摘要:本文整理自 Shopee 研发专家李明昆,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为四个部分:
1. 流批一体在 Shopee 的应用场景
2. 批处理能力的生产优化
3. 与离线生态的完全集成
4. 平台在流批一体上的建设和演进
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
01
流批一体在 Shopee 的应用场景

首先,先来了解一下 Flink 在 Shopee 的使用情况。
除了流任务,仅从支持的批任务来看,Flink 平台上的作业已经到达了一个比较大的规模。
目前 Flink 批任务已经在 Shopee 内部超过 60 个 Project 上使用,作业数量也超过了 1000,这些作业在调度系统的支持下,每天会生成超过 5000 个实例来支持各个业务线。
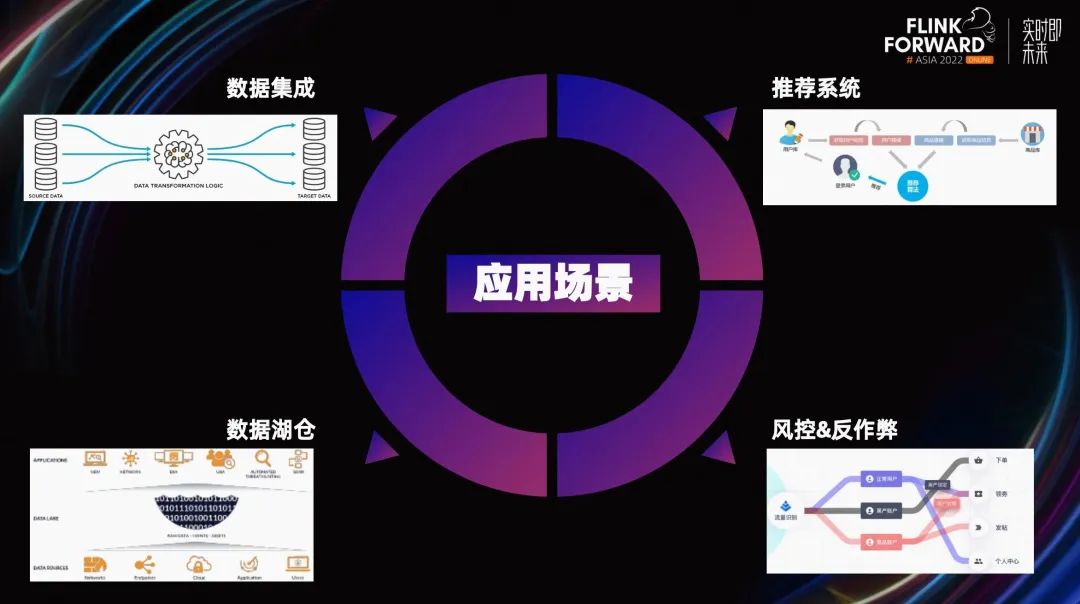
从应用场景划分,这些作业在 Shopee 主要分为以下四个部分:
第一个应用场景是数据集成领域。
第二个应用场景是数仓领域。
第三个应用场景是特征工程,主要用于实时和离线特征的生成。
第四个应用场景是风控反作弊领域,用做实时反作弊和离线反作弊。
从 Shopee 内部的业务场景来看,数仓是一个流批一体发挥重要作用的领域。
目前,业内还没有这样一个端到端流式数仓的成熟解决方案,大部分都是通过一些纯流的方案 + 离线数仓方案 + 交互式查询方案叠加起来达到近似效果。
在这类 Lambda 架构中,Flink 流批一体主要带来的优势是实现计算统一。通过计算统一去降低用户的开发及维护成本,解决两套系统中计算逻辑和数据口径不一致的问题。
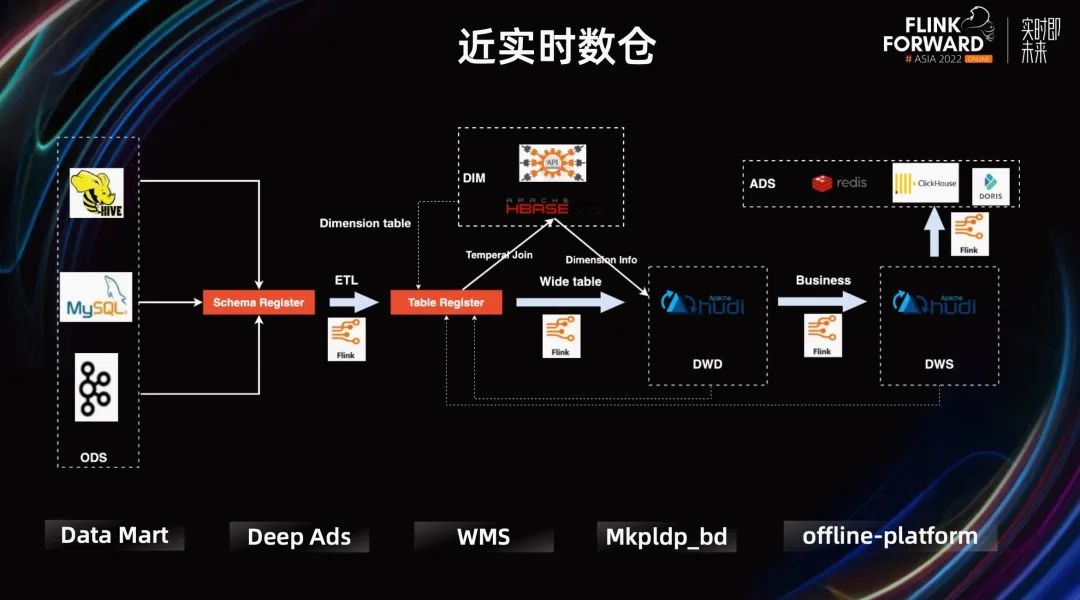
但这样的 Lambda 架构复杂性又太高了。所以针对时延要求不高的业务,Shopee 实时团队主推通过 Flink+ Hudi 的替代方案,构建近实时数仓,这种方案可以解决很多场景的问题。
这种方案的好处很明显,它实现了部分的流批一体:Flink 统一的引擎,Hudi 提供统一的存储。它的限制也很明显,Hudi 数据可见性与 Commit 的间隔相关,进而与 Flink 做 Checkpoint 的时间间隔相关,这延长了整个数据链路的时延。
目前这种 Flink+Hudi 的方案已经在 Shopee 内部很多业务线上进行使用。比如广告业务的 Deep ads.和 offline-platform ads.用于给广告主和产品运营产出广告数据。又比如 Shopee 核心业务 supply chain 的 WMS。WMS 的数据服务整体使用的是 lambda 架构。但对于核心业务使用该方案生成的近实时数据,用于与离线数据做 diff,监控实时链路提供的数据质量。
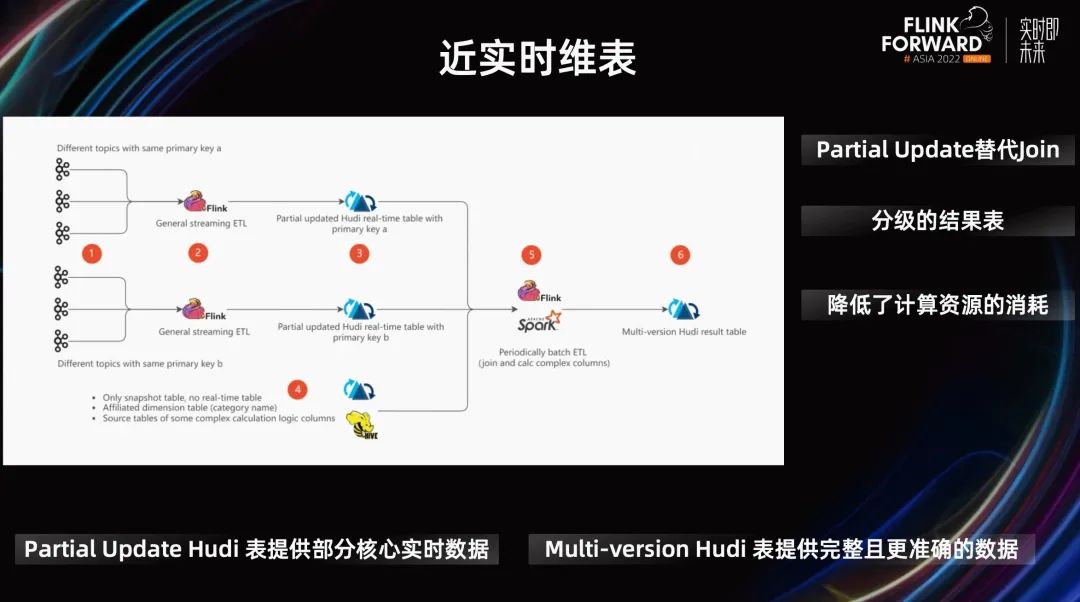
