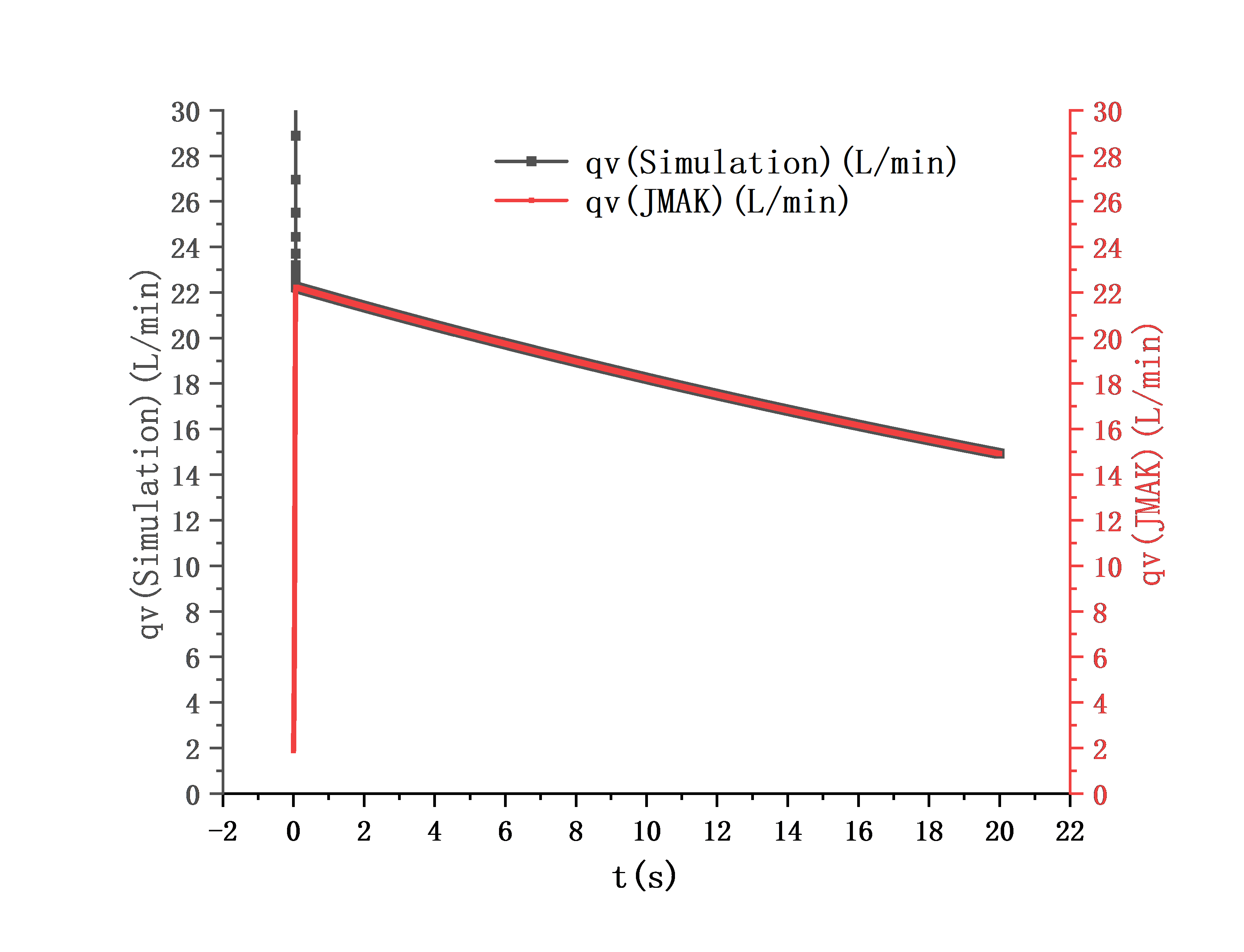
🔗 课程链接:李樾老师和谭天老师的:南京大学《软件分析》课程03(Data Flow Analysis I)_哔哩哔哩_bilibili
南京大学《软件分析》课程04(Data Flow Analysis II)_哔哩哔哩_bilibili
这篇文章总结了两节课程的内容,方便对比。
目录
第三章 数据流分析的应用 Data Flow Analysis--Application
3.1 什么是数据流分析 (Data Flow Analysis)
3.2 数据流分析的预备知识
3.2.2 传递函数约束的表示方法
3.2.3 Control Flow的约束规则的表示
3.3 可达性分析 (Reaching Definitions Analysis)
3.3.1 Reach Definitions 的基本概念
3.3.2 Reaching Definitions分析流程
1. Abstraction——怎么表示Reaching Definitions
2. Transfer function 转换函数
3. Control Flow 控制分析
3.3.3 Reaching Definitions Analysis 的算法
3.3.4 举个例子🌰
3.3.5 总结⭐
3.4 存活变量分析 (Live Variables Analysis)
3.4.1 基本概念
3.4.2 Live Variables分析流程
3.4.3 算法
3.3.4 举个例子🌰
3.5 可用表达式分析 (Available Expressions Analysis)
3.5.1 基本概念
3.5.2 Available Expressions 分析流程
1. Abstraction
2. Transfer function 转换函数
3. Control Flow 控制分析
3.5.3 算法
3.5.4 举个例子🌰
3.6 总结
第三章 数据流分析的应用 Data Flow Analysis--Application
3.1 什么是数据流分析 (Data Flow Analysis)
Data Flow Analysis 研究的是 How Data Flows on CFG? 即数据流是如何在控制流图中运行的。实际上,不同的数据流分析应用面对的Data是不一样的。例如上一章中分析的【正负零】的问题中,关注的data就是正负零,通过CFG(a program)中的边(control flows)和节点(BBs/statementes)进行分析。
第一节课里讲过,绝大多数静态分析是牺牲了completeness,来追求soundness,但是精度不能保证。但是从技术层面来讲,静态分析可以从两个方面来把握,对Data做Abstraction,和对Flows做Safe-approximation。这里要引入两个概念may analysis和must analysis:
may analysis 和 must analysis:
- may analysis:输出的信息may be 正确(over-approximation)(也就是说这个程序在动态运行时的所有路径行为,在静态分析的时候都应该包含进来。)
- must analysis:输出的信息must be 正确(under-approximation)
不管是over- 还是 under- approximations 都是为了分析的安全性,也是正确性,我们不能分析是错的,所以这里写成Safe-approximation,这里的Safe 就可以理解为,当分析是
- may-analysis:safe = over
- must-analysis:safe = under
在CFG中无非是边和节点,第一章1.5 中曾经提到过对于节点,要做转换函数,对边,要做control-flow handing。

