目录
一、前言
二、Apache—DBUtils的引入
1.传统使用ResultSet的缺点 :
2.改进方法 :
3.改进方法的模拟实现 :
三、Apache—DBUtils的使用
1.基本介绍 :
2.准备工作 :
3.DBUtils查询(DQL) :
4.query方法源码分析 :
5.DBUtils处理(DML) :
四、总结
一、前言
- 第六节内容,up打算和大家分享一下JDBC——ApacheDBUtils相关的内容。
- 注意事项——①代码中的注释也很重要;②不要眼高手低;③点击文章的侧边栏目录或者文章开头的目录可以进行跳转。
- 良工不示人以朴,所有文章都会适时补充完善。大家如果有问题都可以在评论区进行交流或者私信up。 感谢阅读!
二、Apache—DBUtils的引入
1.传统使用ResultSet的缺点 :
1° 返回的结果集ResultSet与Connection是关联的,当调用Connection的close方法关闭连接后(放回连接池),ResultSet对象就不能用了。那么,如果出现“要求结果集复用”的需求,显然是办不到的。PS : 如果在关闭连接后仍调用ResultSet,会报异常,如下图所示 :
2° 就算是先用完ResultSet,再关闭Connection,ResultSet也只是使用了一次,这种对结果集的使用方式显然不利于数据的管理(说没就没)。
3° 传统使用ResultSet结果集的过程中,也让人感到不爽,如下图所示:
我们只能使用固定的格式getXxx来获取表中对应的字段,不但容易在传入形参时出纰漏,而且getInt,getString等也不符合我们“见名知意”的原则。

2.改进方法 :
之前在JDBC API详解中,我们提到——ResultSet在使用过程中,底层实际是将表中的记录存放在了ArrayLIst集合中。而我们知道,ArrayList底层其实就是一个Object类型的数组elementData。既然如此,我们为什么不把ResultSet结果集中的记录取出来,专门放到一个存放表记录的ArrayList集合中去呢?
于是,在这种念头的鼓动下,我们想出了以下的牛逼方法(不是我想出来的😂)——
创造一个Java类用于对应一张表,该类中所有的属性对应表中的所有字段,即该类的每个对象都表示了表中的一条记录。查询到表中有几条记录,就创建几个该类的实例,不同实例的属性可以自行设置。这样一来,我们只需要将该类的对象存放在ArrayList集合中,就实现了数据的“迁移”,结果集中的数据也得以复用。
以上,这样的一个类我们称为POJO, 或者Domain,或者一个你早已听过的名字——JavaBean类。
Apache—DBUtils就是为实现这种需求而诞生的一个工具类,它可以完美解决以上的问题。
3.改进方法的模拟实现 :
在使用Apache—DBUtils工具类之前,我们先简单模拟一下该方法。遵循上文“改进方法”中的思想。我们试着来查询fruit表,fruit表如下 :
