点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2305.12972.pdf
项目代码:https://github.com/huawei-noah/VanillaNet
https://gitee.com/mindspore/models/tree/master/research/cv/vanillanet
计算机视觉研究院专栏
Column of Computer Vision Institute
基础模型的核心是“越多越好”的哲学,计算机视觉和自然语言处理领域的惊人成功就是例证。然而,优化的挑战和transformer模型固有的复杂性要求范式向简单性转变。
深度学习算法架构越复杂越好吗???

01
总 述
在这项研究中,研究者就介绍了VanillaNet,一种在设计中融入优雅的神经网络架构。通过避免高深度、shortcuts和自注意力机制等复杂操作,VanillaNet简洁而强大。每一层都经过精心制作,紧凑而直接,在训练后对非线性激活函数进行修剪,以恢复原始架构。VanillaNet克服了固有复杂性的挑战,使其成为资源受限环境的理想选择。其易于理解且高度简化的体系结构为高效部署开辟了新的可能性。大量实验表明,VanillaNet的性能与著名的深度神经网络和vision transformer不相上下,展示了极简在深度学习中的力量。
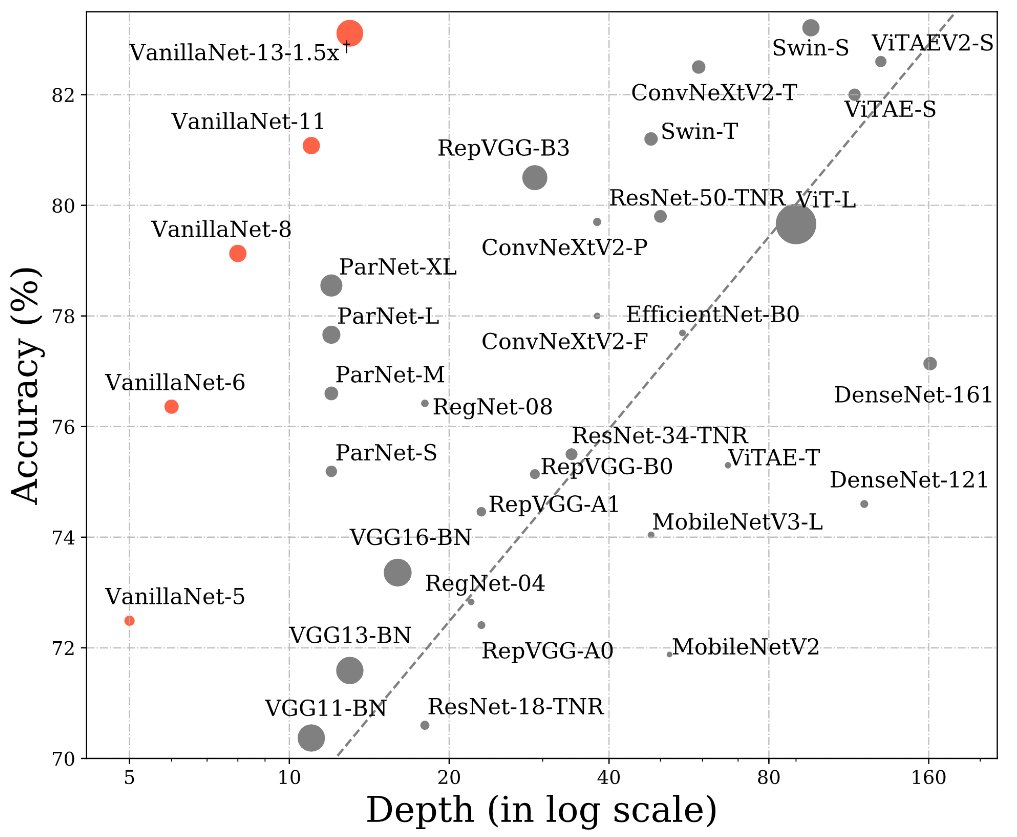
VanillaNet的这一富有远见的旅程具有重新定义景观和挑战基础模型现状的巨大潜力,为优雅有效的模型设计开辟了一条新的道路。
02
背 景
在过去的几十年里,人工神经网络取得了显著的进步,这是由于网络复杂性的增加会提高性能。这些网络由具有大量神经元或transformer块的多层组成,能够执行各种类似人类的任务,如人脸识别、语音识别、目标检测、自然语言处理和内容生成。现代硬件令人印象深刻的计算能力使神经网络能够以高精度和高效率完成这些任务。
