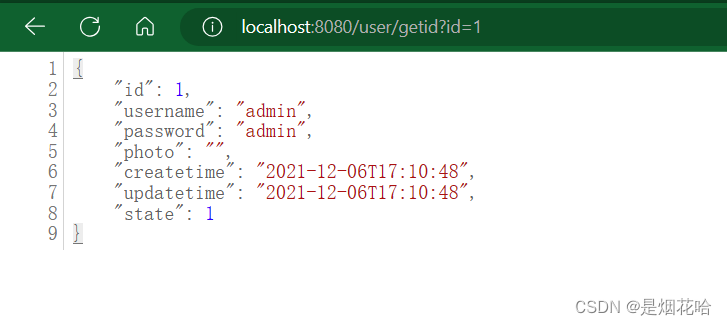
Tensorflow训练代码1.x接口自动升级2.x踩坑记录
- TF准备工作
- 环境问题解决
- 自动升级脚本,从TF1.0调通到TF2.0

一起学AI系列博客:目录索引
本文小结Tensorflow训练代码1.x接口自动升级2.x踩坑过程和问题解决的方法。
TF准备工作
Tensorflow环境准备
- 前提已安装好Anaconda/Spyder/Tensorflow,步骤略
- 从spyder进入tensorflow环境,具体方法见:link
- 核心步骤:
- Anaconda prompt命令窗下:
activate tensorflowSpyder
- Spyder界面右侧IPython对话窗:
import tensorflow as tf,如无报错则表明环境进入成功
- Anaconda prompt命令窗下:
MNIST数据集准备
于官网下载数据集文件4个,相对py代码,将其放在../MNIST目录下。
环境问题解决
以下为跑基线代码时遇到的问题记录。
版本环境:
- Anaconda:2.0.3
- Tensorflow:2.9.1
- Python:3.8
- Spyder:5.4.3
报错解决:ModuleNotFoundError: No module named tensorflow_datasets’
- 下载examples/turials目录拷贝至本地tensorlow路径,具体方法见:link。
报错解决:AttributeError: module ‘tensorflow’ has no attribute ‘placeholder’
- tf句柄替换为兼容v1的版本句柄,参见链接:link1,link2
报错解决:RuntimeError: tf.placeholder() is not compatible with eager execution.
- 在使用placeholder前,添加语句:
tf.compat.v1.disable_eager_execution(),具体原因见:link1,link2
接着又报:AttributeError: module ‘tensorflow._api.v2.train’ has no attribute ‘exponential_decay’,发现一个个换不是个办法。
而究其核心原因:该代码版本为1.x 环境tf接口,tf2.0相对而言许多接口已无法直接调用,需要兼容适配。
所以接下来有两种解决方案:
- 现有环境降级,Python和TF动
- 现有代码升级,代码替换,找自动化工具,自动完成TF接口迁移替换
显然第一种因噎废食成本较大,优选第二种方式。
自动升级脚本,从TF1.0调通到TF2.0
首先,查看Tensorflow官网有介绍升级脚本工具和EXE,见:link。具体使用可参考:网友总结方法。
其次,梳理下使用时遇到的报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xad in position 175: illegal multibyte sequence,且用tf_upgrade_v2.exe和tf_upgrade_v2_main.py脚本运行时都报错。
分析确认py脚本都是utf8编码无gbk,说明升级脚本里默认没按utf8编码,于是修改源码,将路径C:\ProgramData\Anaconda3\Lib\site-packages\tensorflow\tools\compatibility下的ast_edits.py中:
with open(in_filename, "r") as in_file, \- 替换为
with open(in_filename, "r", encoding='utf-8') as in_file, \
成功使训练代码从tf1.x升级tf2.x,本地升级脚本,运行指令举例:
tf_upgrade_v2_main.py --infile D:\test\d3_1_ref.py --outfile D:\test\d3_1_v2.py
最后,还要注意代码转换时,内部注释#不要和中文连在一起,要用空格隔开,否则存在编码异常,报gbk cant encode。