本文主要说明perf和FrameGraph的使用,例如:火焰图的输出,系统性能状态查看等。
Author:mayimin
perf version 3.10.0-1160.80.1.el7.x86_64.debug
参考资料:perf example: https://www.brendangregg.com/perf.html
一、 Perf
perf 中包含工具众多,本文只说明其中一部分,如:perf bench、perf list、perf record、perf report、perf stat、perf top。
1. perf list
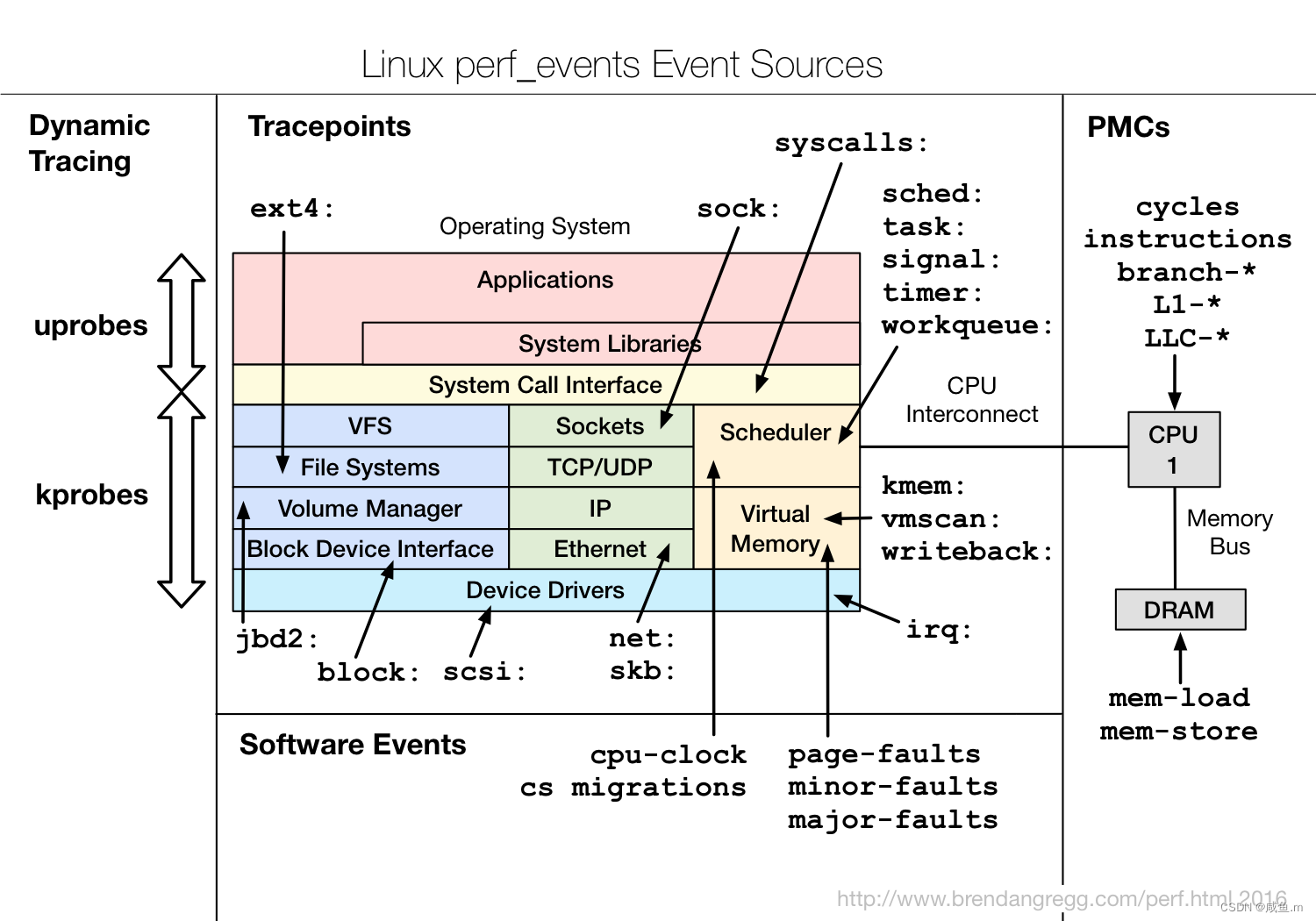
perf list不是实际的功能工具,主要是列出 perf 支持的事件,例如:cpu周期、总线周期等。
Usage: perf list [<options>] [hw|sw|cache|tracepoint|pmu|sdt|event_glob]
主要有以下几种事件:
hw:Hardware event,8个 # 硬件事件
sw:Software event,11个 # 软件事件
cache:Hardware cache event,20个 # 硬件缓存事件
tracepoint:Tracepoint event,2196个 # 跟踪点事件
下面看看每种事件中都有什么:
- 硬件
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event] # 分支指令
branch-misses [Hardware event] # 分支预测失败
// CPU 取指执行需要提前载入数据和指令,在流水线处理中硬件会有分支预测
bus-cycles [Hardware event] # 总线周期
cache-misses [Hardware event] # 缓存未命中
cache-references [Hardware event] # 缓存命中
cpu-cycles OR cycles [Hardware event] # CPU周期
instructions [Hardware event] # 指令
ref-cycles [Hardware event] # 参考周期
- 软件
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event] # 上下文切换
// CPU从在内核态和用户态切换,或者在进程间切换,引起的寄存器值的变化,称为上下文切换
cpu-clock [Software event] # cpu 时钟
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event] # 内存缺页
task-clock [Software event]
- 缓存
List of pre-defined events (to be used in -e):
L1-dcache-load-misses [Hardware cache event] # L1缓存未命中(数据寄存区)
