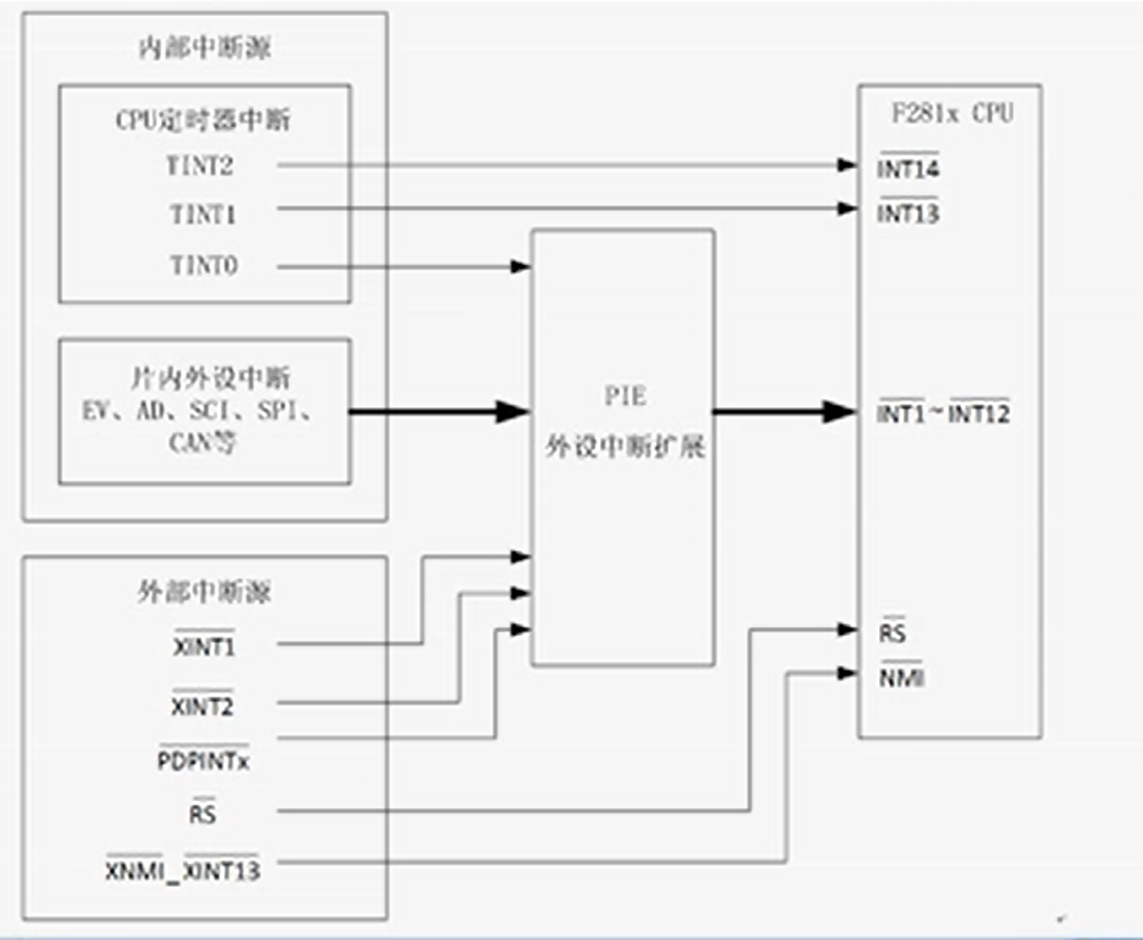
1 什么是泛型
引入:
关于泛型,先来说几句集合。都知道集合是可以存储任意对象,当我们创建一个集合时如果没有声明它的存储类型,那该集合便自动提升为Object类型
提示:在我们创建对象的时候,如果没有明确指出一种数据类型,那么编译器会默认为Object类。
当我们在遍历的时候就需要强制转换为对应的类型,但是我们无法确认那个元素属于那种类型,就导致我们强制转换会出现异常。
Java在引入泛型之前都是使用Object来实现类似泛型的功能。
public class A {
private Object b;
public void setB(Object b) {
this.b = b;
}
public Object getB() {
return b;
}
}
--------------------------------------
A a=new A();
a.setB(1);
int b=(int)a.getB();//需要做类型强转
String c=(String)a.getB();//运行时,ClassCastException 上面代码中需要手动进行类型强转,并且在编译时无法进行类型检查,只能在运行期才能检查出来,这样就很容易造成类型转换异常。
Java中引入泛型最主要的目的是将类型检查工作提前到编译时期,将类型强转(cast)工作交给编译器,从而让你在编译时期就获得类型转换异常以及去掉源码中的类型强转代码。
定义:
泛型,即“参数化类型”,将参数的类型泛化。在声明时不指定参数类型,根据传入的实际参数的类型来决定。是jdk1.5的特性;可以将类型当作参数传递给一个类或者是方法或者接口。
- Java泛型也是一种语法糖,在编译阶段完成类型的转换的工作,避免在运行时强制类型转换而出现ClassCastException,类型转化异常。
泛型可以随便写,但默认的规则为:
E—Element,常用在Java的集合中
K,V-----key,value 代表Map中的键值对
N-----Number 代表数字
T----Type 类型,如String,Integer等等
?:表示不确定的java类型
注意:
基本数据类型不能作为泛型
在集合中不使用泛型时,可以存储任意类型的对象,集合中的元素是对象。
泛型在编译期有效,可以动态修改参数类型,泛型的底层主要是通过list源码来实现的。
2 为什么要用泛型
那么,如何解释类型参数化呢?
public class Cache {
Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}假设 Cache 能够存取任何类型的值,于是,我们可以这样使用它。
Cache cache = new Cache();
cache.setValue(134);
int value = (int) cache.getValue();
cache.setValue("hello");
String value1 = (String) cache.getValue();使用的方法也很简单,只要我们做正确的强制转换就好了。
但是,泛型却给我们带来了不一样的编程体验。
public class Cache<T> {
T value;
public Object getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}这就是泛型,它将 value 这个属性的类型也参数化了,这就是所谓的参数化类型。再看它的使用方法。
Cache<String> cache1 = new Cache<String>();
cache1.setValue("123");
String value2 = cache1.getValue();
Cache<Integer> cache2 = new Cache<Integer>();
cache2.setValue(456);
int value3 = cache2.getValue();最显而易见的好处就是它不再需要对取出来的结果进行强制转换了。但,还有另外一点不同。

