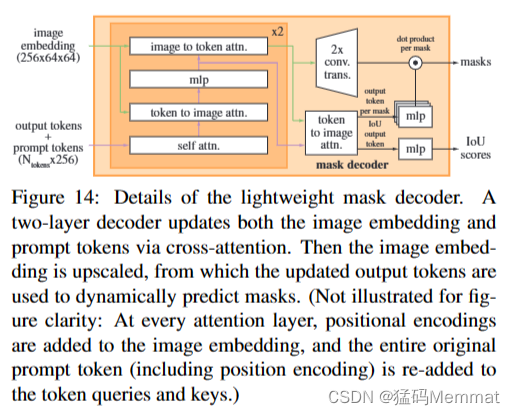
轻量级掩码解码器的细节。两层解码器通过交叉注意更新图像嵌入和提示标记。然后对图像嵌入进行放大,利用更新后的输出令牌动态预测掩码。(为了图形清晰,这里没有说明:在每个注意层,位置编码被添加到图像嵌入中,整个原始提示令牌(包括位置编码)被重新添加到令牌查询和键中。)
Lightweight mask decoder

这个模块有效地将图像嵌入和一组提示嵌入映射到输出掩码。为了组合这些输入,我们从**Transformer分割模型[14,20]**中获得灵感,并修改了标准Transformer解码器[103]。在应用我们的解码器之前,我们首先在提示嵌入集中插入一个学习的输出令牌嵌入,该输出令牌嵌入将用于解码器的输出,类似于[33]中的[class]令牌。为简单起见,我们将这些嵌入(不包括图像嵌入)统称为“令牌”。
我们的解码器设计如图14所示。每个解码器层执行4个步骤:(1)对标记的自我注意,(2)从标记(作为查询)到图像嵌入的交叉注意,(3)逐点MLP更新每个标记,以及(4)从图像嵌入(作为查询)到标记的交叉注意。最后一步用提示信息更新图像嵌入。在交叉注意过程中,图像嵌入被视为一组642个256维向量。每个自我/交叉注意和MLP都有一个残差连接[49],层归一化,训练时的dropout[93]为0.1。下一个解码器层从前一层获取更新的标记和更新的图像嵌入。我们使用两层解码器。
为了确保解码器能够访问关键的几何信息,每当位置编码参与注意层时,都会添加到图像嵌入中。此外,当整个原始提示令牌(包括它们的位置编码)参与注意层时,将重新添加到更新的令牌中。这允许强烈依赖提示标记的几何位置和类型。
在运行解码器后,我们对更新后的图像嵌入进行了4倍的上采样,并进行了两次转置卷积

图层(现在相对于输入图像缩小了4倍)。然后,令牌再次参与图像嵌入,我们将更新的输出令牌嵌入传递给一个小的3层MLP,该MLP输出一个与放大后的图像嵌入的通道维度匹配的向量。最后,我们用放大后的图像嵌入和MLP输出之间的空间点积来预测一个掩模。图层(现在相对于输入图像缩小了4倍)。然后,令牌再次参与图像嵌入,我们将更新的输出令牌嵌入传递给一个小的3层MLP,该MLP输出一个与放大后的图像嵌入的通道维度匹配的向量。最后,我们用放大后的图像嵌入和MLP输出之间的空间点积来预测一个掩模。
变压器使用256的嵌入维数。转换器MLP块的内部维度很大,为2048,但MLP仅应用于提示令牌相对较少(很少大于20)的提示令牌。然而,在我们有64×64图像嵌入的交叉注意层中,为了提高计算效率,我们将查询、键和值的通道维度降低了2倍至128。所有注意层使用8个头。
用于提升输出图像嵌入的转置卷积为2×2, stride 2,输出通道维数为64和32,具有GELU激活。通过层归一化将它们分开。
Making the model ambiguity-aware

如上所述,单个输入提示符可能是模糊的,因为它对应于多个有效掩码,模型将学习对这些掩码求平均值。我们通过一个简单的修改消除了这个问题:我们使用少量的输出令牌并同时预测多个掩码,而不是预测单个掩码。默认情况下,我们预测三个蒙版,因为我们观察到三个层(整体、部分和子部分)通常足以描述嵌套的蒙版。在训练过程中,我们计算地面真相和每个预测掩码之间的损失(简要描述),但只从最低的损失反向传播。这是一种用于具有多个输出的模型的常用技术[15,45,64]。为了在应用程序中使用,我们想要对预测的掩码进行排名,因此我们添加了一个小的头(在一个额外的输出令牌上操作),以估计每个预测掩码与其覆盖的对象之间的IoU。
对于多个提示符,歧义很少出现,并且三个输出掩码通常会变得相似。为了最大限度地减少训练时简并损失的计算,并确保单个无歧义掩码接收到规则的梯度信号,我们只在给出多个提示时预测单个掩码。这是通过为额外的掩码预测添加第四个输出令牌来实现的。这第四个掩码永远不会为单个提示返回,它是为多个提示返回的唯一掩码。
Losses