L1-dcache-loads [Hardware cache event] # L1缓存命中(数据寄存区)
L1-dcache-stores [Hardware cache event] # L1 缓存写回命中
L1-icache-load-misses [Hardware cache event] # L1缓存未命中(指令寄存区)
LLC-load-misses [Hardware cache event] # 最后一级缓存未命中
LLC-loads [Hardware cache event] # 最后一级缓存命中
LLC-store-misses [Hardware cache event] # LLC缓存写回丢失
LLC-stores [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
iTLB-load-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
node-load-misses [Hardware cache event]
node-loads [Hardware cache event]
node-store-misses [Hardware cache event]
node-stores [Hardware cache event]
其中loads和stores分别代表预测和写回过程,一个是CPU要载入、一个是CPU要存储,i和d分别代表
instructions和data(指令和数据)
- 跟踪点
跟踪点事件中包含事件众多,主要是各个模块发生的一些事件
例如:alarmtimer:alarmtimer_fired 告警、ext4:ext4_error EXT4错误、huge_memory:mm_collapse_huge_page 折叠大页、ib_cma:icm_send_req ib发送请求等。
tracepoints是散落在内核源码中的一些hook,它们可以在特定的代码被执行到时触发,这一特定可以被各种trace/debug工具所使用。
这些tracepoint的对应的sysfs节点在/sys/kernel/debug/tracing/events目录下
List of pre-defined events (to be used in -e):
alarmtimer:alarmtimer_cancel [Tracepoint event] // 警告定时器取消事件
alarmtimer:alarmtimer_fired [Tracepoint event] // 警告
alarmtimer:alarmtimer_start [Tracepoint event] // 警告定时器开始开始
alarmtimer:alarmtimer_suspend [Tracepoint event]
avc:selinux_audited [Tracepoint event]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
......