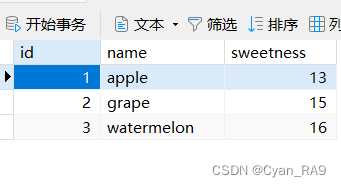
Fruit的JavaBean类如下 :
package apache_dbutils;
/**
MySQL的字段类型与JavaBean类属性的对应关系————
(1) 数值型——>包装类(允许为null)
(2) 字符串型——>String类
(3) 日期类型——>Date类
*/
public class Fruit {
private int id;
private String name;
private int sweetness;
public Fruit() {
}
public Fruit(int id, String name, int sweetness) {
this.id = id;
this.name = name;
this.sweetness = sweetness;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getSweetness() {
return sweetness;
}
public void setSweetness(int sweetness) {
this.sweetness = sweetness;
}
@Override
public String toString() {
return "\nFruit{" +
"id=" + id +
", name='" + name + '\'' +
", sweetness=" + sweetness +
"};";
}
}
接着我们在测试类中试着将Fruit类对象封装到ArrayList集合中,up以Advanced_Demo类为演示类,代码如下 :
package apache_dbutils;
import connection_pool.druid.JDBCUtilsDruid;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class Advanced_Demo {
public static void main(String[] args) {
//JDBC核心四部曲
//1.注册驱动(底层根据druid.properties配置文件自动注册了驱动)
//Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
//3.执行SQL
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
ArrayList<Fruit> fruitArrayList = new ArrayList<>();
String sql = "SELECT * FROM fruit " +
"WHERE `id` >= ?;";