我们使用焦点损失[65]和骰子损失[73]的线性组合来监督掩模预测,焦点损失与骰子损失的比例为20:1,如下[20,14]。与[20,14]不同的是,我们观察到每个解码器层之后的辅助深度监督是没有帮助的。IoU预测头使用IoU预测与预测掩码的IoU之间的均方误差损失(ground truth mask)进行训练。它以恒定的缩放因子1.0添加到掩模损耗中。
Training algorithm

根据最近的方法[92,37],我们在训练过程中模拟交互式分割设置。首先,以相同的概率随机选择一个前景点或包围框作为目标蒙版。点从地面真值掩模中均匀采样。将box作为ground truth mask的包围框,在每个坐标中加入随机噪声,标准差等于box边长的10%,最大20像素。这种噪声剖面是实例分割(在目标对象周围产生一个紧密的框)和交互式分割(用户可以画一个松散的框)等应用程序之间的合理妥协。
从第一个提示符进行预测后,从前一个掩码预测和地面真值掩码之间的误差区域中均匀地选择后续点。如果错误区域为假阴性或假阳性,则每个新点分别为前景或背景。我们还提供了前一次迭代的掩码预测,作为对模型的额外提示。为了为下一次迭代提供最大的信息,我们提供了未阈值的掩码logits而不是二值化的掩码。当返回多个掩码时,传递给下一个迭代并用于采样下一个点的掩码是预测IoU最高的掩码。
我们发现在8个迭代采样点之后,收益递减 (我们已经测试了16个点)。此外,为了鼓励模型从提供的掩码中受益,我们还使用了两次以上的迭代,其中没有采样额外的点。其中一个迭代随机插入到8个迭代采样点之间,另一个迭代总是在最后。这总共给出了11个迭代: 一个采样的初始输入提示,8个迭代采样点,以及两个迭代,其中没有新的外部信息提供给模型,因此它可以学习改进自己的掩码预测。我们注意到,使用相对大量的迭代是可能的,因为我们的轻量级掩码解码器只需要图像编码器计算量的不到1%,因此,每次迭代只增加了很小的开销。这不同于以前的交互方法,每次优化器更新只执行一个或几个交互步骤[70,9,37,92]。
Training recipe

我们使用AdamW[68]优化器(β1 = 0.9, β2 = 0.999)和250次迭代的线性学习率热身[42]和逐步学习率衰减计划。热身后的初始学习率(lr)为8e−4。我们训练了90k次迭代(约2个SA-1B epoch),并在60k次迭代和86666次迭代中将thelr降低了10倍。批处理大小为256个图像。为了正则化SAM,我们将权重衰减(wd)设置为0.1,并以0.4的速率应用下降路径53。我们使用的分层学习率衰减5为0.8。没有应用数据扩充。我们从MAE[47]预训练的vi - h初始化SAM。我们在256个gpu上分发训练,这是由于大型图像编码器和1024×1024输入大小。

为了限制GPU内存使用,我们用每个GPU最多64个随机采样的掩码进行训练。此外,我们发现轻度过滤SA-1B掩模以丢弃任何覆盖图像90%以上的掩模可以从质量上改善结果。
对于消融和其他训练的变化(例如,文本到掩码§D.5),我们偏离上面的默认配方如下所示。当只使用第一和第二数据引擎阶段的数据进行训练时,我们使用大规模抖动40来增强输入。直观地说,当训练数据比较有限时,数据增强可能是有用的。为了训练ViT-B和ViT-L,我们使用了180k迭代,批处理大小为128,分布在128个gpu上。我们分别设置vi - b /L的lr = 8e−4/4e−4,ld = 0.6/0.8, wd = 0.1, dp = 0.6/0.4。
B. Automatic Mask Generation Details

在这里,我们讨论用于生成发布的SA-1B的数据引擎全自动阶段的细节。
Cropping

掩模是由完整图像上32×32点的规则网格和分别使用16×16和8×8规则点网格的2×2和4×4部分重叠窗口产生的20个额外的缩放图像作物生成的。原始的高分辨率图像被用于裁剪(这是我们唯一一次使用它们)。我们去掉了触及作物内部边界的面具。我们在两个阶段应用了标准的基于贪婪盒子的NMS(盒子是为了提高效率而使用的):第一个是在每个作物中,第二个是在整个作物中。当在作物中应用NMS时,我们使用模型预测的IoU对掩码进行排名。当在作物间应用NMS时,我们根据它们的源作物,从放大最多(即来自4×4作物)到放大最少(即原始图像)的掩模进行排名。在这两种情况下,我们都使用了0.7的NMS阈值。
Filtering