泛型除了可以将类型参数化外,而参数一旦确定好,如果类似不匹配,编译器就不通过。
上面代码显示,无法将一个 String 对象设置到 cache2 中,因为泛型让它只接受 Integer 的类型。
所以,综合上面信息,我们可以得到下面的结论。
- 与普通的 Object 代替一切类型这样简单粗暴而言,泛型使得数据的类别可以像参数一样由外部传递进来。它提供了一种扩展能力。它更符合面向抽象开发的软件编程宗旨。
- 当具体的类型确定后,泛型又提供了一种类型检测的机制,只有相匹配的数据才能正常的赋值,否则编译器就不通过。所以说,它是一种类型安全检测机制,一定程度上提高了软件的安全性防止出现低级的失误。
- 泛型提高了程序代码的可读性,不必要等到运行的时候才去强制转换,在定义或者实例化阶段,因为 Cache<String>这个类型显化的效果,程序员能够一目了然猜测出代码要操作的数据类型。
3 泛型的类型
参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
4 如何使用泛型
4.1 泛型类
我们可以这样定义一个泛型类。
public class Test<T> {
T field1;
}尖括号 <>中的 T 被称作是类型参数,用于指代任何类型。事实上,T 只是一种习惯性写法,如果你愿意。你可以这样写。
public class Test<Hello> {
Hello field1;
}但出于规范的目的,Java 还是建议我们用单个大写字母来代表类型参数。常见的如:
-
- T 代表一般的任何类。
- E 代表 Element 的意思,或者 Exception 异常的意思。
- K 代表 Key 的意思。
- V 代表 Value 的意思,通常与 K 一起配合使用。
- S 代表 Subtype 的意思,文章后面部分会讲解示意。
如果一个类被 <T>的形式定义,那么它就被称为是泛型类。
那么对于泛型类怎么样使用呢?只要在对泛型类创建实例的时候,在尖括号中赋值相应的类型便是。T 就会被替换成对应的类型,如 String 或者是 Integer。你可以相像一下,当一个泛型类被创建时,内部自动扩展成下面的代码。
public class Test<String> {
String field1;
}当然,泛型类不至接受一个类型参数,它还可以这样接受多个类型参数。
public class MultiType <E,T>{
E value1;
T value2;
public E getValue1(){
return value1;
}
public T getValue2(){
return value2;
}
}父类派生子类的时候不能在包含类型形参,需要传入具体的类型
- 错误的方式:
public class A extends Container<K, V> {}- 正确的方式:
public class A extends Container<Integer, String> {}- 也可以不指定具体的类型,系统就会把K,V形参当成Object类型处理
public class A extends Container {}4.2 泛型接口
泛型接口和泛型类差不多,所以一笔带过。
public interface Iterable<T> { }4.2.1 在使用泛型类和泛型接口时需注意
泛型类和接口主要在继承和实现时使用。
1 泛型类和接口主要在继承和实现时使用。
2 未传入泛型的实参时,与泛型类定义的相同,在声明类时,需要将泛型的声明也一起加到类中
class a<T>{
public void eat(Object name) {
// return null;
}
}
class b<T> extends a<T>{
public static void main(String[] args) {
b w=new b();
}
}3 接口和类在被继承的时候指定具体的类型,子类将不需要泛型,但所有在接口和父类中使用泛型的地方都要替换成传入的实参类型