跟踪点事件说明:
block: block device I/O
ext4: file system operations
kmem: kernel memory allocation events
random: kernel random number generator events
sched: CPU scheduler events
syscalls: system call enter and exits
task: task events
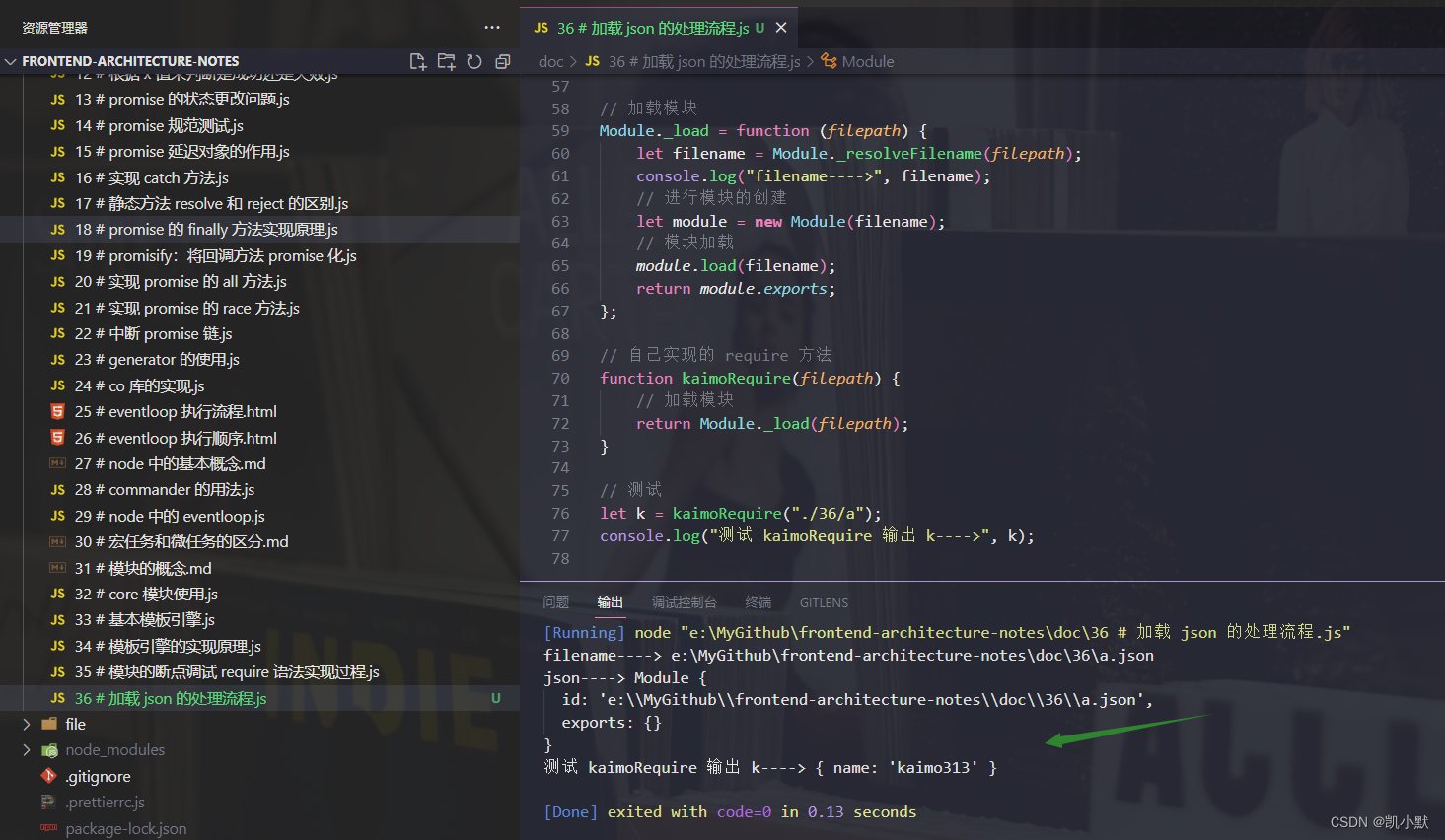
2. perf record
perf record为将性能数据存入数据文件
Usage: perf record [<options>] [<command>]
or: perf record [<options>] -- <command> [<options>]
-a, --all-cpus system-wide collection from all CPUs # 收集所有cpu数据
-c, --count <n> event period to sample # 采样使用的事件周期
-C, --cpu <cpu> list of cpus to monitor # 监控的CPU列表
-D, --delay <n> ms to wait before starting measurement after program start # 启动延迟
-e, --event <event> event selector. use 'perf list' to list available events # 采样使用的事件 perf list中的事件
-F, --freq <freq or 'max'> # 采样频率
profile at this frequency
-g enables call-graph recording # 使能调用图,显示函数调用关系
-o, --output <file> output file name # 输出文件名称
-p, --pid <pid> record events on existing process id # 采样进程的ID
-t, --tid <tid> record events on existing thread id
-T, --timestamp Record the sample timestamps
--call-graph <record_mode[,record_size]> # 启用函数调用图
setup and enables call-graph (stack chain/backtrace):
record_mode: call graph recording mode (fp|dwarf|lbr)
record_size: if record_mode is 'dwarf', max size of stack recording (<bytes>)
default: 8192 (bytes)
Default: fp
--dry-run Parse options then exit # 只解析命令
--exclude-perf don't record events from perf itself # 不记录perf自身数据
--filter <filter>
event filter
例子:
perf record -e cpu-clock -g -p 2548 # 记录进程2548 包括函数调用 使用CPU周期
perf record -F 99 -p PID --call-graph dwarf sleep 10 # 以99HZ采集数据 使用 dwarf (dbg info) 展开堆栈
perf record -e L1-dcache-load-misses -c 10000 -ag -- sleep 5 # 每10000次未命中采集一次
perf record -e 'sched:sched_process_*' -a sleep 5
perf record -F 99 -a --call-graph lbr
perf record -F 99 -a --call-graph dwarf # dwarf采集出来的数据量很大,调用显示详细
perf record -e block:block_rq_complete --filter 'nr_sector > 200' # Trace all block completions, of size at least 100 Kbytes, until Ctrl-C
perf record -e block:block_rq_complete --filter 'rwbs == "WS"' # Trace all block completions, synchronous writes only, until Ctrl-C
perf record -e block:block_rq_complete --filter 'rwbs ~ "*W*" # Trace all block completions, all types of writes, until Ctrl-C
3. perf report
perf report 为读取perf record记录的数据并展示
[root@t151 ~]# perf report -h
Usage: perf report [<options>]
-C, --cpu <cpu> list of cpus to profile # 解析的CPU列表
-f, --force don't complain, do it # 强制执行