我们使用了三种滤镜来提高掩模质量。首先,为了只保留自信的面具,我们用模型预测的IoU分数在88.0的阈值进行过滤。其次,为了只保持稳定的掩码,我们比较了由相同底层软掩码产生的两个二进制掩码,并将其阈值设置为不同的值。我们只在其-1和+1阈值掩码对之间的IoU等于或大于95.0时保持预测(即,由阈值logits在0处产生的二进制掩码)。第三,我们注意到有时自动蒙版会覆盖整个图像。这些遮罩通常是无趣的,我们通过移除覆盖图像95%或更多的遮罩来过滤它们。所有过滤阈值的选择都是为了实现大量的掩码和高掩码质量,由专业注释人员使用§5中描述的方法进行判断。
Postprocessing

我们观察到两种很容易通过后处理减轻的错误类型。首先,估计有4%的口罩含有微小的虚假成分。为了解决这些问题,我们删除了面积较小的连接组件

大于100像素(包括删除整个蒙版,如果最大的组件低于这个阈值)。其次,另有4%的口罩上有小而假的洞。为了解决这些问题,我们用小于100像素的区域填充洞。孔洞被认为是倒置掩模的组成部分。
Automatic mask generation model

我们为全自动掩码生成训练了一个特殊版本的SAM,它牺牲了一些推理速度来改进掩码生成属性。我们注意到我们默认的SAM和这里用于数据生成的SAM之间的差异:它只在手动和半自动数据上训练,它训练的时间更长(177656次迭代而不是90k次),使用大规模抖动数据增强[40],模拟交互式训练只使用点和掩码提示(没有框),并且在训练期间每个掩码只采样4点(从默认的9减少到4加速训练迭代,对1点性能没有影响,尽管如果用更多的点评估会损害mIoU),最后,掩码解码器使用了3层而不是2层。
SA-1B examples

我们在图2中展示了SA-1B样品。有关更多示例,请参阅我们的数据集资源管理器。
C. RAI Additional Details

虽然SA-1B中的图像没有地理标记,但每张图像都有描述其内容和拍摄地点的标题。我们使用基于elmo的命名实体识别模型[78]从这些标题推断出大致的图像地理位置。每个提取的位置实体都映射到每个匹配的国家、省和城市。通过首先考虑匹配的国家,然后考虑省份,最后考虑城市,将标题映射到单个国家。我们注意到这种方法存在歧义和潜在的偏差(例如,“格鲁吉亚”可能指国家或美国州)。因此,我们使用提取的位置来整体分析数据集,但不发布推断的位置。图片提供者不会要求图片说明公开发布。
Inferring geographic information for SA-1B

COCO[66]和Open Images[60]数据集不提供地理位置。在[29]之后,我们使用Flickr API检索地理元数据。我们检索了24%的COCO训练集(19562张图像)的位置,而对于Open images,我们检索了18%的训练集(493,517张图像,仅考虑带有遮罩的图像)。我们注意到地理信息是近似的,具有此信息的图像样本可能不完全匹配完整的数据集分布。
Inferring geographic information for COCO and Open Images.
Inferring income information

我们使用每张图像的推断国家,根据世界银行[98]定义的水平来查找其收入水平。我们将上层中层和下层中层折叠成单个中层。

SAM在感知的性别表现和年龄群体中分割服装的表现。感知性别的间隔不一致,男性的mIoU较高。年龄组重叠的置信区间。
Fairness in segmenting people

为了调查SAM在划分人群时的公平性,我们使用了Open Images[60]的更包容注释(MIAP)[87]测试集注释,这使我们能够比较SAM在感知的性别呈现和感知的年龄组之间的表现。MIAP提供方框注释,而我们需要地面真相掩码来进行分析。为了获得地面真相掩码,我们从Open Images中选择每个人类别掩码,如果其对应的包围框在MIAP中带注释的包围框的1%范围内(基于相对盒子边长),则得到3.9k掩码。
Fairness in segmenting clothing

我们将分析从§6扩展到服装细分。我们看看SAM在衣服上的表现与穿着衣服的人的属性有关。我们使用所有来自Open Images的6.5k地面真相面具,它们在服装超类下有一个类别,并驻留在MIAP的人框中。在表6中,我们比较了不同性别和年龄组的表现。我们发现SAM在以男性为主的人群中更善于分割服装,95%置信区间不一致。当从1点到3点评估时,差距就会缩小。感知年龄组差异不显著。我们的研究结果表明,在使用一点提示来根据感知的性别表现来分割服装时存在偏差,我们鼓励SAM的用户注意这一限制。
D. Experiment Implementation Details
D.1. Zero-Shot Single Point Valid Mask Evaluation
Datasets