class a<T>{
public T eat(T name) {
return null;
}
}
class b extends a<String>{
//即b可以不使用泛型,在a中使用泛型的地方都变为了String
@Override
public String eat(String name) {
return null;
}
public static void main(String[] args) {
b w=new b();
}
}
public interface qwr<T> {
public T eat(T name);
}
public class tyuio implements qwr<Integer>{
@Override
public Integer eat(Integer name) {
return null;
}
public static void main(String[] args) {
tyuio t=new tyuio();
}
}4.3 泛型方法
public class Test1 {
public <T> void testMethod(T t){
}
}泛型方法与泛型类稍有不同的地方是,类型参数也就是尖括号那一部分是写在返回值前面的。<T>中的 T 被称为类型参数,而方法中的 T 被称为参数化类型,它不是运行时真正的参数。
当然,声明的类型参数,其实也是可以当作返回值的类型的。
public <T> T testMethod1(T t){
return null;
}泛型类与泛型方法的共存现象
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <T> T testMethod1(T t){
return t;
}
}上面代码中,Test1<T>是泛型类,testMethod 是泛型类中的普通方法,而 testMethod1 是一个泛型方法。而泛型类中的类型参数与泛型方法中的类型参数是没有相应的联系的,泛型方法始终以自己定义的类型参数为准。
所以,针对上面的代码,我们可以这样编写测试代码。
Test1<String> t = new Test1();
t.testMethod("generic");
Integer i = t.testMethod1(new Integer(1));泛型类的实际类型参数是 String,而传递给泛型方法的类型参数是 Integer,两者不想干。
但是,为了避免混淆,如果在一个泛型类中存在泛型方法,那么两者的类型参数最好不要同名。比如,Test1<T>代码可以更改为这样
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <E> E testMethod1(E e){
return e;
}
}4.2.1 泛型方法具体使用例句
class a<T> {
//此类是一个泛型类
private T name;
/*此方法不是泛型方法,因为没有<T>,它是一个普通的成员方法,
因为泛型类已经声明了泛型T,所以此处的T可以使用,该方法的返回值类型为T类型
*/
public T getName(T d) {
return name;
}
/*d
下列方法是错误的,因为类的声明中并未声明泛型B,泛型B在作为返回值和形参时无法被编译器识别。
public B getName(B d) {
return name;
}*/
public void setName(T name) {
this.name = name;
}
/*下列方法为一个泛型方法,主要体现在使用了<T>,<T>表明该方法为一个泛型方法,并且声明了一个泛型T,T可以出现在任意位置,需注意的是此处的T与泛型类中声明的T是不同类型的*/
public <T> T lok(a<T> name) {
T d = null;
return name.getName(d);
}
/*此方法正确,E在public 后被声明(方法声明是被声明),所以即使泛型类中未声明也可以在该方法中可以使用,编译器也能正确识别泛型方法中的泛型