try {
connection = JDBCUtilsDruid.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 0);
resultSet = preparedStatement.executeQuery();
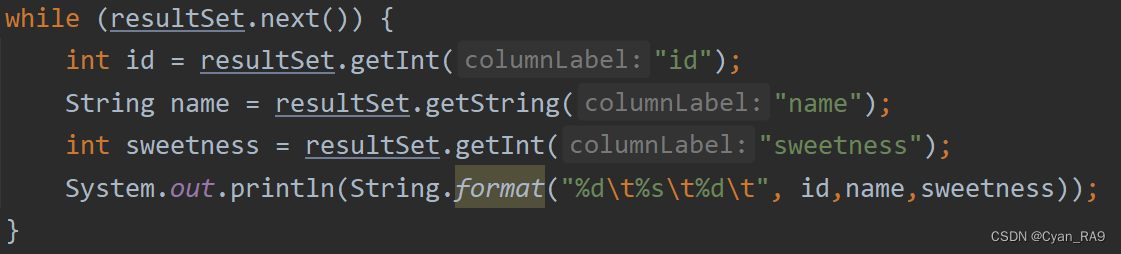
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int sweetness = resultSet.getInt("sweetness");
fruitArrayList.add(new Fruit(id, name, sweetness));
}
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
//4.释放资源
JDBCUtilsDruid.close(resultSet, preparedStatement, connection);
}
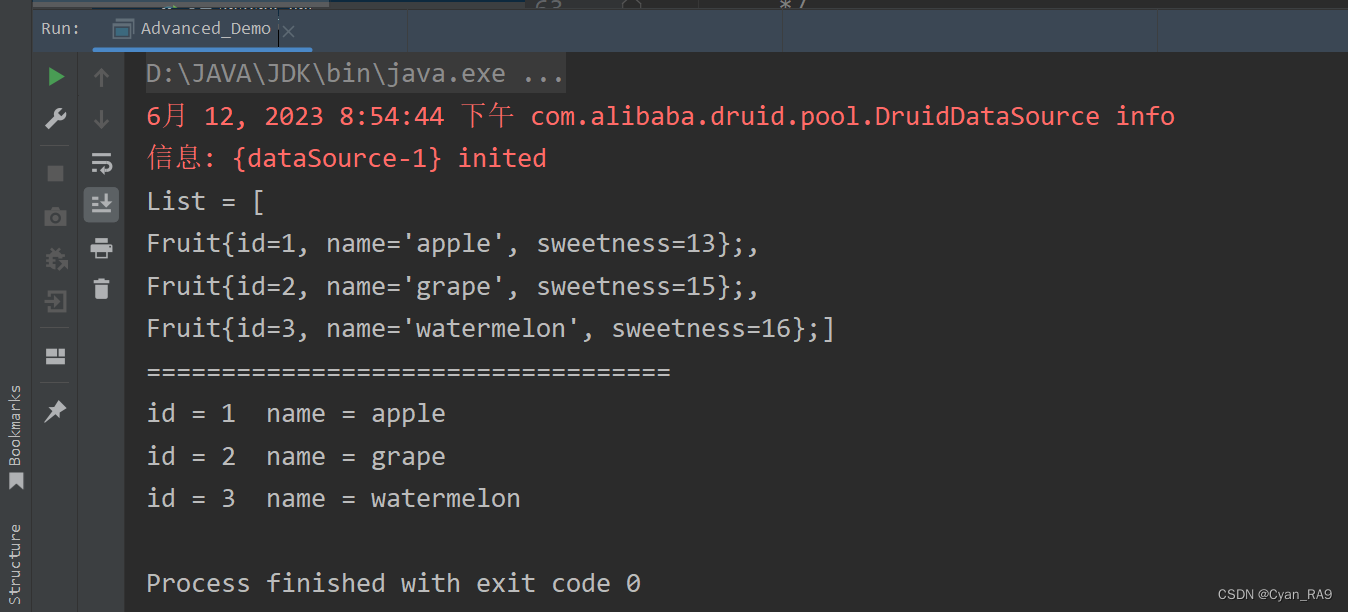
//关闭Connection后,轻松调用集合
System.out.println("List = " + fruitArrayList);
System.out.println("===================================");
for (int i = 0; i < fruitArrayList.toArray().length; i++) {
System.out.print("id = " + fruitArrayList.get(i).getId());
System.out.print("\tname = " + fruitArrayList.get(i).getName());
System.out.println();
}
/*
在某些情况下,我们甚至可以返回该集合其他调用者使用。
eg : return fruitArrayList;
*/
}
}
运行结果 :
三、Apache—DBUtils的使用
1.基本介绍 :
1° commons-dbutils是Apache组织提供的一个开源的JDBC工具类库,它是对JDBC的封装,使用dbutils能极大简化JDBC编程的工作量。
2° dbutils中常用的类和接口如下——
- QueryRunner类 : 该类封装了SQL的执行,并且是线程安全的;可以实现增删查改,并且支持批处理。
- ResultSetHandler接口 : 该接口用于处理java.sql.ResultSet,将数据按照要求转换为另一种格式。常见实现类如下 :
- ArrayHandler : 将结果集中的第一行数据转换成对象数组。
- ArrayListHandler : 将结果集中的每一行数据转换成对象数组,再存入List中。