我们建立了一个新的分割基准来评估我们的模型的零镜头传输能力,使用了一套来自之前工作的23个不同的分割数据集。表7给出了每个数据集的描述。举例参见正文图8。该套件涵盖了一系列领域,包括自我中心[34,28,113]、显微镜[12]、x射线[104]、水下[52,100]、航空[17]、模拟[86]、驾驶[25]和绘制[24]图像。为了有效评估,我们对超过15k掩码的数据集进行了次采样。具体来说,我们随机选择图像,使采样图像中的掩码总数为~ 10k。我们对所有数据集中的人脸进行了模糊处理。
Point sampling

我们的默认点采样遵循交互式分割的标准实践[109,64,92]。确定地选择第一个点作为离目标边界最远的点。每个后续点都是距离地面真相和先前预测之间的误差区域边界最远的点。一些实验(在指定的地方)使用更具挑战性的抽样策略,其中第一个点是随机点,而不是确定性选择的“中心”点。每个后续点都是如上所述选择的。这种设置更好地反映了第一个点不可靠地靠近面具中心的用例,例如来自眼睛凝视的提示。
Evaluation

我们在N点提示后的预测和地面真相掩码之间测量IoU,其中N ={1,2,3,5,9},并且使用上述策略中的任何一种对点进行迭代采样。每个数据集mIoU是数据集中所有对象的每个掩码IoU的平均值。最后,我们通过在所有23个数据集上平均perdataset miou来报告顶线指标。我们的评估不同于标准的交互式分割评估协议,后者衡量实现X% IoU所需的平均点数,最高可达20分。我们只关注一个或几个点之后的预测,因为我们的许多用例涉及单个或很少的提示。考虑到我们的应用重点,需要实时提示处理,我们期望最佳的交互式分割模型在使用大量点时优于SAM。
Baselines

我们使用了三个最近的强交互基线:RITM [92], FocalClick[18]和SimpleClick[67]。对于每一个模型,我们都使用了在作者公开发布的最广泛的数据集上训练的最大模型。对于RITM,我们使用在COCO[66]和作者介绍的LVIS[44]组合训练的HRNet32 IT-M。对于FocalClick,我们使用在“组合数据集”上训练的SegFormerB3-S2,其中包括8个不同的分割数据集[18]。对于SimpleClick,我们使用了经过COCO和LVIS组合训练的vi - h448。我们遵循建议的默认策略进行数据预处理(即数据增强或图像调整大小),不更改或调整任何参数用于我们的评估。在我们的实验中,我们观察到RITM在我们的23个数据集套件上以1点评估优于其他基线。因此,我们使用RITM作为默认基线。当使用更多的点进行评估时,我们会报告所有基线的结果。
Single point ambiguity and oracle evaluation

除了N点提示后的欠条外,我们还通过评估SAM的三个预测中与地面真相最匹配的预测掩码来报告SAM在1点的“甲骨文”性能(而不是使用SAM本身排名第一的掩码,因为我们默认这样做)。该协议通过放宽在几个有效对象中猜测一个正确掩码的要求,解决了可能的单点提示歧义。
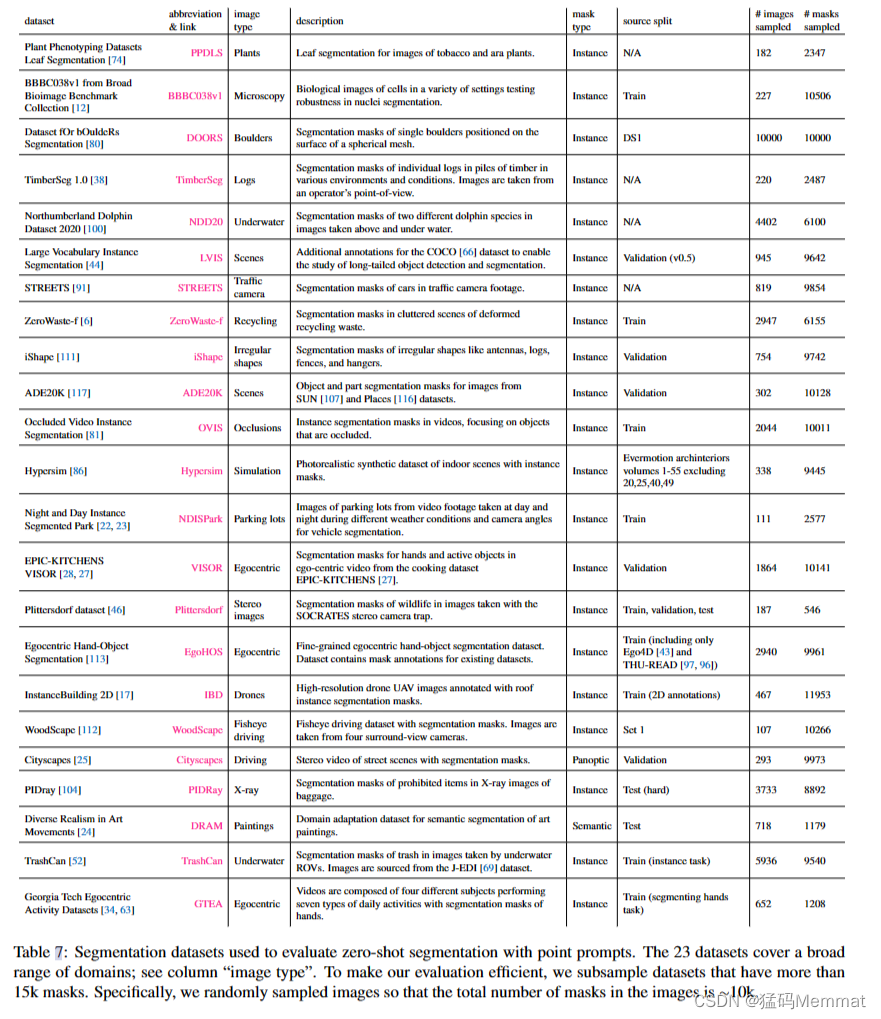
分割数据集用于评估零镜头分割与点提示。23个数据集涵盖了广泛的领域;见“图像类型”栏。为了使我们的评估高效,我们对掩码超过15k的数据集进行了子抽样。具体来说,我们随机采样图像,使图像中的掩码总数为~ 10k。