因此,人工智能嵌入式设备在我们的生活中越来越普遍,包括智能手机、人工智能摄像头、语音助手和自动驾驶汽车。诚然,该领域的一个显著突破是AlexNet的开发,它由12层组成,在大规模图像识别基准上实现了最先进的性能。在这一成功的基础上,ResNet中的残差,使深度神经网络能够在图像分类、目标检测和语义分割等广泛的计算机视觉应用中进行高性能训练。在这些模型中加入人工设计的模块,以及网络复杂性的持续增加,无疑增强了深度神经网络的代表能力,导致了关于如何训练具有更复杂架构的网络以实现更高性能的研究激增。
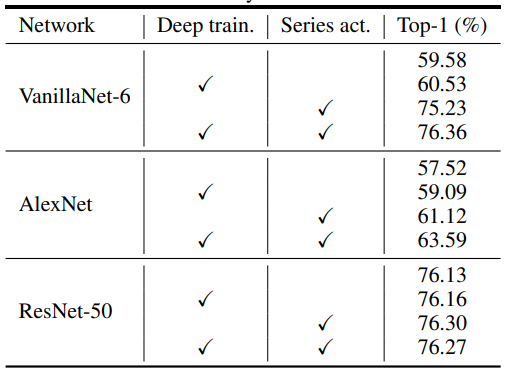
于是,研究者提出了VanillaNet,这是一种新颖的神经网络架构,强调设计的优雅和简单,同时在计算机视觉任务中保持卓越的性能。VanillaNet通过避免过多的深度、shortcuts和复杂的操作来实现这一点,从而产生了一系列精简的网络,这些网络解决了固有的复杂性问题,非常适合资源有限的环境。为了训练提出的VanillaNets,对其简化架构所带来的挑战进行了全面分析,并制定了“深度训练”策略。
这种方法从包含非线性激活函数的几个层开始。随着训练的进行,逐渐消除了这些非线性层,从而在保持推理速度的同时易于合并。为了增强网络的非线性,提出了一种有效的、基于级数的激活函数,该函数包含多个可学习的仿射变换。应用这些技术已经被证明可以显著提高不太复杂的神经网络的性能。VanillaNet的这项开创性研究为神经网络设计的新方向铺平了道路,挑战了基础模型的既定规范,并为精细有效的模型创建建立了新的轨迹。
03
新框架分析
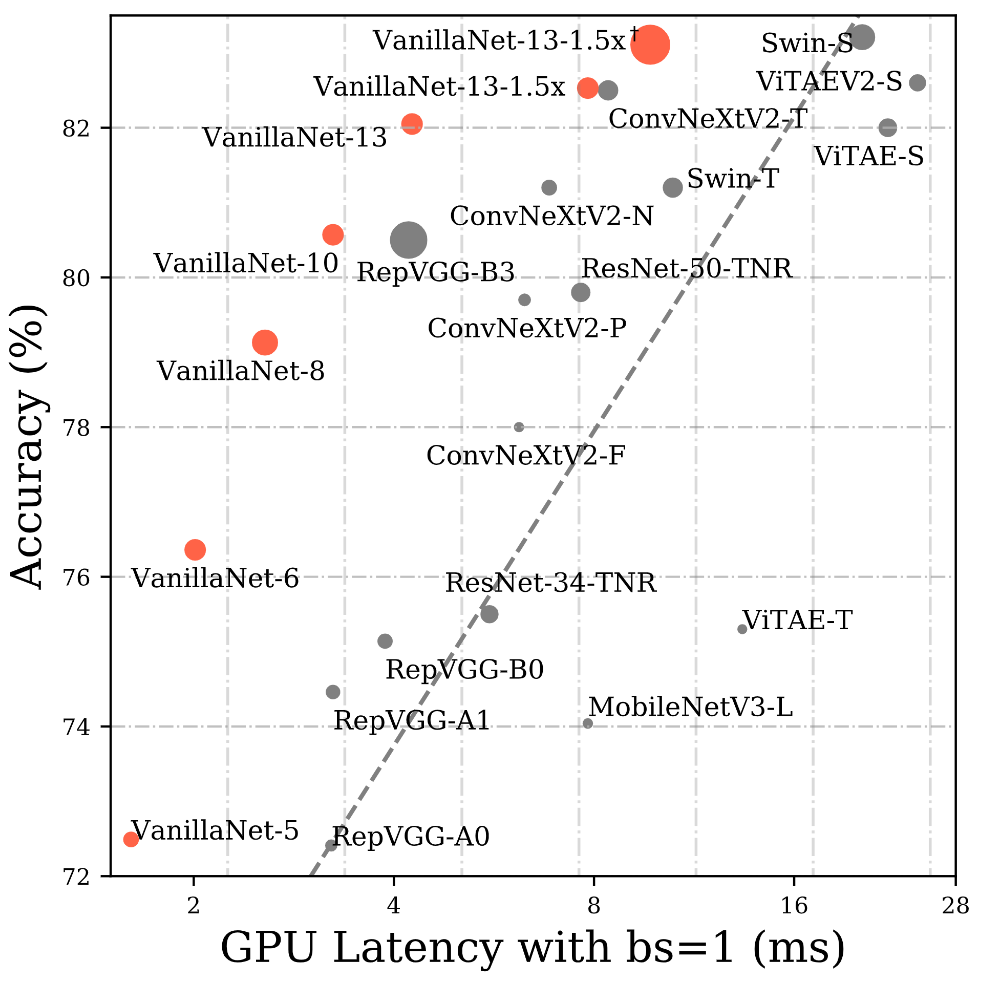
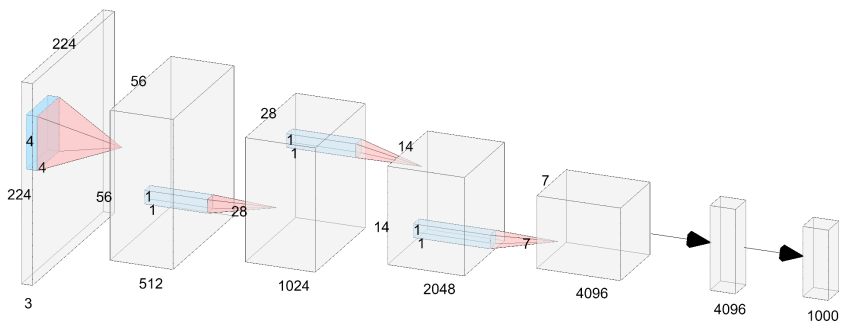