- BeanHandler : 将结果集中的第一行数据封装到一个对应的JavaBean实例中(适用于返回单条记录的情况)。
- BeanListHandler : 将结果集中的每一行数据都封装到对应的JavaBean实例中,再存放到List集合中。
- ColumnListHandler : 将结果集中某一列的数据存放到List中。
- KeyedHandler(name) : 将结果集中的每行数据都封装到Map里,然后将所有的map再单独存放到一个map中,其key为指定的key。
- MapHandler : 将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
- MapListHandler : 将结果集中的每一行数据都封装到Map里,再存入List。
- ScalarHandler : 将结果集中的一列映射为一个Object对象,适用于返回单行单列的情况。
2.准备工作 :
先去谷歌搜一下commons-dbutils-jar,进入官网下载Apache_DBUtils的jar包,如下图所示 :
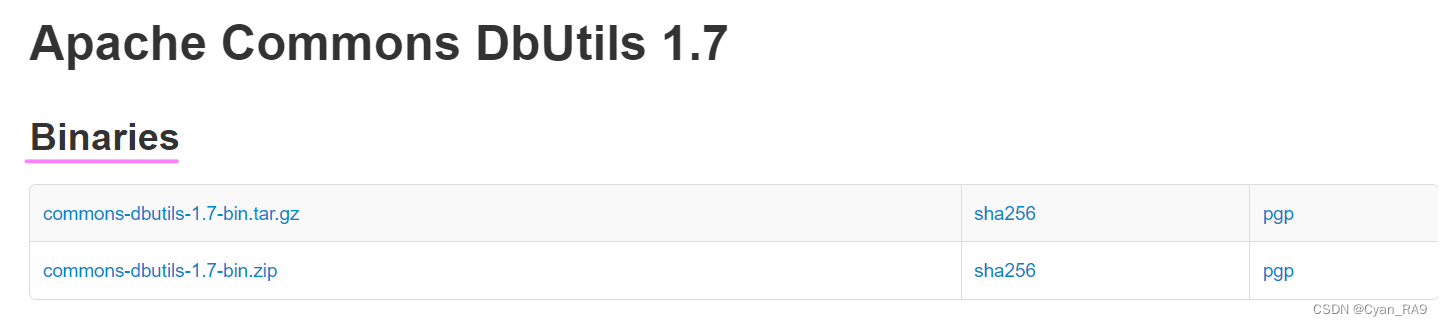
注意要选择Binaries,而不是Source,否则你下载的文件中没有jar包。
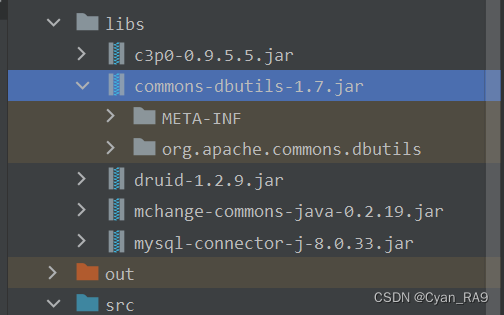
接着还是老规矩,将jar包复制到IDEA中存放jar包的目录下,然后导入当前项目,如下图所示 :
3.DBUtils查询(DQL) :
仍然操作fruit表,如下所示 :
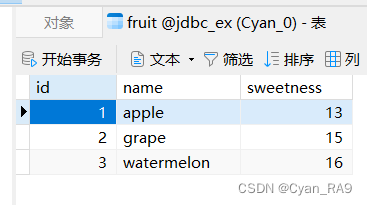
up以ApacheDBUtils_Demo1类为演示类,代码如下 : (注意看注释)
package apache_dbutils;
import connection_pool.druid.JDBCUtilsDruid;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class ApacheDBUtils_Demo1 {
public static void main(String[] args) throws SQLException {
//核心四部曲
//1.注册驱动(根据druid.properties配置文件自动注册)
//Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
connection = JDBCUtilsDruid.getConnection();
//3.执行SQL
QueryRunner queryRunner = new QueryRunner();
String sql = "SELECT * FROM fruit WHERE `id` >= ?;";