上图 PPT 展示了 Datamart 的一个例子。Datamart 使用 Hudi partital update 完成 DIM 表的 Join 更新,降低资源使用量。
之前,他们每小时对最近 3 小时的数据进行计算和刷新,在保证数据及时更新的情况下,解决数据延迟、Join 时间不对齐等问题。但随着数据量的迅速增长,小时级数据 SLA 的保障难度和计算资源的消耗都在不断增加。
现在,用户一方面通过 Flink 加速计算,另一方面通过与批处理结合来确保数据的最终一致性。并通过提供分级的结果表来满足不同场景的及时性要求,实时计算产出的 Partial Update Hudi 表提供部分核心实时数据,批处理产出的 Multi-version Hudi 表提供完整且更准确的数据。
最终,在确保数据一致性的基础上,达到了分钟级延迟,并有效降低了计算资源的消耗。

除了业务线使用之外,目前 Shopee 内部提供的一些平台服务也在使用 Flink。
第一个例子是 Data Infra 团队提供的 Data Hub, 它提供了一些离线集成和实时集成的常用模块。之前他们必须引入不同的引擎来支持不同的集成模块,导致项目依赖复杂,用户也需要了解多套引擎。
使用 Flink 后,在之后新的需求中,Data Hub 不再需要引入不同的引擎来解决批和流两套数据的集成。
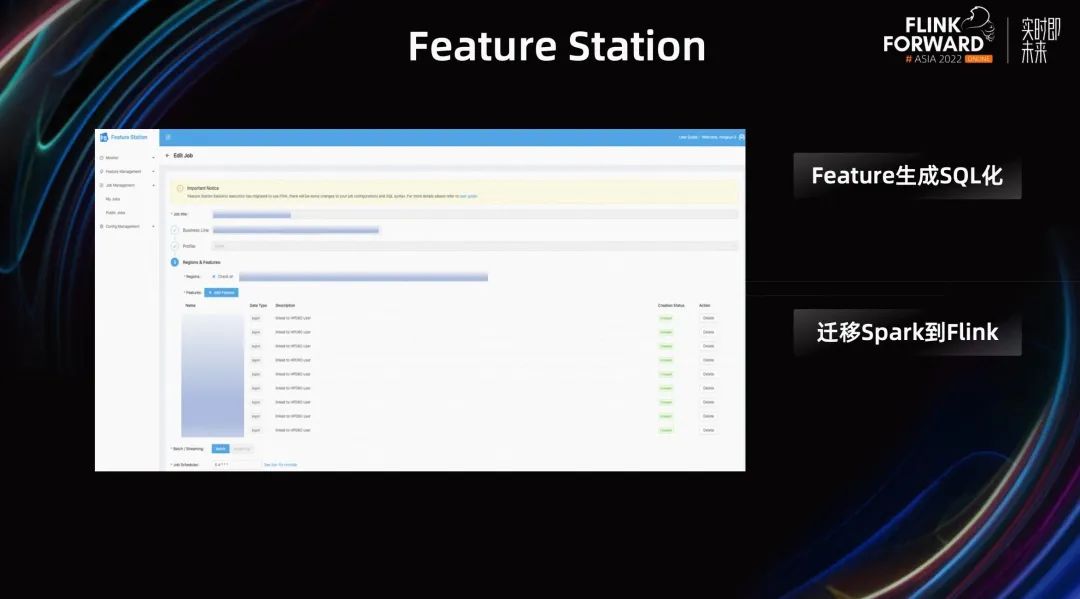
第二个例子是 Feature Station,Feature Station 是 Shopee 内部提供的一个 特征生成的平台。它提供了一些降低用户运维成本的功能,比如 Feature 生成 SQL 化,支持多业务线并行开发等等。
之前这个平台的任务依赖 Spark,后来从 Spark 全部迁移到了 Flink。Flink 带来的一个很大的优势是便于扩展。如果之后用户有实时特征需求,用户可以将离线特征的生成逻辑非常快速的复用到实时特征上。
上面介绍的都是 Shopee 内部流批一体应用场景的一些例子,我们内部还有很多团队也正在尝试 Flink 的流批一体,未来会使用的更广泛。
02
批处理能力的生产优化
Flink 在流处理方面一直有着天然的优势,相对而言,批的能力较弱一些。我们都能看到,社区最近几个版本中,一直在大力推进 Flink 批处理的能力。而对批支持的好坏也一直是用户选择 Flink 流批一体的一个重要影响因素。下面将基于内部的实践,我将介绍一下 Shopee 对 Flink 批在生产上的一些优化,主要分为稳定性和易用性两个方向。
2.1 稳定性

批作业一般都是通过调度系统周期性调度的。用户一般会管理大量的批作业,所以在生产实践中,他们非常关注作业的稳定性。
Flink Batch 在使用过程中,我们主要遇到了以下的问题:
当大作业执行时间长时,任务越容易遇到各种问题,失败次数会显著增加。
Task 失败后 failover 的成本过高,作业的整体耗时会被严重拉长。
