缺陷先关的智能检测应用和深度学习的结合是具有非常不错的应用前景的,比如:PCB缺陷检测、布匹瑕疵缺陷检测、瓷砖缺陷检测等等,在我之前的博文中对于缺陷领域相关的实践也有不少的项目开发实践,感性却的话可以自行移步阅读即可。
本文的核心目的就是想要对比分析不同精度系列的模型对于钢铁缺陷检测的性能差异,首先看下效果图:
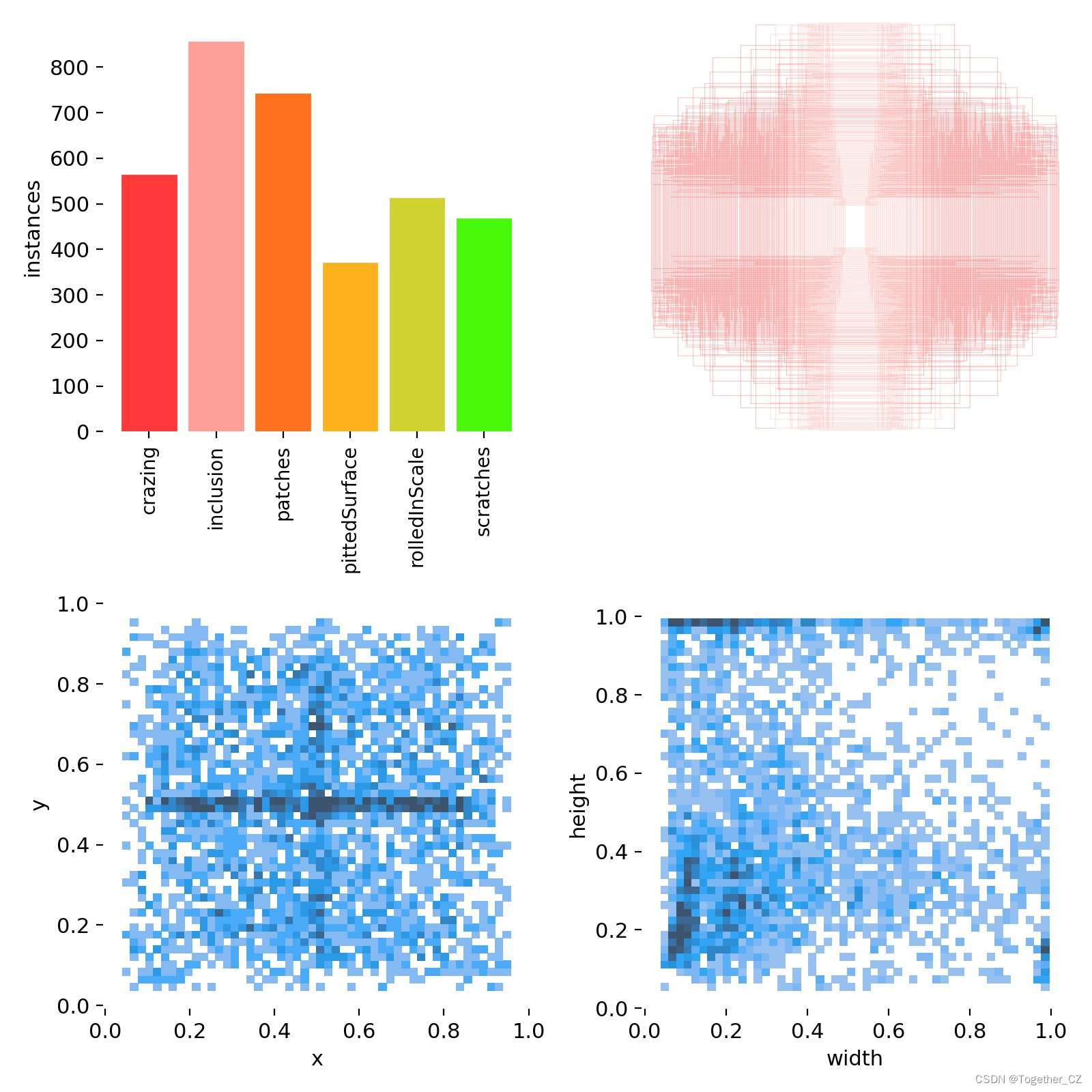
简单看下数据集:

这里使用到的是东北大学开源的热轧钢缺陷数据集。
数据集中共包含了6种不同类型的缺陷数据。
详情数据配置如下所示:
# Dataset
path: ./dataset
train:
- images/train
val:
- images/test
test:
- images/test
# Classes
names:
0: crazing
1: inclusion
2: patches
3: pittedSurface
4: rolledInScale
5: scratches模型的话这里分别使用了n/s/m三款不同精度系列的模型来完成模型的开发工作。
默认都是100次epoch的迭代计算,接下来看下结果详情:
【n系列】
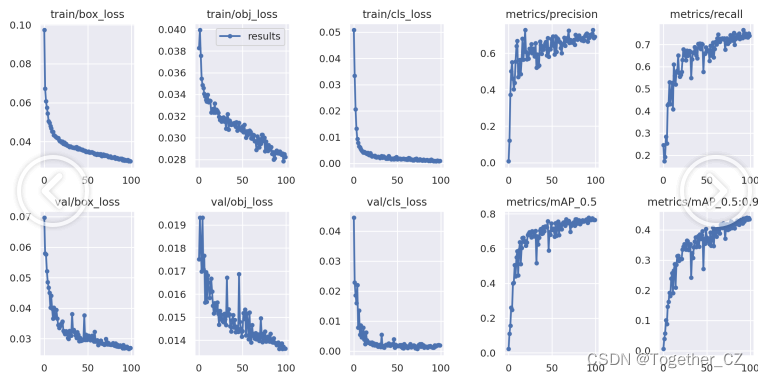

【s系列】



【m系列】

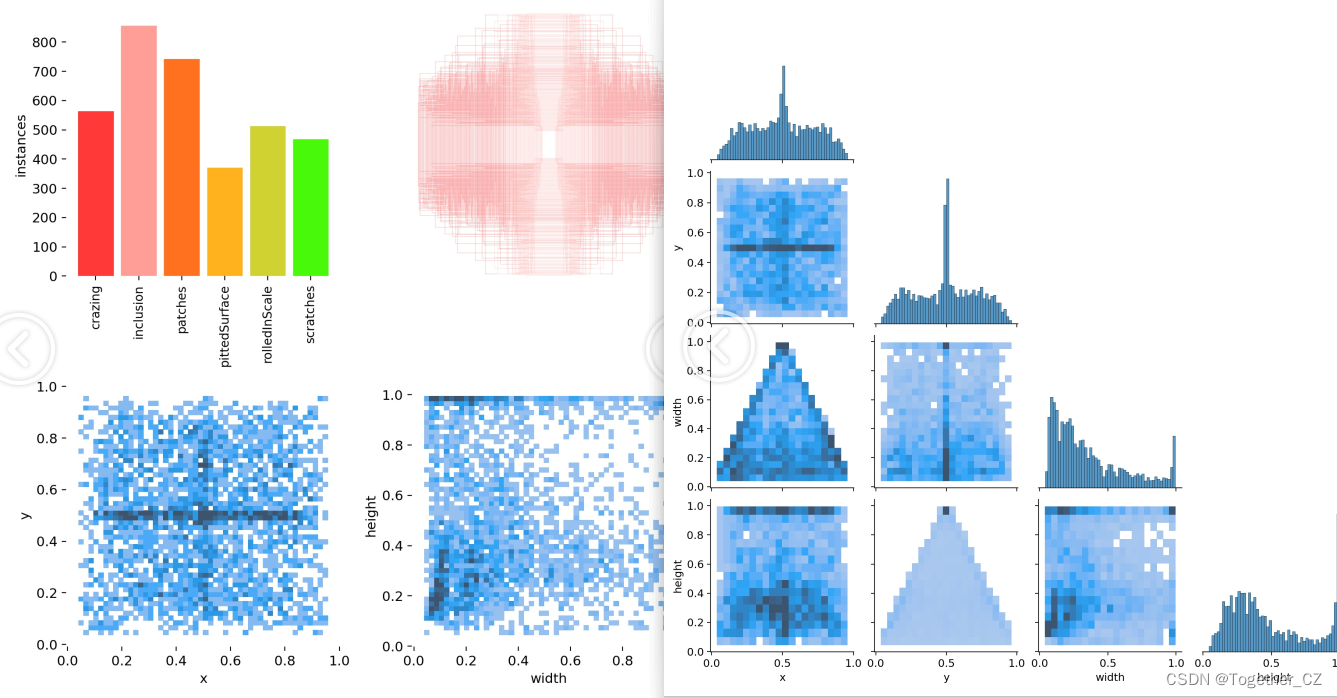

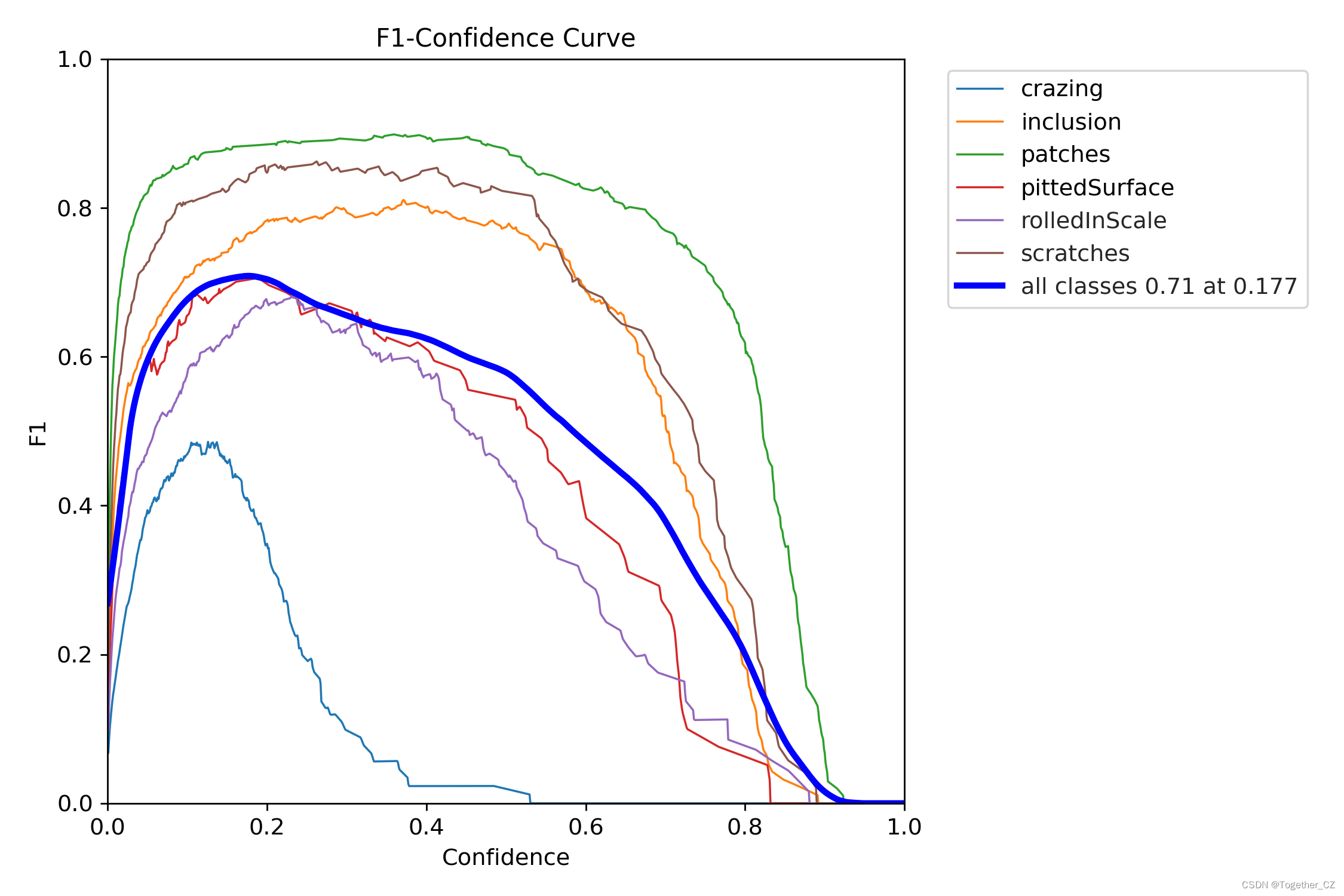
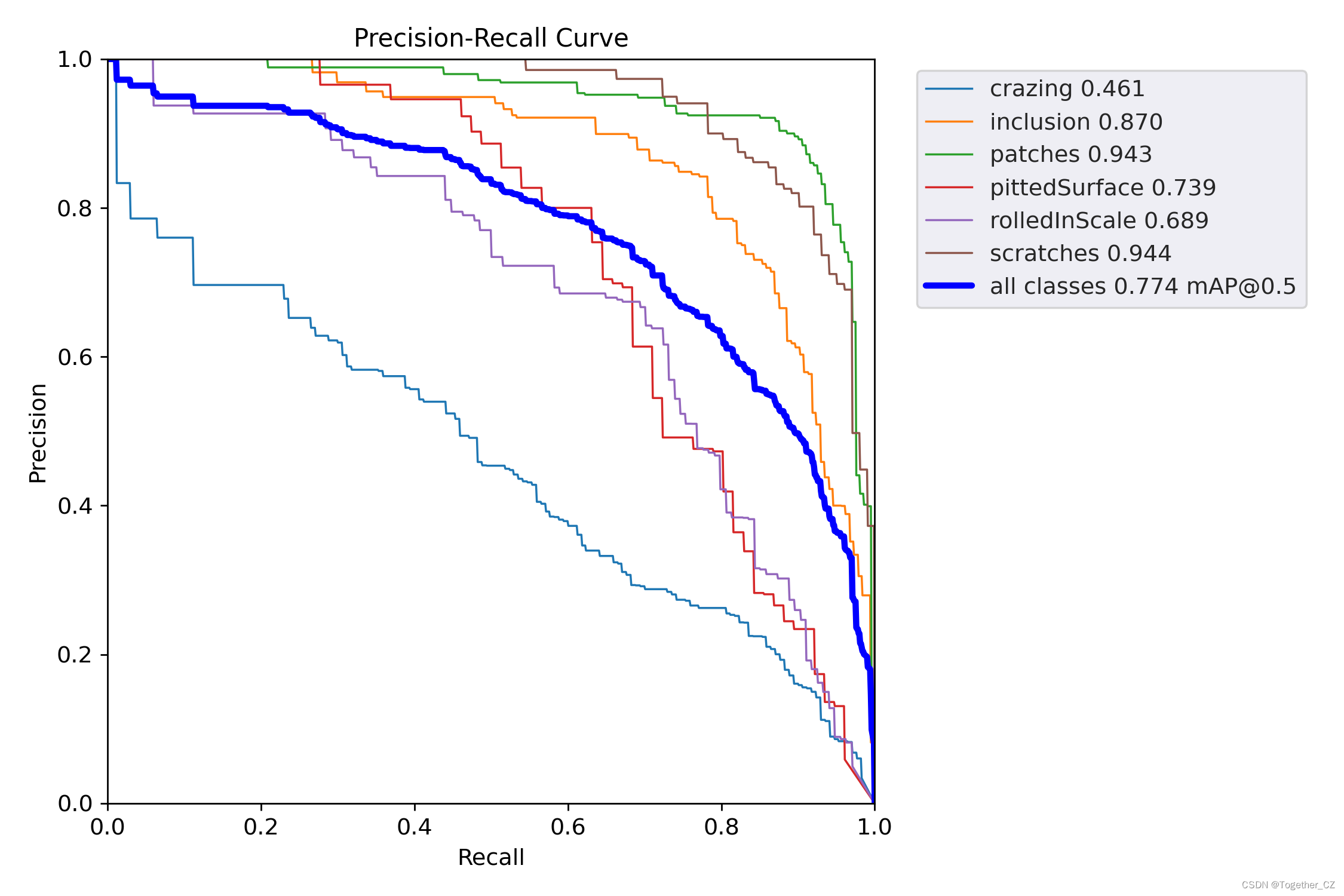
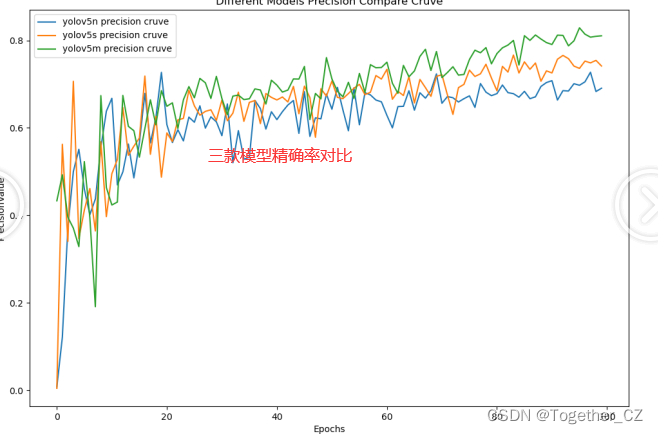
