量化投资 现代投资组合理论(MPT)
问题:构建投资组合,达到目标收益率的同时拥有最小的 risk exposure.
-
有 J J J 个可交易证券,期望收益率为 R = [ R 1 , ⋯ , R j ] T R=[R_1,\,\cdots,\,R_j]^T R=[R1,⋯,Rj]T,无风险利率为 R f R^f Rf ;
-
令 μ ∈ R J \mu\in \mathbb{R}^J μ∈RJ 为期望收益率, Σ \Sigma Σ 为期望收益率的协方差矩阵;
-
投资组合 θ = [ θ 1 , ⋯ , θ J ] J \theta=[\theta_1,\,\cdots,\,\theta_J]^J θ=[θ1,⋯,θJ]J ,满足 θ T e = 1 \theta^Te=1 θTe=1 , θ i \theta_i θi 代表投资于第 j j j 个证券的资产比例;
-
投资组合 θ \theta θ 的期望收益率为: μ [ θ ] = R θ = R f + θ T ( μ − R f e ) \mu[\theta]=R^{\theta}=R^f+\theta^T(\mu-R^fe) μ[θ]=Rθ=Rf+θT(μ−Rfe) ,标准差为 σ [ θ ] = ( θ T Σ θ ) 1 2 \sigma[\theta]=(\theta^T\Sigma\theta)^{\frac{1}{2}} σ[θ]=(θTΣθ)21 ;
-
不同投资组合之间的协方差为: σ [ θ , θ ′ ] = θ T Σ θ ′ \sigma[\theta,\,\theta']=\theta^T\Sigma\theta' σ[θ,θ′]=θTΣθ′ ;
有效投资组合 Efficient Portfolio:投资组合
θ
0
\theta_0
θ0 在
μ
0
\mu_0
μ0 处是 mean-variance efficient,若
θ
0
\theta_0
θ0 的期望收益为
μ
0
\mu_0
μ0 ,并且不存在其他达到同样期望收益率且拥有更小方差的投资组合。即:
θ
0
∈
arg
min
{
σ
2
[
θ
]
∣
μ
[
θ
]
=
μ
0
}
\theta_0 \in \arg \min\{\sigma^2[\theta]\,|\,\mu[\theta]=\mu_0\}
θ0∈argmin{σ2[θ]∣μ[θ]=μ0}
该问题可以写成最优化问题:
θ
0
=
arg
min
{
1
2
θ
0
T
Σ
θ
0
:
θ
T
μ
=
μ
0
and
θ
T
e
=
1
}
\theta_0=\arg \min\{\frac{1}{2}\theta_0^T\Sigma\theta_0:\,\theta^T\mu=\mu_0\text{ and }\theta^Te=1\}
θ0=argmin{21θ0TΣθ0:θTμ=μ0 and θTe=1}
其中的
1
2
\frac{1}{2}
21 是为了便于求导。构建 Lagrangian:
L
=
1
2
θ
T
Σ
θ
+
λ
1
(
θ
T
μ
−
μ
0
)
+
λ
2
(
θ
T
e
−
1
)
L=\frac{1}{2}\theta^T\Sigma\theta+\lambda_1(\theta^T\mu-\mu_0)+\lambda_2(\theta^Te-1)
L=21θTΣθ+λ1(θTμ−μ0)+λ2(θTe−1)
得到 FOC 为:
{
Σ
θ
+
λ
1
μ
+
λ
2
e
=
0
θ
T
μ
=
μ
0
θ
T
e
=
1
\left\{ \begin{array}{l} \Sigma\theta+\lambda_1\mu+\lambda_2e=0 \\ \theta^T\mu=\mu_0 \\ \theta^Te=1 \end{array} \right.
