优化算法笔记(一)优化算法的介绍
(一)优化算法的介绍
1.1(what)什么是优化算法?
我们常见常用的算法有排序算法,字符串遍历算法,寻路算法等。这些算法都是为了解决特定的问题而被提出。
算法本质是一种按照固定步骤执行的过程。
优化算法也是这样一种过程,是一种根据概率按照固定步骤寻求问题的最优解的过程。与常见的排序算法、寻路算法不同的是,优化算法不具备等幂性,是一种概率算法。算法不断的迭代执行同一步骤直到结束,其流程如下图。

优化算法流程图
1.1.1什么是等幂性?
等幂性即对于同样的输入,输出是相同的。

图1鱼与熊掌谁更重?
比如图1,对于给定的鱼和给定的熊掌,我们在相同的条件下一定可以知道它们谁更重,当然,相同的条件是指鱼和熊掌处于相同的重力作用下,且不用考虑水分流失的影响。在这些给定的条件下,我们(无论是谁)都将得出相同的结论,鱼更重或者熊掌更重。我们可以认为,秤是一个等幂性的算法(工具)。

图2鱼与熊掌更爱谁。
现在把问题变一变,问鱼与熊掌你更爱哪个,那么现在,这个问题,每个人的答案可能不会一样,鱼与熊掌各有所爱。说明喜爱这个算法不是一个等幂性算法。当然你可能会问,哪个更重,和更喜欢哪个这两个问题一个是客观问题,一个是主观问题,主观问题没有确切的答案的。当我们处理主观问题时,也会将其转换成客观问题,比如给喜欢鱼和喜欢熊掌的程度打个分,再去寻求答案,毕竟计算机没有感情,只认0和1(量子计算机我不认识你)。
1.1.2什么是概率算法?
说完了等幂性,再来说什么是概率算法。简单来说就是看脸、看人品、看运气的算法。

图3烧根香

有一场考试,考试的内容全部取自课本,同时老师根据自己的经验给同学们划了重点,但是因为试卷并不是该老师所出,也会有考试内容不在重点之内,老师估计试卷中至少80%内容都在重点中。学霸和学渣参加了考试,学霸为了考满分所以无视重点,学渣为了pass,因此只看了重点。这样做的结果一定是score(学霸)>=score(学渣)。
当重点跟上图一样的时候,所有的内容都是重点的时候,学霸和学渣的学习策略变成了相同的策略,则score(学霸)=score(学渣)。但同时,学渣也要付出跟学霸相同的努力去学习这些内容,学渣心里苦啊。

课本

当课本如下图时

学霸?学霸人呢,哪去了快来学习啊,不是说学习一时爽,一直学习一直爽吗,快来啊,还等什么。
这时,如果重点内容远少于书本内容时,学渣的学习策略有了优势——花费的时间和精力较少。但是同时,学渣的分数也是一个未知数,可能得到80分也可能拿到100分,分数完全取决于重点内容与题目的契合度,契合度越高,分数越高。对学渣来说,自己具体能考多少分无法由自己决定,但是好在能够知道大概的分数范围。
学霸的学习策略是一种遍历性算法,他会遍历、通读全部内容,以保证满分。
学渣的学习策略则是一种概率算法,他只会遍历、学习重点内容,但至于这些重点是不是真重点他也不知道。
与遍历算法相比,概率算法的结果具有不确定性,可能很好,也可能很差,但是会消耗更少的资源,比如时间(人生),空间(记忆)。概率算法的最大优点就是花费较少的代价来获取最高的收益,在现实中体现于节省时间,使用很少的时间得到一个不与最优解相差较多的结果。
“庄子:吾生也有涯,而知也无涯;以有涯随无涯,殆矣。”的意思是:人生是有限的,但知识是无限的(没有边界的),用有限的人生追求无限的知识,是必然失败的。
生活中概率算法(思想)的应用其实比较广泛,只是我们很少去注意罢了。关于概率算法还衍生出了一些有趣的理论,比如墨菲定律和幸存者偏差,此处不再详述。

1.1.3迭代过程
上面说到,优化算法就是不停的执行同样的策略、步骤直到结束。为什么要这样呢?因为优化算法是一种概率算法,执行一次操作就得到最优结果几乎是不可能的,重复多次取得最优的概率也会增大。
栗子又来了,要从1-10这10个数中取出一个大于9的数,只取1次,达到要求的概率为10%,取2次,达到要求的概率为19%。

可以看出取到第10次时,达到要求的概率几乎65%,取到100次时,达到要求的概率能接近100%。优化算法就是这样简单粗暴的来求解问题的吗?非也,这并不是一个恰当的例子,因为每次取数的操作之间是相互独立的,第2次取数的结果不受第1次取数结果的影响,假设前99次都没达到要求,那么再取一次达到要求的概率跟取一次达到要求的概率相同。
优化算法中,后一次的计算会依赖前一次的结果,以保证后一次的结果不会差于前一次的结果。这就不得不谈到马尔可夫链了。
1.1.4什么是马尔可夫链?

