🍁博主简介:
🏅云计算领域优质创作者
🏅2022年CSDN新星计划python赛道第一名🏅2022年CSDN原力计划优质作者
🏅阿里云ACE认证高级工程师
🏅阿里云开发者社区专家博主💊交流社区:CSDN云计算交流社区欢迎您的加入!
目录
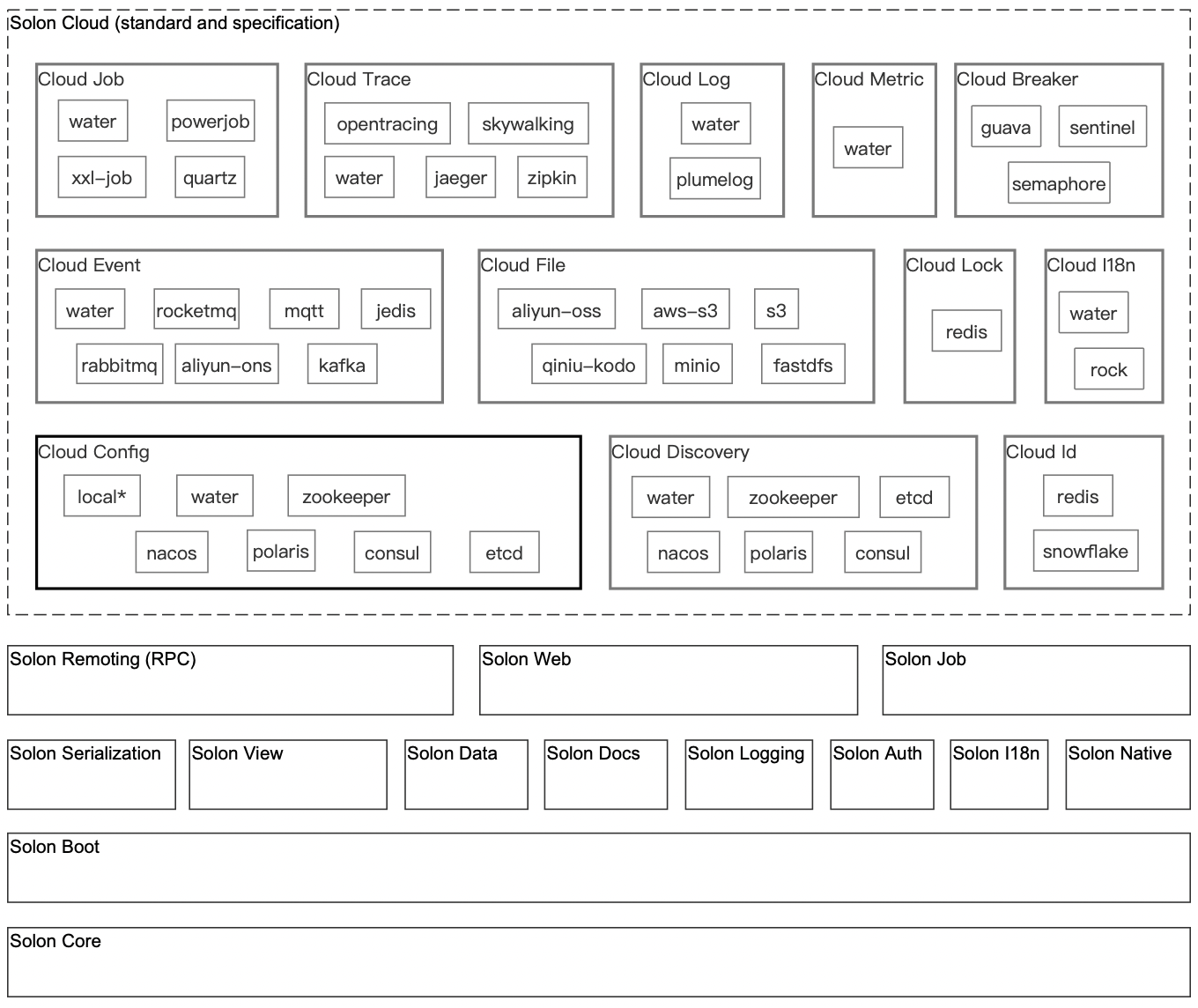
1、简介
2、准备工作
2.1 docker-compose.yml文件
2.2 master服务
2.3 worker服务
3、启动集群
4、执行应用
👑👑👑结束语👑👑👑编辑
1、简介
|
Spark是Berkeley开发的分布式计算的框架,相对于Hadoop来说,Spark可以缓存中间结果到内存从而提高某些需要迭代的计算场景的效率,目前受到广泛关注。
|
|
熟悉Hadoop的读者会比较轻松,Spark很多设计理念和用法都跟Hadoop保持一致和相似,并且在使用上完全兼容HDFS。但是Spark的安装并不容易,依赖包括Java、Scala、HDFS等。
通过使用Docker Compose,可以快速地在本地搭建一套Spark环境,方便大家开发Spark应用,或者扩展到生产环境。
|
2、准备工作
|
这里,我们采用比较热门的sequenceiq/docker-spark镜像,这个镜像已经安装了对Spark的完整依赖。由于镜像比较大(超过2GB),推荐先下载镜像到本地:
|
$ docker pull sequenceiq/spark:1.4.02.1 docker-compose.yml文件
|
首先新建一个spark_cluster目录,并在其中创建一个docker-compose.yml文件。文件内容如下:
|
master:
image: sequenceiq/spark:1.4.0
hostname: master
ports:
- "4040:4040"
- "8042:8042"
- "7077:7077"
- "8088:8088"
- "8080:8080"
restart: always
#mem_limit: 1024m
command: bash /usr/local/spark/sbin/start-master.sh && ping localhost > /dev/null
worker:
image: sequenceiq/spark:1.4.0
links:
- master:master
expose:
- "8081"
restart: always
command: bash /usr/local/spark/sbin/start-slave.sh spark://master:7077 &&
ping localhost >/dev/null|