⎩
⎨
⎧Σθ+λ1μ+λ2e=0θTμ=μ0θTe=1
由第一个式子,我们可以得到:
θ
=
−
Σ
−
1
[
μ
,
e
]
[
λ
1
λ
2
]
\theta=-\Sigma^{-1}[\mu,\,e]\begin{bmatrix} \lambda_1 \\ \lambda_2 \end{bmatrix}
θ=−Σ−1[μ,e][λ1λ2]
由第二个式子,我们可以得到:
[
μ
,
e
]
T
θ
=
[
μ
0
1
]
[\mu,\,e]^T\theta=\begin{bmatrix} \mu_0 \\ 1 \end{bmatrix}
[μ,e]Tθ=[μ01]
两个式子联立得到:
−
[
μ
,
e
]
T
Σ
−
1
[
μ
,
e
]
[
λ
1
λ
2
]
=
[
μ
0
1
]
-[\mu,\,e]^T\Sigma^{-1}[\mu,\,e]\begin{bmatrix} \lambda_1 \\ \lambda_2 \end{bmatrix}=\begin{bmatrix} \mu_0 \\ 1 \end{bmatrix}
−[μ,e]TΣ−1[μ,e][λ1λ2]=[μ01]
令
A
=
[
μ
,
e
]
T
Σ
−
1
[
μ
,
e
]
A=[\mu,\,e]^T\Sigma^{-1}[\mu,\,e]
A=[μ,e]TΣ−1[μ,e] (
A
A
A 是一个
2
×
2
2\times 2
2×2 的方阵),则:
[
λ
1
λ
2
]
=
−
A
−
1
[
μ
0
1
]
\begin{bmatrix} \lambda_1 \\ \lambda_2 \end{bmatrix}=-A^{-1}\begin{bmatrix} \mu_0 \\ 1 \end{bmatrix}
[λ1λ2]=−A−1[μ01]
再代回去,得到:
θ
=
Σ
−
1
[
μ
,
e
]
A
−
1
[
μ
0
,
1
]
\theta=\Sigma^{-1}[\mu,\,e]A^{-1}[\mu_0,\,1]
