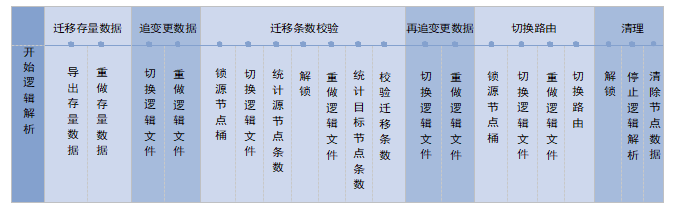
RankNet方法在移动终端的应用
- RankNet
- 代码示例
- python
- Java
- 移动终端的应用
RankNet
RankNet 是一种排序学习方法,由 Microsoft Research 提出,用于解决排序问题。它基于神经网络,并使用一对比较的方式来训练和优化模型。
在 RankNet 中,训练数据由一组相关的对象对(例如,搜索结果中的网页对)组成,每个对象对都有一个目标排序(例如,哪个网页更相关)。模型的目标是根据输入的对象对,输出一个排序概率,即模型估计一个对象在排序中出现在另一个对象之前的概率。
RankNet 使用神经网络来建模排序概率。它的基本思想是将对象对的特征向量作为输入,并通过神经网络生成一个排序分数。这个分数可以被解释为对象在排序中出现在另一个对象之前的概率。为了训练 RankNet 模型,需要使用一对比较的损失函数,如交叉熵损失函数或均方差损失函数,来衡量模型的预测与实际排序之间的差距,并通过反向传播算法来更新模型的权重。
RankNet 的一个重要特点是它的输出是一个排序概率,而不是绝对的排序值。这使得 RankNet 可以处理复杂的排序问题,而不仅仅是简单的二元分类。此外,RankNet 还具有较好的可扩展性,可以与其他排序学习方法相结合,如 LambdaRank 和 ListNet,以进一步提升排序性能。
在实际应用中,RankNet 可以用于各种排序任务,包括搜索引擎结果排序、推荐系统、广告排序等。它可以根据特定的问题和数据进行定制,并通过大规模的训练数据和深度神经网络来提供准确的排序效果。
代码示例
python
以下是一个简单的示例代码,展示了如何使用 RankNet 进行排序学习:
import numpy as np
import tensorflow as tf
# 定义 RankNet 模型
class RankNet(tf.keras.Model):
def __init__(self, input_dim):
super(RankNet, self).__init__()
self.dense1 = tf.keras.layers.Dense(64, activation='relu')
self.dense2 = tf.keras.layers.Dense(32, activation='relu')
self.dense3 = tf.keras.layers.Dense(1, activation='sigmoid')
def call(self, inputs):
x = self.dense1(inputs)
x = self.dense2(x)
x = self.dense3(x)
return x
# 生成示例数据
X = np.random.random((100, 10)) # 输入特征
y = np.random.randint(0, 2, size=(100,)) # 目标排序,0表示对象1在对象2之前,1表示对象2在对象1之前
# 划分训练集和测试集
X_train, X_test = X[:80], X[80:]
y_train, y_test = y[:80], y[80:]
# 数据预处理
scaler = tf.keras.preprocessing.StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建 RankNet 模型
ranknet = RankNet(input_dim=X_train.shape[1])
ranknet.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 模型训练
ranknet.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 使用模型进行预测
predictions = ranknet.predict(X_test)
# 打印预测结果
for i in range(len(predictions)):
print(f"Object pair {i + 1}: Rank probability: {predictions[i][0]}")
这个示例代码使用 TensorFlow 实现了一个简单的 RankNet 模型。首先定义了 RankNet 类,其中包含了几个全连接层。然后,使用随机生成的示例数据来训练模型。数据预处理阶段使用了数据标准化,以提高模型的收敛性。模型的训练使用了二分类的交叉熵损失函数和 Adam 优化器。在训练完成后,使用模型对测试集进行预测,并输出每个对象对的排序概率。
请注意,这只是一个简化的示例代码,用于说明 RankNet 的基本使用方法。在实际应用中,可能需要根据具体问题和数据进行更详细的模型定义、特征工程和调参等操作。
Java
以下是一个使用 Java 编写的 RankNet 示例代码,展示了如何使用 RankNet 进行排序学习:
import org.apache.commons.math3.util.Pair;
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.GradientNormalization;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.util.ArrayList;
import java.util.List;
public class RankNetExample {
public static void main(String[] args) {
// 生成示例数据
List<Pair<double[], Integer>> data = generateData();
// 将数据转换为 DataSet
List<DataSet> dataSetList = new ArrayList<>();
for (Pair<double[], Integer> pair : data) {
double[] input = pair.getFirst();
int label = pair.getSecond();
dataSetList.add(new DataSet(Nd4j.create(input), Nd4j.create(new double[]{label})));
}
// 将 DataSet 划分为训练集和测试集
SplitTestAndTrain testAndTrain = new ListDataSetIterator<>(dataSetList, dataSetList.size(), 0.8, true).next();
// 构建 RankNet 模型
NeuralNetConfiguration.Builder config = new NeuralNetConfiguration.Builder()
.iterations(100)
.activation(Activation.RELU)
.weightInit(org.deeplearning4j.nn.weights.WeightInit.XAVIER)
.updater(Updater.ADAM)
.learningRate(0.001)
