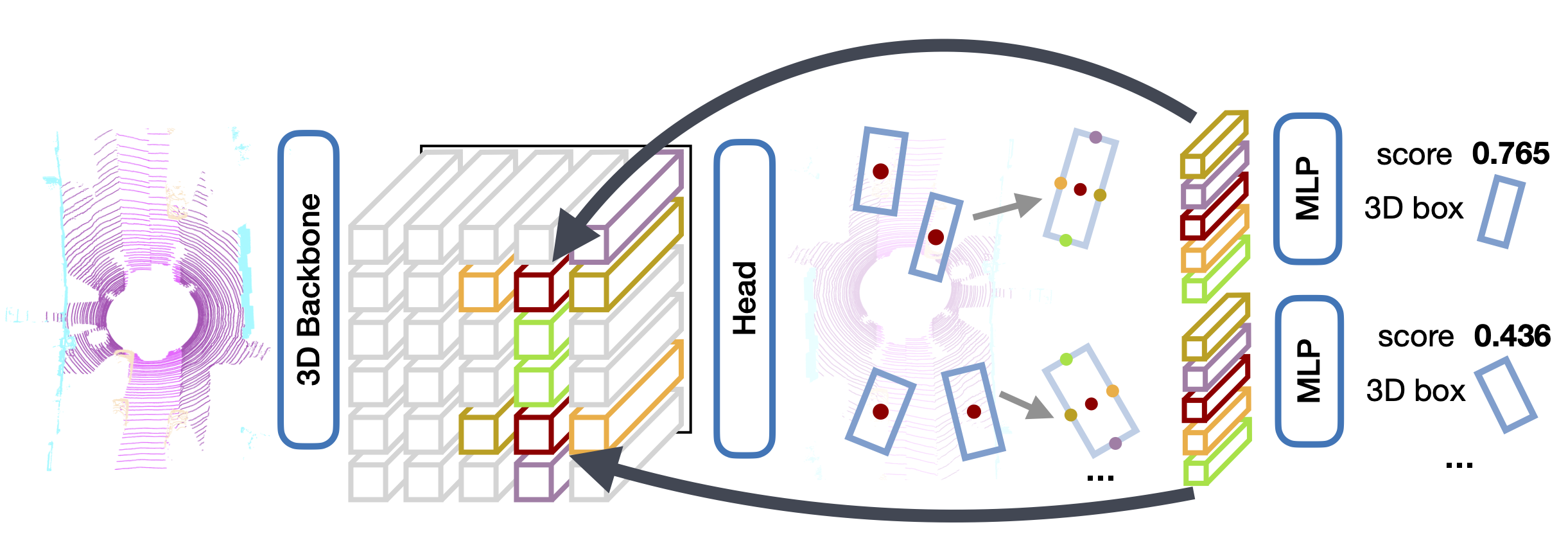
第1关:词云练习1
任务描述
本关任务:编写一个能制作词云的小程序。
相关知识
词云
词云,也叫文字云,是一种应用广泛的数据可视化方法。是过滤掉文本中大量的低频信息,形成“关键词云层”或“关键词渲染”,对出现频率较高的“关键词”予以视觉化的突出展现,使浏览者只要一眼扫过文本就可领略文本的主旨。
word_cloud 是 python 的一个第三方库,可根据文本或文本中的词频,对文本内容进行可视化。
安装方法:
pip install wordcloud

word_cloud生成词云的主要方法有如下,分别用于以词频为参数或以字符文本为参数的场景。
| 方法名 | 使用场景 |
|---|---|
| fit_words(frequencies) | 根据词频生成词云,参数为包含词与词频的字典,为generate_from_frequencies的别名 |
| generate(text) | 根据文本生成词云,是generate_from_text的别名 |
| generate_from_frequencies(frequencies) | 根据词频生成词云,参数为词频字典 |
| generate_from_text(text) | 根据文本生成词云,如果参数是排序的列表,需设置’collocations=False’,否则会导致每个词出现2次。 |
| process_text(text) | 将英文长文本text分词并去除屏蔽词后生成词云。 |
请按照如下要求,依次绘制对应的词云图:
根据文件 Who Moved My Cheese.txt 的内容,用词频为参数的方法绘制英文词云,设置背景色为白色,不显示坐标轴。

(图片仅供参考,与本题要求不同)
编程要求
根据提示,在右侧编辑器补充代码,完成词云图的制作。
测试说明
平台会对你编写的代码进行测试:
- 预期输出:
图像对比一致,恭喜通关!
参考代码
import string
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def read_file(file):
"""接收文件名为参数,将文件中的内容读为字符串,只保留文件中的英文字母和西文符号,过滤掉中
文,所有字符转为小写,将其中所有标点、符号替换为空格,返回英文文本字符串。"""
with open(file, 'r', encoding='utf-8') as f:
res = ''.join([x for x in f.read() if ord(x)<256]).lower()
for c in string.punctuation:
res = res.replace(c, ' ')
return res
def word_frequency(txt):
"""参数 txt去除标点、符号的文本,统计并返回每个单词出现的次数。返回值为字典类型"""
dic = {}
for s in txt.split():
dic[s] = dic.get(s, 0)+1
return dic
def draw_cloud_en_freq(en_frequency):
"""参数 en_frequency为字典类型词频,绘制词云,显示高频单词数量为80个,图片的宽度600,高度400,背景白色、字体最大值150、图片边缘为5,放大画布1.5倍,不随机(random_state=False),不显示坐标轴,词云保存为图片,路径和名为:'result/result.png' """
wc = WordCloud(max_words=80, width=600, height=400,
background_color='White', max_font_size=150,
margin=5, scale=1.5, random_state=False)
wc.generate_from_frequencies(en_frequency)
plt.axis('off')
wc.to_file('result/result.png')
plt.imshow(wc)
if __name__ == '__main__':
filename = 'Who Moved My Cheese.txt' # 英文文件名
content = read_file(filename) # 调用函数返回字典类型的数据
frequency_result = word_frequency(content) # 统计词频
draw_cloud_en_freq(frequency_result) # 调用函数生成词云
plt.show() # 显示图像
第2关:词云练习2
任务描述
本关任务:编写一个能制作词云的小程序。
相关知识
相关知识请参考 词云练习1 内的相关知识
根据文件“Who Moved My Cheese.txt”的内容,用文本为参数的方法绘制英文词云,设置背景色为白色,不显示坐标轴。观察两种方法绘制结果,分析其原因,了解stopwords参数的意义及stopwords文件的内容,思考用词频方法时,怎样处理才能得到与文本方法相近的结果?