由此可以看出来:不同的数据流分析应用有不同的抽象方法(data abstraction),也有不同的对流的安全近似策略(flow safe-approximation),也就会定义不同的转换函数(transfer functions)和控制流处理方案(control-flow handlings)。
可以回顾第一章的内容:【软件分析/静态分析】学习笔记01——Introduction_HiLittleBoat的博客-CSDN博客
3.2 数据流分析的预备知识
3.2.1. 输入输出状态(Input and Output States)
如下图所示,在一个程序块的语句s1 执行之前,程序的状态,用IN[s1]来表示,s1执行之后,程序的状态用OUT[s1]表示。不同类型语句之间的IN和OUT状态有不同的关系,如下图从左到右分别是顺序执行、分叉、合并。

例如,在顺序执行语句中,s1的OUT状态就是 s2的IN状态。
合并中的
代表meet的时候的操作符号,可能是∪也可能是∩……需要根据程序情况
由此,输入输出的性质:
- 每次IR块的执行,都将一个旧的input state转换为一个新的output state。
- 每一个input(output) state都和一个在IR块前(后)的程序点(program point)相对应
在静态分析中,我们想要达成的效果就是:
每一个数据流分析的应用中,我们会将每个程序点(program point),关联一个数据流的值(data-flow value) 这个数据流值代表了对该点所有可能的程序状态的抽象。
老师PPT原句是:
In each data-flow analysis application, we associate with every program point a data-flow value that represents an abstraction of theset of all possible program states that can be observed for that point.
这句话很抽象,这里可以试着理解一下,在3.3.4中会结合具体的例子再次感受这句话,这里先举一个简单的例子:
例如,左边就是一个程序,红点就是一个个程序点,我们会对每个程序点都关联一个 程序分析的结果(data-flow value),这些结果是前期抽象域里的值(+- 0等):

宏观上看,数据流分析(Data-flow analysis)的目的是:为所有语句s 的IN[s]和OUT[s]找到一组,基于控制流和传递函数的,安全的-近似约束的解决方案。
老师PPT原句是这样的:
Data-flow analysis is to find a solution to a set of safe-approximation-directed constraints on the IN[s]'s and OUT[s]'s, for all statements s.
- constraints based on semantics of statements (transfer functions)
- constraints based on the flows of control这句话很抽象,简单来说就是:
程序当中所有的语句,都需要找到一个对应的IN OUT的解决方案,通过解析一系列的safe-approximation-directed的约束规则,所谓的约束规则,就是-基于语句语义的约束(转移函数)或- 基于控制流的约束
也就是说,我们通过不断地解这些转换函数和控制流信息的约束规则,最后会得到一个solution,这个solution会给每个语句的输入输出point 关联一个data-flow value
不太理解也没关系,在3.3.4 中有个例子,学完例子就能明白这句话的含义了,总结在3.3.5。这里只是一个总体的概览,但是这句话很关键。
3.2.2 传递函数约束的表示方法
Transfer Function的表示可以分为正向和反向两种
1. Forward Analysis:
正常的分析一般是正向传播的,即输出由输入根据IR块的转换函数决定,表示的方法如下图, 是语句s的转换函数:

2. Backward Analysis:
与之相对的是反向分析,同理,如下图

3.2.3 Control Flow的约束规则的表示
控制流的约束可以分为BB里边的,和BB之间的:
1. 一个 BB 里边的 Control flow:
假设有一个BB,里边有n条语句s1, s2, ……,每一个语句的输入其实是紧邻着上一条语句的输出,可以用以下符号来表示
意思就是,后一句的输入等于前一句的输出
2. BBs之间的 Control flow
实际上一个BB的IN,就是该程序块以一个语句s1的IN;如果是再汇聚的时候,所以可以得出以下表示:
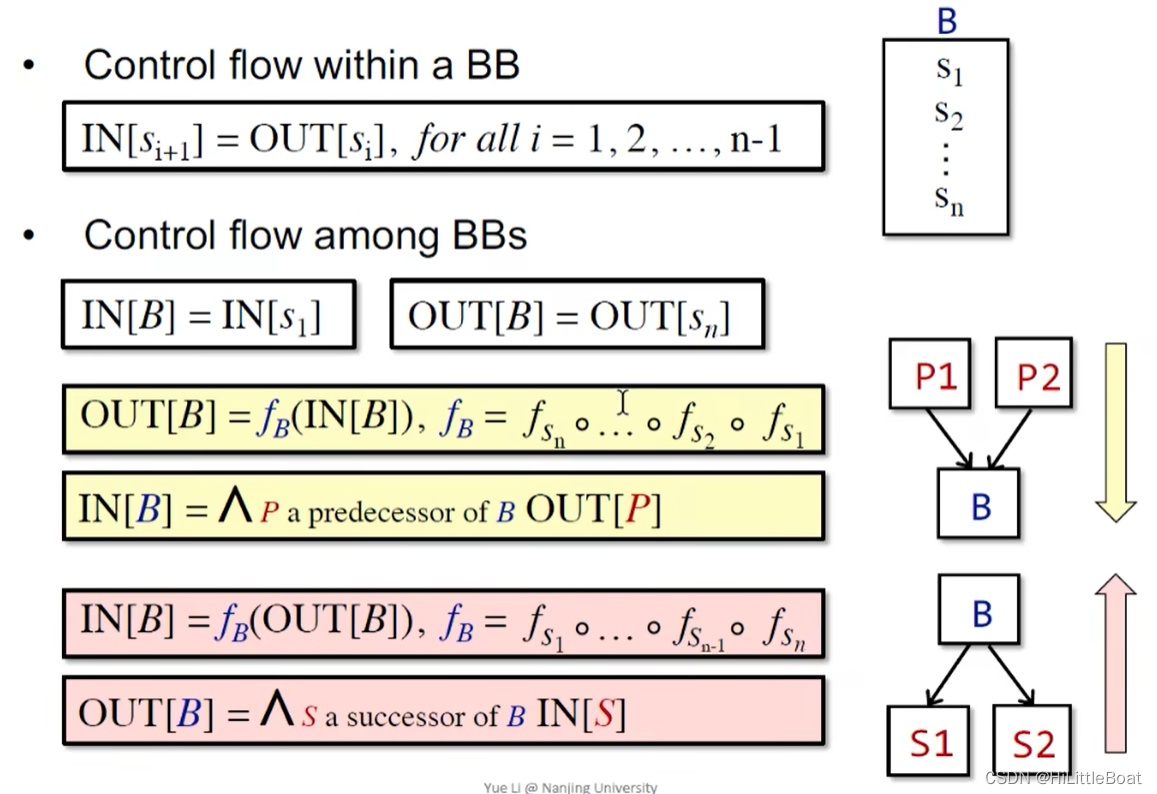
BBs间的控制流中 白色框框里的表示:
BB的输入等于其第一个语句的输入,BB的输出等于其最后一句的输出
黄色框表示正向的:
① 输出OUT[B] 由 输入IN[B] 经过运算
获得,其中
② 输入IN[B] 由 指向自己的所有的输出OUT 的union决定。
红色框表示反向的:
① 输入IN[B] 由 输出OUT[B]经过运算得到。
② 输出OUT[B] 由 所有的B的后继的输入IN 的 union决定。
3.3 可达性分析 (Reaching Definitions Analysis)
以下正式进入数据流分析的应用部分,接下来的3个小节,分别讲解了3个数据流的应用,通过这3个应用,能够更好地理解数据流分析的细节、理论。
3.3.1 Reach Definitions 的基本概念
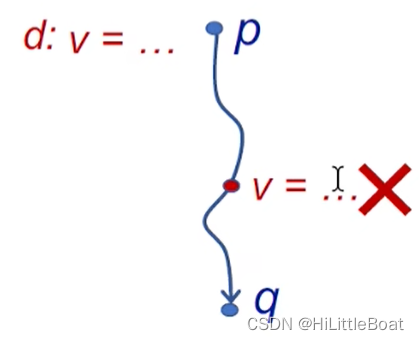
1. Reach 的定义
如果在程序中有一条从p到q的路径,在点p处的定义d在该路径上不会被 "杀死",则称定义d可以从点p reach 点q。
换句话说就是:在p处定义变量v, 这个变量v从点p可以 reach 到 q,并且在这条路径中,v不会被重新定义。如下图所示:
2. 为什么要进行可达性分析?(作用/应用)
Reaching definitions 的其中一个作用是:可以用来检测可能存在的、未定义的变量。例如说,在CFG的入口处(entry)为每一个变量v引入一个虚拟定义,如果v的虚拟定义能从入口处reach 到使用v的点,那么这个变量就有可能为定义就使用。(因为 undefined作为点p reach到了 使用v的点q)
思考一下,这个是may analysis还是 must analysis呢?
答案是may analysis,因为如果运行时候,可能其他路径上是没有问题的,当时有这样一条没有定义,我们就会报这个错,不放过任何一条路径。
3.3.2 Reaching Definitions分析流程
前面的内容也曾说到,做分析的时候要做abstraction、safe-approximation,(做abstracion也就是再研究其表示形式),做safe-approximation的时候,主要从transfer function、Control Flow。这小节就通过这几个步骤来更好地理解Reaching Definitions
- Abstraction
- Safe-approximation
- Transfer Function
- Control Flow
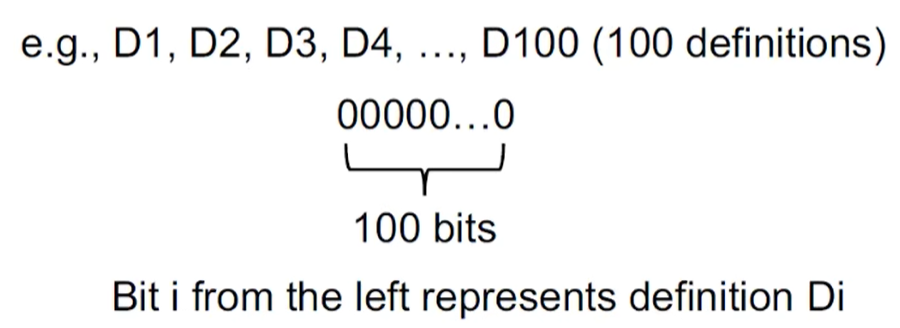
1. Abstraction——怎么表示Reaching Definitions
在数据流分析中,我们会关注所有变量的定义,可以用bit编码来表示在某个程序点上的多个Reaching Definitions。如下图所示,表示从左数第i个字节就表示第i个definition即Di,Di 如果为0,则表示Di无法reach到该程序点,Di为1,则表示Di可以reach该程序点。
2. Transfer Function转换函数
怎么用Definition 进行程序分析?
我们先看一个语句的例子,如下面这个语句,我们用D 来表示变量v 的定义Definition,op是 x 与 y 的之间的操作运算符
D: v = x op y
该语句的主要作用就是:①“生成”变量v的定义D,②并“杀死”程序中定义变量v的所有其他定义,同时其余传入定义不受影响。
把这句话当成一个Basic Block,用符号的形式表示这条语句的作用,就得到了其转换函数 Transfer Function:
![]()
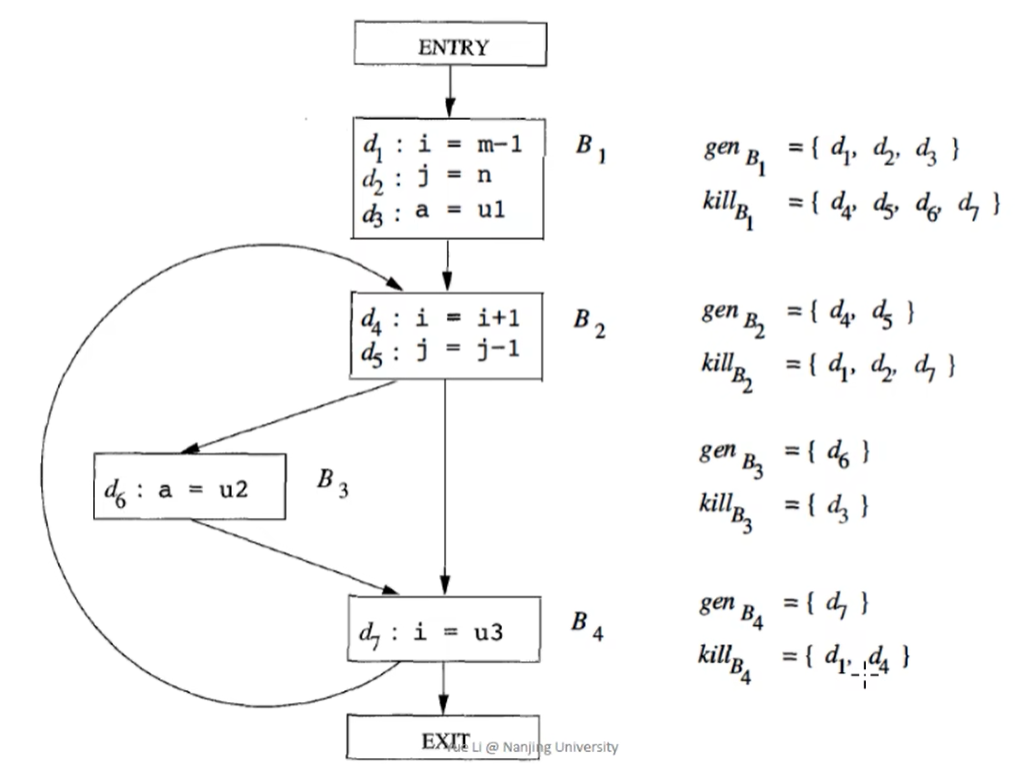
举个例子,如下图所示,比如:
gen B1 就是生成三个变量的 定义{d1, d2, d3},
kill B1 就是去掉B1中的变量 i, j, a 再其他地方的所有定义,如 i 在d4 d7处有定义,j 在d5处有定义,a 在 d6 处有定义,所以kill B1 就是{d4, d5, d6, d7}
3. Control Flow 控制流处理
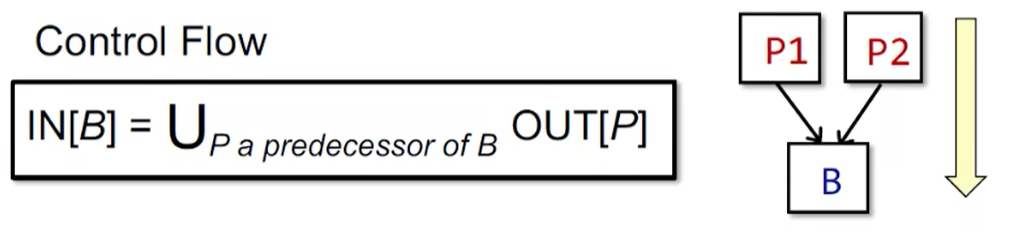
如图,这是一个forward analysis,也是一个may analysis,是over-approximation。因为,结合前文的使用bit字节表示的D的方法,这里的IN[B] 是由其所有前驱节点的 OUT状态 求并集得到(union)。这里意味着只要存在一条路径可以reach,那么就算是可以reach的。
3.3.3 Reaching Definitions Analysis 的算法
这里先将伪代码贴出来,看不懂没关系,后续会结合例子进行更深入的了解。
INPUT: CFG (kill[B] and gen[B] computed for each basic block B)
OUTOUT: IN[B] and OUT[B] for each basic block B
METHOD:
// 初始化入口
OUT[entry] = Φ;
// 初始化每个基础块B
for (每个除了entry之外的basic block B)
OUT[B] = Φ;
while (有 OUT 发生改变){
for (每个除了entry之外的basic block B){
// 入口处合并,使用flows of control的约束
IN[B] = ∪p OUT[p]; // p是B的每一个前驱节点
// 出口处转换,使用transfer function的约束
OUT [B] = gen[B] ∪ (IN[B] - kill[B])
}
}根据代码,这里会为每一个块进行初始化,任何对每个节点的IN 和OUT 程序点处的状态进行更新,直到没有值发生变化这里先抛出来几个问题:
1. 初始值的设定
entry的OUT状态初始化为空,每个Basic Block 的出口状态,也初始化为空,为什么不合并在一起?
这里的伪代码是通用的,只是may analysis是一样的,must 的 可能是不一样的:
一般来说,may analysis 的初始化,是将入口节点的OUT和每个块的OUT 都置为空集,
must analysis 的初始化,是将入口节点的OUT置空,而每个块的OUT置为上限top。
2. 这个while循环真的能停下来吗?
这个问题的答案,放在3.3.5中,先看完3.3.4 的例子 之后再来理解这个问题。
3.3.4 举个例子🌰
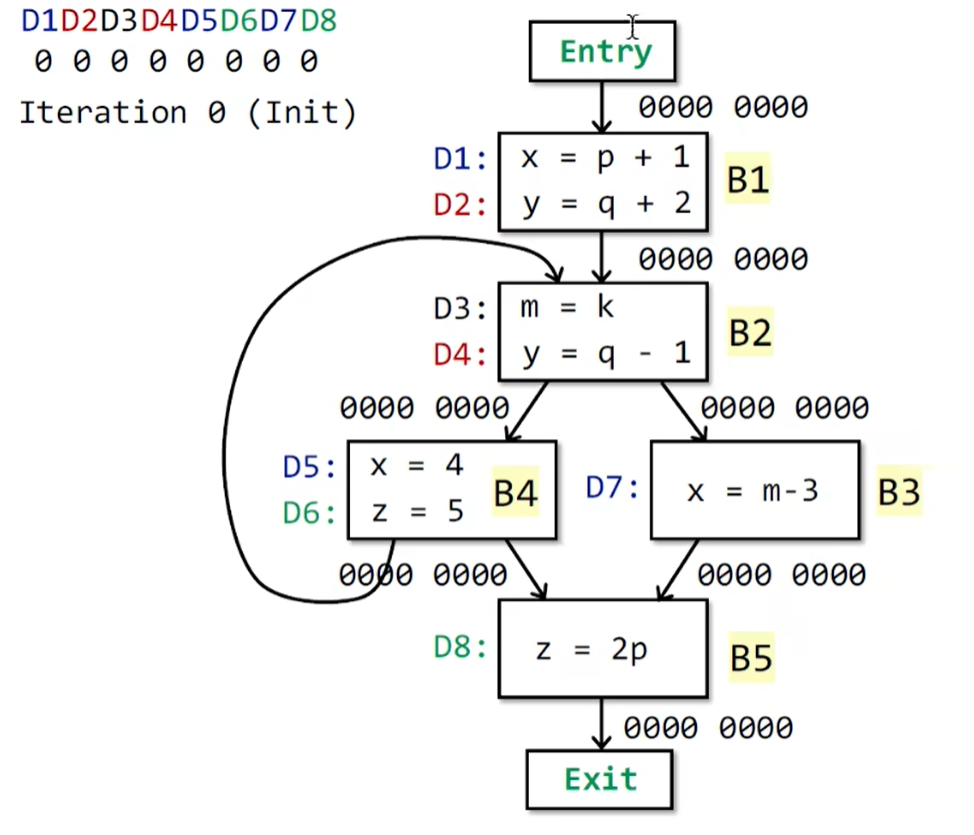
1. 初始化
如下图,D是每个语句上的变量的定义,不同颜色代表不同的变量,这里有8个definition,就用8个bit来进行表示,B是程序块。
2. 第一轮循环:
这里举一个例子,其他的就可以自行推敲了。
例如说B1的,根据transfer function:![]() ,这里的
,这里的
· gen[B1] = {D1,D2},所以第1,2个 bit 置为1,
· kill[B1]={D5,D7,D4},
IN[B1]-kill[B1]:就是将 IN[B1]上 kill 的这3个D置为0,最后再与gen[B1]相并,就得到了B1的OUT值:1100 0000
需要注意的是B2的IN处,是合并的,也就是将B4的OUT 和B1的OUT进行合并,这里B4还没有计算过所以还是0000 0000,B1的结果是已经算出来的 1100 0000,相并,就得到B2 的IN值仍为1100 0000.
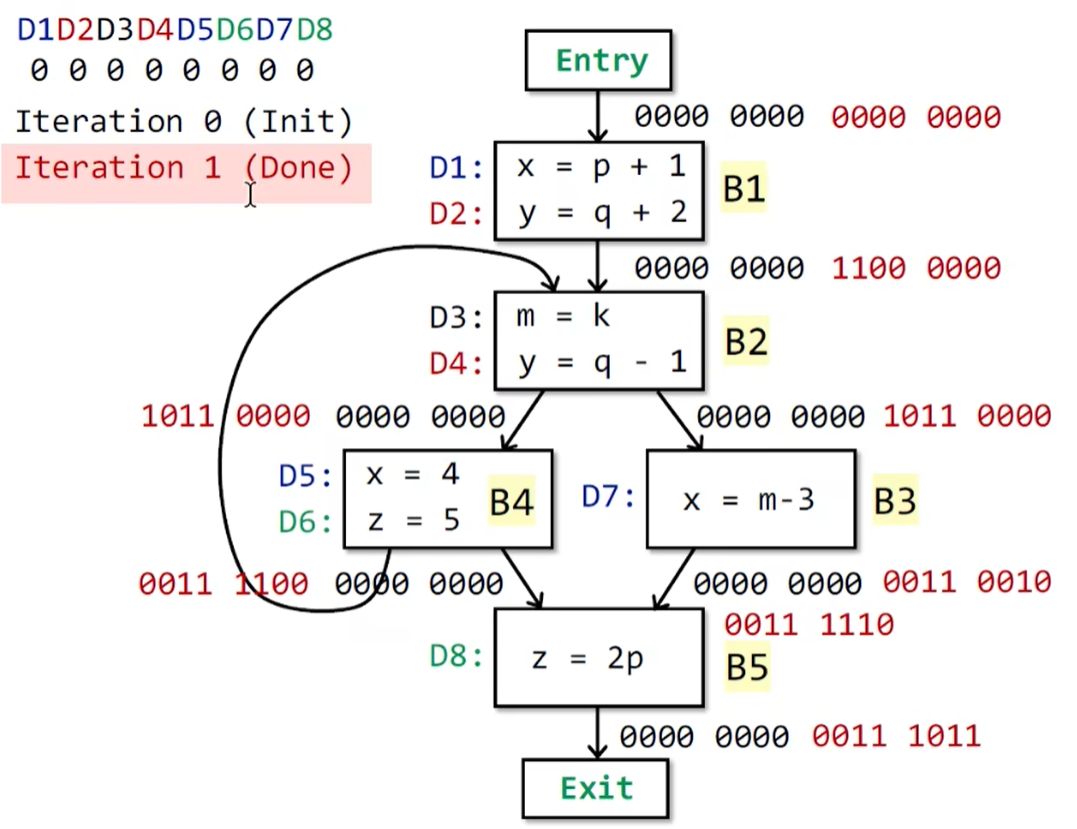
如图黑色是初始结果,红色为第一次遍历后的结果,这里很多BB 的 OUT值都有变化,所以会有第2轮循环。
3. 第2、3轮循环:
规则跟第一轮是一样的,结果如下图所示蓝色为第2轮,绿色高亮为第3轮:

第三轮之后,已经没有BB的OUT值发生改变的,所以循环终止,绿色高亮的即为最终结果。
3.3.5 总结⭐
1. 得到的结果有什么用?
RAD 可以用于死代码消除,例如说,在上边的例子中,赋值语句D1可以到达的点分别是B1 B2 的OUT,而B1 和B2中的语句,没有用到过D1定义的变量x,所以赋值语句D1在这个程序中就是一条死代码,没有什么用,可以删除。
2. 遗留问题:循环一定会停下来吗?
其实根据上述的例子还有transfer funtion,可以发现,一个程序中的 gen 和 kill 是不会变的,当IN发生变化的时候,其OUT值才会跟着变。
初始化的时候,所有的OUT都是全0,每个块 kill 的 是一样的,所以不管多少次循环,这个块的 OUT与前一次循环的OUT相比 只会增长,而不会缩小(某个D的变化只会从0 -> 1,或者 1 -> 1,而不会 从1->0)
这些可能增长的状态,成为下一个块的IN,再形成下一个块的新OUT,同样也是只会增长,不会缩小。
这里忽略了合并的控制流处理,因为合并也只会让1变多,而不会有1->0。
而一个程序中的赋值语句D是有限个的,所以最坏情况就是OUT 增长为满集(全为1)然后OUT就不会再发生变化,循环就停下了。
当算法所有的OUT集不发生变化时,称这个状态为该算法的不动点(fixed point)。

3. 总结⭐
结合这个3.3.4中的例子,我们再去感受一下3.2.1中 高亮的两句话,就可以理解了:
在这个例子中, data-flow value 即每个程序点处的 bit 序列,代表程序在这一点的状态的抽象,在这里就是每个definition 在这个点能不能reach 到的一个抽象。

也就是说,我们不停的应用transfer functtions 还有 flow在分叉的时候怎么做的规则,直到算法停止下来的时候,得到一个solution,(即 图中绿色标绿的分析结果。)

这两句话很重要,适用于所有的常见的data-flow analysis,以后我们就可以依照这两句话取关联所有的数据流分析。
3.4 存活变量分析 (Live Variables Analysis)
LVA与上小节的可达性分析很像,这里采用跟上小节一样的学习过程,方便进行对比
3.4.1 基本概念
1. 定义
Live variables analysis tells whether the value of variable v at program point p could be used along some path in CFG starting at p. If so, v is live at p; otherwise, v is dead at p.
存在一条path,且在这条路径上有使用v的地方,想知道变量v 在程序点p处是否是存活的。
这里有一条隐藏的要求,就是v在这条path中,v没有被重新定义redefined.