docker-compose.yml中定义了两种类型的服务:master和slave。master类型的服务容器将负责管理操作,worker则负责具体处理。
|
2.2 master服务
| master服务映射了好几组端口到本地,端口的功能如下: |
|
·4040:Spark运行任务时候提供Web界面观察任务的具体执行状况,包括执行到哪个阶段、在哪个executor上执行;
·8042:Hadoop的节点管理界面;
·7077:Spark主节点的监听端口,用户可以提交应用到这个端口,worker节点也可以通过这个端口连接到主节点构成集群;
·8080:Spark的监控界面,可以看到所有worker、应用的整体信息;
·8088:Hadoop集群的整体监控界面。
|
2.3 worker服务
|
类似于master节点,启动后,执行/usr/local/spark/sbin/start- slave.sh spark://master:7077命令来配置自己为worker节点,然后通过ping来避免容器退出。
|
|
注意,启动脚本后面需要提供spark://master:7077参数来指定master节点地址。
|
|
8081端口提供的Web界面,可以看到该worker节点上任务的具体执行情况,如图所示。
|

3、启动集群
| 在spark_cluster目录下执行启动命令: |
$ docker-compose up|
docker-compose服务运行起来后,我们还可以用scale命令来动态扩展Spark的worker节点数,例如:
|
$ docker-compose scale worker=2
Creating and starting 2... done4、执行应用
| Spark推荐用spark-submit命令来提交执行的命令,基本语法为: |
spark-submit \
--class your-class-name \
--master master_url \
your-jar-file
app_params|
例如,我们可以使用Spark自带样例中计算Pi的应用。
在master节点上执行如下命令:
|
/usr/local/spark/bin/spark-submit --master spark://master:7077 --conf "spark.
eventLog.enabled=true" --class org.apache.spark.examples.SparkPi /usr/local/
spark/lib/spark-examples-1.4.0-hadoop2.6.0.jar 1000|
最后的参数1000表示要计算的迭代次数为1000次。
任务运行中,可以用浏览器访问4040端口,看到任务被分配到了两个worker节点上执行,如图所示。
|