1.打印输出
print(“Hello World”)
在许多大众的编程语言中,需要在每个语句的末尾添加分号,但Python并非如此。Python是一种简洁的编程语言,你不需要添加不必要的字符和语法。在Python中,一条语句结束于一行的结尾(方括号,引号或括号除外)。
Python中的分号表示分隔,而不是终止。它允许在同一行中编写多个语句。
print('Statement1'); print('Statement 2'); print('Statement 3')
此语法允许在单个语句的末尾加上分号:
print('WhyGod? WHY?');
2.python解释器的概念
安装运行环境时候其实就是安装python解释器,用来将python的代码转换成二进制
3.python中常用数据类型
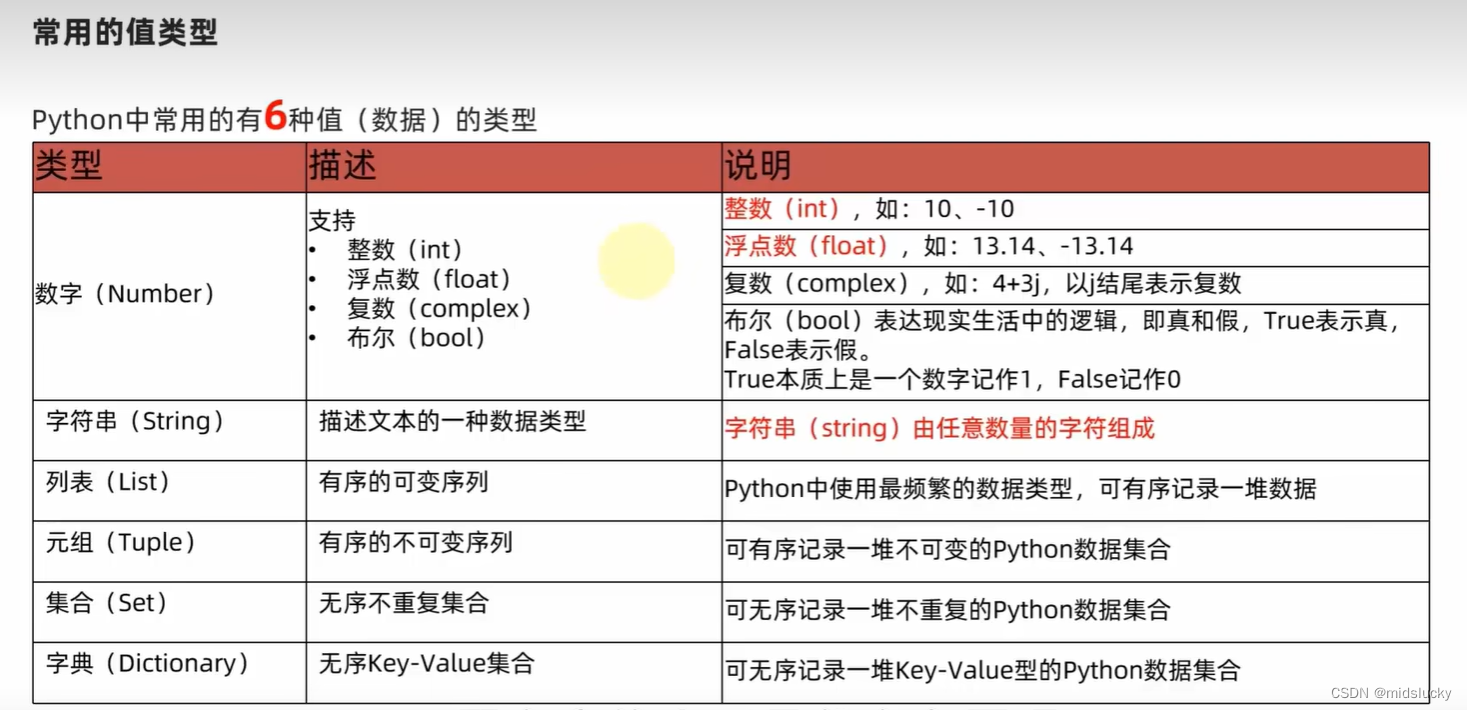
字面量:被写在代码中被固定的值。
比如print(666);这个666
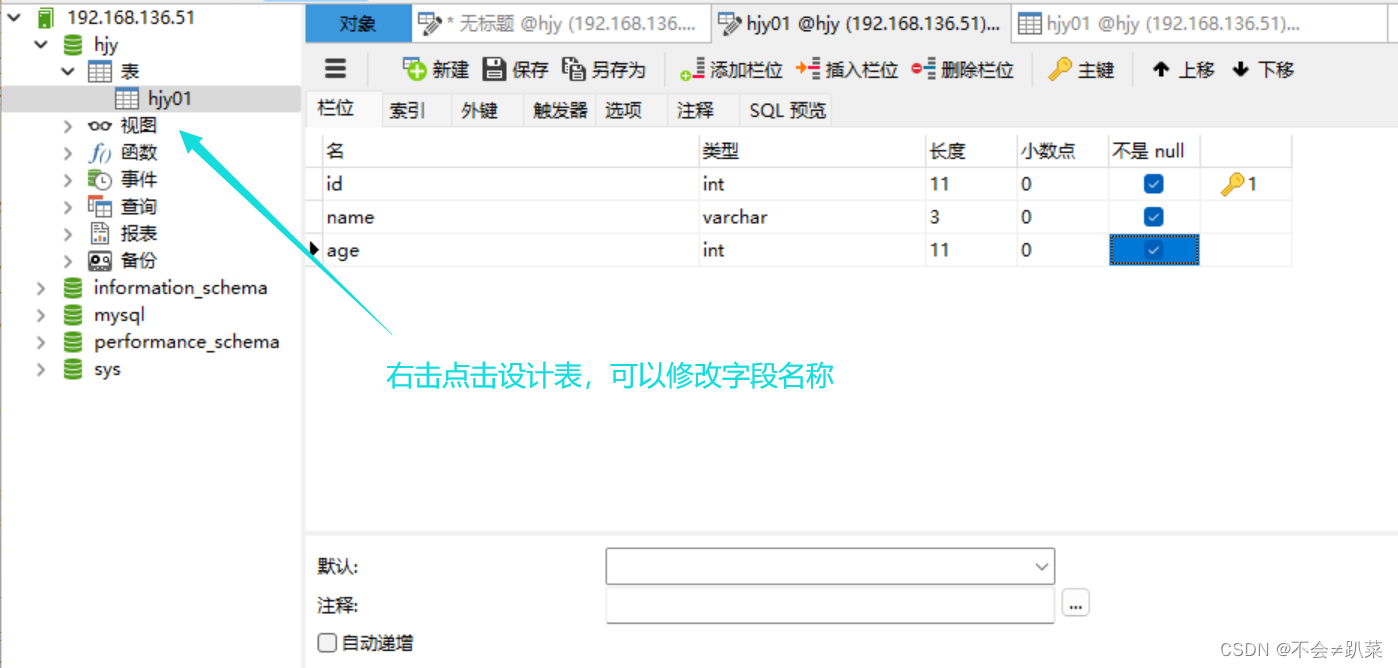
使用type()语句查看变量类型,如下图所示演示示例:
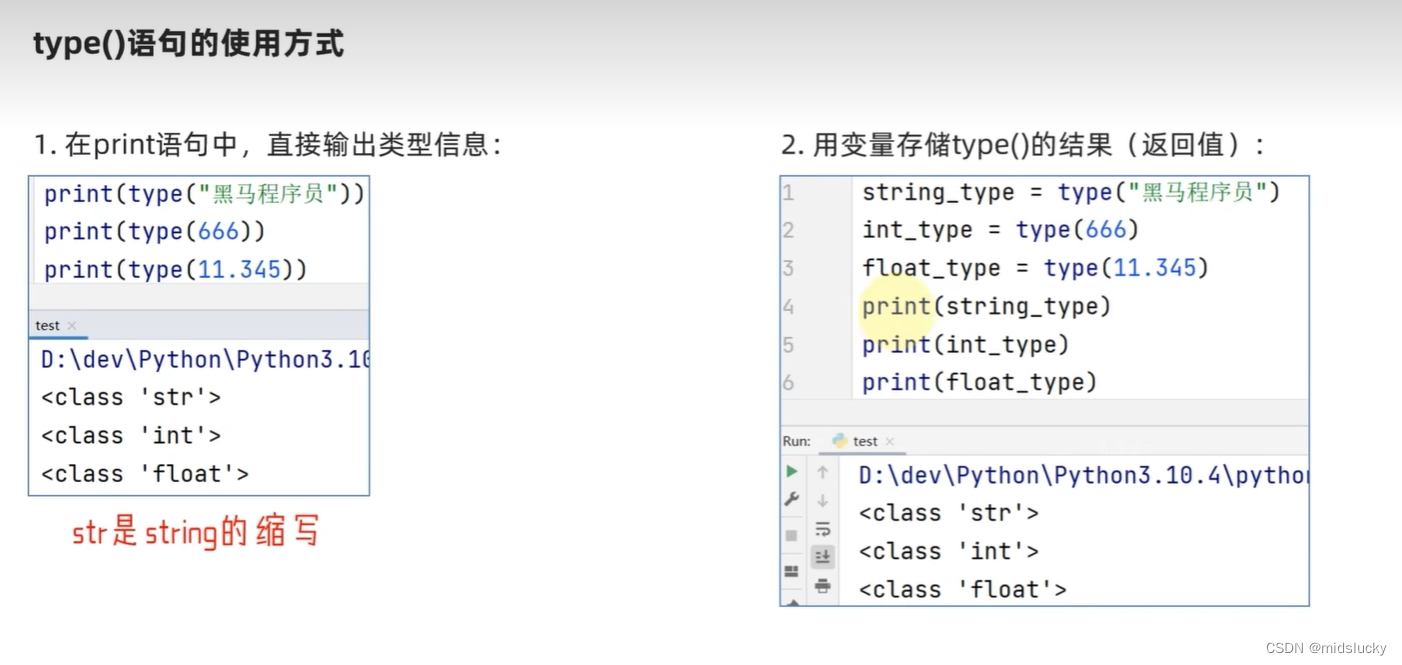
(字面量和变量的数据类型都能查看,就比如a=10; tpye(a);)
4.注释
666 #这里是单行注释
"""
使用 3 个双引号分别作为注释的开头和结尾
可以一次性注释多行内容
这里面的内容全部是注释内容
"""
'''
使用 3 个单引号分别作为注释的开头和结尾
可以一次性注释多行内容
这里面的内容全部是注释内容
'''
5.定义变量
money = 50
print("钱包还有:",money)
monet = money -10
print("买了冰淇淋花了10元还剩余:",money ,"元")