*/
public <E> E lok(E name) {
E d = null;
return d;
}
/*
此方法错误因为此方法只是声明了泛型E并未声明N
public <E> E lok(N name) {
E d = null;
return d;
}*/
/*
此方法错误,对于编译器来说N并没有在项目中被声明过,因此编译器不知道如何编译N
所以此方法不是一个正确的泛型方法的声明
public void lok(N name) {
}
*/
}4.2.2 泛型方法与可变参数
public void d(T...arg){
for (T t:arg) {
System.out.println(t);
}
} 4.2.3 静态方法与泛型
需注意:静态方法无法访问类上定义的泛型。如果静态方法操作的引用数据不确定的时候,必须要将泛型定义在方法上。即如果静态方法要是用泛型的话,必须将静态方法定义为泛型方法。
class o<T>{
public static void d(T...arg){
System.out.println(arg);
}//此方法会报错,在静态方法中使用泛型时,无论该泛型类型是否在泛型类中声明,必须将静态方法设定为泛型方法。
public static <T> void d2(T...arg){
System.out.println(arg);
} //此静态方法使用的泛型正确
public static void main(String[] args) {
d();
d2();
}
} 4.4 通配符 ?
除了用 <T>表示泛型外,还有 <?>这种形式。? 被称为通配符。
可能有同学会想,已经有了 <T>的形式了,为什么还要引进 <?>这样的概念呢?
class Base{}
class Sub extends Base{}
Sub sub = new Sub();
Base base = sub; 上面代码显示,Base 是 Sub 的父类,它们之间是继承关系,所以 Sub 的实例可以给一个 Base 引用赋值,那么
List<Sub> lsub = new ArrayList<>();
List<Base> lbase = lsub;最后一行代码成立吗?编译会通过吗?
答案是否定的。
编译器不会让它通过的。Sub 是 Base 的子类,不代表 List<Sub>和 List<Base>有继承关系。
但是,在现实编码中,确实有这样的需求,希望泛型能够处理某一范围内的数据类型,比如某个类和它的子类,对此 Java 引入了通配符这个概念。
所以,通配符的出现是为了指定泛型中的类型范围。
通配符有 3 种形式。
- <?>被称作无限定的通配符。
- <? extends T>被称作有上限的通配符。
- <? super T>被称作有下限的通配符。
4.4.1 无限定通配符 <?>
无限定通配符经常与容器类配合使用,它其中的 ? 其实代表的是未知类型,所以涉及到 ? 时的操作,一定与具体类型无关。
public void testWildCards(Collection<?> collection){
}上面的代码中,方法内的参数是被无限定通配符修饰的 Collection 对象,它隐略地表达了一个意图或者可以说是限定,那就是 testWidlCards() 这个方法内部无需关注 Collection 中的真实类型,因为它是未知的。所以,你只能调用 Collection 中与类型无关的方法。

我们可以看到,当 <?>存在时,Collection 对象丧失了 add() 方法的功能,编译器不通过。
我们再看代码。
List<?> wildlist = new ArrayList<String>();
wildlist.add(123);// 编译不通过有人说,<?>提供了只读的功能,也就是它删减了增加具体类型元素的能力,只保留与具体类型无关的功能。它不管装载在这个容器内的元素是什么类型,它只关心元素的数量、容器是否为空?我想这种需求还是很常见的吧。
有同学可能会想,<?>既然作用这么渺小,那么为什么还要引用它呢?