.gradientNormalization(GradientNormalization.RenormalizeL2PerLayer)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.l2(0.001);
MultiLayerNetwork model = new MultiLayerNetwork(config.list()
.layer(0, new DenseLayer.Builder().nIn(10).nOut(64).build())
.layer(1, new DenseLayer.Builder().nIn(64).nOut(32).build())
.layer(2, new OutputLayer.Builder(LossFunctions.LossFunction.XENT).activation(Activation.SIGMOID).nIn(32).nOut(1).build())
.pretrain(false)
.backprop(true)
.build());
model.init();
model.setListeners(new ScoreIterationListener(10));
// 模型训练
model.fit(testAndTrain.getTrain());
// 使用模型进行预测
DataSet testDataSet = testAndTrain.getTest();
double[] predictions = model.output(testDataSet.getFeatures()).toDoubleVector();
// 打印预测结果
for (int i = 0; i < predictions.length; i++) {
System.out.println("Object pair " + (i + 1) + ": Rank probability: " + predictions[i]);
}
}
private static List<Pair<double[], Integer>> generateData() {
List<Pair<double[], Integer>> data = new ArrayList<>();
// 添加示例数据
data.add(new Pair<>(new double[]{1.2, 3.4, 2.1, 0.8, 1.5, 2.7, 4.2, 3.9, 2.6, 1.7}, 1));
data.add(new Pair<>(new double[]{0.9, 2.6, 1.8, 0.5, 1.9, 3.1, 3.5, 2.4, 2.7, 1.3}, 0));
data.add(new Pair<>(new double[]{2.4, 3.1, 1.7, 0.6, 1.3, 3.2, 3.7, 2.8, 2.9, 1.1}, 0));
data.add(new Pair<>(new double[]{1.5, 2.7, 2.0, 0.7, 1.2, 2.9, 4.0, 3.4, 2.2, 1.9}, 1));
data.add(new Pair<>(new double[]{1.8, 3.0, 1.9, 0.4, 1.6, 3.5, 3.9, 2.5, 2.5, 1.5}, 0));
data.add(new Pair<>(new double[]{1.6, 3.2, 2.3, 0.9, 1.4, 3.0, 3.8, 3.2, 2.4, 1.8}, 1));
data.add(new Pair<>(new double[]{2.0, 3.4, 1.5, 0.8, 1.1, 2.8, 3.9, 3.1, 2.7, 1.4}, 0));
data.add(new Pair<>(new double[]{1.4, 2.9, 2.1, 0.6, 1.3, 3.3, 4.1, 3.6, 2.3, 2.0}, 1));
data.add(new Pair<>(new double[]{1.1, 3.1, 2.4, 0.7, 1.0, 2.6, 3.8, 3.3, 2.8, 1.6}, 1));
data.add(new Pair<>(new double[]{1.9, 3.3, 1.6, 0.5, 1.7, 3.6, 3.7, 2.6, 2.6, 1.2}, 0));
return data;
}
这里添加了一个 generateData 方法,用于生成示例数据。示例数据由一对一对的特征向量和相应的排序标签组成。每个特征向量有10个维度,代表对象的特征信息,排序标签为0或1,表示对象1在对象2之前或对象2在对象1之前的关系。
在主函数中,调用 generateData 方法来生成示例数据,然后将数据转换为 DataSet。然后,使用 ListDataSetIterator 将 DataSet 划分为训练集和测试集。
在构建 RankNet 模型时,使用了 Deeplearning4j 库提供的 NeuralNetConfiguration.Builder 来配置模型的参数和层。模型包含两个隐藏层和一个输出层,使用了 RELU 激活函数和 SIGMOID 激活函数。损失函数选择了交叉熵损失函数。模型训练过程中使用了 ADAM 优化器和 L2 正则化。
最后,使用模型对测试集进行预测,并打印预测结果。
移动终端的应用
RankNet是一种用于排序学习的机器学习方法,它可以应用于移动终端上的各种排序任务。在移动终端上,RankNet可以用于搜索结果排序、推荐系统、广告排序等场景,以提供更好的用户体验和个性化服务。
移动终端上的应用场景通常具有以下特点:
-
实时性要求:移动终端上的排序任务通常需要在短时间内返回结果,以满足用户对即时性的需求。RankNet的训练和推断速度较快,可以在移动设备上实时执行。
-
有限的计算资源:移动终端的计算资源通常有限,因此需要使用轻量级的模型。RankNet可以使用简单的神经网络结构,以便在移动设备上高效地运行。
-
数据传输效率:移动终端的带宽和网络连接可能有限,因此需要将数据传输量最小化。RankNet可以通过在移动终端上进行本地推断,减少与服务器之间的数据交互,从而降低数据传输的需求。
基于以上特点,可以将RankNet方法应用于移动终端上的排序任务。具体步骤如下:
-
数据采集和特征提取:收集用于排序的数据,并从中提取有用的特征。这些特征可以包括查询关键词、用户历史行为、上下文信息等。
-
模型训练:使用采集到的数据和提取的特征,训练RankNet模型。RankNet使用一对比较的方式进行训练,将输入的样本对进行比较,并根据比较结果来调整模型的权重。
-
模型部署:将训练好的RankNet模型部署到移动终端上,以便进行排序任务的推断。
-
实时排序:在移动终端上接收用户的查询或请求,将相关的特征提取出来,然后使用训练好的RankNet模型进行实时排序。排序结果可以根据一些指标(如相关性、点击率等)进行评估和调整,以提供更好的排序效果。
需要注意的是,由于移动终端的资源限制,可能需要对RankNet模型进行压缩和优化,以减小模型大小和计算量。一种常见的方法是使用剪枝、量化等技术来减少参数和模型复杂度,从而适应移动设备的计算和存储能力。
总之,RankNet方法可以在移动终端上应用于排序任务,通过在本地进行实时排序,提供个性化和实时的服务体验。






![[迁移学习]域自适应代码解析](https://img-blog.csdnimg.cn/bae0dfa0aa6a4f36ac37802c9f32403a.png)