6.数据类型的转换
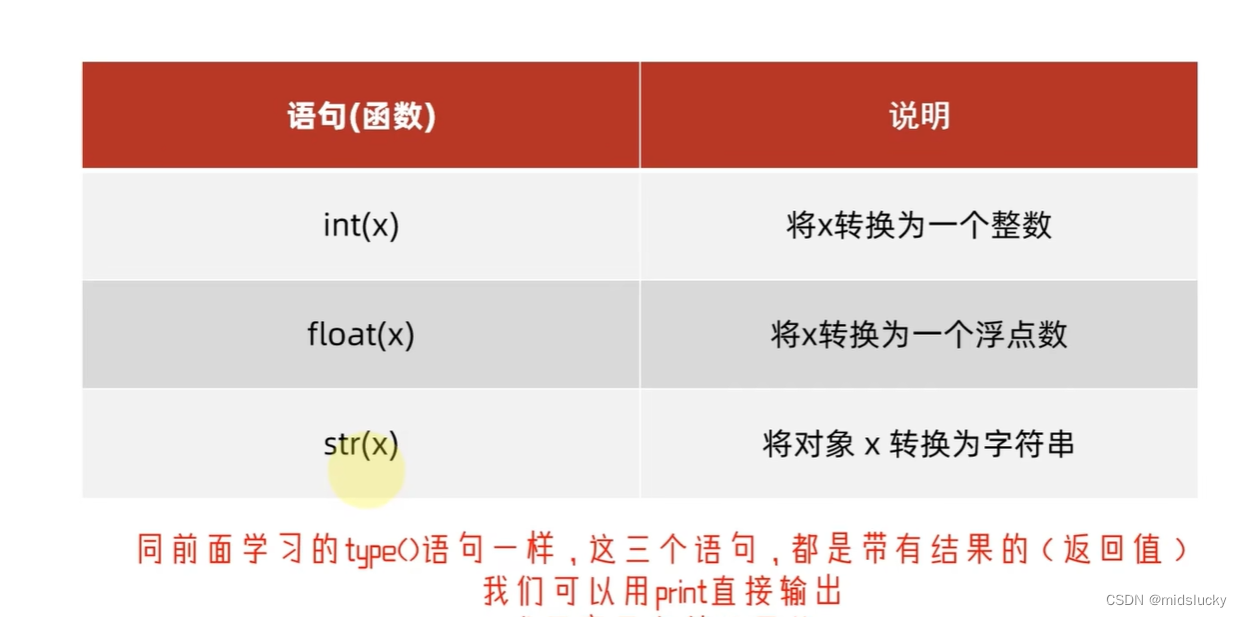

这里可以观察到即使num_str 内存储的111类型变了,但打印的时候其内容并没有发生变化。
浮点型转整形其小数会丢掉,丢失精度。
任何类型都可以转换成字符串,而字符串不能任意转换为数字(字符串内只有数字才行)
7.标识符
用户在编程的时候所使用的一系列名字,用于给变量,类,方法等命名。
内容限定:
命名时只允许出现
- 英文
- 中文 //不推荐中文
- 数字 //数字不可以用在开头
- 下划线(_)
大小写敏感:
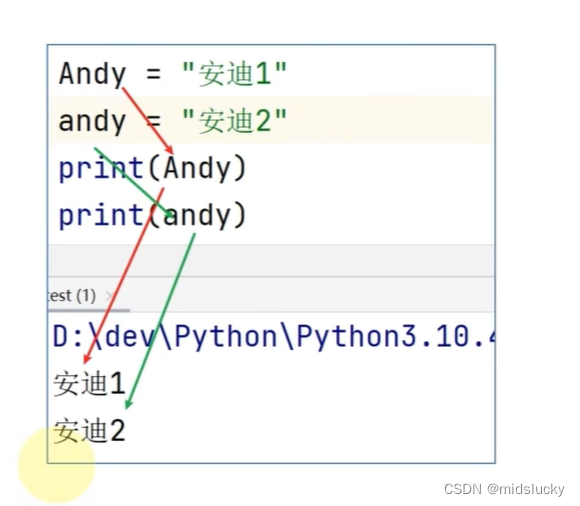
不可使用关键字(大小写要注意哦):