BSDS500上的零镜头边缘预测的额外可视化。回想一下,SAM没有被训练来预测边缘图,并且在训练期间没有访问BSDS图像和注释。
D.2. Zero-Shot Edge Detection
Dataset and metrics

我们在BSDS500上进行了零镜头边缘检测实验[72,3]。每张图像的基本真相来自五个不同主题的手动注释。我们使用边缘检测的四个标准指标[3,32]报告了200个图像测试子集的结果:最佳数据集规模(ODS),最佳图像规模(OIS),平均精度(AP)和50%精度的召回率(R50)。
Method

对于zero-shot transfer,我们使用简化版本的自动蒙版生成管道。我们用前景点的16×16规则网格提示SAM,它产生768个预测掩模(每个点三个)。我们不通过预测借据或稳定性进行过滤。网管移除冗余的掩码。然后,我们对剩余的掩模的非阈值概率图应用Sobel滤波器,如果它们不与掩模的外边界像素相交,则将值设置为零。最后,我们对所有预测取逐像素的最大值,将结果线性归一化为[0,1],并应用边缘NMS[13]来细化边缘。
Visualizations

在图15中,我们展示了来自SAM的零射击边缘预测的其他示例。这些定性的例子进一步说明了SAM如何倾向于输出敏感的边缘图,尽管没有经过边缘检测的训练。我们看到边缘可以很好地与人类注释对齐。虽然,如前所述,由于SAM没有进行边缘检测训练,因此它不会学习BSDS500数据集的偏差,并且经常输出比基础真理注释中存在的更多的边缘。
D.3. Zero-Shot Object Proposals
Dataset and metrics

我们报告了LVIS v1验证集[44]上1000个提案的掩码的标准平均召回(AR)指标。由于LVIS为1203个对象类提供了高质量的掩码,因此它为对象提议生成提供了具有挑战性的测试。由于我们模型的开放世界性质,我们专注于AR@1000,这可能会产生许多有效的掩码,甚至在LVIS中的1203类之外。衡量在频繁、常见和罕见事件上的表现
gory,我们使用AR@1000,但与只包含相应LVIS类别的ground truth集进行度量。
Baseline

我们使用级联ViTDet-H作为基线,这是AP在LVIS上使用的[62]中最强的模型。如正文所述,在域内训练的对象检测器可以“游戏”AR[16],并且有望成为比其他专注于开放世界提案或分割的模型更强大的基线[58,105]。为了产生1000个提案,我们在三个级联阶段禁用得分阈值,并将每个阶段的最大预测数提高到1000。
Method

我们使用改进版的SAM的自动掩码生成管道进行零镜头传输。首先,为了使推断时间与ViTDet相当,我们不处理图像裁剪。其次,我们消除了预测IoU和稳定性的过滤。这留下了两个可调参数,以获得每张图像约1000个掩码:输入点网格和NMS阈值重复掩码抑制。我们选择64×64点网格和0.9的NMS阈值,平均每个图像产生约900个掩模。在评估时,如果在一张图像中提出了超过1000个掩码,则根据其置信度和稳定性分数的平均值对它们进行排名,然后截断到前1000个建议。

我们假设SAM输出多个掩码的能力对于这项任务特别有价值,因为召回应该受益于从单个输入点在多个尺度上生成的建议。为了测试这一点,我们比较了一个只输出一个掩码而不是三个掩码的烧蚀版本SAM (SAM - single-output)。由于该模型产生的掩码更少,我们进一步将采样点数和NMS阈值分别增加到128×128和0.95,平均每张图像获得约950个掩码。此外,单输出SAM不会在自动掩码生成管道中产生用于为NMS对掩码进行排名的IoU分数,因此掩码是随机排名的。测试表明,这与更复杂的掩码排名方法具有类似的性能,例如使用掩码的最大logit值作为模型置信度的代理。