List<Fruit> query = queryRunner.query(connection, sql, new BeanListHandler<>(Fruit.class), 2);
/*
query方法复制执行SQL, 并将得到的结果集封装到ArrayList集合中, 然后返回;
PS : 底层得到的ResultSet结果集以及PreparedStatement会在query方法中自动关闭。
方法参数解读————
(1)connection : 当前使用的连接
(2)sql : 需要被执行的SQL
(3)new BeanListHandler<>(Fruit.class) : 底层通过反射机制获取到Fruit类的信息;
将ResultSet结果集中的每一条记录都封装到一个Fruit对象中,最后将这些对象
封装到ArrayList集合中。
(4)2 : 可变参数,传给sql中的?
*/
System.out.println("query = " + query);
//4.释放资源
JDBCUtilsDruid.close(null, null, connection);
}
}
运行结果 :
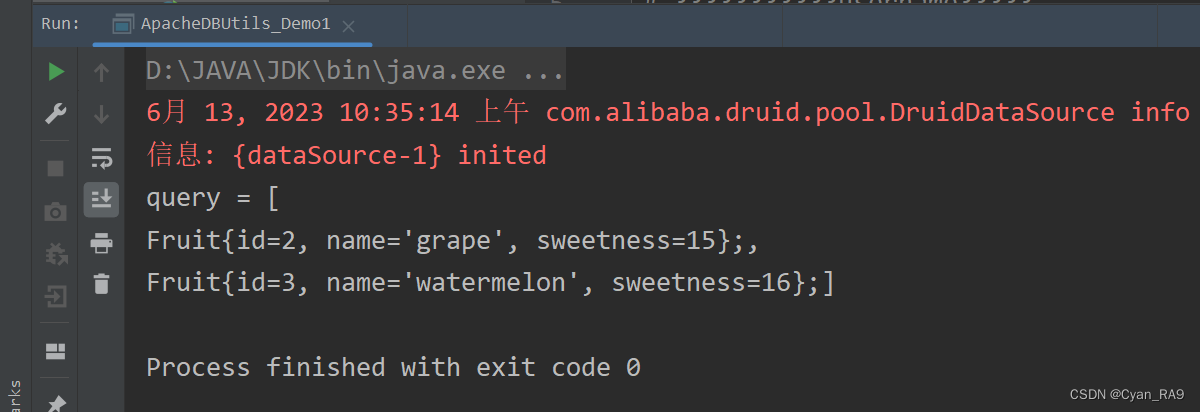
4.query方法源码分析 :
我们在query方法处下一个断点,如下图所示 :

接着进入Debug。我们先跳入new BeanListHandler<>(Fruit.class)看看,如下所示 :
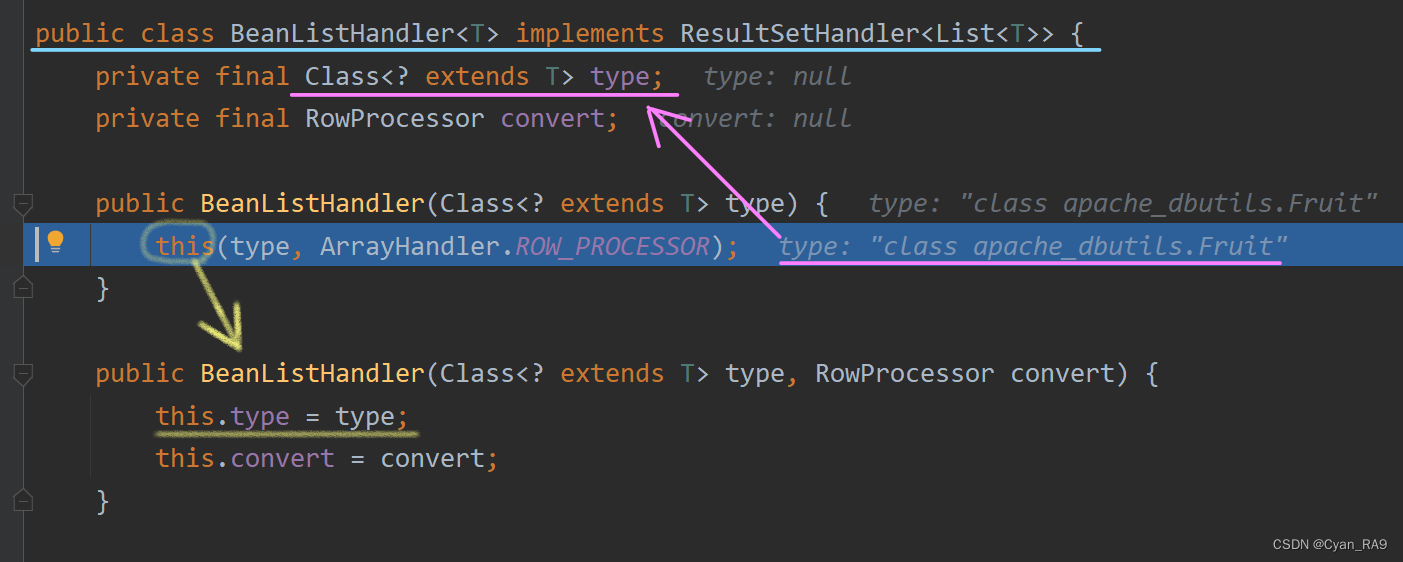
一目了然。上文“Apahce—DBUtils”的基本介绍中,我们说过,ResultSetHandler接口用于处理ResultSet结果集,这不,BeanListHandler实现了该接口。
并且,我们在query方法的形参列表new一个BeanListHandler时,是传入了一个Fruit类对应的Class对象(Fruit就是fruit表对应的JavaBean类),这个Class对象,最后会传递给BeanListHandler类的type成员变量,这么一来,BeanListHandler就可以通过反射get到了Fruit类的信息了。
继续,我们回去,跳入query方法,如下 :

首次跳入其实是对我们可变参数中的2进行装箱,不管他。重新跳入query,如下 :

经典“包皮”结构,可以看到,我们传入的四个形参都历历在目,并且可以直观的看到最后的可变参数。 但是,这个"this.query(...)",又是在干嘛呢?不着急,我们可以发现,新调用的query方法无非就是多传入了一个false布尔变量而已。直接跳进去看看,如下图所示 :

这个query看似复杂,其实逻辑非常清楚,一开始就是一大串判断——连接是不是为空呀?要执行的sql是不是为空呀?传入的ResultSetHandler对象是不是为空呀?