这样就形成了恶性循环,执行时间越长越容易失败,而失败又反向拉长了执行时间。这里的根本的问题是 Shuffle。
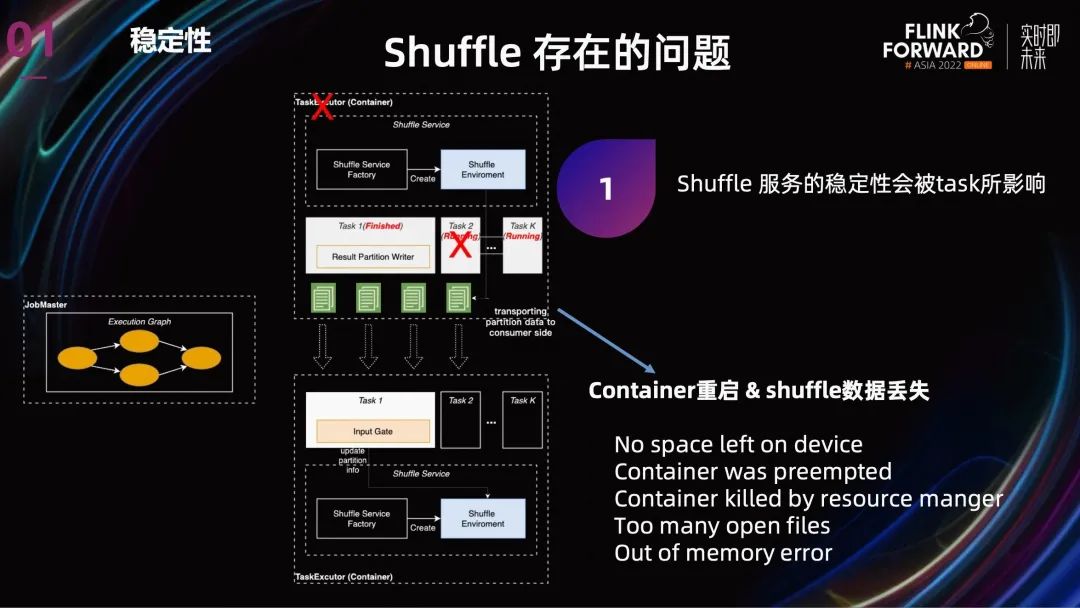
Flink 目前提供了两种 Shuffle,Hash Shuffle 和 Sort Shuffle,但这两种 Shuffle 的不同主要是表现在 Shuffle 数据的结构上,从 Shuffle 的整体架构上看,两者都是 Internal Shuffle。Internal Shuffle 就是 Shuffle 服务与 Task 共享进程,TaskManager 在 Task 执行完成之后还要继续保留去做 Shuffle 服务。
Internal Shuffle 的问题主要有两个:
第一个是:Shuffle 服务的稳定性会被有问题的 task 所影响。
这个有问题 task 可能来自 job 本身,也可能是同机器的其他 job。在 Shopee 内部,Spark 与 Flink Batch 跑在相同的离线集群,所以也会受到其他类型离线任务的影响。同样,yarn 的稳定性也会影响 Flink batch 任务。
按照现在的 failover 逻辑,TaskManager 无论是由于内部原因还是外部原因导致崩溃,Task 都会重跑,Shuffle 数据也都会丢失。尽管可能只是部分 Task 重跑,但因为我们目前使用的 1.15 没有推测执行,所以也会导致 Job 整体执行时间严重拉长。
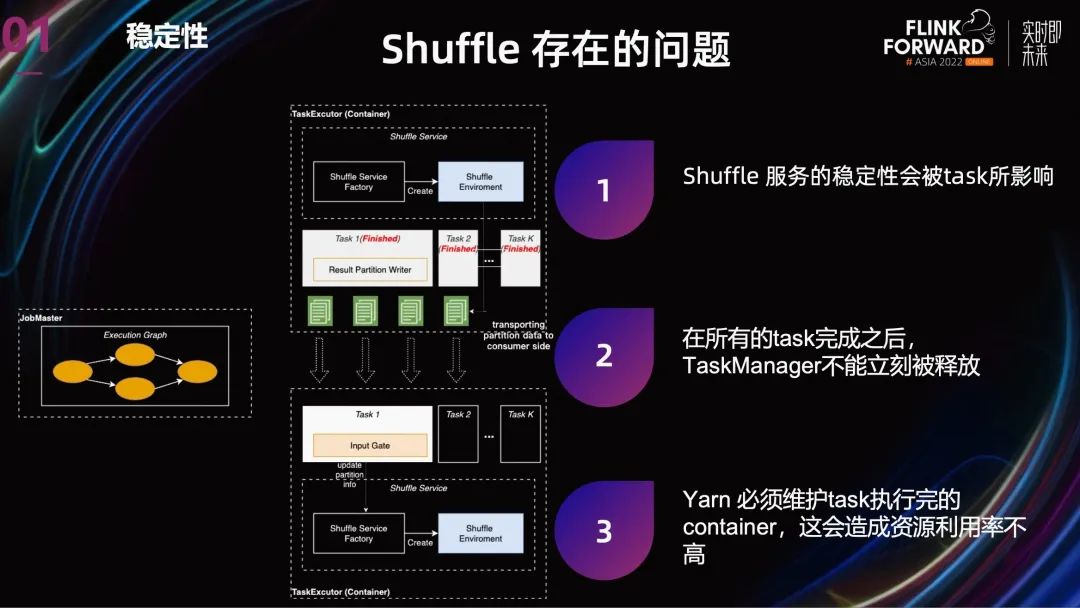
第二个是:当 Task 完成之后,由于 TaskManager 不能立刻被释放,还要提供 Shuffle 服务,这就导致 Yarn 必须维护 Task 执行完的 container,造成集群资源利用率不高。
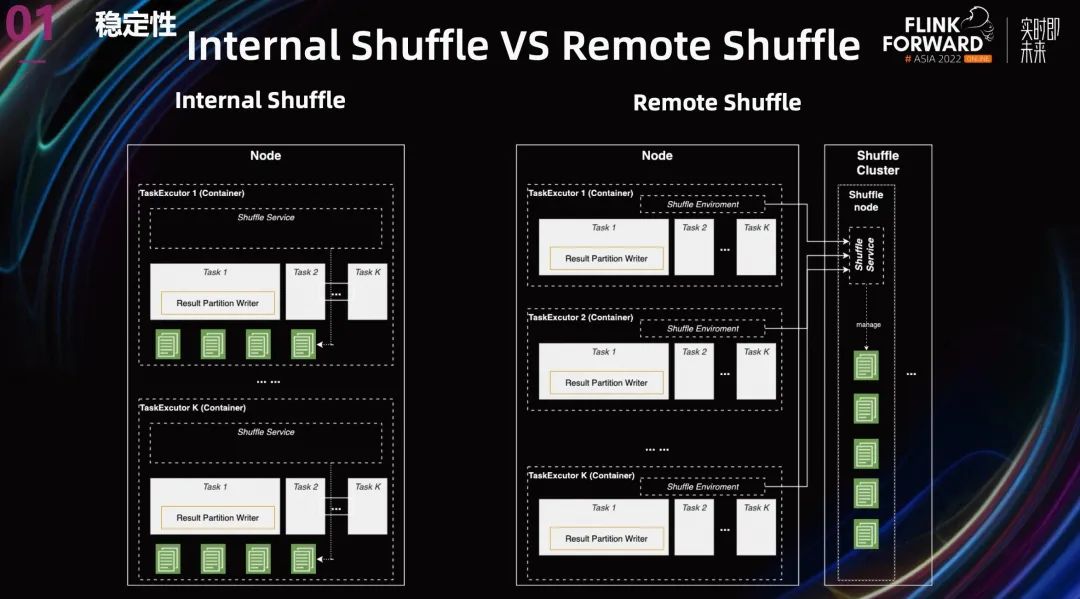
针对 Internal Shuffle 的问题,其实业界也已经有了成熟的方案,那就是 Remote Shuffle。
上图中展示了两张架构图,一个是 Internal Shuffle,另一个是 Remote Shuffle,其实还有一个 external Shuffle,External Shuffle 就是把 Shuffle 服务拆分到另一个进程中。Spark 使用的 yarn auxilary external Shuffle,就是把 Shuffle 服务挪到了 Node Manager 里面,但是这还是存储跟计算混合在一起的架构。
所以我们选择一步到位,使用 Remote Shuffle。就是转门搭建一套 Shuffle 集群来提供 Shuffle 服务。
这种存储与计算分离的架构有以下几个好处:
计算和存储再也不会相互影响。Shuffle 服务与用户的代码完全隔离。
将 Shuffle 的工作转移到 Remote Shuffle 集群后,Task 执行完毕时,Task Manager 的资源可以立刻被释放。