LVIS v1上的零镜头实例分割。SAM生产的masks质量比ViTDet高。SAM作为一个zero-shot模型,没有机会学习到具体的训练数据偏差;参见右上方的例子,其中SAM进行了模态预测,而LVIS中的基本真理是模态的,因为LVIS中的掩码注释没有洞。
D.4. Zero-Shot Instance Segmentation
Method

对于零镜头实例分割,我们用完全监督的ViTDet-H在COCO和LVIS v1验证分割上的输出框提示SAM。我们应用一个额外的掩码优化迭代,通过将最可信的预测掩码连同框提示符一起提供给掩码解码器,以产生最终的预测。我们在图16中展示了在LVIS上预测的零镜头实例分割。与ViTDet相比,SAM倾向于生产更高质量的口罩,边界更清洁。我们在§7.4中的人体研究中证实了这一观察结果。请注意,作为一个零镜头模型,SAM不能学习数据集中的注释偏差。例如,我们看到SAM对板进行了有效的模态预测,而LVIS掩模不能通过设计包含孔,因此板是模态注释的。
D.5. Zero-Shot Text-to-Mask
Model and training

我们使用最大的公开可用的CLIP模型[82](viti - l /14@336px)来计算文本和图像嵌入,我们在使用之前对其进行了归一化。为了训练SAM,我们使用数据引擎前两个阶段的掩码。此外,我们丢弃所有面积小于1002像素的蒙版。我们用大规模抖动[40]训练这个模型,进行了12万次迭代,批大小为128。所有其他训练参数遵循我们的默认设置。
Generating training prompts

为了提取输入提示符,我们首先将每个掩码周围的包围框随机从1×扩展到2×,对扩展框进行平切以保持其纵横比,并将其大小调整为336×336像素。在将作物馈送到CLIP图像编码器之前,我们以50%的概率将蒙版外的像素归零。为了确保嵌入的焦点在对象上,我们在最后一层使用掩码注意力来限制从输出标记到掩码内图像位置的注意力。最后,我们的提示符是输出令牌嵌入。对于训练,我们首先提供基于clip的提示,然后是额外的迭代点提示来细化预测。

从SAM的潜在空间中可视化掩模嵌入的相似性阈值。一个查询由洋红色框表示;上一行显示低阈值匹配,下一行显示高阈值匹配。同一图像中最相似的掩码嵌入通常在语义上与查询掩码嵌入相似,即使SAM没有使用显式语义监督进行训练。
Inference

在推断过程中,我们使用CLIP文本编码器,不做任何修改,为SAM创建提示。我们依赖于文本和图像嵌入由CLIP对齐的事实,这允许我们在使用基于文本的提示进行推理时,在没有任何显式文本监督的情况下进行训练。
D.6. Probing the Latent Space of SAM

最后,我们进行了初步调查,定性地探测SAM学习的潜在空间。特别是,我们感兴趣的是SAM是否能够在其表示中捕获任何语义,即使没有使用显式语义监督进行训练。为此,我们通过从SAM中从掩码周围的图像裁剪及其水平翻转版本中提取图像嵌入来计算掩码嵌入,将图像嵌入乘以二进制掩码,并在空间位置上求平均值。在图17中,我们展示了同一图像中查询掩码和类似掩码(在潜在空间中)的3个例子。

我们观察到,每个查询的最近邻显示出一些(尽管不完美)形状和语义相似性。虽然这些结果是初步的,但它们表明来自SAM的表示可能对各种目的有用,例如进一步的数据标记、理解数据集的内容或作为下游任务的特征。
E. Human Study Experimental Design

在这里,我们描述了§7.1和§7.4中用于评估口罩质量的人体研究的细节。人体研究的目的是解决使用借据来验证真相作为预测面具质量的衡量标准的两个局限性。第一个限制是,对于模棱两可的输入,例如单个点,模型可能会因为返回与基本真相不同的对象的有效掩码而受到严重惩罚。第二个限制是地面真相掩模可能包括各种偏差,例如边缘质量中的系统错误或对模态或模态分割遮挡对象的决定。在域内训练的模型可以学习这些偏差并获得更高的IoU,而不必产生更好的面具。为了缓解这些问题,人工审查可以获得独立于底层真实掩码的掩码质量度量。
Models

对于单点评估,我们使用RITM[92]、单输出SAM和SAM来检验两个假设。首先,我们假设,当给定一个单点时,SAM比基线交互式分割模型产生了视觉上更高质量的掩模,即使在诸如IoU等具有基本真相的指标没有揭示这一点的情况下。其次,我们假设SAM消除模糊掩码的能力提高了单点输入的掩码质量,因为单输出SAM可能会返回比模糊掩码平均的掩码。
例如分割实验,我们评估级联ViTDet-H[62]和SAM,以测试SAM产生视觉上更高质量的掩码的假设,即使它由于无法学习验证数据集的特定注释偏差而获得较低的AP。
Datasets