2. 为什么要进行存活变量分析?(作用/应用)
这里举例一个典型的应用场景:在执行一个程序的过程中,所有的寄存器已经满了,想要执行下一条操作语句,就需要替换到已经存进去的,我们就需要知道,哪些变量从当点位置到程序结束都不会再用到。
注意,如果一个变量在使用之前被重新赋值 ,那么从赋值到上一次使用之间,该变量不算live
存货变量分析关注的是variable变量,上节课讲的可达性分析关注的是definition定义
3.4.2 Live Variables分析流程
这小节依旧通过这几个步骤来更好地理解分析流程
- Abstraction
- Safe-approximation
- Transfer Function
- Control Flow
1. Abstraction——怎么表示Live Variables
采取与可达性分析一样的方式,就是用bit编码,如果是1,代表是live的,这里不再赘述

在进行Safe-approximation的时候,我们先要思考一些问题:
Q: 怎么样扫描这段代码更方便?(从哪儿开始,到哪儿结束,按照什么方向?)
其实不管正向还是反向,都可以解决问题,只是效率不同,在可达性分析中,我们采用的是正向的,因为我们想要得到每个变量的定义是否能到这个位置。
如果这里,我们也采用正向分析,在执行到某一行代码的时候,其实是没法判断变量在这个点是否是存活的,只有往下继续执行,到程序结束 / 变量被重新定义 / 变量被使用,才可以知道刚刚那个点,该变量是不存活 / 不存活 / 存活的,然后返回去更改这些信息。显然正向分析效率是比较低的。
所以我们可以采用backward 来进行分析会更加方便。
2. Transfer Function转换函数的设计
如下图所示,以B块为例,用反向分析的话,就是已知OUT[B] = {v},也就是说B的出口处,变量v是存活的,那怎么样求IN[B]呢?
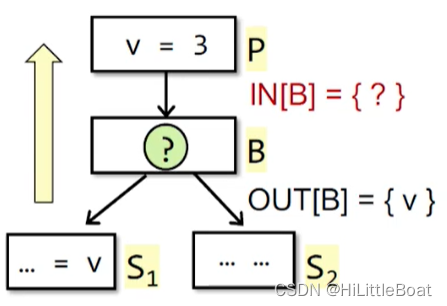
Tip: 在设计data flow analysis的时候,就想象一下其可能的情况,这样会更直观一点,比如,对于块B来说,只看v的话,如果OUT是已知要用到B 的,那B中不同的语句对IN会有什么影响呢,保留 or可以删除?
也就是需要讨论 变量v在 B 中的所有可能的情况:
①完全没有出现 --> v的情况与OUT保持一致,NO--> v 的情况不做改变
②被使用了 --> v保留,YES --> v 的值置为 1
③被重新定义 --> v可以删除,NO --> v 的值置为 0
④在同一语句中,被使用也被定义--> v保留,YES --> v 的值置为 1
⑤ 不同语句中,先被定义后被使用--> v可以删除,NO -->v 的值置为 0
⑥不同语句中,先被使用后被定义-->v保留,YES --> v 的值置为 1
如下图所示,这里先用集合来表示状态 Yes: IN[B]={ v } No: IN[B]={} ,已知OUT[B]为{v},只讨论变量v,不同B 的语句下IN 的值:
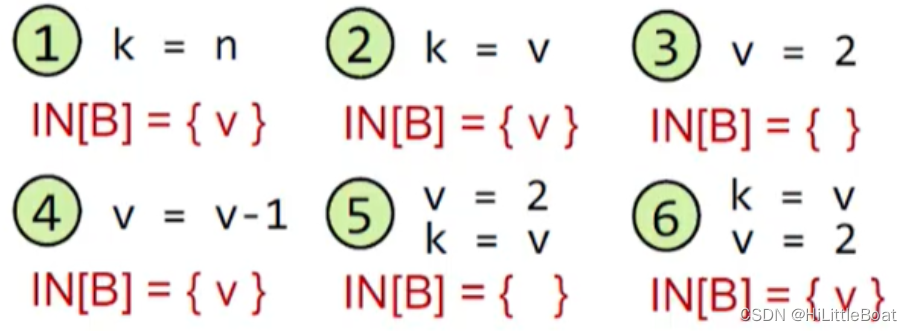
根据分析可以得出,Transfer Function的公式如下所示:

3. Control Flow 控制流处理
控制流分析起来,就很好理解了,对于有分支块B的OUT,需要将B的所有继承者的IN值进行union,然后在进行分析。
如下图所示,方框中第一个公式即为控制流处理的公式,第二个公式为转换函数的公式。

Q:这里可以思考一个问题,这个分析是may 还是must 呢?
答案是may analysis,因为只要有一个子节点中v是live的,总体就是live的,属于是may的。
3.4.3 算法
经过上述的分析,还有上小节的举例,这里的算法是类似的,就很好理解了:

需要注意的是,初始值的设定:首先这里的起点是Exit,设置为0,其余各个点,根据上述分析,也应该都是bottom,这里还是遵循可达性分析中,所讨论的初始值的情况:may analysis初始值都是bottom,must为top。
3.3.4 举个例子🌰
1. 初始化
如下图的程序,为7个变量,分7个bit,初始化,将所有块的IN 设为全0。

2. 第1轮循环
从下往上分析,这里依旧只举几个例子,其他就可以自行推敲了。
例如说B5,他的OUT值为全0,根据其语句块,z=2p,这里use了p,新定义def了z,所以就是将p置为1,然后kill掉新定义的z,根据转换函数:![]() ,得到最终IN[B5] 为000 1000。
,得到最终IN[B5] 为000 1000。
需要注意的是B4的OUT值有两个,第一轮,B4的左边的OUT仍为全0,需要先于右边的OUT合并,再根据B4的语句计算其IN。
另一个需要注意的是B3,这里的代码x=x-3,虽然重新定义了x,应该被kill掉,但是定义的时候使用了先前x,所以也use了,所以IN[B3]的x应该为1。
这里可以引出一个问题,到底是先增加use还是先减去def呢?
根据上述的分析,其实不难看出,是先减去def然后再加上use的,并且块内的语句也需要自下网上分析。

如上图所示,红色的即为第一次遍历结果,那么需不需要进行下一轮遍历呢?其实是需要的,因为这里的IN 有改变。
3. 第2、3轮遍历
规则跟第一轮一样,分析过程就不再赘述了,如下图所示,蓝色为第2轮结果,绿色高亮为第3轮结果,因为第三轮结束IN值没有再发生改变,所以停下,高亮绿色即为最终结果。