-g, --call-graph <print_type,threshold[,print_limit],order,sort_key[,branch],value>
Display call graph (stack chain/backtrace):
print_type: call graph printing style (graph|flat|fractal|folded|none)
threshold: minimum call graph inclusion threshold (<percent>)
print_limit: maximum number of call graph entry (<number>)
order: call graph order (caller|callee)
sort_key: call graph sort key (function|address)
branch: include last branch info to call graph (branch)
value: call graph value (percent|period|count)
Default: graph,0.5,caller,function,percent
-n, --show-nr-samples
Show a column with the number of samples
-i, --input <file> input file name # 输入文件名
-I, --show-info Display extended information about perf.data file
-s, --sort <key[,key2...]> # 排序
sort by key(s): pid, comm, dso, symbol, parent, cpu, srcline, ... Please refer the man page for the complete list.
--pid <pid[,pid...]>
only consider symbols in these pids
例子:
perf report 相对简单,主要是显示记录的数据信息
perf report -i perf.data
perf report --stdio
perf report -n
Remark:
省略帧指针是默认设置
4. perf script
perf script 的功能是读取perf.data 然后显示trace输出
Usage: perf script [<options>]
or: perf script [<options>] record <script> [<record-options>] <command>
or: perf script [<options>] report <script> [script-args]
or: perf script [<options>] <script> [<record-options>] <command>
or: perf script [<options>] <top-script> [script-args]
-a, --all-cpus system-wide collection from all CPUs
-c, --comms <comm[,comm...]>
only display events for these comms # 只显示这些事件
-C, --cpu <cpu> list of cpus to profile
-d, --debug-mode do various checks like samples ordering and lost events
-D, --dump-raw-trace dump raw trace in ASCII
-F, --fields <str> comma separated output fields prepend with 'type:'. +field to add and -field to remove.Valid types: hw,sw,trace,raw,synth. Fields: comm,tid,pid,time,cpu,event
-f, --force don't complain, do it
-G, --hide-call-graph
When printing symbols do not display call chain
-i, --input <file> input file name # 输入文件
-I, --show-info display extended information from perf.data file
-L, --Latency show latency attributes (irqs/preemption disabled, etc)
-l, --list list available scripts
-s, --script <name> script file name (lang:script name, script name, or *)
-S, --symbols <symbol[,symbol...]>
only consider these symbols
-v, --verbose be more verbose (show symbol address, etc)
--header Show data header. # 显示数据头
--header-only Show only data header. # 只显示数据头
--inline Show inline function # 显示内联函数
--insn-trace[=...]