对于单点实验,我们从23个数据集中选择了7个数据集,因为完整的数据集太大,无法进行人工审查。我们选择LVIS v0.5[17]、VISOR[28,27]、DRAM[24]、IBD[17]、NDD20[100]、OVIS[81]和iShape[111],它们提供了多种图像集合,包括场景级图像、自我中心图像、绘制图像、头顶图像、水下图像和合成图像。此外,这组数据集包括SAM在IoU指标上优于RITM的数据集,反之亦然。例如分割实验,我们使用LVIS v1验证集,允许直接与在LVIS上训练的ViTDet进行比较。
Methodology

我们将由模型生成的掩码呈现给专业注释者,并要求他们使用提供的指南对每个掩码进行评级(完整指南参见§G)。注释者均来自同一网站 为数据引擎收集手动注释掩码的公司。向注释器提供对图像、单个模型的预测掩码和模型输入(单个点或单个框)的访问权限,并要求根据三个标准判断掩码:掩码是否对应于有效对象?口罩有干净的边界吗?和掩码是否与输入对应?然后,他们提交了从1到10的评分,表明口罩的整体质量。

得分为1表示掩码根本不对应任何对象;低分数(2-4)表示该面具存在较大的误差,例如包含了大面积的其他物体或有大面积的无意义边界;中等分数(5-6)表示掩码大部分是合理的,但仍然有显著的语义或边界错误;得分高(7-9)表示掩码只有轻微的边界错误;10分是指没有明显错误的面具。注释器提供了5个不同的视图,每个视图都用于帮助识别不同的错误类型。
对于单点实验,每个数据集从用于零镜头交互分割基准的相同子集中随机选择1000个掩码(见§D)。参阅这些子集的详细资料)。模型输入为最中心点,计算为到掩模边缘的距离变换的最大值。例如分割实验,从LVIS v1验证集中选取1000个掩码,模型输入为LVIS ground truth box。在所有实验中,尺寸小于242像素的掩模都被排除在采样之外,以防止向评分者显示太小而无法准确判断的掩模。由于内存和显示原因,在预测掩码之前,大图像被重新缩放到最大边长为2000。在所有实验中,向每个模型输入相同的输入以生成预测的面具。