在这种架构下,计算跟资源解耦 了,我们可以自由的扩展或者收缩各自的资源量。
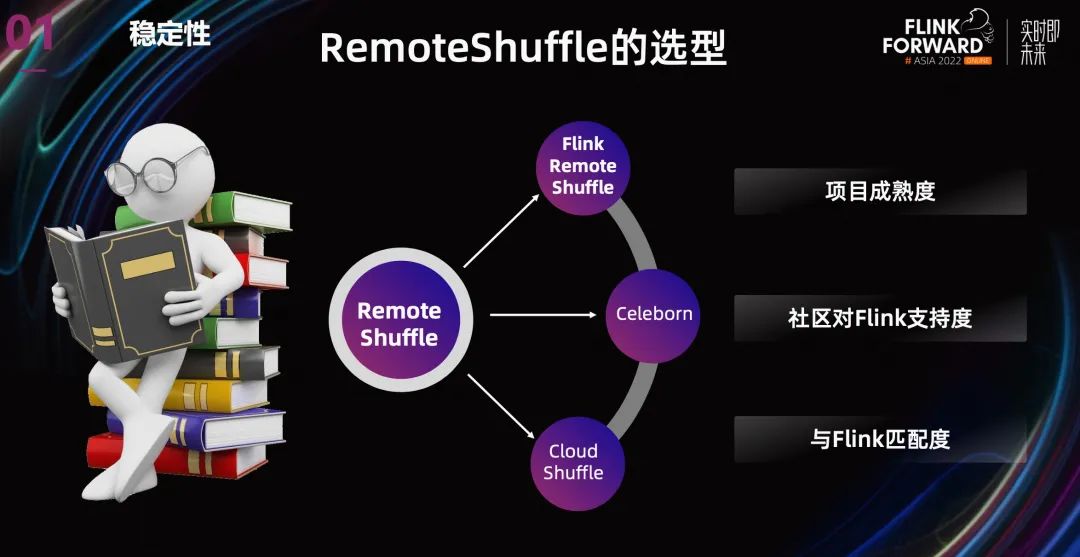
业界有不少 Remote Shuffle 的方案,比如阿里云的 Celeborn,字节的 Cloud ShuffleService,另外还有 Uber Remote Shuffle Service,Splash 等等。但是这些 Remote Shuffle 大部分主要是为了支持 Spark,支持 Flink 的并不多,另外有一些只在内部版本中支持 Flink。
最后在选型的标准里面,我们主要考虑了项目本身的成熟度,社区对 Flink 的支持度,与 Flink 的匹配程度,最终还是采用了 Flink Remote Shuffle。
这个方案有几个好处:
Flink Remote Shuffle 是 Flink 的一个扩展项目,原生就是为了支持 Flink,社区的支持力度大,之后有了问题可以跟社区多交流。
目前 Flink 的 Batch 正在快速发展,每个版本都有很大的变动和提高,比如 1.16 的 hybrid Shuffle 和推测执行,其他的 Remote Shuffle 不可能这么快速跟进。
虽然 Flink Remote Shuffle 也有缺点,但暂时可以忍受。另外 Remote Shuffle 其实是跟计算引擎分离的,等之后 Flink Batch 的特性稳定了,我们最终希望是离线能共用一套 Remote Shuffle service。

在集群部署方案上,我们采取了跟 Presto 混部的方案。主要的考虑是为了充分的利用资源,Presto 和 Remote Shuffle 在资源使用上刚好互补。Remote Shuffle 本身是一个存储服务,它不怎么使用 CPU 和 memory,但会占用大量的磁盘。相反,Presto 会占用大量的 CPU 和 memory,磁盘使用量相对较少。
另外,从时间上看,Batch 任务更多的集中在晚上,交互式查询更多集中在白天,这也有利于资源复用。再就是为了避免相互影响,我们使用 Ggroup 来为两个服务提供资源限制和隔离。
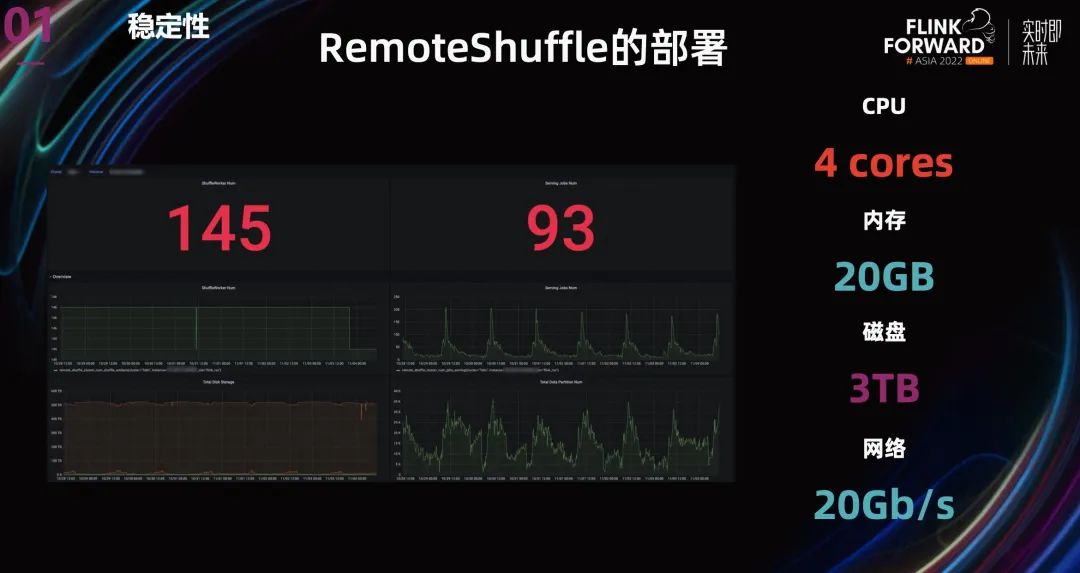
最后,我们搭建了一个有 145 个节点的 Shuffle 集群,为线上的 Batch 任务提供 Shuffle 服务。其中每个节点使用一个 3TB 的 SSD 来保存数据,有效保证 Shuffle 数据的存取性能。
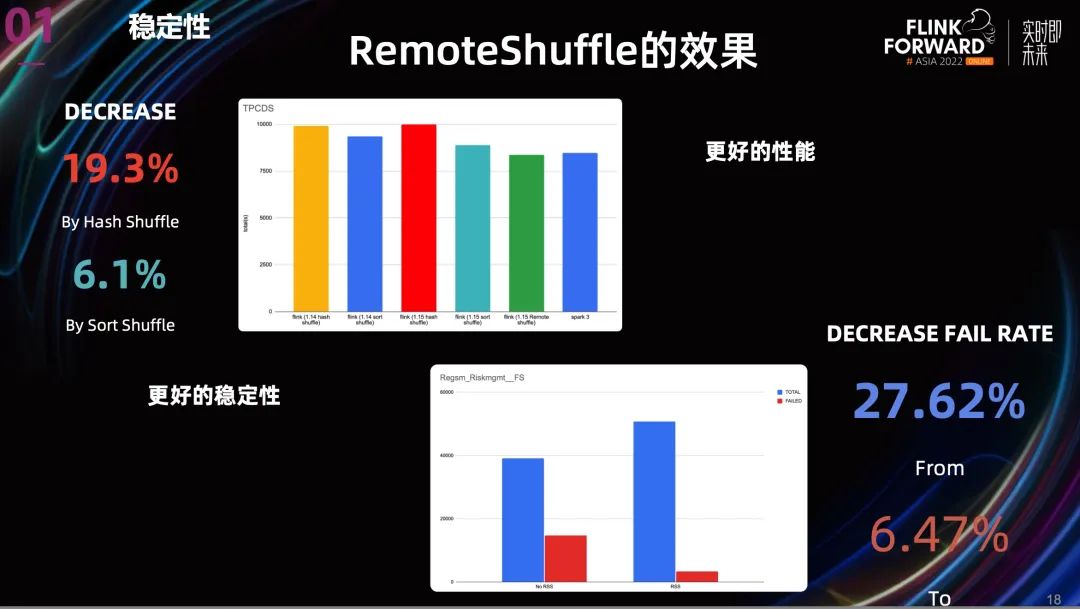
在集群搭建好之后,我们也在 Remote Shuffle Service 上做了一些测试和生产验证。从上图就可以看到效果。
从性能上看,相比 Hash Shuffle , Remote Shuffle 的性能提升了 19.3%, 相比 Sort Shuffle, 性能提升了 6.1%。
