YOLO v8 训练自己的数据集
- 环境准备
- YOLO v8
- 创建自己的数据集
- 1.首先准备了VOC 格式的数据集
- 2.然后确定用于训练、测试的数据
- 3.将VOC格式标注转为YOLO 标注
- 4.配置数据文件 yaml
- 配置 YOLO v8
- 安装和训练
- 安装依赖包
- 训练
环境准备
这里我的环境是Windows 环境
YOLO v8
下载链接:https://github.com/ultralytics/ultralytics
官方教程链接:https://docs.ultralytics.com/quickstart/
预训练模型:https://github.com/ultralytics/assets/releases
创建自己的数据集
1.首先准备了VOC 格式的数据集
推荐使用labelImg 得到 Annotations
数据文件结构
-data
—images 所有图片(.jpg .png 等)
—Annotations VOC格式标注(.xml)
—ImageSets 目前为空
—labels 目前为空
2.然后确定用于训练、测试的数据
import os
from random import sample
from pathlib import Path
trainval_percent = 0
train_percent = 1
xml_file_path = Path('data/Annotations')
txt_save_path = Path('data/ImageSets')
total_xml = os.listdir(xml_file_path)
num = len(total_xml)
num_list = list(range(num))
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = sample(num_list, tv)
train = sample(trainval, tr)
with open(txt_save_path / 'trainval.txt', 'w') as ftrainval, \
open(txt_save_path / 'test.txt', 'w') as ftest, \
open(txt_save_path / 'train.txt', 'w') as ftrain, \
open(txt_save_path / 'val.txt', 'w') as fval:
for i in num_list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
3.将VOC格式标注转为YOLO 标注
import xml.etree.ElementTree as ET
import os
sets = ['train']
classes = ["WCF"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x *= dw
w *= dw
y *= dh
h *= dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(f'data/Annotations/{image_id}.xml')
out_file = open(f'data/labels/{image_id}.txt', 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (
float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text)
)
bb = convert((w, h), b)
out_file.write(f'{cls_id} {" ".join(str(a) for a in bb)}\n')
in_file.close()
out_file.close()
wd = os.getcwd()
print(wd)
for image_set in sets:
os.makedirs('data/labels/', exist_ok=True)
with open(f'data/ImageSets/{image_set}.txt') as f:
image_ids = f.read().strip().split()
with open(f'data/{image_set}.txt', 'w') as list_file:
for image_id in image_ids:
list_file.write(f'data/images/{image_id}.jpg\n')
convert_annotation(image_id)
4.配置数据文件 yaml
自己创建 data.yaml
# train val test 集合
train: .../data/train.txt
val: .../data/train.txt
test: .../data/train.txt
# 类别标签
names:
0: tree
# nc: 类别数
nc: 1
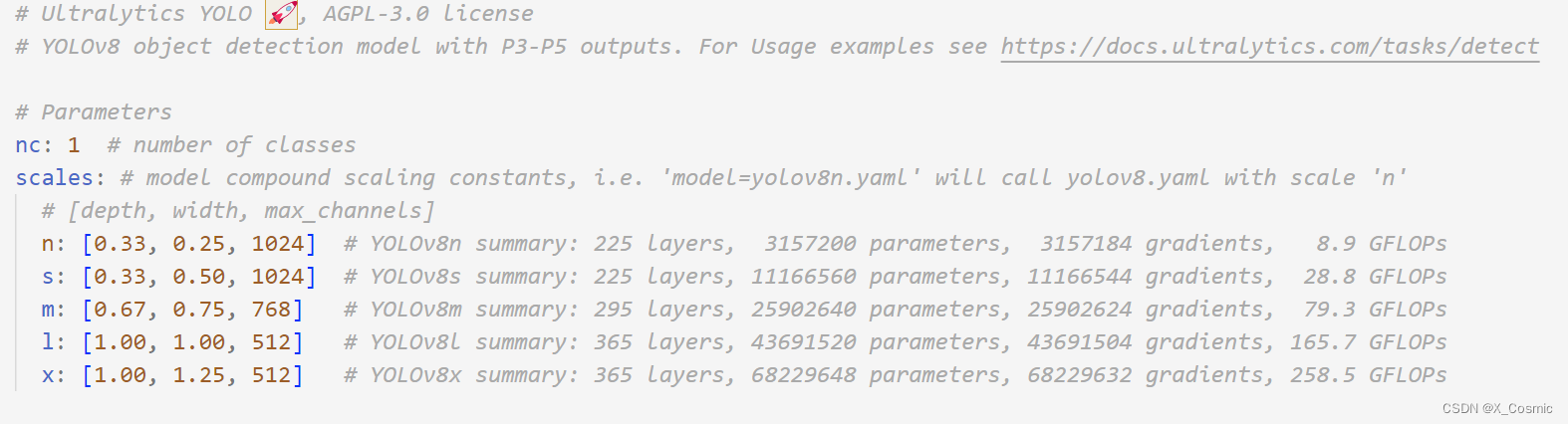
配置 YOLO v8
需要找到yolo v8 的yaml 文件
通常地址为:ultralytics\models\v8
修改类别数
也可改动里面其他的信息
安装和训练
安装依赖包
pip install ultralytics
训练
Win 上workers 尽量改为1
if __name__ == '__main__':
from ultralytics import YOLO
# Load a model
model = YOLO('.../ultralytics/models/v8/yolov8m.yaml').load('models/yolov8m.pt') # build from YAML and transfer weights
# Train the model
model.train(data='data/data.yaml', batch=3, epochs=300, imgsz=640,workers=1)