为了整体综合来对三款模型进行对比分析,这里对其进行综合对比可视化如下所示:
首先是精确率:
精确率(Precision)是一个用于衡量分类模型性能的指标,特别用于二分类问题。它衡量了模型预测为正例的样本中有多少是真正的正例。精确率可以用以下公式表示:
精确率 = 真正的正例数 / (真正的正例数 + 假正例数)
其中,真正的正例数是模型正确预测为正例且实际为正例的样本数,假正例数是模型错误预测为正例但实际为负例的样本数。
精确率的取值范围在0到1之间,数值越高表示模型的分类结果中真正的正例比例越高,即模型在将负例误判为正例的情况下更少。
接下来是召回率:
召回率(Recall),也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate),是用于衡量分类模型性能的指标,特别用于二分类问题。它衡量了模型能够正确识别出所有真正正例样本的能力。召回率可以用以下公式表示:
召回率 = 真正的正例数 / (真正的正例数 + 假负例数)
其中,真正的正例数是模型正确预测为正例且实际为正例的样本数,假负例数是模型错误预测为负例但实际为正例的样本数。
召回率的取值范围在0到1之间,数值越高表示模型能够更准确地识别出真正的正例样本,即模型在将正例漏报(错判为负例)的情况下更少。

之后是F1值:
F1值是一种综合考虑精确率(Precision)和召回率(Recall)的评估指标,用于衡量二分类模型的性能。F1值是精确率和召回率的调和平均值,可以综合评估模型在正确预测正例和尽可能少漏报的能力。F1值可以使用以下公式计算:
F1值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