随着人工智能芯片的发展,神经网络推理速度的瓶颈将不再是FLOP或参数,因为现代GPU可以很容易地进行并行计算,而且计算能力很强。相比之下,它们复杂的设计和巨大的深度阻碍了它们的速度。为此,研究者提出了vanilla network,即VanillaNet,其架构如下图所示。遵循了流行的神经网络设计,包括主干、主体和全连接层。与现有的深度网络不同,在每个阶段只使用一层,以尽可能少的层建立一个极其简单的网络。
下图展示了6层的VanillaNet的结构,它的结构十分简洁,由5个卷积层,5个池化层,一个全连接层和5个激活函数构成,结构的设计遵循AlexNet和VGG等传统深度网络的常用方案:分辨率逐渐缩小,而通道数逐渐增大,不包含残差,自注意力等计算。
04
极简网络的训练策略
深度训练策略的主要思想是在训练过程开始时用激活函数训练两个卷积层,而不是单个卷积层。随着训练时期的增加,激活函数逐渐减少为恒等映射。在训练结束时,可以很容易地将两个卷积合并为一个卷积,以减少推理时间。这种思想在细胞神经网络中也得到了广泛的应用。
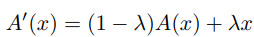
上面公式由一个传统非线性激活函数(如ReLU等)和恒等映射加权得到。我们首先将每个批量归一化层及其之前的卷积转换为单个卷积。
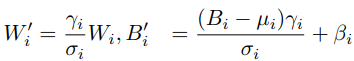
在将卷积与批量归一化合并后,开始合并两个1×1卷积。将x和y表示为输入和输出特征,卷积可以公式化为:
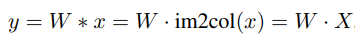
在网络训练的初始阶段,非线性激活函数会占主导地位,使得网络在开始训练时具有较高的非线性,在网络训练的过程中,恒等映射的权值会逐渐提升,此时该激活函数会逐渐变为线性的恒等映射,通过以下公式简单推导:

不具有非线性激活的两个卷积层就可以被融合为一层,从而达到了” 深层训练,浅层推理 “的效果。