变量的命名规范:
- 见名知意
- 下划线命名法
- 英文字母全小写
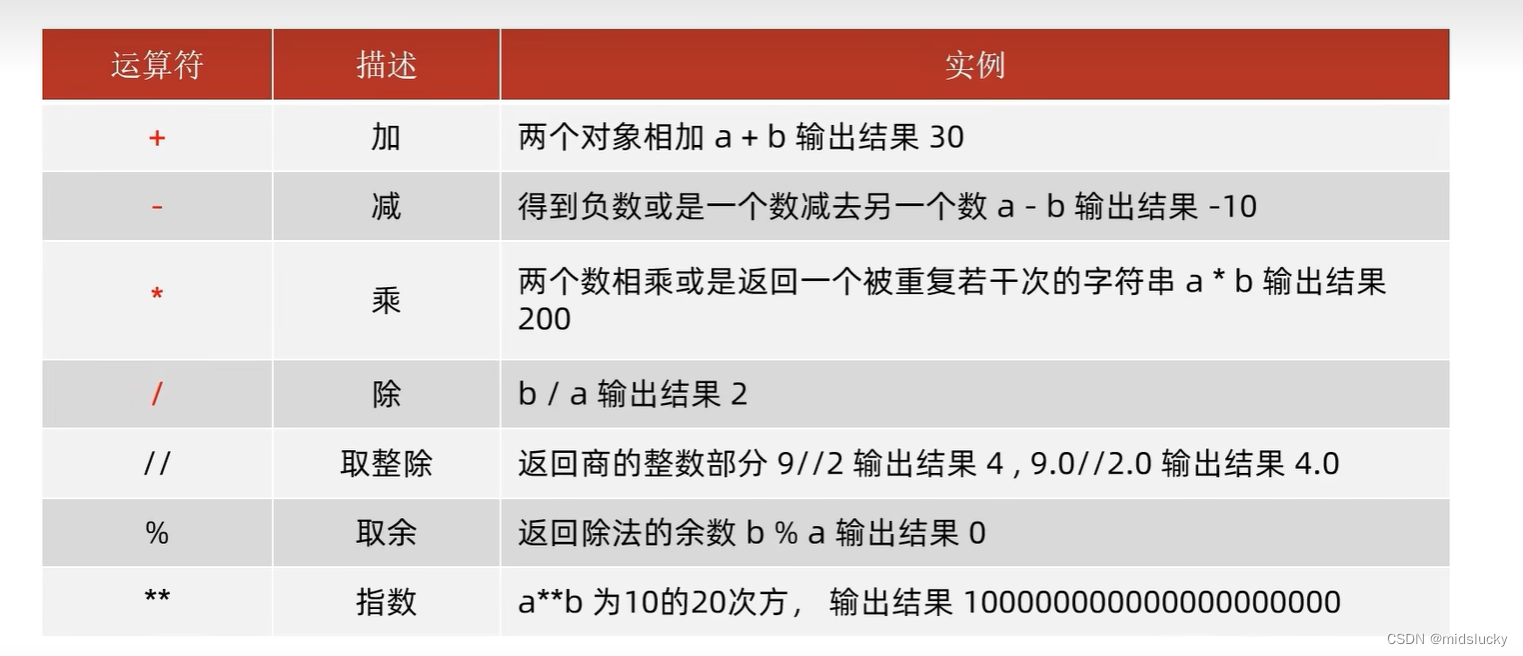
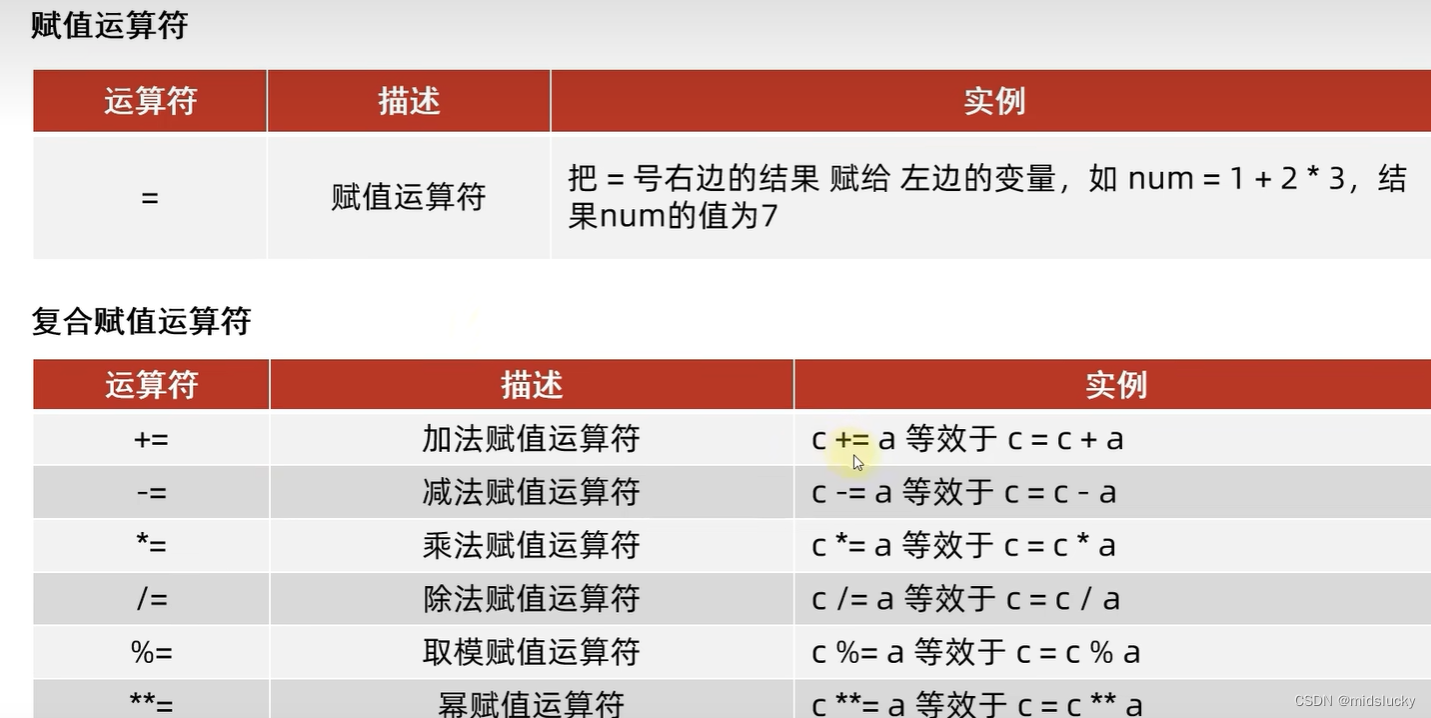
8.算数运算符
9.字符串
9.1字符串的定义