从稳定性上看,我们取了一个之前非常不稳定的 project。结果是 Task 失败率降低了超过 70%。
所以无论从性能还是稳定性,Remote Shuffle 都能带来很好的收益。
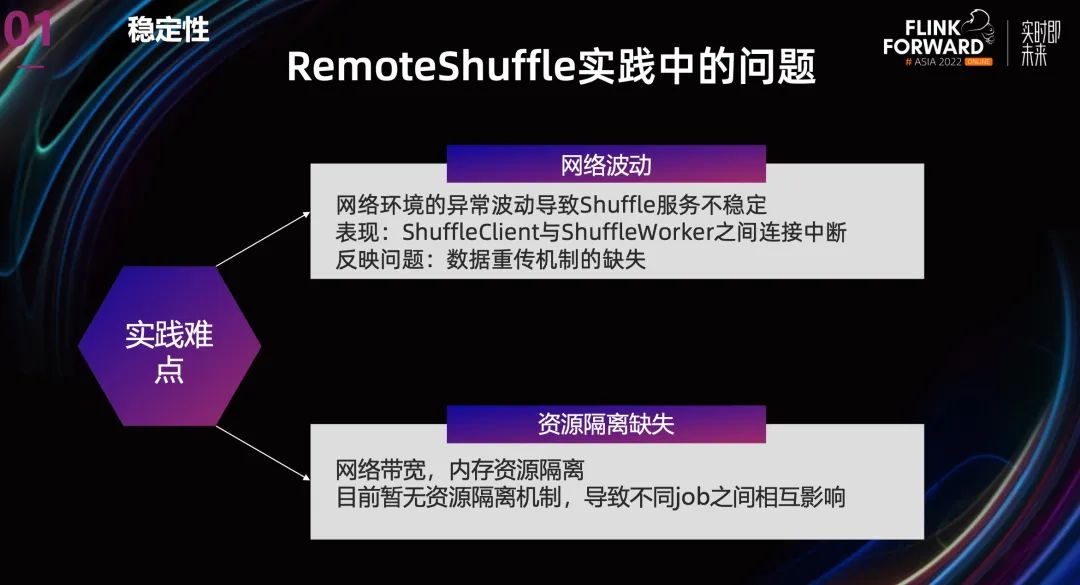
当然,Remote Shuffle 这个项目也还有一些问题。
网络环境的异常波动会导致 Shuffle 服务不稳定,表现出来主要是 ShuffleClient 与 ShuffleWorker 之间连接中断。这反映了一个问题,就是数据重传机制的缺失。
另外就是没有多租户资源隔离机制,无论是带宽还是磁盘资源,目前都没有隔离机制,这会导致不同 Job 之间相互影响。
当然,这些问题也都在不断改进中,总的来看,Flink Remote Shuffle 对 Flink Batch 有很大的帮助。
2.2 易用性

除了上面针对 Shuffle 的优化之外,Shopee 也在易用性方面做了很多工作。大家都知道,对于流批一体,Flink SQL 为核心载体。在使用过程中,SQL 也存在一系列使用上的困难。
第一个问题是 SQL 任务有问题后,对于用户而言定位困难。之前我们的流任务主要依赖 web UI,没有 History Server。有了 History Server 之后,定位 Task 的问题得到了缓解。但是还有一个比较麻烦的事情,就是 SQL 任务经过 Planner 优化之后,执行计划与 SQL 结构上有了较大差异,用户使用过程中,经常很难根据 Task 信息定位到相关的 SQL 语句。
第二个问题是 SQL 配置困难。SQL 任务各 Task 之间资源使用经常不均衡,有的是 CPU 密集型,有的是内存密集型,很难通过统一的 TM 配置来解决。社区 SQL API 也并没有提供细粒度资源配置的接口。导致一些高级用户希望优化资源使用量时,SQL 任务的资源配置十分困难。
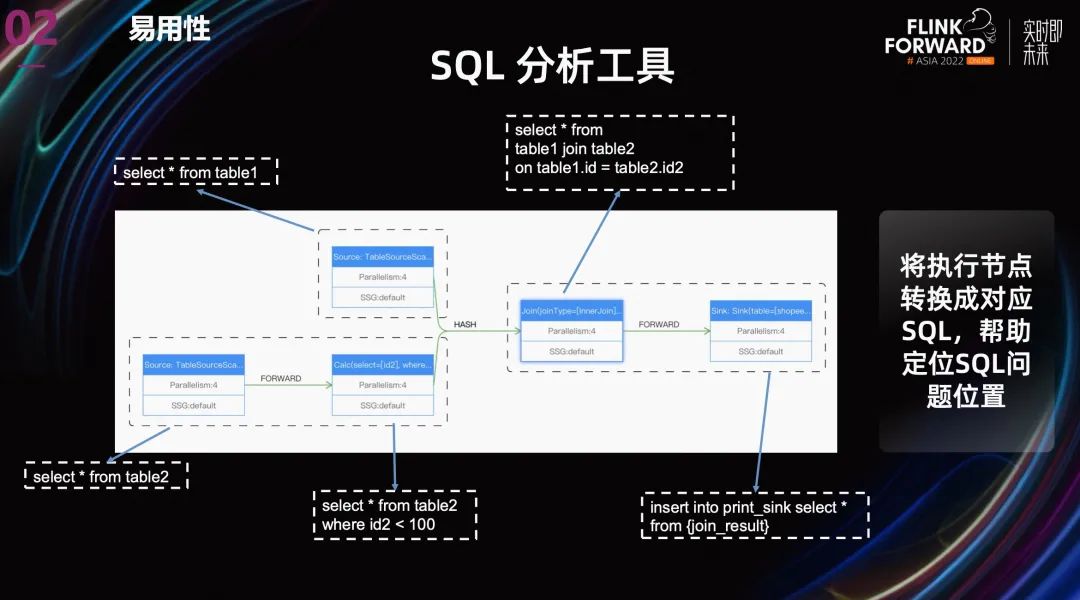
针对 SQL 问题分析定位的难点,我们做了两点优化:
在用户提交 SQL 任务之前,展示作业的 streamgraph,让用户执行之前就能看到 SQL 的执行逻辑,以判断是否符合自己的预期。
第二个优化就像上图中展示的一样,将执行节点转换成对应 SQL,让用户知道每个 Task 的对应的 SQL 段,帮助定位问题位置。

另外,一些算子为了在不同的数据下有更好的性能,同一个算子会有多种实现方案,比如 join。一些用户在排查问题时,会关心优化器对 SQL operator 的具体实现逻辑。所以,除了展示每个 Task 的对应的 SQL 之外,我们还提供展示 SQL 算子对应生成的 Java code,以确定算子底层实现逻辑,辅助排查 SQL 故障。
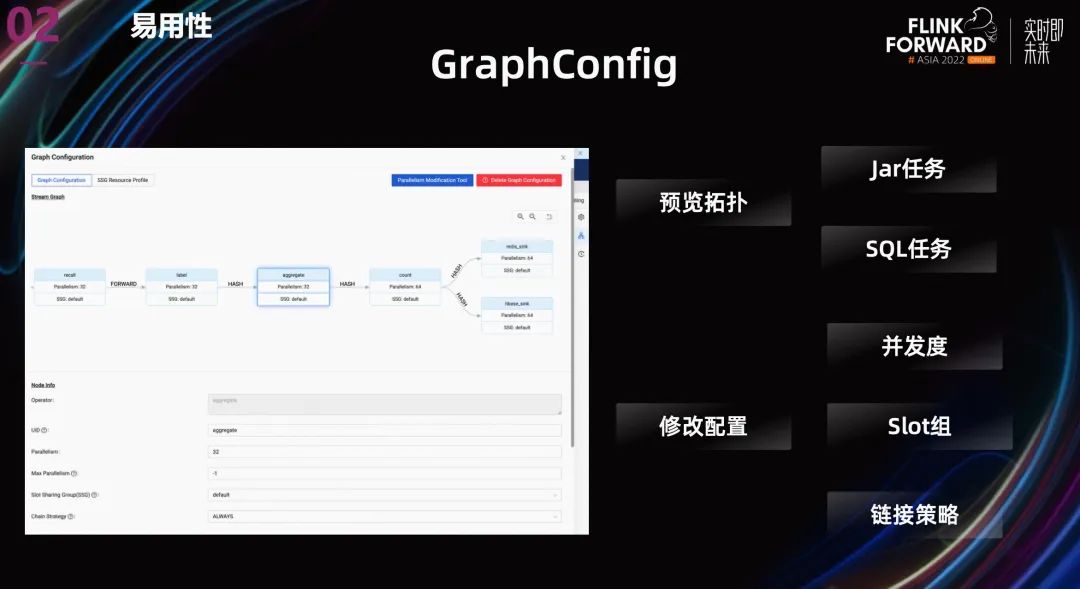