Series Informed Activation Function
此外,研究者还提出了一种基于级数启发的激活函数,来进一步增加网络非线性,具体的,假设A(x)为任意现有的非线性激活函数,级数激活函数通过对激活函数进行偏置和加权,得到多个激活函数的叠加,从而使得单个激活函数具有更强的非线性:
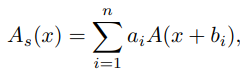
为了进一步丰富级数的逼近能力,使基于级数的函数能够通过改变其邻居的输入来学习全局信息,这与BNET类似。具体而言,给定输入特征x,其中H、W和C是其宽度、高度和通道的数量,激活函数公式化为:
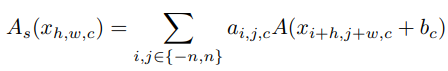
与相应的卷积层相比,研究者进一步分析了所提出的激活函数的计算复杂性。对于具有K核大小、Cin输入通道和Cout输出通道的卷积层,计算复杂度为:
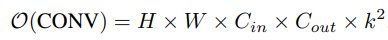
05
新框架的实验
Ablation study on the number of series
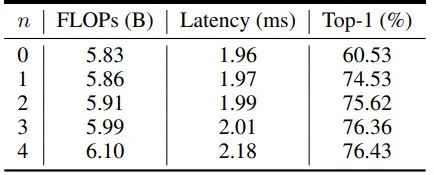
不同网络上的消融研究如下:
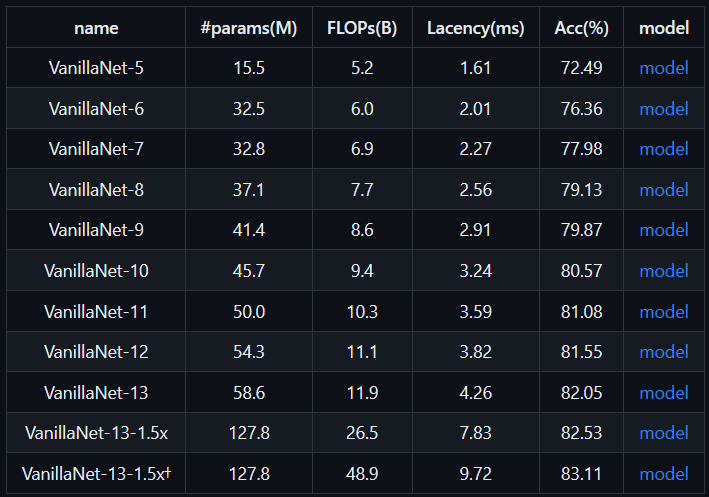
ImageNet-1K trained models如下:
通过ResNet-50和VanillaNet-9对分类样本的注意力图进行可视化。展示了他们错误分类样本和正确分类样本的注意力图,以进行比较:

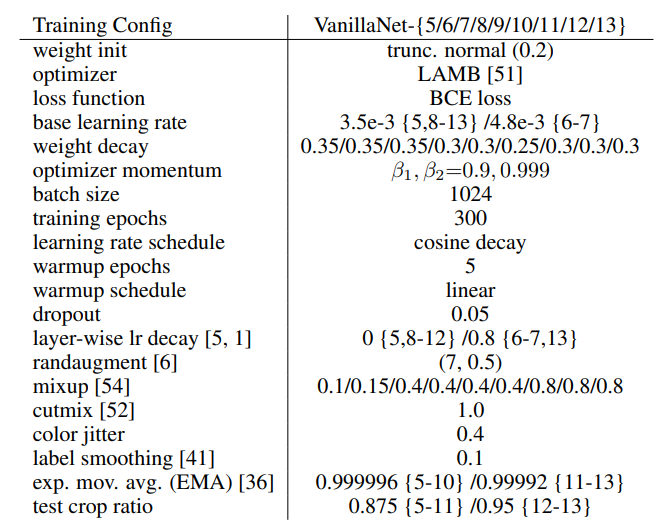
ImageNet-1K training settings:
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!



点击“阅读原文”,立即合作咨询