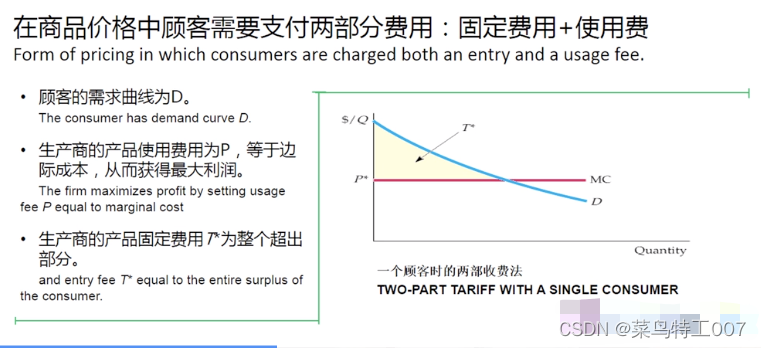
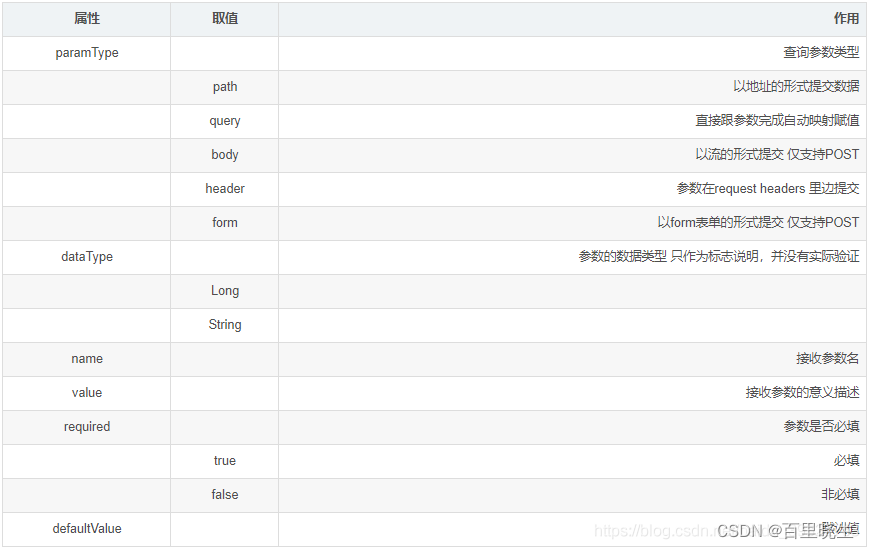
在阅读关于UTF8变长编码的文档时,看到如下内容,
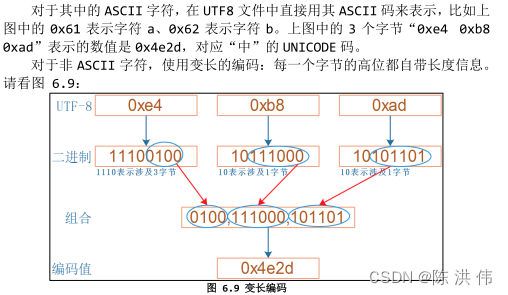

文档中1110表示涉及3个字节,10表示涉及一个字节,还有后面的1110高位有三个1,表示从当前字节起有3字节参与表示UNICODE,后面的高位有1个1,表示从当前字节起有1字节参与表示UNICODE,这什么意思,其实应该按照下面的意思理解,尤其是下面的红色加粗部分:
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
因此UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去那些控制位(每字节开头的10等),这些x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。
实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。
因此那些基本ASCII字符集中的字符(UNICODE兼容ASCII)只需要一个字节的UTF-8编码(7个二进制位)便可以表示。