个人认为,提高了代码的可读性,程序员看到这段代码时,就能够迅速对此建立极简洁的印象,能够快速推断源码作者的意图。
4.4.2 ? extends T
<?>代表着类型未知,但是我们的确需要对于类型的描述再精确一点,我们希望在一个范围内确定类别,比如类型 A 及 类型 A 的子类都可以。
<? extends T> 代表类型 T 及 T 的子类。
public void testSub(Collection<? extends Base> para){ } 上面代码中,para 这个 Collection 接受 Base 及 Base 的子类的类型。 但是,它仍然丧失了写操作的能力。也就是说
para.add(new Sub());
para.add(new Base());仍然编译不通过。
没有关系,我们不知道具体类型,但是我们至少清楚了类型的范围。
<? super T> 这个和 <? extends T>相对应,代表 T 及 T 的超类。
public void testSuper(Collection<? super Sub> para){ } <? super T>神奇的地方在于,它拥有一定程度的写操作的能力。
public void testSuper(Collection<? super Sub> para){
para.add(new Sub());//编译通过
para.add(new Base());//编译不通过
}通配符与类型参数的区别 一般而言,通配符能干的事情都可以用类型参数替换。 比如
public void testWildCards(Collection<?> collection){}
可以被
public <T> void test(Collection<T> collection){}
取代。值得注意的是,如果用泛型方法来取代通配符,那么上面代码中 collection 是能够进行写操作的。只不过要进行强制转换。
public <T> void test(Collection<T> collection){
collection.add((T)new Integer(12));
collection.add((T)"123");
}需要特别注意的是,类型参数适用于参数之间的类别依赖关系,举例说明。
public class Test2 <T,E extends T>{
T value1;
E value2;
}
public <D,S extends D> void test(D d,S s){
}E 类型是 T 类型的子类,显然这种情况类型参数更适合。
有一种情况是,通配符和类型参数一起使用。
public <T> void test(T t,Collection<? extends T> collection){
}如果一个方法的返回类型依赖于参数的类型,那么通配符也无能为力。
public T test1(T t){
return value1;
}4.4.3 总结
无限定通配符<?>
1 通常与集合配合使用
2 集合中的限定类型,表示集合中只能包含一种类型;不限定类型,表示不限定任何类型。一旦集合转为不限定类型,不可以向集合中添加数据,只能进行查询集合长度、判断集合是否为空等一些与集合中数据的类型无关的一些操作。
3 通常与<? extends T> 和<? super T>配合使用
上限通配符<? extends T>
<? extends T>:表示的意思为T类型及其子类
- 表示规定范围的类型。比如<? extends T>:规定的类型是T类型及其子类
- 表示的集合不能添加元素。
下限通配符<? super T>
<? super T>:表示T类型及其父类
- 表示规定范围的类型。
- 在集合中可以添加元素,也可以查询
4.5 类型擦除
泛型是 Java 1.5 版本才引进的概念,在这之前是没有泛型的概念的,但显然,泛型代码能够很好地和之前版本的代码很好地兼容。
这是因为,泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。
通俗地讲,泛型类和普通类在 java 虚拟机内是没有什么特别的地方。回顾文章开始时的那段代码
大家可能会有疑问,我为什么叫做泛型是一个守门者。这其实是我个人的看法而已,我的意思是说泛型没有其看起来那么深不可测,它并不神秘与神奇。泛型是 Java 中一个很小巧的概念,但同时也是一个很容易让人迷惑的知识点,它让人迷惑的地方在于它的许多表现有点违反直觉。
文章开始的地方,先给大家奉上一道经典的测试题。
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());请问,上面代码最终结果输出的是什么?不了解泛型的和很熟悉泛型的同学应该能够答出来,而对泛型有所了解,但是了解不深入的同学可能会答错。
正确答案是 true。
上面的代码中涉及到了泛型,而输出的结果缘由是类型擦除。
打印的结果为 true 是因为 List<String>和 List<Integer>在 jvm 中的 Class 都是 List.class。
泛型信息被擦除了。可能同学会问,那么类型 String 和 Integer 怎么办?