9.2转义字符

9.3字符串拼接

注意➕只能用于字符串和字符串之间的拼接,要是换成了其他类型的变量是拼接不了的。
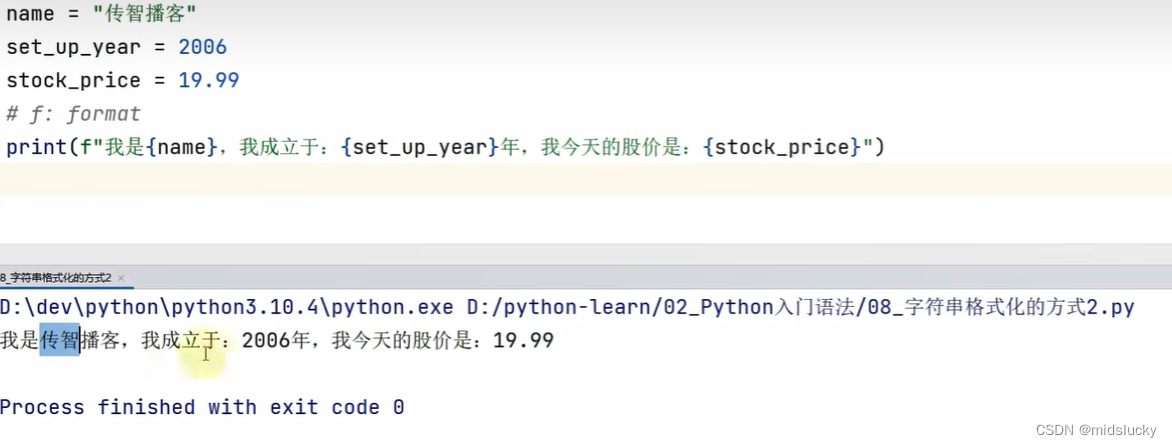
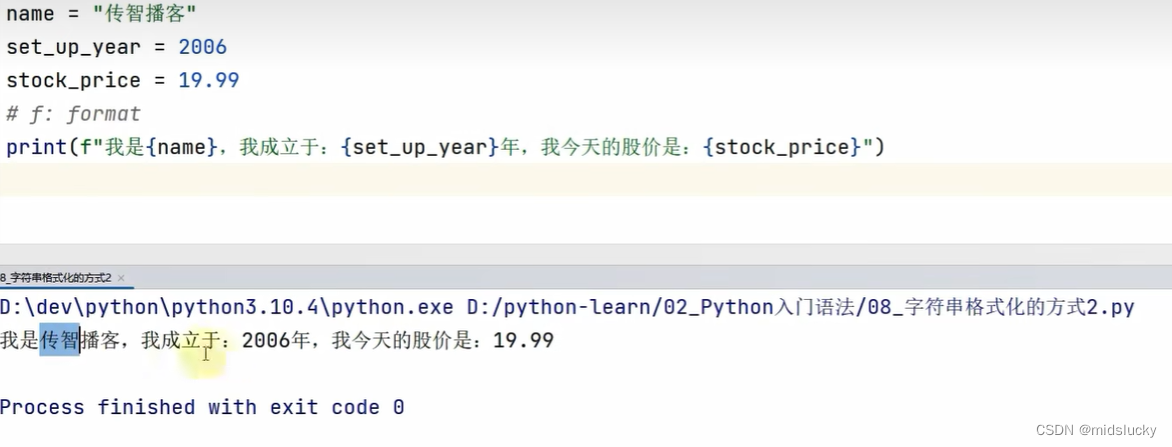
9.4字符串格式化
name = "小明"
message = "我叫:%s" %name #%表示占位符号,s表示所占位地方
print(message)
class_sum = 57
avg_salary = 16781
message2 = "据有关部门统计,上海%s期,毕业平局工资:%s" %(class_sum,avg_salary)#多个变量占位需要加括号并且用逗号隔开,还需安装指定顺序,其实这边因该用%d的%s也可以
print(message2)
print("字符串在python中的类型名是:%s" % type("字符串"))
占位符的介绍:
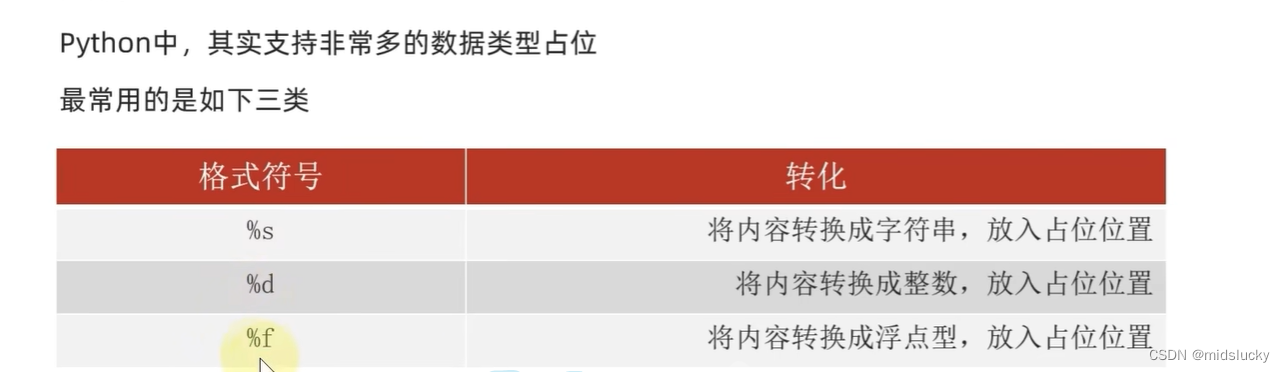
9.5格式化的精度控制

9.6快速占位
9.7input语句
input()实质上可以类比c语言中的scanf
观察一段如下代码:
print("请告诉我你是谁")
name = input()
print("我知道了,你是:%s" % name)
#等价于
name = input("请告诉我你是谁")
print("我知道了,你是:%s" % name)
(补充一点:无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型)
10.if语句
10.1布尔类型
True(1)
False(0)
(补充一点,py里的字符串比较(没c那么多讲究)会返回true,false,其他比较也是返回bool类型)
10.2if语句的各种用法
基本概念:

判断条件的结果一定要是布尔类型
判断条件后的冒号记得要加
归属于if语句的代码块,需要在前方填充4个空格缩进
10.3if elif else
直接上例子
height = int(input("请输入你的身高(cm):"))
vip_level = int(input("请输入你的vip等级(1-5):"))
day = int(input("请告诉我今天几号:"))
if height < 120:
print("身高小于120cm,可以免费。")
elif vip_leval > 3:
print("vip级别大于3,可以免费。")
elif day == 1:
print("今天是一号免费日,可以免费。")
else:
print("不好意思,条件都不满足,需要买票10元。")
(嵌套的话还是模仿c语言那一套就近原则)
11.while
11.1基础语法
i = 0
while i < 100:
print("我爱你,小静静")
i += 1
1.while的条件需得到布尔类型,True表示继续循坏,False表示结束循坏
2.需要设置循坏终止的条件,如i+=1 配合 i < 100,就能确保100此后停止,否则将无线循坏
3.空格缩进和if判断一样,都需要设置
11.2获取随机数
import random
num = random.randint(1,100)
12.for
12.1基础格式
#for临时变量in待处理数据集(也可称之为序列类型):
# 循环满足条件时执行的代码
#例子
name ="itheima"
#for循环处理字符串
# x = 'i' 也可以先在外面写个x 那么这样for循坏的作用就是一次次覆盖外面的这个x
for x in name:
print(x)
#运行效果如下
i
t
h
e
i
m
a
tips:
- 无法定义循环条件,只能被动取出数据处理
- 要注意,循坏内的语句,需要有空格缩进
- 在for循坏外部这个临时变量实际上是可以访问到的但是在编程规范上是不允许,不建议这么做的
12.2range语句
功能:获取数字序列
语法:
range(num)
获取一个从0开始,到num结束的数字序列(不含num本身)
如range(5)获取的数据是:[0,1,2,3,4]
range(num1 , num2)
例如:range(5,10) 获取的数据为:[5,6,7,8,9]
range(num1,num2,step)
获取一个从num1开始,到num2结束的数字序列(不含num2本身)
数字之间的步长,以step为准(step默认为1)
如,range(5,10,2)获得的数据是:[5,7,9]
12.3break continue
continue:中断所在循坏的当次执行,直接进入下一处
break:直接结束所在的循坏
其实和c语言中的用法没什么区别,这里就不过多说明了
13.函数
13.1基础格式
def 函数名(传入参数):
函数体
return 返回值
(return和传入参数可省略,return之后的语句不执行,如果不写return,会返回一个none)
13.2函数的传参
def add(x,y):
result = x + y
print(f"{x} + {y}的计算结果是:{result}")
add(5,6)
13.3函数的说明文档
其实本质就是采用多行注释对函数整体进行说明
13.4变量的作用域
定义在函数体内部的变量,只在函数体内部生效
在函数中设置global可以使函数内定义的局部变量变为全局变量
num = 100
def test_a()
global num
num = 500
print("运行成功")
print(num)
#可以看到num的值被修改成了500
14.数据容器
14.基本概念
一种可以容纳多分数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串,数字,布尔等。
14.1列表(list)
基本定义:
my_list = ['itheima',666,True]
print(my_list)
print(type(my_list))
#输出结果
['itheima',666,True]
<class 'list'>
#列表的嵌套定义
mt_list = [[1,2,3],[4,5,6]]
print(my_list)
print(type(my_list))
#输出结果
[[1,2,3],[4,5,6]]
<class 'list'>
下标索引:
正向(和数组下标一样从左到又从0到n)和反向(从右到左,从-1到-n)都能取
示例:
#正向
my_list = ["Tom","Lily","Rose"]
print(my_list[0])
print(my_list[1])
print(my_list[2])
#反向
print(mt_list[-1])
print(mt_list[-2])
print(mt_list[-3])
#反向输出结果为
ROSE
Lily
Tom
#嵌套存取
my_list = [[1,2,3],[4,5,6]]
print(my_list[1][1])
#此时输出结果为5
列表的方法:
mylist = ["itcast","itheima","python"]
#1.查找某元素在列表内的下标索引,如果该索引不存在会报错
index = mylist.index("itheima")
print(f"itheima在列表中的下标索引值是:{index}")#结果就是打印下标(正向的)
#2.修改特点小标索引值
mylist[0] = "教育行业"
#3.在指定下标位置插入元素
mylist.insert(1,"best")
#4.在列表的尾部追加单个元素
mylist.append("程序员")
#5.在列表的尾部追加一批新元素
mylist2 = [1,2,3]
mylist.extend(mylist2)
#6.删除指定下标索引的元素(2种方式)
mylist = ["itcast","itheima","python"]
del mylist[2] #把"python"删掉了
mylist = ["itcast","itheima","python"]
element = mylist.pop(2) #删掉了"python”,并将其附加给了element
#7.删除某元素在列表中的第一个匹配项
mylist = ["itcast","itheima","itcast","itheima","python"]
mylist.remove("itheima") #这里就从前往后搜索把第一个"itheima"删掉了
#8.清空列表
mylist.clear() #此时的mylist列表什么都没有了
#9.统计列表内某元素的数量
mylist = ["itcast","itheima","itcast","itheima","python"]
count = mylist.count("itheima") #count的值为2
#10.统计列表中元素有多少个(这个算是库函数的使用)
mylist = ["itcast","itheima","itcast","itheima","python"]
count = len(mylist) #count结果为5
#列表的循坏
my_list = [1,2,3,4,5]
for element in my_list: #for临时变量in数据容器
print(f"列表中的元素有:{element}")
14.2元组(tuple)
列表是可以修改的,但是元组定义了就不可被修改
格式:(元素1,元素2,元素3)
#定义元组
t1 = (1,"Hello",True)
t2 = ()
t3 = tuple()
#定义单个元素的元组
t4("hello",) #记得要加括号不然数据就不是元组类型了
#元组的嵌套
t5 = ((1,2,3),(4,5,6))
#下标索引取元组内数据
num = t5[1][2] #取6
#元组的相关方法
#index() 查找某个数据,如果数据存在,返回对应的下标,否则报错
#count() 统计某个数据在当前元组出现的次数
#len(元组)这里算库函数的使用,统计元组内的元素个数
#尝试修改元组内容的有趣例子(可以修改内部list的值)
t1 = (1,2,['itheima','itcast'])
t1[2][1] = 'best'
print(t1) #结果:(1,2,['itheima','best'])
14.3字符串(str)
本质一个字符对应一个下标。
字符串和元组一样是一个无法修改的数据容器,如果不得不修改,将得到一个新的字符串。
mt_Str = "itheima and itcast"
#通过下标索引取值
value = mt_str[2] #取到了“h”
#index方法
value = mt_str.index("and") #找的是起始下标为8,空格也算
#replace方法
new_my_str = my_str.replace("it","程序") #将所有的it全部替换成“程序”,并生成一个新的字符串
print(f"将字符串(mt_str),进行替换后得到:{new_my_str}")
#split方法
mt_str = "hello python itheima itcast"
my_str_list = my_str.split(" ")#my_str没变,生成了一个新的字符串,以空格切割得:'hello','python','itheima','itcast'
#strip方法 用法看最下面图片
#count方法 用法和上面的一样这边不做过多说明了
#统计字符串长度len() 空格也算

此处的空格包含’\n’, ‘\r’, ‘\t’, ’ ’
14.4序列容器的切片操作
序列支持切片,即:列表,元组,字符串,均支持进行切片操作
切片:从一个序列里,取出一个子序列