由铁组成的链叫做铁链,同理可得,马尔可夫链就是马尔可夫组成的链。

马尔可夫组成的链
言归正传, 马尔可夫链(Markov Chain, MC),描述的是状态转移的过程中,当前状态转移的概率只取决于上一步的状态,与其他步的状态无关。简单来说就是当前的结果只受上一步的结果的影响。每当我看到马尔可夫链时,我都会陷入沉思,生活中、或者历史中有太多太多与马尔可夫链相似的东西。西欧封建等级制度中“附庸的附庸不是我的附庸”与“昨天的努力决定今天的生活,今天的努力决定明天的生活”,你的下一份工作的工资大多由你当前的工资决定,这些都与马尔可夫链有异曲同工之处。
还是从1-10这10个数中取出一个大于9的数的这个例子。基于马尔可夫链的概率算法在取数时需要使当前取的数不小于上一次取的数。比如上次取到了3,那么下次只能在3-10这几个数中取,这样一来,达到目标的概率应该会显著提升。还是用数据说话。

取1次达到要求的概率仍然是
取2次内达到要求的概率为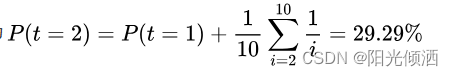
取3次内达到要求的概率为
取4次内……太麻烦了算了不算了

可以看出基于马尔可夫链来取数时,3次内能达到要求的概率与不用马尔可夫链时取6次的概率相当。说明基于马尔可夫链的概率算法求解效率明显高于随机概率算法。那为什么不将所有的算法都基于马尔可夫链呢?原因一,其实现方式不是那么简单,例子中我们规定了取数的规则是复合马尔可夫链的,而在其他问题中我们需要建立适当的复合马尔科夫链的模型才能使用。原因二,并不是所有的问题都符合马尔科夫链条件,比如原子内电子出现的位置,女朋友为什么会生(lou)气,彩票号码的规律等,建立模型必须与问题有相似之处才能较好的解决问题。
1.2(where)什么领域、业务需要或者能/不能使用优化算法?
介绍完了优化算法,再来讨论讨论优化算法的使用场景。
前面说了优化算法是一种概率算法,无法保证一定能得到最优解,故如果要求结果必须是确定、稳定的值,则无法使用优化算法求解。
例1,求城市a与城市b间的最短路线。如果结果用来修建高速、高铁,那么其结果必定是唯一确定的值,因为修路寸土寸金,必须选取最优解使花费最少。但如果结果是用来赶路,那么即使没有选到最优的路线,我们可能也不会有太大的损失。
例2,求城市a与城市b间的最短路线,即使有两条路径,路径1和路径2,它们从a到b的距离相同,我们也可以得出这两条路径均为满足条件的解。现在将问题改一下,求城市a到城市b耗时最少的线路。现在我们无法马上得出确切的答案,因为最短的线路可能并不是最快的路线,还需要考虑到天气,交通路况等因素,该问题的结果是一个动态的结果,不同的时间不同的天气我们很可能得出不同的结果。
现实生产、生活中,也有不少的场景使用的优化算法。例如我们的使用的美图软件,停车场车牌识别,人脸识别等,其底层参数可能使用了优化算法来加速参数计算,其参数的细微差别对结果的影响不太大,需要较快的得出误差范围内的参数即可;电商的推荐系统等也使用了优化算法来加速参数的训练和收敛,我们会发现每次刷新时,推给我们的商品都有几个会发生变化,而且随着我们对商品的浏览,系统推给我们的商品也会发生变化,其结果是动态变化的;打车软件的订单系统,会根据司机和客人的位置,区域等来派发司机给客人,不同的区域,不同的路况,派发的司机也是动态变化的。
综上我们可以大致总结一下推荐、不推荐使用优化算法的场景的特点。

1.3(how)如何使用优化算法?
前面说过,优化算法处理的问题都是客观的问题,如果遇到主观的问题,比如“我孰与城北徐公美”,我们需要将这个问题进行量化而转换成客观的问题,如身高——“修八尺有余”,“外貌——形貌昳丽”,自信度——“明日徐公来,孰视之,自以为不如;窥镜而自视,又弗如远甚”,转化成客观问题后我们可以得到各个解的分数,通过比较分数,我们就能知道如何取舍如何优化。这个转化过程叫做问题的建模过程,建立的问题模型实际上是一个函数,这个函数对优化算法来说是一个黑盒函数,即不需要知道其内部实现只需要给出输入,得到输出。

在优化算法中这个黑盒函数叫做适应度函数,优化算法的求解过程就是寻找适应度函数最优解的过程,使用优化算法时我们最大的挑战就是如何将抽象的问题建立成具体的模型,一旦合适的模型建立完成,我们就可以愉快的使用优化算法来求解问题啦。(“合适”二字谈何容易)

优化算法的大致介绍到此结束,后面我们会依次介绍常见、经典的优化算法,并探究其参数对算法性能的影响。






![千万级入口服务[Gateway]框架设计(二)](https://img-blog.csdnimg.cn/93e0da73bf074e55bcd4bd3e80d4aa42.png)