只要有一个环节出了问题,就给你抛出一个异常,并打印出相关信息。当然了,眼尖的小伙伴儿还会发现其中有两个if (closeConn)的判断,如果成立会关闭连接(放回连接池),这个"closeConn"其实就是之前多出来的那个false布尔变量,那肯定就不进入if语句了呗。
我们继续往下看,最下面的else语句才是真正要完成执行SQL的操作滴。如所示 :
else {
PreparedStatement stmt = null;
ResultSet rs = null;
T result = null;
try {
stmt = this.prepareStatement(conn, sql);
this.fillStatement(stmt, params);
rs = this.wrap(stmt.executeQuery());
result = rsh.handle(rs);
} catch (SQLException var33) {
this.rethrow(var33, sql, params);
} finally {
try {
this.close(rs);
} finally {
this.close(stmt);
if (closeConn) {
this.close(conn);
}
}
}
return result;
} 噢,我们心心念念已久的PreparedStatement和ResultSet总算出现辽。可以看到,源码中也是先将对象置为null,之后才初始化的。值得一提的是这个result,直接告诉你结论,这个result就是query方法最终要返回的ArrayList类型的集合。
继续,这里的prepareStatement方法传入了conn和sql两个实参,其实追进去会发现还是原来那一套——通过连接来获取prepareStatement对象,如下图所示 :

而fillStatement就是用你传入的可变参数来给sql中的?赋值。

再往下就是通过PreparedStatement对象来执行sql了,此处返回的是结果集。

紧接着是handle方法执行,可以肯定的是,handle方法最终返回的一定是ArrayList类型的对象。 我们追进去handle方法看看,如下图所示 :

又是经典包皮结构。别急,我们的目的很明确——找到return ArrayList的语句。继续往下追,如下图所示 :

双层包皮结构?再往下追!如下 :
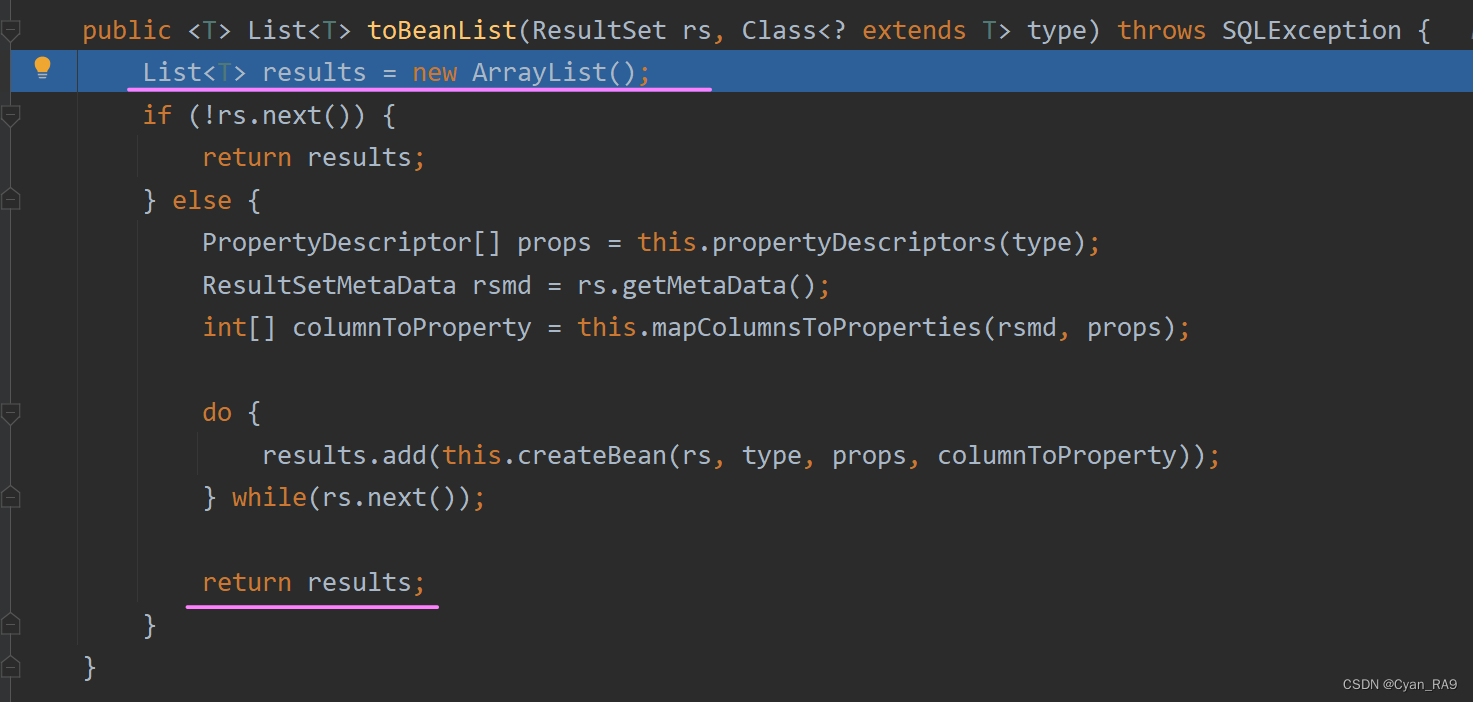