Decode instructions from itrace
--pid <pid[,pid...]>
only consider symbols in these pids # 选择进程
例子:
# List all events from perf.data: 显示perf.data中的所有事件
perf script
# List all perf.data events, with data header (newer kernels; was previously default):
perf script --header
# List all perf.data events, with my recommended fields (needs record -a; newer kernels):
perf script --header -F comm,pid,tid,cpu,time,event,ip,sym,dso
# List all perf.data events, with my recommended fields (needs record -a; older kernels):
perf script -f comm,pid,tid,cpu,time,event,ip,sym,dso
# 将perf.data转存为16进制 (for debugging):
perf script -D
5. perf stat
主要用于收集特定进程/命令的性能计数器统计信息
主要使用方法:
perf stat command # 统计command的信息
perf stat -d command # 显示细节信息 (includes extras)
perf stat -p PID # 统计PID进程的信息 until Ctrl-C
perf stat -a sleep 5 # 统计整个系统的信息 5s
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
# 统计整个系统的cycles,instructions,cache-references,cache-misses,bus-cycles 这些信息
例子:
perf stat gzip product/ # 收集gzip product/命令的性能信息
Performance counter stats for 'gzip product/':
0.79 msec task-clock # 0.514 CPUs utilized
0 context-switches # 0.000 K/sec # 上下文切换
0 cpu-migrations # 0.000 K/sec # cpu迁移
55 page-faults # 0.070 M/sec # 缺页错误
782,011 cycles # 0.990 GHz
802,591 instructions # 1.03 insn per cycle # 指令
165,338 branches # 209.223 M/sec # 分支预测
5,064 branch-misses # 3.06% of all branches # 分支预测错误
0.001537300 seconds time elapsed # 运行时间
0.000828000 seconds user # 用户态
0.000828000 seconds sys # 内核态
6. perf top
和linux的top类似,实时查看性能状况。
主要用法:
perf top -a -e cycles,instructions,cache-references,cache-misses,bus-cycles # 显示全局的cycles,instructions,cache-references,cache-misses,bus-cycles事件
perf top -p PID -d 2 -g graph # 显示PID信息,2s刷新一次,显示函数调用关系
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
例子:
Samples: 18K of event 'cycles:ppp', 4000 Hz, Event count (approx.): 3625879525 lost: 0/0 drop: 0/0
Overhead (CPU占用) Shared Object (DSO) Symbol(.代表用户态,k代表内核态)
5.88% libpython2.7.so.1.0 [.] PyEval_EvalFrameEx
2.32% perf [.] __symbols__insert
2.11% perf [.] rb_next
1.75% libpython2.7.so.1.0 [.] PyDict_Next
1.58% libpython2.7.so.1.0 [.] 0x0000000000114851
1.54% [kernel] [k] module_get_kallsym
1.41% libpython2.7.so.1.0 [.] 0x0000000000114899
1.14% libpython2.7.so.1.0 [.] 0x0000000000115410
1.11% libpython2.7.so.1.0 [.] _PyObject_GenericGetAttrWithDict
1.09% libpython2.7.so.1.0 [.] _PyType_Lookup
1.03% libpython2.7.so.1.0 [.] PyObject_Malloc
1.02% libpython2.7.so.1.0 [.] 0x0000000000114be0
0.97% libc-2.17.so [.] __GI_____strtoull_l_internal
0.93% [kernel] [k] kallsyms_expand_symbol.constprop.2
0.88% libc-2.17.so [.] __memcpy_ssse3_back
0.87% libpython2.7.so.1.0 [.] 0x00000000000806b2
0.85% libc-2.17.so [.] _int_malloc
0.84% libpython2.7.so.1.0 [.] PyParser_AddToken
0.80% perf [.] rb_insert_color
7. perf bench
perf 的性能基准测试
主要使用方法:
perf bench sched # 调度器测试 (调度和进程间pipe())
perf bench mem # 内存测试( memset()和memcpy())
perf bench numa # numa 测试 (测试内存remote、local、cross的RAM带宽、线程运行时间等)
perf bench futex # Futex压力测试
# futex 全称为Fast User-space Mutex
8. 其他
perf lock分析锁性能;
perf mem分析内存slab性能;

![[CKA]考试之备份还原 etcd](https://img-blog.csdnimg.cn/0bbe0ce002c64fe482fbb023b5b488e6.png)