θ=Σ−1[μ,e]A−1[μ0,1]
方差为:
σ
0
2
=
θ
T
Σ
θ
=
[
μ
0
,
1
]
A
−
1
[
μ
0
,
1
]
T
\sigma_0^2=\theta^T\Sigma\theta=[\mu_0,\,1]A^{-1}[\mu_0,\,1]^T
σ02=θTΣθ=[μ0,1]A−1[μ0,1]T
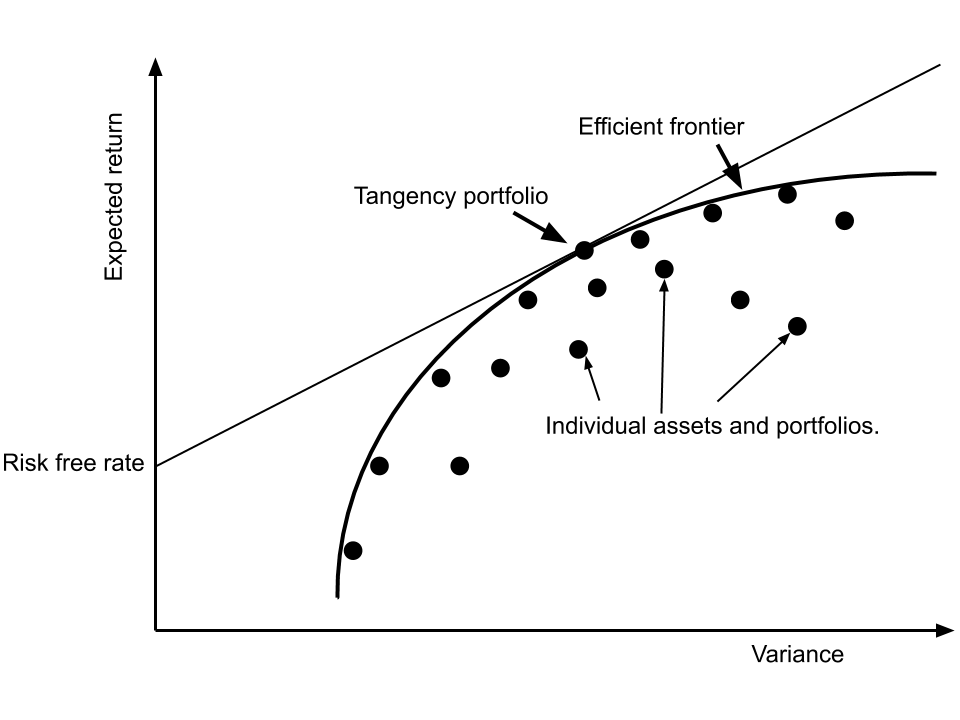
Markowitz’s MV Efficient Frontier:将上述解析解画出图像,可以得到:
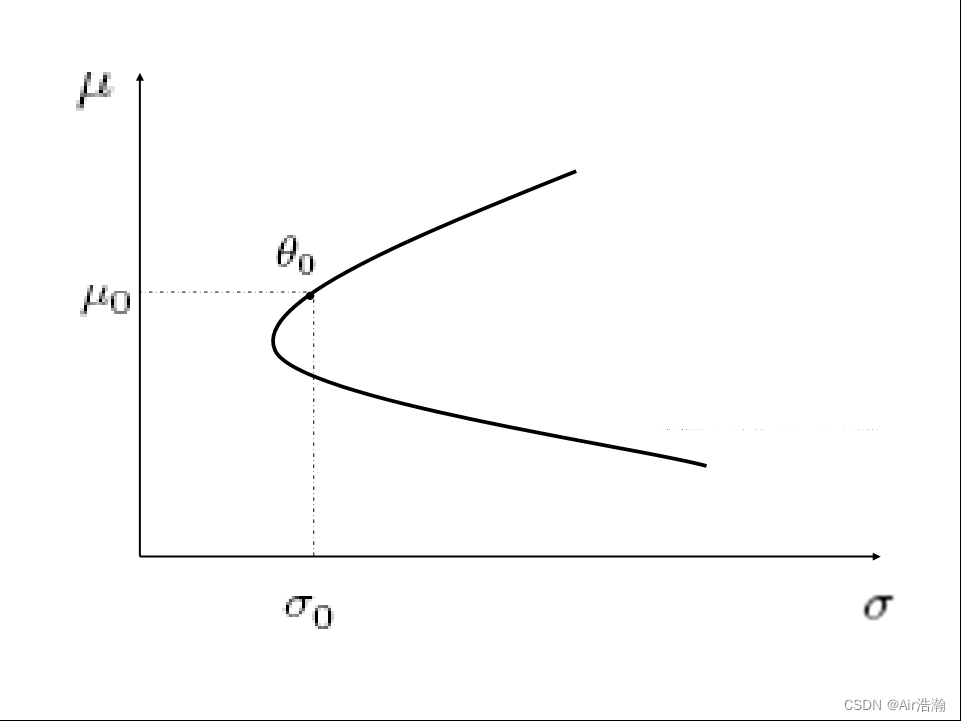
最小方差投资组合:从图像中可以看出,投资组合中具有将
σ
\sigma
σ 最小化的点,对应的最优化问题为:
min
θ
T
Σ
θ
s
.
t
.
θ
T
e
=
1
\min \theta^T\Sigma\theta \quad s.t.\,\,\,\theta^Te=1
minθTΣθs.t.θTe=1
Lagrangian 为:
L
(
θ
;
λ
)
=
θ
T
Σ
θ
+
λ
(
1
−
θ
T
e
)
L(\theta;\,\lambda)=\theta^T\Sigma\theta+\lambda(1-\theta^T e)
L(θ;λ)=θTΣθ+λ(1−θTe)
FOC 为:
{
∂
L
∂
θ
=
2
Σ
θ
−
λ
e
=
0
∂
L
∂
λ
=
1
−
∑
i
=
1
n
θ
i
=
0
\left\{ \begin{array}{l} \frac{\partial L}{\partial \theta}=2\Sigma\theta-\lambda e=0 \\ \frac{\partial L}{\partial \lambda}=1-\sum\limits_{i=1}^n\theta_i=0 \end{array} \right.