诺,总算给我们找到了,的确是new了一个ArrayList类型的对象,并且最后给返回了。那么经过层层返回,最后这个ArrayList对象就会被赋值给query方法中的result,所以query方法最终也是返回了ArrayList类型的对象。
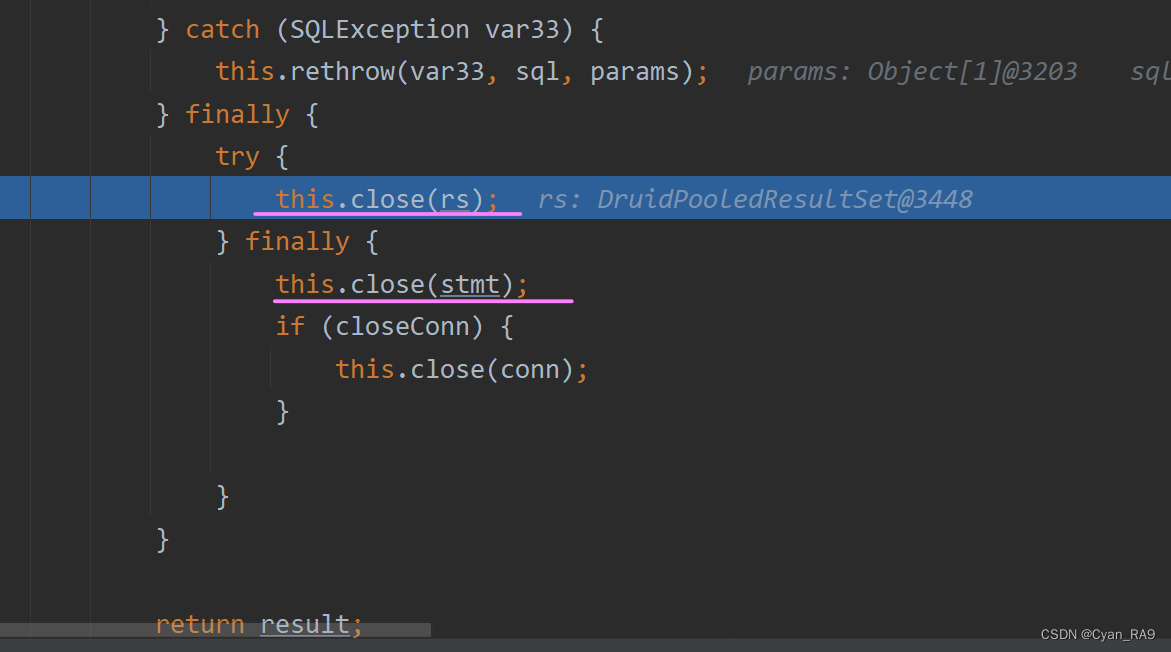
最后,query方法的finally语句中自动关闭了ResultSet和PreparedStatement,如下图所示 :
5.DBUtils处理(DML) :
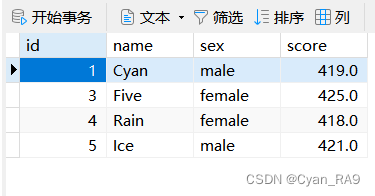
这次我们来操作学生表stus(id为自增长主键),如下图所示 :
现要求——
①向表中新插入一条“id = 6;name = 'Carl';sex = 'male';score=499”的记录;
②修改name = Five的记录,令其score = 433;
③删除id = 5的记录。
up以ApacheDBUtils_Demo2类为演示类,代码如下 :
package apache_dbutils;
import connection_pool.druid.JDBCUtilsDruid;
import org.apache.commons.dbutils.QueryRunner;
import java.sql.Connection;
import java.sql.SQLException;
public class ApacheDBUtils_Demo2 {
public static void main(String[] args) throws SQLException {
//JDBC核心四部曲
//1.注册驱动(底层会根据druid.properties配置文件中的信息自动注册驱动)
//Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = null;
connection = JDBCUtilsDruid.getConnection();
//3.执行SQL
String sql1 = "INSERT INTO stus " +
"VALUES " +
"(NULL,?,?,?);";
String sql2 = "UPDATE stus " +
"SET score = ? " +
"WHERE `name` = ?";