答案是泛型转译。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}Erasure 是一个泛型类,我们查看它在运行时的状态信息可以通过反射。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());打印的结果是
erasure class is:com.frank.test.Erasure
Class 的类型仍然是 Erasure 并不是 Erasure<T>这种形式,那我们再看看泛型类中 T 的类型在 jvm 中是什么具体类型。
Field[] fs = eclz.getDeclaredFields();
for ( Field f:fs) {
System.out.println("Field name "+f.getName()+" type:"+f.getType().getName());
}打印结果是
Field name object type:java.lang.Object
那我们可不可以说,泛型类被类型擦除后,相应的类型就被替换成 Object 类型呢?
这种说法,不完全正确。我们更改一下代码。
public class Erasure <T extends String>{
// public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}现在再看测试结果:
Field name object type:java.lang.String
我们现在可以下结论了,在泛型类被类型擦除的时候,之前泛型类中的类型参数部分如果没有指定上限,如 <T>则会被转译成普通的 Object 类型,如果指定了上限如 <T extends String>则类型参数就被替换成类型上限。所以,在反射中。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
public void add(T object){
}
}add() 这个方法对应的 Method 的签名应该是 Object.class。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());
Method[] methods = eclz.getDeclaredMethods();
for ( Method m:methods ){
System.out.println(" method:"+m.toString());
}打印结果是
method:public void com.frank.test.Erasure.add(java.lang.Object)
也就是说,如果你要在反射中找到 add 对应的 Method,你应该调用 getDeclaredMethod("add",Object.class)否则程序会报错,提示没有这么一个方法,原因就是类型擦除的时候,T 被替换成 Object 类型了。
4.5.1 类型擦除带来的局限性
类型擦除,是泛型能够与之前的 java 版本代码兼容共存的原因。但也因为类型擦除,它会抹掉很多继承相关的特性,这是它带来的局限性。
理解类型擦除有利于我们绕过开发当中可能遇到的雷区,同样理解类型擦除也能让我们绕过泛型本身的一些限制。比如

正常情况下,因为泛型的限制,编译器不让最后一行代码编译通过,因为类似不匹配,但是,基于对类型擦除的了解,利用反射,我们可以绕过这个限制。
public interface List<E> extends Collection<E>{
boolean add(E e);
}上面是 List 和其中的 add() 方法的源码定义。
因为 E 代表任意的类型,所以类型擦除时,add 方法其实等同于
boolean add(Object obj);
那么,利用反射,我们绕过编译器去调用 add 方法。
public class ToolTest {
public static void main(String[] args) {
List<Integer> ls = new ArrayList<>();
ls.add(23);
try {
Method method = ls.getClass().getDeclaredMethod("add",Object.class);
method.invoke(ls,"test");
method.invoke(ls,42.9f);
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for ( Object o: ls){
System.out.println(o);
}
}
}打印结果是:
23 test 42.9