针对第二个 SQL 任务资源优化的问题,我们在展示 streamgraph 的基础上,允许为不同的 operator 配置不同的并发度,链接策略还有 slot group 等等。
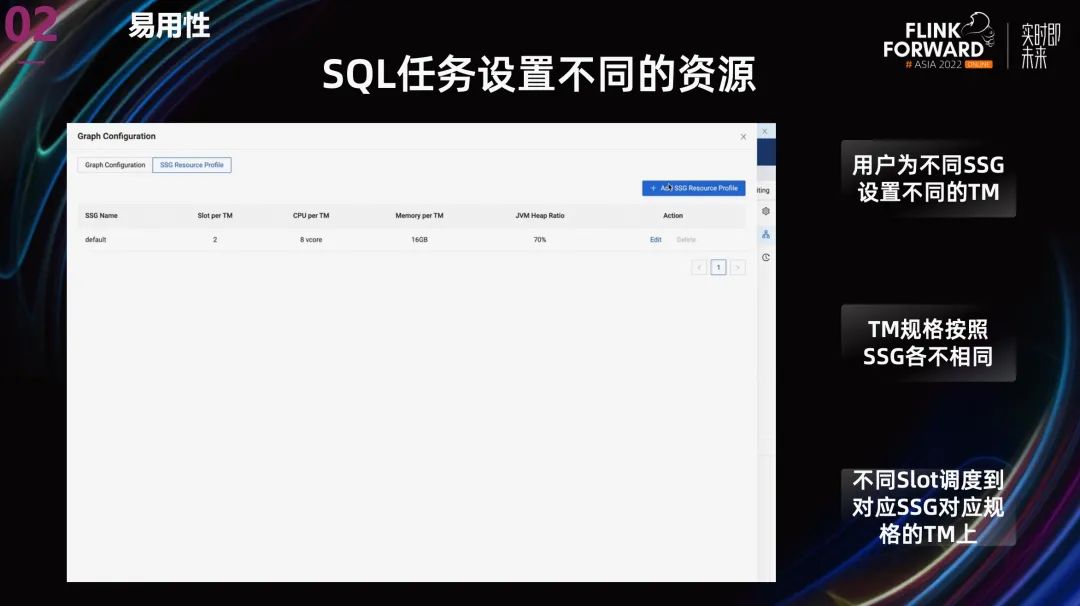
在资源配置上,我们并没有使用社区提供的 operator 级别的细粒度资源配置。主要有两个原因:
Slot 资源使用量用户很难监控,目前最多监控到 TM 粒度。这导致用户没有监控依据,无法准确预估每个 slot 的资源使用量。
动态资源切割机制导致机器上出现大量碎片。
我们最后使用了自己开发的 SlotGroup 级别的资源配置,整体思路是不同的 SlotGroup 申请不同规格的 TM,Slot 依然是均分 TaskManager 的资源,但可以通过为不同的 Operator 设置不同的 SlotGroup,进而设置不同的资源量。
这种方案让用户可以很方便的依据 TaskManager 使用监控,定位到配置不合理的 SlotGroup 和 Operator, 进而调整 TM 资源配置,优化作业的整体资源利用率。
上图中的功能依赖于我们内部开发的“SlotGroup 粒度的资源调度”。

当然除了以上对 Batch 的优化之外,我们还进行很多其他的优化。比如复用 stream 模式下 compact 小文件的逻辑;调整容错机制, 支持 Batch SQL 的小文件 compact
还有就是 parquet 的 nested projection/filter pushdown;优化超过 64 位 GroupId 生成策略;优化 FileSourceCoodinator 创建逻辑等等。
这些优化都有效解决了生产过程中 Shopee 各个业务线遇的问题。
03
与离线生态的完全集成
在流批一体落地的过程中,用户最关心的就是技术架构的改动成本和潜在风险。作为 Flink 平台,面临的一个很重要的挑战就是如何兼容好用户已经广泛应用的离线批处理能力。所以第三部分主要介绍与离线生态的集成,主要涉及开发和执行两个层面的问题。
3.1 开发层面

开发层面主要是复用的问题,复用的目的是为了降低用户的使用成本。由于很多用户已经在其他引擎上积累的大量的业务 UDF,所以我们提供的统一 UDF 来解决 UDF 复用的问题。
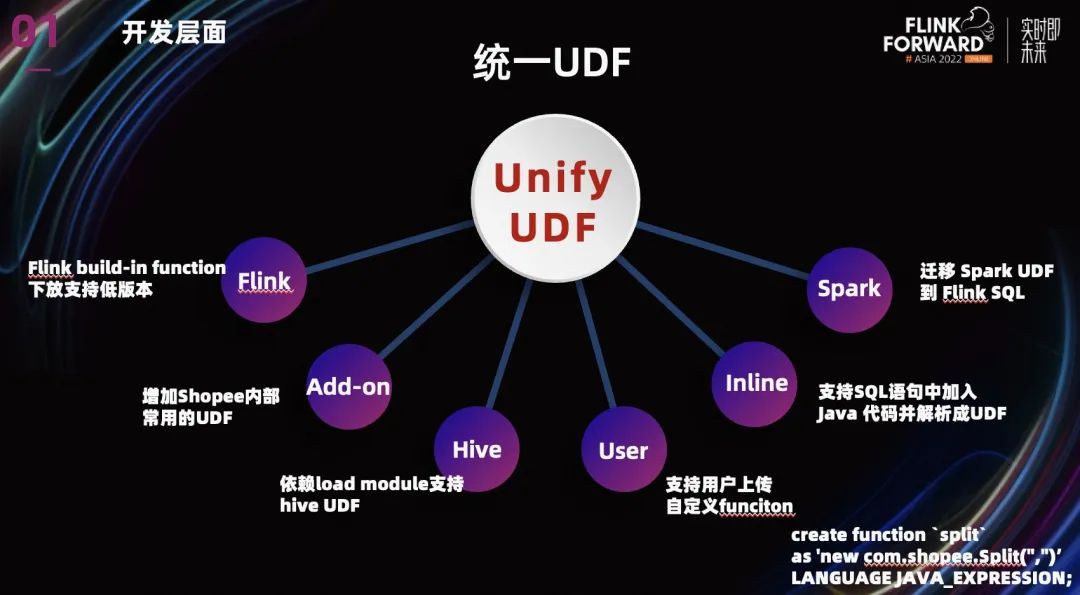
统一 UDF 的目标是为了用户能在 Flink 平台上无缝访问各种 UDF。目前我们已经支持了很多类型的 UDF。
Flink 本身的 UDF,我们将很多 Flink build-in function 下放支持低版本。
增加了一些 Shopee 内部常用的 UDF,用户也可以上传共享自定义的 UDF。
针对其他引擎的 UDF,我们依赖 load module 支持了的 Hive UDF。对于 Spark build in 的 UDF,为了降低用户使用成本,我们也把大量常用的 Spark UDF 迁移到了 Flink。