#对list进行切片,从1开始,4结束,步长1
mt_list = [0,1,2,3,4,5,6]
result1 = mt_list[1:4]# 步长默认为1,可以省略不写
print(f"结果1:{result1}")#打印结果为[1,2,3]
#对tuple进行切片,从头开始,到最后结束,步长为1
my_tuple = (0,1,2,3,4,5,6)
result2 = my_tuple[:] #起始和结束不写表示从头到尾,步长为1省略
print(f"结果2:{result2}") #打印为(0,1,2,3,4,5,6)
#对str进行切片,从头开始,到最后结束,步长2
my_str = "01234567"
result3 = mt_str[::2]
print(f"结果3:{result3}") #打印结果为0246
14.5集合(set)
特点:不支持元素重复(自带去重功能),并且内容无序,不支持下标索引访问,但是允许修改,其中元素不能是任意数据类型(不能是容器),所以一般无法嵌套
语法:变量名称 = {元素,元素,…,元素}
定义空集合:变量名称 = set()
{}是后面定义空字典的所以不能用
#定义一个集合
mt_set = {"你好","学习","你好"} #会自动去重
#添加新元素
my_set.add("python") #如果加入已有的照样去重
#移除元素
mt_set.remove("python")
#随机取出一个元素
element = my_set.pop() #因为无序,所以随机取,并把取出的值附给element
#清空集合
my_set.clear()
#取2个集合的差集 语法:集合1.difference(集合2) 功能:取出集合1有但集合2没有的
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2) #此时打印set3为{2,3}
#消除2个集合的差集 集合1.difference_update(集合2) 在集合1内,删除和集合2相同的元素 ,集合1被修改,集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2) #打印结果为 set1{2,3},set2{1,5,6}
#2集合合并 ,集合1,2合并组成新集合,1,2本身不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2) #set3{1,2,3,5,6}去重,顺序是不确定的其实
#统计集合元素数量
len(mt_set)
#集合的遍历
set1 = {1,2,3,4,5}
for element in set1:
print(element)
14.6字典(dictionary)
字典的定义,同样使用{},不过存储的元素是一个个的:键值对(key,value),key不能够重复如果重复了会自动去重
字典的Key和Value可以是任意类型数据(key不可为字典),那么就表明字典可以嵌套
基础语法示例:
#定义字典字面量
{key: value,key: value,......,key:value}
#定义字典变量
my_dict = {key: value,key: value, ......,ket:value}
#定义空字典
my_dict = {}
my_dict = dict()
基本功能演示:
#字典同集合一样,不能使用下标索引,但是字典可以通过key的值来取得对应的Value
stu_score = {"王力宏":99,"周杰伦":88,"林俊杰":77}
print(stu_score["王力宏"]) #结果99
print(stu_score["周杰伦"]) #结果88
print(stu_score["林俊杰"]) #结果77
#定义嵌套的字典
stu_score_dict =
{
"王力宏":{"语文":77,"数学":66,"英语":33},
"周杰伦":{"语文":87,"数学":86,"英语":53},
"林俊杰":{"语文":67,"数学":76,"英语":67}
}
score = stu_score_dict["周杰伦"]["语文"]
print(f"周杰伦的语文分数是:{score}") #得到周杰伦的语文成绩
字典的常用操作:
#新增元素,更新元素
stu_score = {"王力宏":99,"周杰伦":88,"林俊杰":77}
my_dict["张信哲"] = 66 #新增
my_dict["周杰伦"] = 33 #更新
#删除元素
score = my_dict.pop("周杰伦")#结果就是删掉了,取出了分数
#清空元素
my_dict.clear()
#获取全部的key
my_dict = {"王力宏":99,"周杰伦":88,"林俊杰":77}
keys = my_dict.key()
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{mt_dict[key]}")
for key in my_dict: #每一次循坏都是直接得到key
print(f"字典的key是:{key}")
print(f"字典的value是:{mt_dict[key]}")
#统计字典内的元素数量,len()函数
num = len(my_dict)
14.7总结
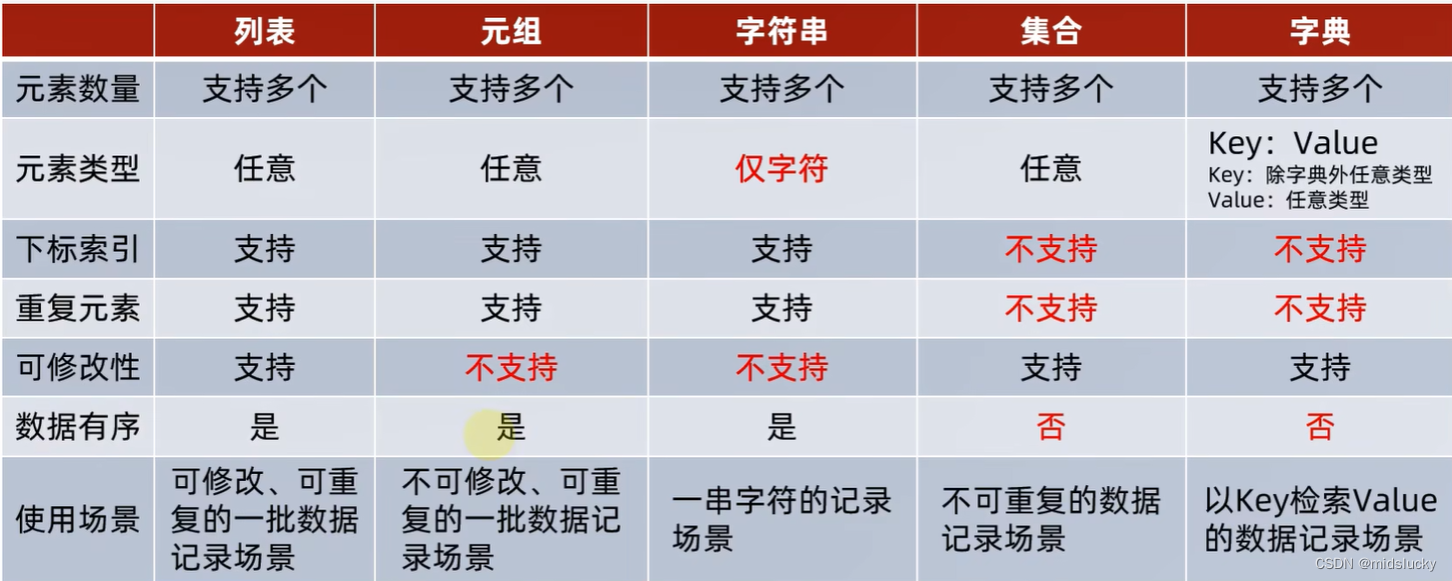
14.8通用操作总结
首先在遍历上:
- 5类数据容器都支持for循坏遍历
- 列表,元组。字符串都支持while循坏,集合,字典不支持(无法下标索引)
#定义出5类容器
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
mt_str = "abcdefg"
my_set = {1,2,3,4,5}
my_dict = {"key1": 1,"key2":2,"key3":3}
#len元素个数
print(len(my_list))
.....
#max最大元素
print(max(my_list))
......
#min最小元素
print(min(my_list))
......
#转列表 转元组 转字符串 转集合 字典转列表元组集合抛弃value,但是转字符串没问题, 字符串转列表元组集合,变成单个单个的如('a','b','c')
list(my_tuple)
tuple(my_list)
str(my_dict)
set(my_str)
.......
#进行容器的排序 字符串的比较和c那一套一样
sorted(my_list) #默认会从小变大排序,并将排序之后的结果放入list容器,字典对象的排序结果中丢失了value
sorted(my_list,reverse=True) #反向排序
15.函数进阶
15.1多个返回值
def test_return():
return 1,2,3 #也可以1,"hello",True l
x,y,z = test_return()
#实际结果就是x,y,z被赋值了1,2,3
15.2函数的多种传参方式
#按顺序传递(之前使用的基础传参方式)
#关键字传参
def user_info(name,age,gender):
print(name,age,gender)
user_info(name='小王',age=11,gender='女')
#缺省参数(默认值)
def user_info(name,age,gender='男'):
print(name,age,gender)
#不定长形式的传参
def user_info(*args): #实际为元组
print(args)
user_info(1,2,3,'小明','男孩')
def user_info(**kwargs): #实际为字典
print(kwarg)
user_info(name='小王',age=11,gender='男孩')
15.3函数作为参数传递
def test_func(compute):
result = compute(1,2)
print(result)
def compute(x,y):
return x+y
test_func(compute) #结果为3
15.4lambda匿名函数
#lambda 传入参数: 函数体(一行代码) #只能使用一次
test_func(lambda x,y:x+y)
16.文件操作
16.1open
作用:打开一个已经存在的文件,或者创建一个新文件
基础格式:open(name,mode,encoding)
name:是要打开的文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读,写入,追加等。
三种模式:r-只读(默认模式) w-只写(文件不存在则创建,原有内容会被删除) a-追加(文件不存在则创建)
encoding:编码格式(推荐使用UTF-8)
16.2read
read()方法:
文件对象.read(num)
num表示要从文件中读取的数据长度(单位为字节),如果没有传入num,那么就表示读取文件中的所有数据。
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f = open('python.txt') #省略了
content = f.readlines() #readlines不要和read这些在一起用是要主义,在文件读取的时候实质上是有个指针,会续接上一个读取的指针
print(count)
f.close()
readline()方法:一次读取一行内容
for line in f:
print{f"每一行的数据是{line}"}
16.3close(和大多数语言一样需要关闭)
with open("D:/测试.txt","r",encoding="UTF-8") as f: #打开一个文件后自动帮你写close
for line in f:
print(f"每一行的数据是:{line}")
16.4write
with open("D:/测试.txt","w",encoding="UTF-8")
f.write("Hello World") #内容写到内存中
f.flush() #flush刷新将内存中积攒的内容,写入到硬盘的文件中,如果不写,用了close也会帮你刷新到磁盘上
-
上述例子为’w’模式
-
w模式,文件不存在,会创建新文件
-
w模式,文件存在,会清空原有内容
-
文件追加模式将’w’换成’a’即可,也是用write写入
-
a模式,文件不存在会创建文件
-
a模式,文件存在会在最后,追加写入文件
正常文件一行行写入之后在最后都有一个\n,这时要处理这个换行符我们需要使用方法strip()
17.异常机制
17.1基本属性
检测到一个错误时,python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”,也就是我们说的BUG
基础语法:
#基本捕获语法
try:
可能发生错误的代码
except:
如果出现异常要执行的代码
#捕获指定的异常
try:
except NameError(异常类型) as e(异常的对象里面记录了异常的具体信息):
#捕获多个异常
try:
except(NameError,ZeroDivisionError) as e:
#捕获所有异常
try:
except Exception as e:
else:(没出现异常之后执行的,可以不写)
print("好高兴没有异常")
finally:(有没有异常都会执行,可写可不写)
17.2异常的传递性