String sql3 = "DELETE FROM stus " +
"WHERE id = ?";
QueryRunner queryRunner = new QueryRunner();
int affectedRows1 = queryRunner.update(connection, sql1, "Carl", "male", 499.0);
int affectedRows2 = queryRunner.update(connection, sql2, 433.0,"Five");
int affectedRows3 = queryRunner.update(connection, sql3, 5);
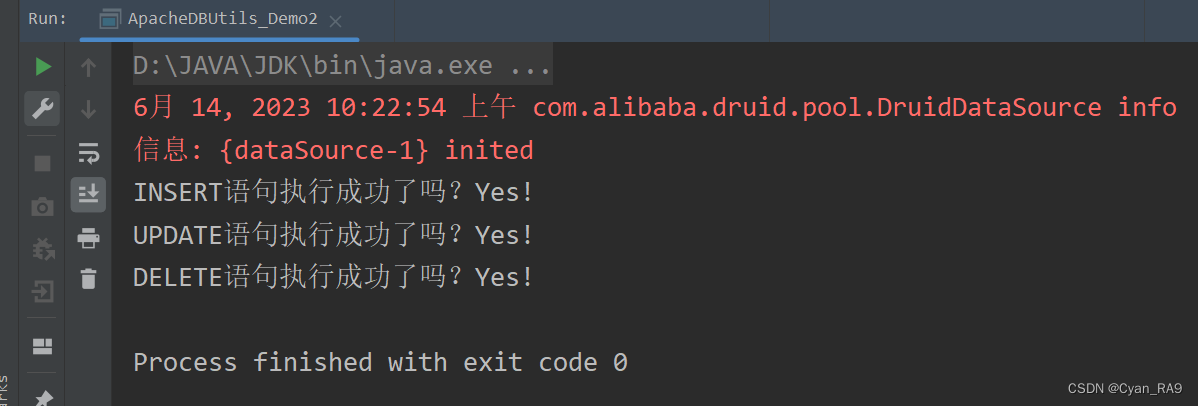
System.out.println("INSERT语句执行成功了吗?" + (affectedRows1 > 0 ? "Yes!" : "No!"));
System.out.println("UPDATE语句执行成功了吗?" + (affectedRows2 > 0 ? "Yes!" : "No!"));
System.out.println("DELETE语句执行成功了吗?" + (affectedRows3 > 0 ? "Yes!" : "No!"));
//4.释放资源
JDBCUtilsDruid.close(null,null,connection);
}
}
运行结果 :
查询一下stus表,如下 :
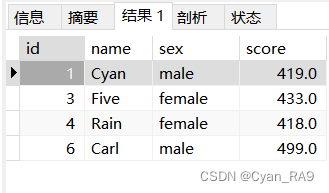
修改成功!
四、总结
- 🆗,以上就是JDBC系列博文第六节的全部内容了。
- 总结一下,我们从"数据管理"和“结果复用”两个角度分析了传统使用ResultSet的弊端,从而引出了本节要学习的ApacheDBUtils工具类,该工具类可以将结果集中的数据转移到表对应的JavaBean类的实例中,然后将多个实例封装到集合中,便可以达到“复用结果集”的目的。大家需要掌握QueryRunner中query方法和update方法的使用,以及熟悉ResultSetHandler接口的几个常用实现类。
- 下一节内容——JDBC BasicDAO,我们不见不散。感谢阅读!
System.out.println("END-----------------------------------------------------------------------------");