值得一提的是,我们团队目前已经支持了 SQL 语句中加入 Java 代码并解析成 UDF。上图中有个例子,之后我们还会支持 lambda 表达式等等,这将大大方便用户对 UDF 的使用。
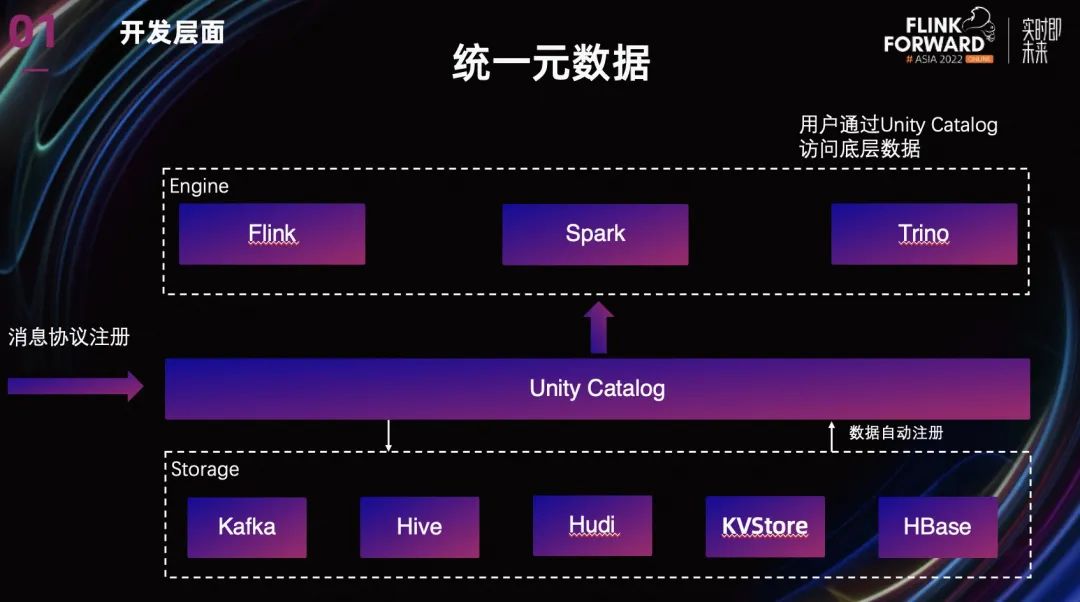
除了复用 UDF 以外,我们还通过统一元数据来复用已经存在的离线数据模型。与其他各自已有的元数据管理一起,加上依赖 HDP scheme registry 构建的实时元数据,一起构建形成 Unity Catalog。
用户可以只通过 Unity Catalog 来访问底层不同的数据,在平台提供的 SQL IDE 中,可以十分方便的访问已有的 Catalog 和数据表。目前已经支持了 Kafka,Hive,Hudi, Redis, Hbase 这几个不同的数据类型。
3.2 执行层面
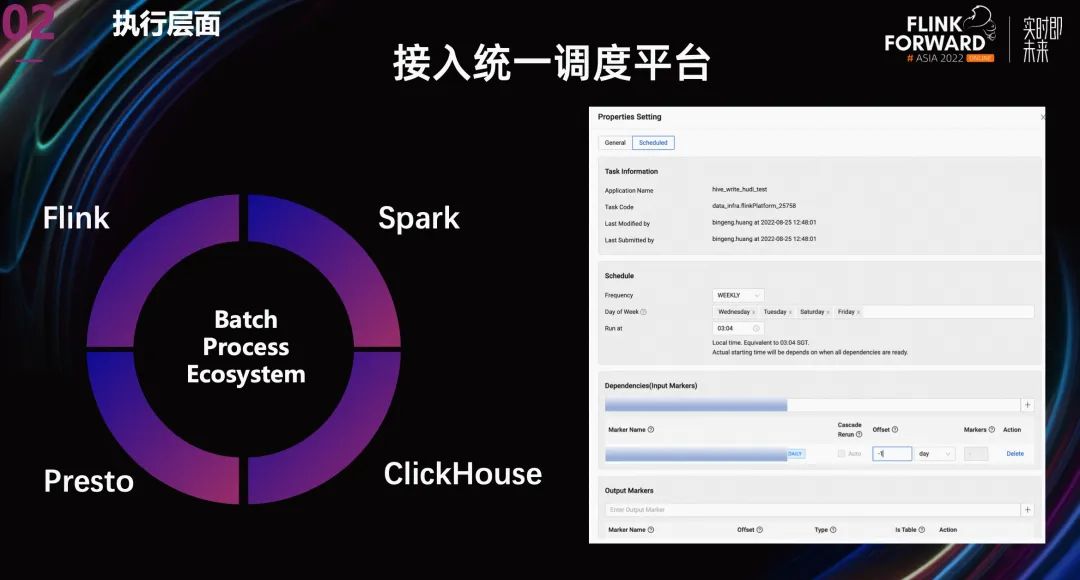
在执行层面,随着 Flink 能力的增强,用户希望 Flink SQL 批任务嵌入到当前的数据加工过程中,作为中间的一个环节。所以我们将 Flink Batch 接入了 Shopee 内部的统一调度平台 Data Scheduler。并且通过统一的数据 marker 服务来进行数据依赖。最终将 FlinkBatch 与已有的其他数据处理引擎打通,更好的服务用户。
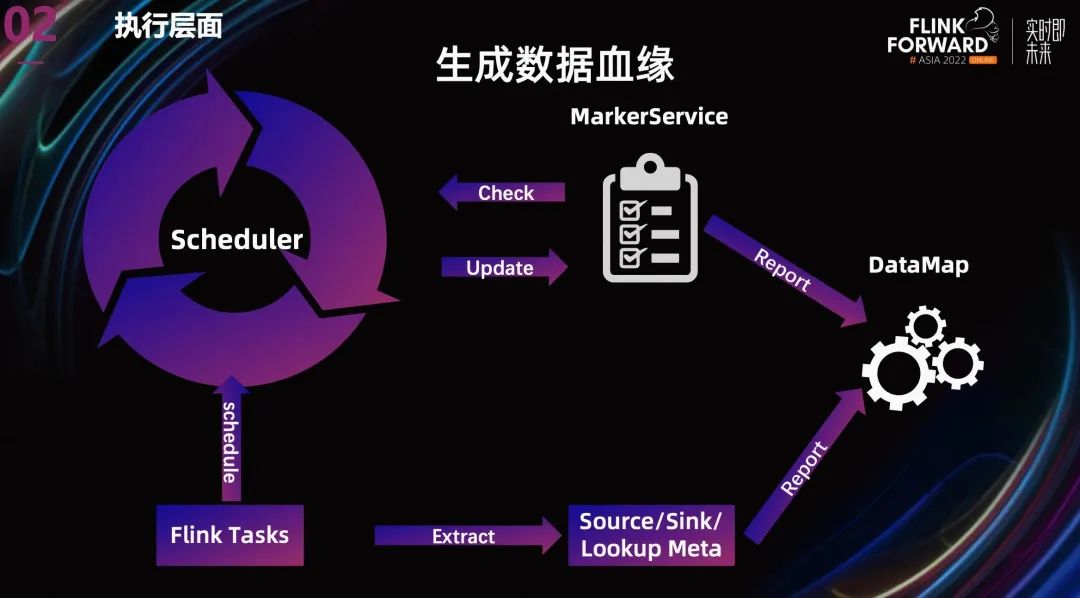
另外,在离线领域,清晰的血缘是对数据进行追溯和影响分析的基础。当数据有了清晰的血缘和归属,系统中的数据就有了清晰的结构。
我们团队目前除了通过上一张 PPT 提到的数据 marker 来提供数据依赖关系之外,
还从 gragh 中抽取 Source,Sink,Lookup 的元数据信息,报告给 Datamap,以生成更完整的数据血缘。
当然除了离线数据的元数据之外, 我们也正在设计将实时数据的元数据整合到现有的数据血缘中,彻底将所有数据的归属打通。
04
平台在流批一体上的建设和演进
最后我想介绍一下我们 Flink 平台在流批一体上的建设和演进。其实在上面介绍中,已经展示了不少平台的功能。所以这一部分,我只会重点介绍一下平台对运维工具 History Server 的优化。
其实 Flink 流任务对 History Server 的需求并不大,因为流任务理论上一直在运行,我们可以用 web UI。但是对于批任务,History Server 却是一个非常有效的运维追溯工具。
4.1 HistoryServer 接入 Yarn 日志
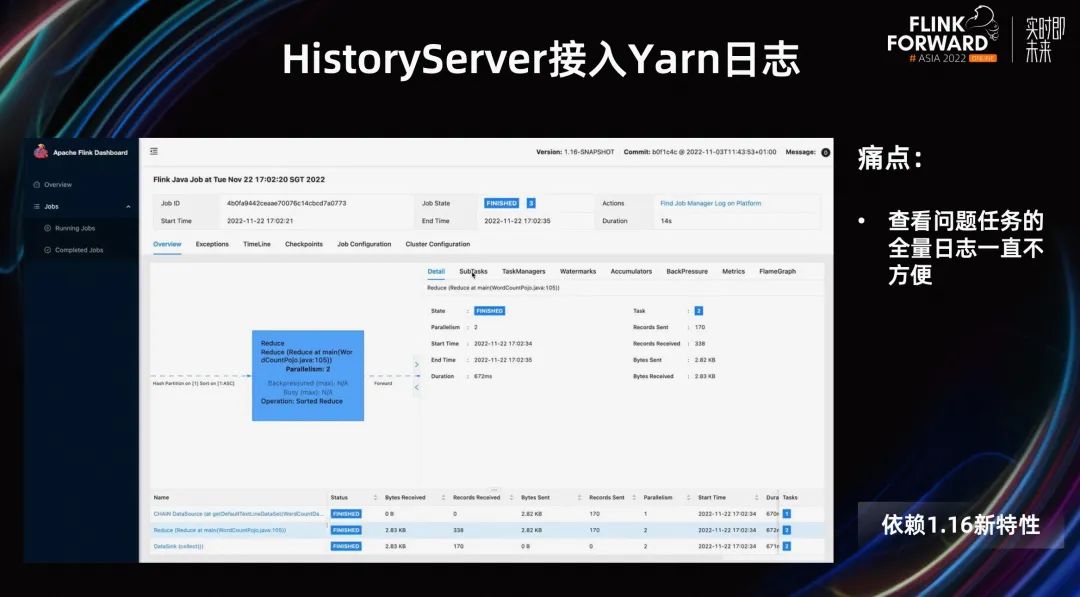
首先我要宣传一下 1.16 的新特性:跳转外部 log。