17.3模块
实质就是一个以.py结尾的文件,里面有类,函数,变量等,我们可以通过导入模块来快捷使用
模块导入的基础语法:
import 模块名1,模块名2(单个也行)
#使用import导入time模块使用sleep功能
import time #这样的话time里面的功能都能用
print("你好")
time.sleep(5) #如果只用sleep功能,可以from time import sleep(这里sleep换成*就相当于导入全部的方法,采用from这种导入形式不需要带点,直接sleep()这么使用即可)(* 相当于all变量其值可以修改)
print("我好")
#模块取别名
improt time as t 或者 from time import sleep as sl
#此时t.sleep() = time.sleep sleep() = sl()
#if的特殊用法
if _ _name_ _ == '_ _main_ _': #;两者都是内置类型,默认值是一样的
test(1,2)
自定义模块也可以,本质就是写一个py文件,然后import 文件名就可以了
不同模块(.py文件名不一样),同名的功能(用from那种同名法),如果都被导入,那么后导入的会覆盖先导入的
17.4python的包
python相当于一个文件夹,里面有一堆的python模块和一个特殊文件_ init _.py的特殊文件
导入包: import 包名.模块名 如:import my_package.my_module1
使用from: from my_package import my_moudle1
18.面向对象基础
18.1类的最基本应用

18.2类的方法
#self关键字,尽管在参数列表中,但是传参的时候可以忽略它。类比c++当中的this指针
class Student:
name = None
def say_hi(self):
print("Hello 大家好") #在方法中需要访问成员变量需要self.name
def say_hi2(self,msg):
print(f"Hello 大家好,{msg}")
stu = Student()
stu.say_hi()
stu.say_hi2("很高兴认识大家")
18.3构造方法
#构建类时传入的参数会自动提供给__init__方法,构建类的时候__init__方法会自动执行
class Student:
name = None
age = None
tel = None
def __init__(self,name,age,tel):
self.name = name
self.age = age
self.tel = tel
print("Student类创建了一个类对象")
stu = Student("周杰伦",31,"18500006666")
18.3其他魔术方法(内置方法)
#__str__ 返回值:字符串,内容:自行定义
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return f"Student类对象,name = {self.name},age={self.age}"
student = Student("周杰伦",31)
print(student)#返回的是上面__str__的return内容
print(str(student))#返回的是上面__str__的return内容
#__lt__方法,传入参数:other(另一个类对象) 返回值:True or False 内容:自定义 (小于符号比较法,写了之后大于也能用了) (扩展__le__ 用于小于等于和大于等于的判断 ,__eq__ 为'=='符号比较)
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __lt__(self,other):
return self.age < other.age
stu1 = Student("周杰伦","11")
stu2 = Student("林俊杰",13)
print(stu1 < stu2) # 结果:True
print(stu1 > stu2) #结果:False
18.4封装

私有成员无法被类对象使用,但是可以被其他的成员使用(格式为以两个下划线作为开头)。
18.5继承
基础语法:
class 类名(父类名):
类内容体
#单继承
class Phone:
IMEI = None
producer = "HM"
def call_by_4g(self):
print("4g通话")
class Phone2022(Phone):
face_id = "10001"
def call_by_5g(self):
print("2022年新功能:5g通话")
#演示多继承
class NFCReader:
nfc_type = "第五代"
producer = "HM"
def read_card(self):
print("NFC读卡")
def write_card(self):
print("NFC写卡")
class RemoteControl:
rc_type = "红外遥控"
def control(self):
print("红外遥控开启了")
class MyPhone(Phone,MFCReader,RemoteControl):
pass #本生这里是空的,在这里目的就是占个位,让语法不报错
#这里注意一点如果有同名的成员变量和成员函数,看继承顺序谁先继承谁的优先级最高
18.6复写
子类继承父类的成员属性和成员方法后,如果对其”不满意“,那么可以进行复写。即:在子类中重新定义同名的属性或方法即可。
class Phone:
IMEI = None
producer = "ITCAST"
del call_by_5g(self):
print("父类的5g通话")
class MyPhone(Phone):
producer = "ITHEIMA" #复写父类属性
def call_by_5g(self):
print("子类的5g通话") #复写父类方法