编程要求
根据提示,在右侧编辑器补充代码,完成词云图的制作,具体要求查看模板中的函数文档注释。
测试说明
平台会对你编写的代码进行测试:
- 预期输出:
图像对比一致,恭喜通关!
参考代码
import string
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def read_file(file):
"""接收文件名为参数,将文件中的内容读为字符串,只保留文件中的英文字母和西文符号,过滤掉中
文,所有字符转为小写,将其中所有标点、符号替换为空格,返回英文文本字符串。"""
with open(file, 'r', encoding='utf-8') as f:
res = ''.join([x for x in f.read() if ord(x)<256]).lower()
for c in string.punctuation:
res = res.replace(c, ' ')
return res
def draw_cloud_en_txt(text):
"""参数text读文件获取的文本,绘制词云,显示高频单词数量为80个,
图片的宽度600,高度400,背景白色、字体最大值150、图片边缘为5,
放大画布1.5倍,不随机(random_state=False),不显示坐标轴,
词云保存为图片,路径和名为:'result/result.png' """
wc = WordCloud(max_words=80, width=600, height=400,
background_color='White', max_font_size=150,
margin=5, scale=1.5, random_state=False)
wc.generate(text)
plt.axis('off')
wc.to_file('result/result.png')
plt.imshow(wc)
if __name__ == '__main__':
filename = 'Who Moved My Cheese.txt' # 英文文件名
content = read_file(filename) # 调用函数返回字典类型的数据
draw_cloud_en_txt(content)
第3关:词云练习3
任务描述
本关任务:编写一个能制作词云的小程序。
相关知识
相关知识请参考 词云练习1 内的部分内容
jieba分词
中文词之间无分隔,所以中文词云的制作略麻烦,需要提前对文本进行分词处理。 jieba 是目前应用较广泛的一个中文分词库,可以导入 jieba 利用它进行分词再绘制词云。
import jieba
import jieba.analyse
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
应用 textrank() 方法对字符串进行分词,可用参数 topK 设置最多返回多少个词(词性表 allowPOS 默认仅提取词性为地名 ns 、名词 n 、动名词 vn 、动词 v),例如设置 topK=100 ,返回最多 100 个词。返回的词与其权值以元组类型作为列表的元素,按权值降序排列,数据格式如:
('科技', 1.0), ('创新', 0.6818768373499384), ('研究', 0.39785607069634815), ('科学家', 0.39327521713414126), ...]
将这个列表转为字典类型, 利用 WordCloud.generate_from_frequencies() 方法,以词频作参数,便可以绘制中文词云了。读文件 scientist.txt ,根据内容生成词云,字体不限,但要求中文能正常显示。设置用前 60 个高频词生成词云,背景色为白色,用 ball.jpg 作背景图片或自选背景图片。

编程要求
根据提示,在右侧编辑器补充代码,完成词云图的制作。
测试说明
平台会对你编写的代码进行测试:
- 预期输出:
{'科技': 1.0, '创新': 0.6818768373499384, '研究': 0.39785607069634815}
图像对比一致,恭喜通关!
参考代码
import jieba.analyse
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def read_file(file):
"""接收文件名为参数,将文件中的内容读为字符串"""
with open(file, 'r', encoding='utf-8') as f:
return f.read()
def word_frequency_cn(txt):
"""参数 txt读文件获取的文本,jieba.analyse.textrank()可用参数topK设置最多返回多少个按词频降序排列的关键词列表,
数据格式为列表:[('人民', 1.0), ('中国', 0.9533997295396189), ...],
将列表转为字典:{'人民': 1.0, '中国': 0.9533997295396189,...},返回这个字典"""
List = jieba.analyse.textrank(txt, topK=60, withWeight=True)
print(List)
return dict(List)
def draw_cloud_cn(frequency_dict):
"""参数为词频,字典类型,设定图片的中文字体为('fonts/MSYH.TTC')、背景为白色、
背景图片'ball.jpg'、字体最大值200、按比例进行放大画布2倍,储存为 result/result.png"""
bg = plt.imread('ball.jpg')
wc=WordCloud(font_path='fonts/MSYH.TTC',
background_color='White',
mask=bg, max_font_size=200,
scale=2, random_state=False)
wc.generate_from_frequencies(frequency_dict)
plt.axis('off')
wc.to_file('result/result.png')
plt.imshow(wc)
if __name__ == '__main__':
filename = '湿地公约.txt' # 用于生成词云的中文文件名
content = read_file(filename)
frequency = word_frequency_cn(content) # 利用jieba对文本进行分词,并统计词频
draw_cloud_cn(frequency) # 绘制词云






![[Hadoop之Hive安装配置 第二篇 ]](https://img-blog.csdnimg.cn/79161e637efd4a2ba8c4fd090fd75e20.png)