虽然我们平台已经将用户的日志接入的 kibana,但是因为日志是混合的,所以查询的时候用户要先定位到 subTask,然后需要输入各种筛选条件查询,查询流程比较长,速度也比较慢。所以我们一直想优化这个流程,在最近发布的 1.16 中,支持了接入外部 log 的功能,我们针对日志较少的 Batch 任务,直接使用该特性跳转到 yarn 的 history log,十分方便查看问题 Task 的全量日志。
4.2 HistoryServer 小文件问题

另外,History Server 还有一个小文件的问题。从上图左侧可以看到,History Server 将历史任务存储为大量 Json 小文件用于服务 Web UI。当只支持流任务的时候这个问题并不明显,但是随着我们平台支持批任务后,历史任务的数量剧增。
数量的上涨带来的几个问题:
大拓扑,大并发的任务的解压对 History Server 服务产生压力。
历史任务产生的大量文件对部署节点的文件系统产生大量存储开销。大量小文件导致单个 History Server 只能保存很短时间的历史任务。不然就会将单机的 inode 耗光。
History Server 目前重启后需要重新拉取历史 Job 信息并解压。
这些都给生产带来了问题。
4.3 HistoryServer 优化方案
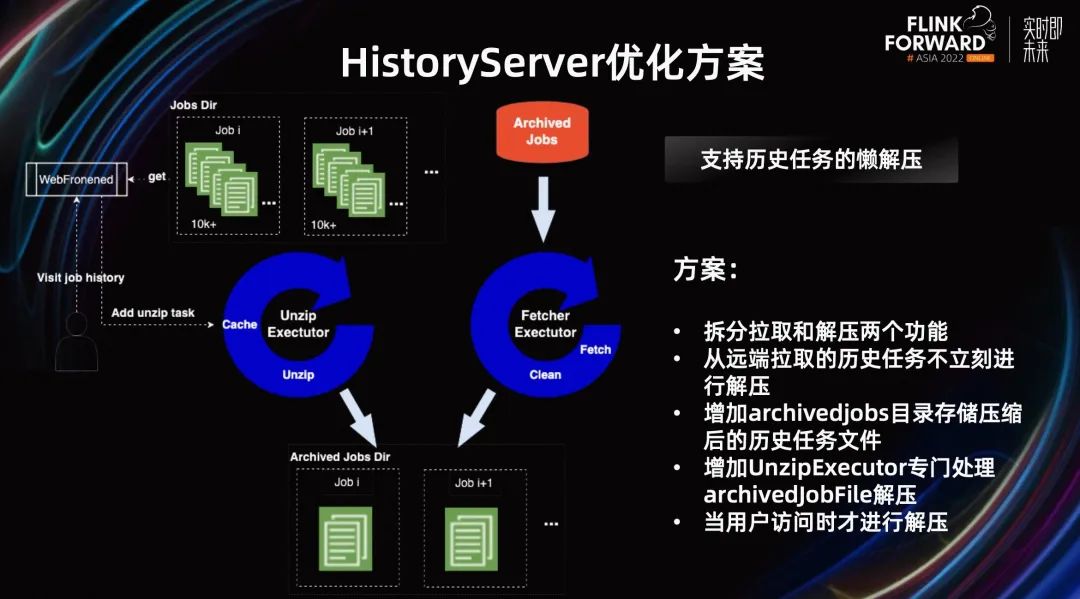
所以我们对 History Server 整体架构做了优化,整体的思路是,只对需要的历史 Job 进行解压。
第一,是拆分拉取和解压两个功能,将原有的 Fetcher Executor 拆分成了 Fetcher Executor 和 Unzip Executor。Unzip Executor 专门处理 archivedJobFile 解压。
第二,增加 archivedJobs 目录存储压缩后的历史任务文件,从远端拉取的历史任务不立刻进行解压。而是当用户访问时增加一个解压任务进行解压。
这样就减少了 History Server 的工作量,降低了 History Server 的负载,也降低了部署节点的存储开销。这个方案在我们线上使用后,将存储开销降低了 90%以上,效果十分明显。
4.4 Flink 平台的演进

最后,简单介绍一下 Shopee Flink 平台支持批任务的发展过程。
我们内部支持 Flink 的批是从去年三季度开始的,到现在为止一年多。从改造平台支持 Batch,到并入离线生态,打通依赖和血缘,再到搭建 Remote Shuffle。有效的支撑起了 Shopee 各个业务线对 Flink 流批一体的需求。
整个落地过程中,最主要经验的是要站在用户的视角看待问题,合理地评估用户的改动成本以及收益,帮助用户找出业务迁移的潜在风险,降低用户使用的门槛。
未来规划主要还是在业务拓展方面。我们会加大 Flink 批任务的推广,探索更多流批一体的业务场景。同时跟社区一起,在合适的场景下,加速用户向 SQL 和流批一体的转型。
往期精选





▼ 活动推荐▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源