3.5 可用表达式分析 (Available Expressions Analysis)
3.5.1 基本概念
1. 定义
An expression x op y is available at program point p if (1) all paths from the entry to p must pass through the evaluation of x op y, and (2) after the last evaluation of x op y, there is no redefinition of x or y
也就是说,程序点p处的表达式x op y 是available(可替换的),需要满足两个条件:
- 从entry到p点的所有路径都必须经过x op y
- 最后一次使用了x op y 之后,没有再重新定义操作数x , y (如果被重新定义了,那原来的表达式x op y 中的x 和 y 就会被替换)
这个定义表示,如果在p处的表达式是available的,就可以将其替换为最后一次的运算结果,或者可以用于检测全局通用表达式,进行优化。
3.5.2 Available Expressions 分析流程
1. Abstraction
抽象的方法依旧是使用bit,这里的每个bit代表的是出现的表达式。

2. Transfer Function 转换函数的设计
如下图所示,这个块的IN里有一个表达式a+b,采用正向的分析,求OUT值,方法就是:
- kill : 将涉及块中被赋值的变量的表达式删去,例如这里被赋值的变量是a,所以要去掉a+b,
- gen : 将块中的新的表达式加入OUT,例如加入x op y
得到最终OUT就是 {x op y}

所以转换函数就是:
![]()
3. Control Flow 控制流处理
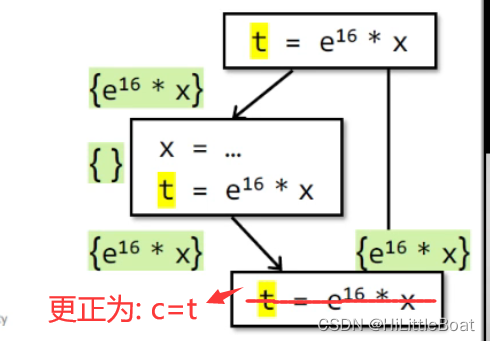
处理控制流的时候,可能会有所不同,如下图所示,有一个流程图。每个程序点的值已经用绿色高亮标出,这里再两条流进行合并的时候,会采用交集,也就是都有e^16 * x 的时候,才会让IN值为{e^16 * x }。

可是这里x值不是更改了嘛,为什么第二个程序块结束,还可以保留这个含x的表达式呢?其实这里我们需要根据定义使用,也就是说, 如果在程序 运行到第3个块的那个IN的点的时候,表达式e^16 *x 是available的,这里就可以有很多优化的方式,一种做法就是:将每个分支,用一个临时变量t 来hold 这个表达式的值,如下图所示,原来是a,b,这里可以用t来记录。然后在第3个块中,c值又取这个表达式的时候,就可以不计算,直接去取 t 的值,不用再重新计算了。所以,从哪条路径下来的,取到的t值就会是哪个路径上的,跟x更不更改,没有太大关系,因为 x= … 这句话之后的状态 其实是空的。
再如,没有b 那条赋值语句的话,左边分支走完会是空,而右边又一条语句是available的,但是取交集,第3块的IN值为空。
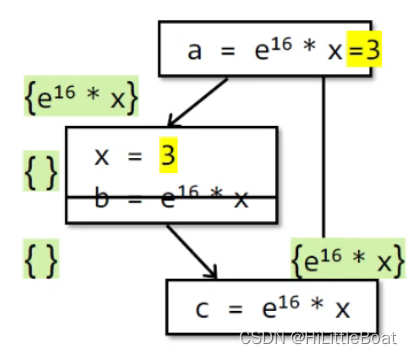
由此可以看出,这个分析是must analysis,也就是虽然,如果x跟前边的x都可能等于3,这里的哪怕经过了左边 分支,再到的赋值的时候,e^16 *x 依旧是可以available的,也可以优化,但是为了安全,我们就不做替换,漏报。
换句话说,就是,只有一定能优化的时候,才会优化。因为这个优化可能违反了第一原则:改变了源程序。
must 做的是under-approximation ,may是 over-approximation,但是不管是must还是may 都是为了safe-approximation,为了保证分析的安全性。
⭐所以得到控制流分析的公式如下:

3.5.3 算法
以下即为改分析的算法,这里也应该可以很好理解了。

与前两种分析算法形式类似,但是注意初始化有所不同。这里的初始化entry仍为空,但是每一个块的OUT值会设为全集,也就是全1。
3.5.4 举个例子🌰
1. 初始化
如下图的程序,有不同的5个表达式,分5个bit,初始化的时候,除了入口依旧为全零,其他块的OUT设为TOP,也就是全1
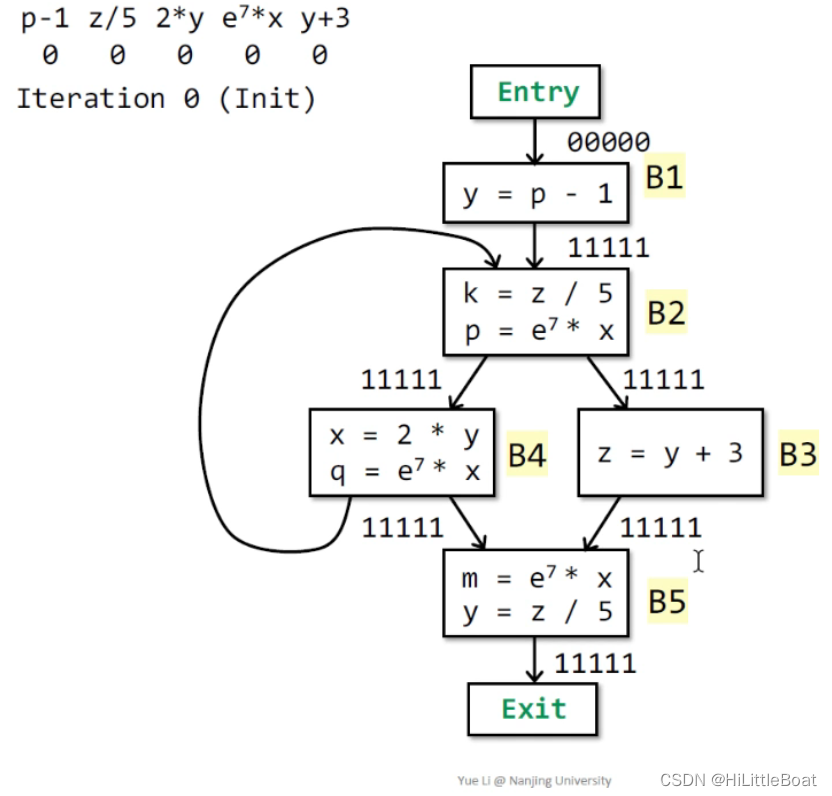
2. 第1轮循环
如下图所示,从上往下分析,这里也只举几个例子,其他的一定要自己分析一遍。
例如B1,初始IN为全0,然后这里有语句p-1,但是新定义了y,会将所有与y有关的表达式置为0,将p-1置为1,结果就是10000;
然后因为B2 的IN 有两条路,先要进行∩,也就是左边的还没计算,按照初始值11111,右边的是刚刚计算的10000,相交得到10000,然后再依据转换函数,将z/5 置为1,将所有用到k的表达式置为0,再将e^7*8 置为1,将用到p的p-1表达式置为0,得到01010。
注意,这里的分析,没有注意区分gen 和kill 的顺序,但是到底是先置为1,还是先kill掉成为0呢?
实际上不同语句之间是按照语句顺序进行的,例如说这里是自顶向下分析块,也就按照自顶向下分析每个语句
但是同一个语句呢?例如说x=x-1,这里是先kill掉还是,先gen呢?笔者认为,依据公式是先kill的,但是如果不对,还请讨论。
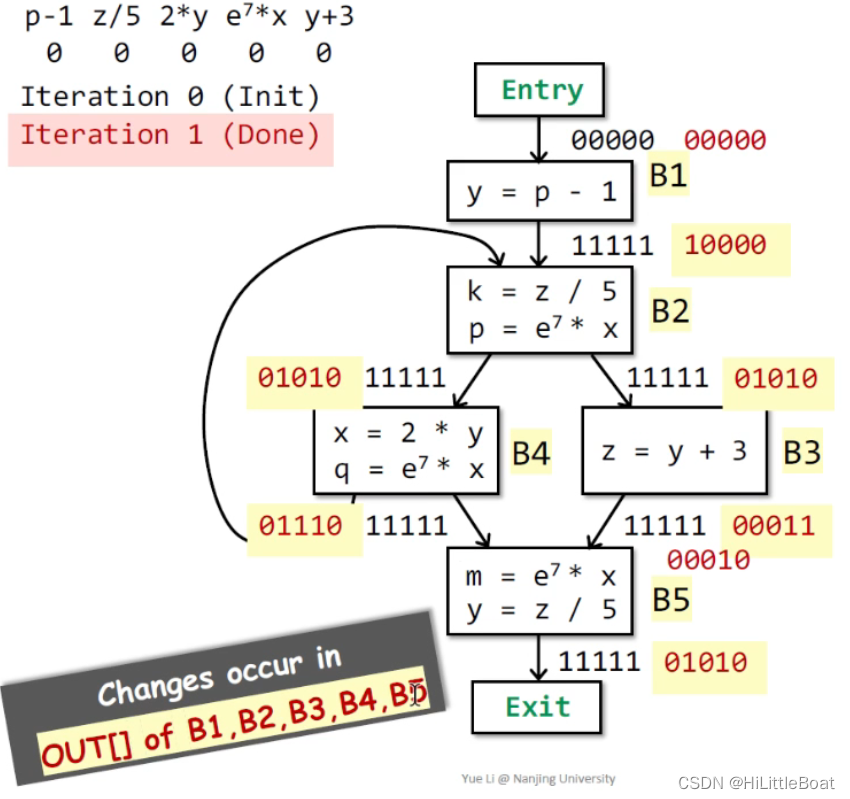
如上图,红色为第一轮的结果,这里有块的OUT值发生了改变,所以需要进行第二轮循环。
3. 第2轮循环
这里的过程就不再赘述,如下图,蓝色为第2轮分析的结果,与第一次的相比,没有改变的OUT,所以停下,蓝色即为最终结果。
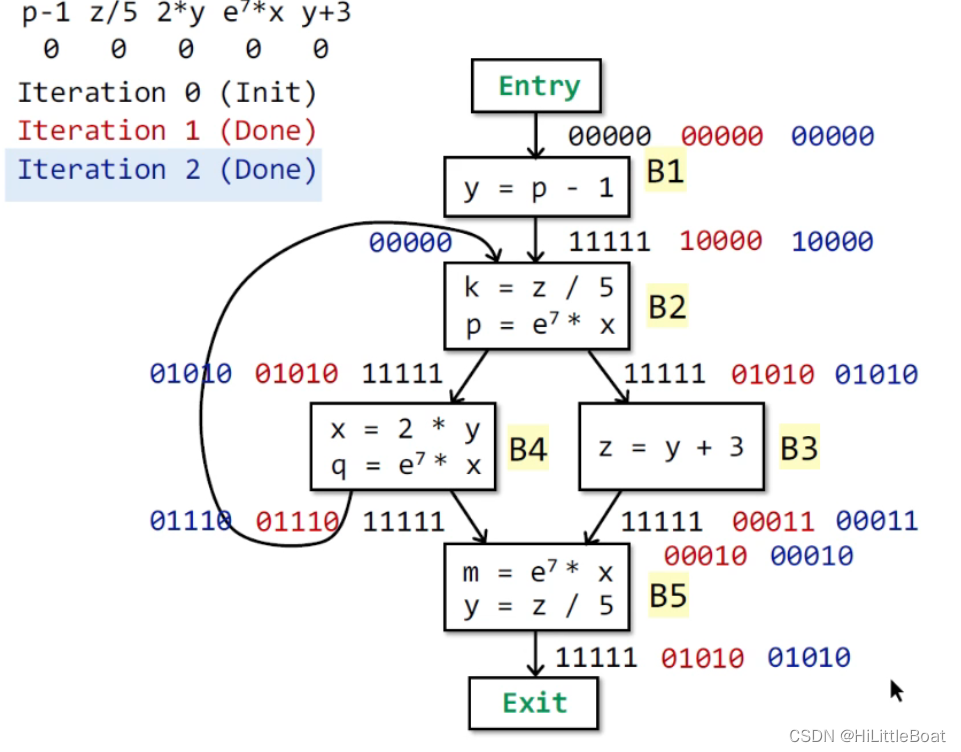
3.6 总结
1. 三种数据流分析的对比

2. 重点回顾
- 理解第3节课结尾的总结,也就是3.3.5 总结⭐部分的几个核心
- 理解三种数据流分析
- reaching definitions 定义可达性分析
- live variables 存活变量分析
- available expressions 可用表达式分析
- 能够说出这三种数据流之间的异同
- 理解迭代算法并了解为什么算法可以结束
写的很好的其他博主的文章:
数据流分析:存活变量分析(live variables analysis) - 知乎 (zhihu.com)【软件分析/静态程序分析学习笔记】4.数据流分析(下):存活变量分析(Live Variables Analysis)及可用表达式分析(Available Expressions Analysis)_童年梦的博客-CSDN博客
南京大学 《软件分析》04 Data Flow Analysis ApplicationsⅡ_南大可达定义分析_听雪的山椒鱼的博客-CSDN博客
❤️写在最后:
最近再看关于程序分析的相关知识,如果有对这方面的论文、课程,欢迎一起学习交流。文中如有不对的地方,欢迎批评指正~