可以看到,利用类型擦除的原理,用反射的手段就绕过了正常开发中编译器不允许的操作限制。
4.5.2 类型擦除的限制
4.5.2.1 模糊性错误
- 对于泛型类User<K,V>而言,声明了两个泛型类参数。在类中根据不同的类型参数重载show方法。
public class User<K, V> {
public void show(K k) {
// 报错信息:'show(K)' clashes with 'show(V)'; both methods have same erasure
}
public void show(V t) {
}
}由于泛型擦除,二者本质上都是Obejct类型。方法是一样的,所以编译器会报错。
换一个方式:
public class User<K, V> {
public void show(String k) {
}
public void show(V t) {
}
}使用结果:
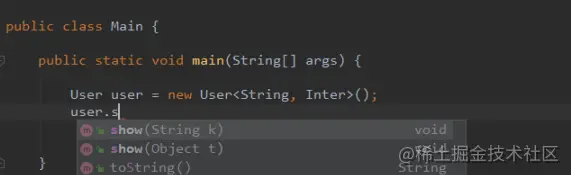
可以正常的使用
4.5.2.2 不能实例化类型参数
编译器也不知道该创建那种类型的对象
public class User<K, V> {
private K key = new K();
// 报错:Type parameter 'K' cannot be instantiated directly
}
4.5.2.3 对静态成员的限制
静态方法无法访问类上定义的泛型;如果静态方法操作的类型不确定,必须要将泛型定义在方法上。
如果静态方法要使用泛型的话,必须将静态方法定义成泛型方法。
public class User<T> {
//错误
private static T t;
//错误
public static T getT() {
return t;
}
//正确
public static <K> void test(K k) {
}
}4.5.2.4 对泛型数组的限制
- 不能实例化元素类型为类型参数的数组,但是可以将数组指向类型兼容的数组的引用
public class User<T> {
private T[] values;
public User(T[] values) {
//错误,不能实例化元素类型为类型参数的数组
this.values = new T[5];
//正确,可以将values 指向类型兼容的数组的引用
this.values = values;
}
}4.5.2.5 对泛型异常的限制
泛型类不能扩展 Throwable,意味着不能创建泛型异常类。
4.6 泛型中值得注意的地方
4.6.1 泛型类或者泛型方法中,不接受 8 种基本数据类型。
所以,你没有办法进行这样的编码。
List<int> li = new ArrayList<>();
List<boolean> li = new ArrayList<>();需要使用它们对应的包装类。
List<Integer> li = new ArrayList<>();
List<Boolean> li1 = new ArrayList<>();对泛型方法的困惑
public <T> T test(T t){
return null;
}有的同学可能对于连续的两个 T 感到困惑,其实 <T>是为了说明类型参数,是声明,而后面的不带尖括号的 T 是方法的返回值类型。
你可以相像一下,如果 test() 这样被调用
test("123");
那么实际上相当于
public String test(String t);
4.6.2 Java 不能创建具体类型的泛型数组
这句话可能难以理解,代码说明。
List<Integer>[] li2 = new ArrayList<Integer>[];
List<Boolean> li3 = new ArrayList<Boolean>[];这两行代码是无法在编译器中编译通过的。原因还是类型擦除带来的影响。
List<Integer>和 List<Boolean>在 jvm 中等同于List<Object>,所有的类型信息都被擦除,程序也无法分辨一个数组中的元素类型具体是 List<Integer>类型还是 List<Boolean>类型。
但是,
List<?>[] li3 = new ArrayList<?>[10];
li3[1] = new ArrayList<String>();
List<?> v = li3[1];借助于无限定通配符却可以,前面讲过 ?代表未知类型,所以它涉及的操作都基本上与类型无关,因此 jvm 不需要针对它对类型作判断,因此它能编译通过,但是,只提供了数组中的元素因为通配符原因,它只能读,不能写。比如,上面的 v 这个局部变量,它只能进行 get() 操作,不能进行 add() 操作,这个在前面通配符的内容小节中已经讲过。