18.7类型注解
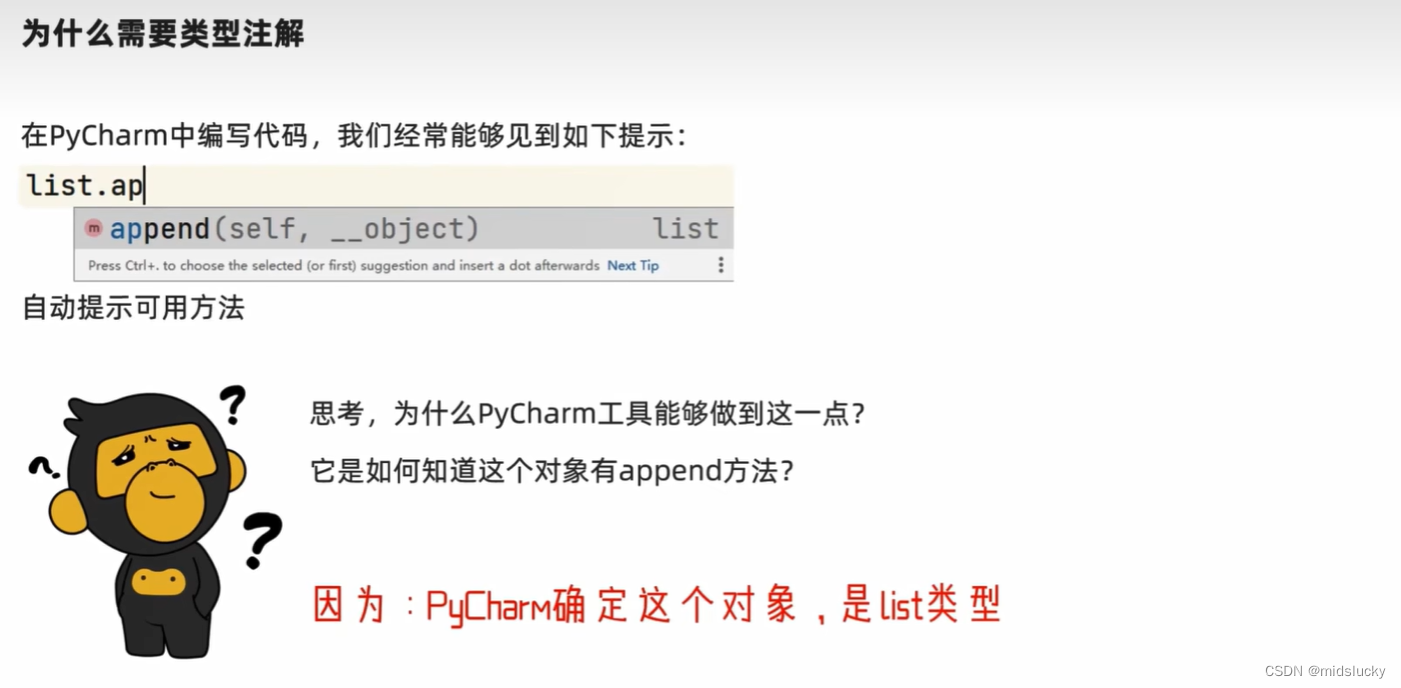

#基础类型注解
var_1: int = 10
var_2: str = "itheima"
var_3: bool = True
#类对象类型注解
class Student:
pass
stu: Student = Student()
#基础容器类型注解
my_list: list = [1,2,3]
#容器类型的详细注解
my_list:list[int] = [1,2,3]
#在注释中进行类型注解
var_2 = json.loads('{"name":"zhanhsan"}') #type:dict[str,str]
类型注解仅仅是个备注,只是个提示性的,并非决定性的。数据类型和注解列举无法对应也不会导致错误。
18.8函数和方法类型注解
#对形参进行类型注解
def add(x: int, y: int):
return x+y
#对返回值进行类型注解
def func(data: list) ->list:
return data
18.9 Union类型
#说明类型是个混合类型
from typing import Union
my_list:list[Union[int,str]] = [1,2,"itheima","itcast"]
def fun(data:Union[int,str]) -> Union[int,str]:
pass
18.10多态
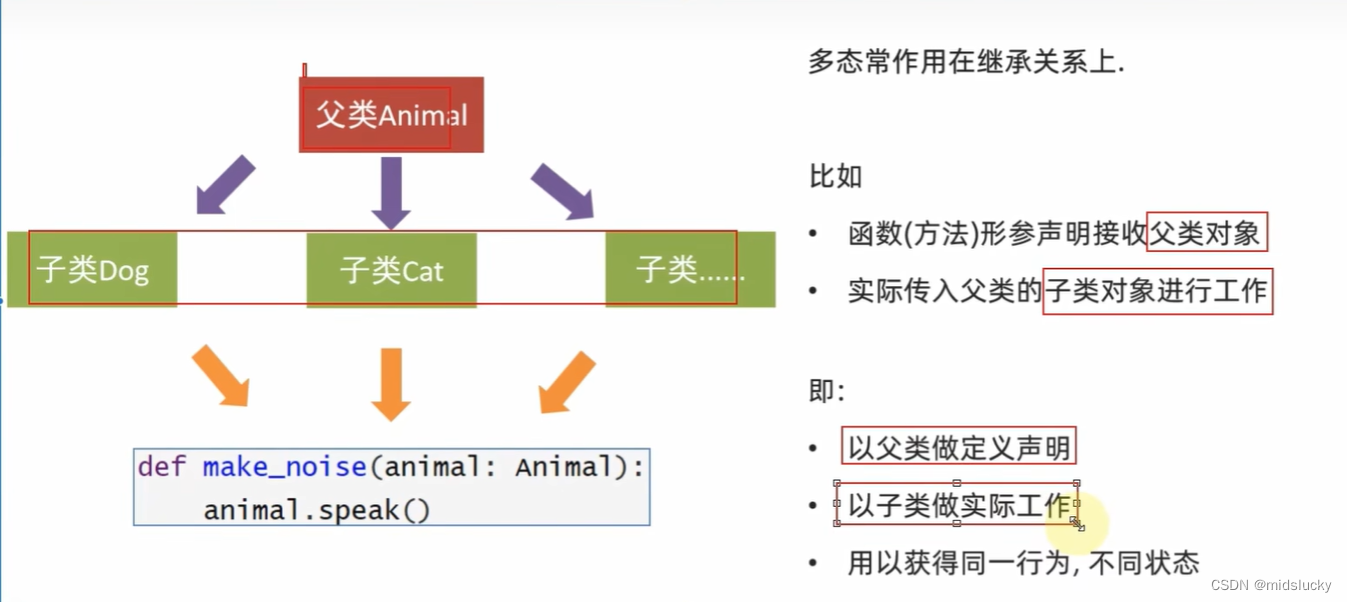
#实际案例
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal:Animal): #这是个类型注解
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog) #汪汪汪
make_noise(cat) #喵喵喵

抽象类的作用,多用于做顶层设计(设计标准),以便子类做具体实现。也是对子类的一种软性约束,要求子类必须复写(实现)父类的一些方法并配合工作使用,获得不同的工作状态。