⎩
⎨
⎧∂θ∂L=2Σθ−λe=0∂λ∂L=1−i=1∑nθi=0
解得:
{
θ
‾
=
Σ
−
1
e
e
T
Σ
−
1
e
λ
=
2
e
T
Σ
−
1
e
\left\{ \begin{array}{l} \underline{\theta} = \frac{\Sigma^{-1}e}{e^T\Sigma^{-1}e} \\ \lambda = \frac{2}{{e^T\Sigma^{-1}e}} \end{array} \right.
{θ=eTΣ−1eΣ−1eλ=eTΣ−1e2
即最小方差和最小方差对应的期望收益率为:
μ
‾
=
μ
T
θ
‾
=
μ
T
Σ
−
1
e
e
T
Σ
−
1
e
σ
‾
2
=
θ
‾
T
Σ
θ
‾
=
e
T
Σ
−
1
T
e
(
e
T
Σ
−
1
e
)
2
\begin{aligned} \underline{\mu}=&\,\mu^T\underline{\theta}=\frac{\mu^T\Sigma^{-1}e}{e^T\Sigma^{-1}e} \\ \underline{\sigma}^2=&\,\underline{\theta}^T\Sigma\underline{\theta}=\frac{e^T\Sigma^{-1T}e}{(e^T\Sigma^{-1}e)^2} \end{aligned}
μ=σ2=μTθ=eTΣ−1eμTΣ−1eθTΣθ=(eTΣ−1e)2eTΣ−1Te
最大夏普率投资组合:以纵坐标上一点
(
0
,
R
f
)
(0,\,R^f)
(0,Rf) 向 frontier 做上切线,可以知道切点对应的投资组合是曲线上夏普率最大的投资组合(称为 tangency portfolio),对应最优化问题为:
max
θ
T
μ
−
R
f
(
θ
T
Σ
θ
)
1
2
s.t.
θ
T
e
=
1
\max \frac{\theta^T \mu-R_f}{(\theta^T\Sigma\theta)^{\frac{1}{2}}}\quad \text{s.t.}\,\,\theta^Te=1
max(θTΣθ)21θTμ−Rfs.t.θTe=1
Lagrangian 为:
L
(
θ
;
λ
)
=
(
θ
T
μ
−
R
f
)
(
θ
T
Σ
θ
)
−
1
2
+
λ
(
1
−
θ
T
e
)
L(\theta;\,\lambda)=(\theta^T \mu-R_f)(\theta^T\Sigma\theta)^{-\frac{1}{2}}+\lambda(1-\theta^Te)
L(θ;λ)=(θTμ−Rf)(θTΣθ)−21+λ(1−θTe)
FOC 为:
{
∂
L
∂
θ
=
μ
(
θ
T
Σ
θ
)
−
1
2
−
(
θ
T
μ
−
R
f
)
(
θ
T
Σ
θ
)
−
3
2
Σ
θ
−
λ
e
=
0
∂
L
∂
λ
=
1
−
θ
T
e
=
0
\left\{ \begin{array}{l} \frac{\partial L}{\partial \theta}=\mu(\theta^T\Sigma\theta)^{-\frac{1}{2}}-(\theta^T \mu-R_f)(\theta^T\Sigma\theta)^{-\frac{3}{2}}\Sigma\theta-\lambda e=0 \\ \frac{\partial L}{\partial \lambda}=1-\theta^Te=0 \end{array} \right.
{∂θ∂L=μ(θTΣθ)−21−(θTμ−Rf)(θTΣθ)−23Σθ−λe=0∂λ∂L=1−θTe=0
解得(这个没解出来。。。看的答案):
{
θ
T
=
Σ
−
1
(
μ
−
R
f
e
)
e
T
Σ
−
1
(
μ
−
R
f
e
)
λ
=
R
f
(
θ
T
T
Σ
θ
T
)
−
1
\left\{ \begin{array}{l} \theta_T= \frac{\Sigma^{-1}(\mu-R_fe)}{e^T\Sigma^{-1}(\mu-R_fe)} \\ \lambda = R_f(\theta_T^T\Sigma\theta_T)^{-1} \end{array} \right.
{θT=eTΣ−1(μ−Rfe)Σ−1(μ−Rfe)λ=Rf(θTTΣθT)−1