精确率和召回率的取值范围都在0到1之间,F1值的取值范围也在0到1之间。F1值越接近1,表示模型在同时考虑精确率和召回率时具有更好的性能。
F1值在处理不平衡数据集和对模型的整体性能进行评估时非常有用。例如,在垃圾邮件分类任务中,我们希望模型既能准确地将垃圾邮件分类为垃圾,又能尽量少漏掉真正的垃圾邮件。F1值综合了这两个指标,提供了一个全面的性能评估指标。
需要注意的是,F1值将精确率和召回率看作同等重要,适用于在精确率和召回率之间没有明确优先关系的任务。如果任务对于精确率或召回率有不同的重要性,可以根据需求选择适当的评估指标或调整模型的阈值。

最后是loss曲线对比:
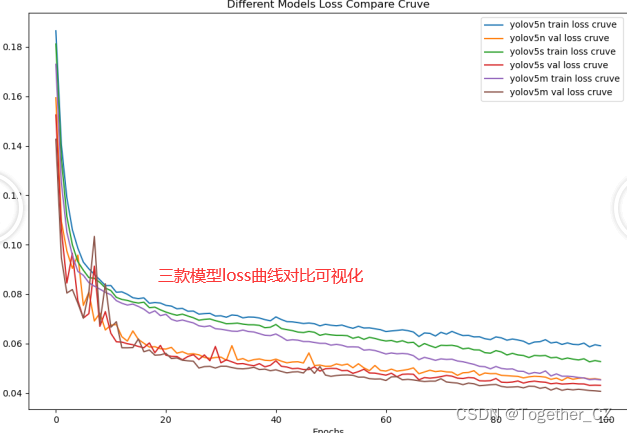
可以看到:m系列的模型效果是优于n和s的。