为了进行比较,每个数据集的地面真相掩码也被提交进行评级。对于单点实验,这为每个数据集提供了4000个评级作业(RITM、SAM单输出、SAM和地面真相各1000个掩码);例如分割实验,它提供了3000个工作(ViTDet, SAM和ground truth)。
对于每个数据集,这些作业以随机顺序插入到一个队列中,其中有30个注释器绘制作业。在回顾研究的初始测试中,我们将每个工作提供给五个不同的注释者,并发现分数的合理一致性:五个注释者得分的平均标准偏差为0.83。此外,注释公司还部署了质量保证测试人员,对部分结果进行抽查,以确定是否与指导方针有极大的偏离。因此,在我们的实验中,每一项工作(即对一张图像中的一个掩码进行评级)都只由一个注释器完成。每个注释器每个作业花费的平均时间为90秒,比我们最初的目标30秒要长,但仍然足够快,可以在7个选定的数据集上收集大量评级。
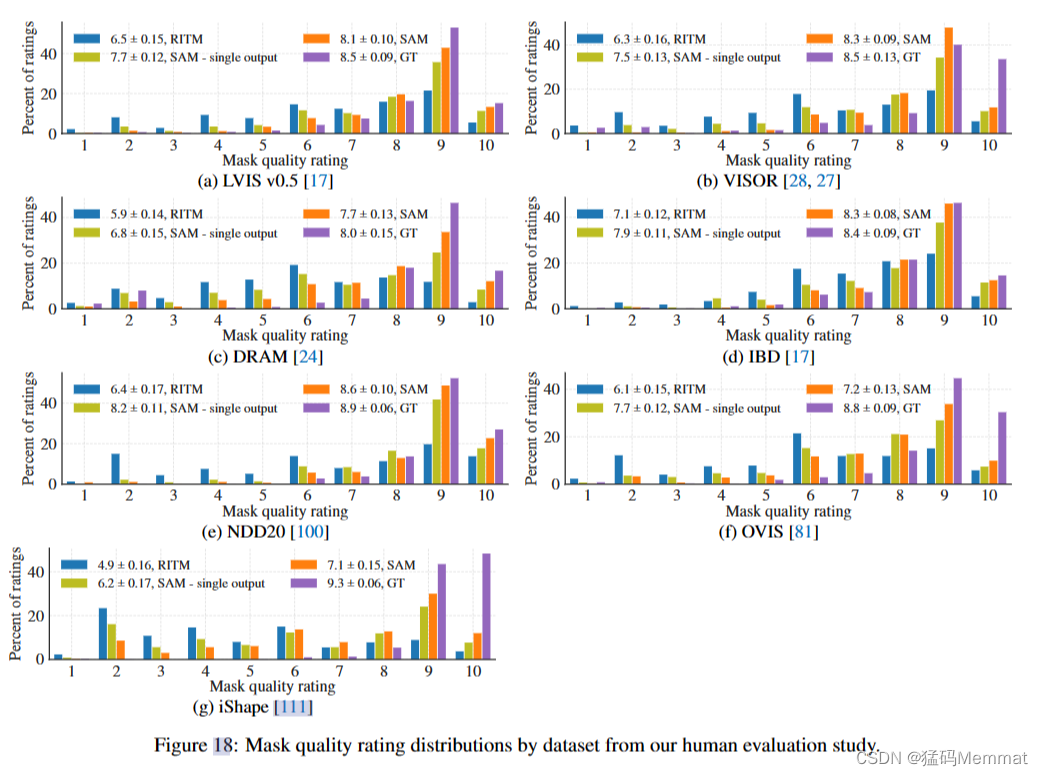
根据我们的人体评估研究数据集,口罩质量评级分布。
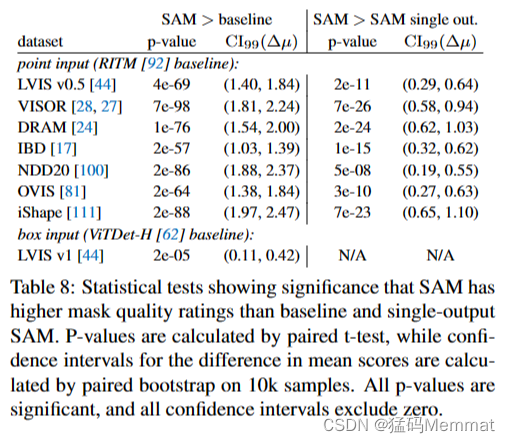
统计测试显示显著性的SAM具有比基线和单输出SAM更高的掩膜质量评级。p值通过配对t检验计算,均值分数差异的置信区间通过配对bootstrap在10k个样本上计算。所有的p值都是显著的,并且所有的置信区间都不为零。
Results

在单点实验中显示每个数据集评级的直方图。

我们对两个假设进行了统计测试:(1)SAM获得比基线模型(RITM或ViTDet)更高的分数,(2)SAM获得比单输出SAM更高的分数。p值是通过对模型得分的均值进行配对t检验来计算的,我们对10k个样本进行配对bootstrap检验,以找到均值差的99%置信区间。表8显示了这些测试的p值和置信区间。所有统计检验都是强显著的,所有置信区间都不为零。
以分割为例,正文的图11显示了评级的直方图。为了与COCO地面真相进行比较,我们还包括了在人工审查过程测试中收集的794个COCO地面真相面具评级。这些掩模使用与LVIS结果相同的设置呈现给评分者。为了公平的比较,图11中LVIS的结果对每个模型和ground truth的相同794个输入进行了次采样。对于表8,使用完整的1000个评级来运行统计测试,这表明SAM的掩模质量优于ViTDet具有统计学意义。
F. Dataset, Annotation, and Model Cards

我们为SA-1B提供了一个数据集卡,如下[39],在问题和答案列表中。接下来,我们在§F中提供一个数据注释卡。2对于§4中描述的数据引擎的前两个阶段,遵循CrowdWorkSheets[30],再次作为问题和答案列表。我们在表9中提供了一个模型卡[75]。
F.1. Dataset Card for SA-1B

…
F.2. Data Annotation Card





在这里,我们提供了完整的指导方针,给注释的掩模质量的人工审查。为了便于发布,一些图像被轻微编辑,人脸被模糊处理。最佳放大观看(1 / 2)。
G. Annotation Guidelines

我们在图19和图20中提供了完整的指导方针,用于人工评审口罩质量。


在这里,我们提供了完整的指导方针,给注释的掩模质量的人工审查。为了便于发布,一些图像被轻微编辑,人脸被模糊处理。最佳放大观看(2 / 2)。
源自:
@article{kirillov2023segment,
title={Segment anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C and Lo, Wan-Yen and others},
journal={arXiv preprint arXiv:2304.02643},
year={2023}
}
![【群智能算法改进】一种改进的白鲸优化算法 改进白鲸优化算法 改进后的EBWO[1]算法【Matlab代码#40】](https://img-blog.csdnimg.cn/164772a6af594cf7a82202000bacd957.png#pic_center)







![[CKA]考试之网络策略NetworkPolicy](https://img-blog.csdnimg.cn/b9a8666f0046416b91e8a71a6eb9d114.png)