原文链接:https://openreview.net/pdf?id=US-TP-xnXI
ICLR 2021
介绍
问题
大多数解决结构性预测的方法都是在预训练模型上对特定的任务进行训练,存在两个局限性:
1)判别分类器不能很好地利用预训练模型中对于该任务标签的已知知识。例如,知道person能够写一本书就能轻松的学习到author在句子中的关系。然而,由于辨别模型的目标是分类,往往不会用标签语义进行训练(也就是没有使用标签的words,而是使用一些简写字母来标记实体类型),因此并不会有这种转移能力(也就是并不能get到person和author之间的关系)。
2)辨别模型只能用于特定的任务,想要将一个模型去解决多个任务或者在不改变辨别器的情况下从一个任务迁移到其他任务,都是非常困难的。
IDEA
基于以上问题,作者考虑能否设计一个结构来解决不同的结构性预测,同时利用预训练模型中关于标签语义的潜在知识?
1)使用增强的自然语言作为一种方法去统一多个任务,即对输入输出进行限制来使得模型能够解决多个结构性预测类任务(感觉这不就是prompt?)。
2)标签语义的利用,例如在命名实体识别中人名直接使用person进行标记,而不是像其他模型中用PER这种标签进行标记。因为预训练模型中可能已经学习到了关于这种标签的相关知识。
方法
作者提出的模型框架在三个不同结构化预测任务下的流程如下图所示:

Augmented语言的方法使其能够轻易地对结构化信息进行编码,并且将输出的文本也解码为结构化的信息。
Augmented natural languages
使用实体和关系抽取任务这个例子来解释增强的自然语言框架。首先,这个任务的目的就是从给定句子中提取出一系列的实体以及这些实体之间的关系。
下面通过以下例子来进行具体的说明:

这个任务中,使用”[]“token来标记一个实体及其可能的关系,使用“|”将实体和关系进行分隔,关系表示为X=Y的形式,X表示关系类型,Y表示另一个实体(客体)。
作者选择在原句子上进行标记,是为了减少句子中同一实体时出现多次时的歧义。这里对实体以及关系的描述都是用的natural words (如person、location)而不是PER, LOC这种标记,就是为了充分利用预训练模型中对这些单词的潜在知识。
其他任务中,额外的信息作为输入的一部分,比如语义角色标注中的实体span(如上图中的粉色框)。
Nested entities and multiple relations
嵌套实体和多关系任务中的输入输出结构,如下例子所示:

实体“lithium toxicity”是一种“disease”,而“lithium”的类型是“drug”。因此“lithium toxicity”包括了两种关系:一是与实体“acyclovir”的effect关系,二是实体“lithium”的effect关系。
Decoding structured objects
模型按增强的自然语言方式产生输出,并按以下步骤对句子中包含预测的结构化对象进行解码得到预测的结构化对象:
1)移除所有的特殊token,并且提取实体类型和关系,得到一个干净的输出(cleaned output)。如果生成的句子中存在无效的格式,则该部分将会被丢弃。
2)使用动态路由算法来对输入的句子和leaned output进行token级的匹配,来识别原句子中的实体对应的token,作者认为该过程能够提升模型的鲁棒性。
3)对于输出的每个关系,为其寻找与预测的客体匹配的最近的实体,如果找不到,该关系则被丢弃。
4)丢弃掉不属于与数据集类型list的实体或者关系。
用以下例子来解释步骤2中的动态路由对齐:
 可以发现输出中包含了一个拼写错误的实体词“Aciclovir”(正确的应该为scyclovir),cleaned output中的“Aciclovir”被标记为“A-cicl-o-vir”,与输入中的“a-cycl-o-vir””相匹配,因此推断该词为“acyclovir”。(acyclovir和aciclovir是同义词)
可以发现输出中包含了一个拼写错误的实体词“Aciclovir”(正确的应该为scyclovir),cleaned output中的“Aciclovir”被标记为“A-cicl-o-vir”,与输入中的“a-cycl-o-vir””相匹配,因此推断该词为“acyclovir”。(acyclovir和aciclovir是同义词)
Multi-task learning
TANL允许在包括不同任务的多个数据集上训练一个模型。只需在每个输入句子中加入数据集的名字,后面加上任务分隔符“:”作为前缀。(例如,“ada:”)
Categorical prediction tasks
对于关系预测这类任务,常规的方法就是计算所有可能分类的分数并将最高分作为预测类别,由于该模型是一个生成类模型,因此作者使用输出序列的似然来代替分类分数,并且作者认为后者能够增加模型在低资源情况下的鲁棒性。
STRUCTURED PREDICTION TASKS
这部分对多个结构化预测任务的输入输出格式进行了解释。联合命名实体识别和关系提取已在Augmented natural languages部分进行了解释,因此不再赘述。
Named entity recognition (NER):该任务为联合命名实体识别和关系提取的子任务。
Relation classification:输入一句包含主体和客体的句子,对它们之间的关系进行分类。由于主体不一定在客体的前面出现,因此对于该任务,在原句子后加入一句:“the relationship between【head】and 【tail】is”。如下例子所示:

Semantic role labeling (SRL):输入一句带有谓词标记的句子,去预测句子其他的参数及其类型。每个参数都对应于和谓词有特定关系的一连串标记(如主语、位置或者时间)。以下例子中,“sold”就是标记的谓词。
![]()
Event extraction:该任务要求提取出 1)event triggers,每一个触发器都表明发生在真实世界的事件;2)trigger arguments,表明与每个触发器相关的属性。
以下例子中,有两个事件triggers:“attacked”和“injured”。triggers检测使用与NER相同的形式,argument提取时,一次只考虑一个trigger。在输入句子中标记trigger及其类型,输出格式与联合命名实体识别和关系提取相似。

Coreference resolution:该任务将表示同一实体的单个文本span进行分组(感觉就是代词解释)。

Dialogue state tracking (DST):该任务输入的是一段用户和客服之间的对话,需要输出对话的状态。如下例子所示:

输入用户和客服之间的对话使用"【user】:"和'【agent】:"进行标记,使用【belief】对输出进行标记。当对话内容没有涉及到的(即如果输入中没有用户回答的two,则输出中的duration 则是not given),使用【not given】进行标记。
实验
对比实验
作者使用三种数据集设定:1)单个数据集;2)同一任务的多个数据集;3)多个任务的多个数据集;总体实验结果如下所示:

在单个任务的设置下,作者提出的模型在多个数据集上的表现都达到了最优。在coreference resolution任务上,TANL的表现与之前使用BERT-base的模型(除了CorefQA)效果相似。但作者认为TANL是第一个不需要单独的mention proposal 模块的模型,以及不强制执行最大mention length的端到端模型。并且,作者提出的方法可以不修改模型只使用一个架构来执行多个任务。
多任务模型在coreference resolution上的表现较差,因为该任务的输入会比其他任务更长,并且我们模型的最大序列长度是512tokens,但是coreference数据集中是1536tokens的输入,2048个tokens的输出,因此输入就会进行分割,也就降低了模型的性能。
低资源实验和消融实验
作者为了测试模型在低资源情况下的表现,使用CoNLL04数据集上部分(0.8%-6%)数据进行训练的结果如下图所示(a):
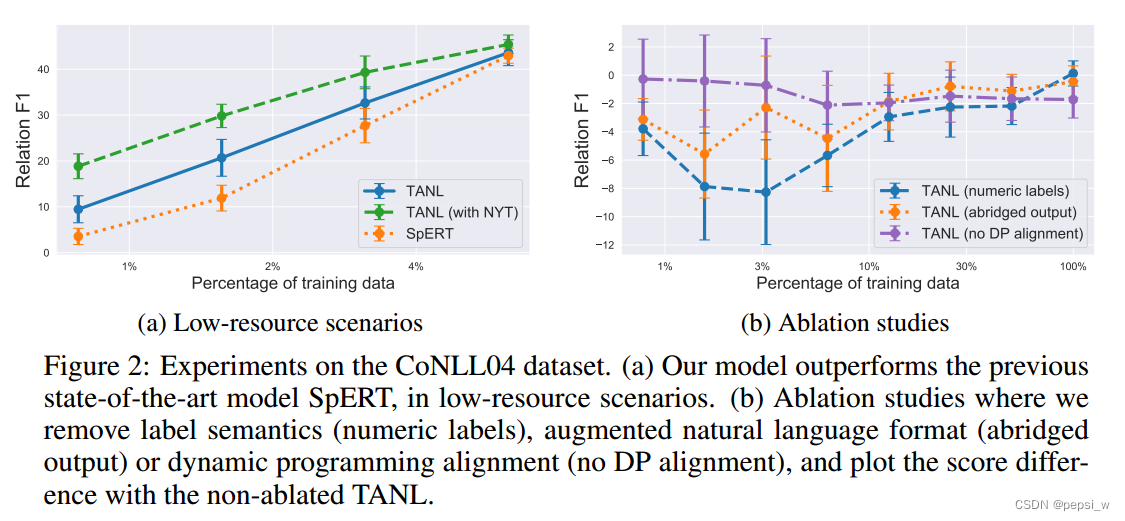
其中在低资源的情况下(训练集只有9-72个数据),TANL的表现比SpERT要好(在使用完整训练集时,性能相似),绿色的线表示在NYT数据集上进行预训练后,迁移到该数据集上的表现。
对标签语义、结构化增强语言(就是输入输出的结构)、对齐这三个方面进行消融实验,结果如下图所示(b)。Numeric labels: 使用数字代替自然单词进行标记实体类型。Abridged output:使用一种不重复整个输入句子的格式进行输出;No DP alignment: 使用精确的单词匹配代替动态编码对齐。
可以看出在低资源的情况下,标签语义对于模型性能的影响是最大的。(但是这里怎么使用全部的训练数据,代替其中一种方法的F1都这么低?不至于吧?)
总结
使用text-to-text的生成模型来解决NLP中的结构化预测任务,训练一个模型就能解决多个任务,并且使用标签的nature word来进行标记(这个能不能运用到其他任务上啊?会提高模型的性能吗?),尽可能地利用了预训练模型中潜在知识。另外,实验也证明提出的模型在低资源的情况下,表现出较强的竞争力。
tips:题目中的translation 指的就是模型在输入的句子上做了 augmented(即加上了标注),最后将输出解码为预测的结构化对象。(做特别说明是因为我最开始以为是常见的语言翻译,其实这也是翻译,一种语言翻译为另一种结构的语言。)