(2023.06.09-2023.06.12)论文阅读简单记录和汇总
2023/06/09:虽然下周是我做汇报,但是到了周末该打游戏还是得打的
2023/06/12:好累好困,现在好容易累。
目录
- (TCSVT 2023)Facial Image Compression via Neural Image Manifold Compression
- (arxiv 2023)Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression
- (arxiv 2023)High-Similarity-Pass Attention for Single Image Super-Resolution
- (arxiv 2023)Reconstruction Distortion of Learned Image Compression with Imperceptible Perturbations
- (IEEE T-BC 2023)End-To-End Compression for Surveillance Video With Unsupervised Foreground-Background Separation
- (arxiv 2023)Improving Position Encoding of Transformers for Multivariate Time Series Classification
- (arxiv 2023)Unsupervised haze removal from underwater images
- (arxiv 2023)Human-imperceptible, Machine-recognizable Images
1. (TCSVT 2023)Facial Image Compression via Neural Image Manifold Compression 通过神经图像流形压缩进行面部图像压缩
1.1 摘要
虽然近年来基于学习的图像和视频 编码技术得到了快速发展,但这些方法中信号保真度驱动的目标导致了对人 和机器的高效编码框架的分歧。在本文中,我们的目标是通过利用生成模型的力量来弥合全保真度(用于人类视觉)和高分辨力 (用于机器视觉)之间的差距来解决这个问题。因此,依靠现有的预训练 生成对抗网络(GAN),我们构建了一个GAN反演框架,将图像投影到低维 自然图像流形中。在这个流形中,特征具有很强的判别性,同时对图像的外观信息 进行编码,称为潜码。采用变分比特率 约束和超先验模型来建模/抑制图像流形码的熵 ,我们的方法能够在非常低的比特率下满足机器和人类视觉的 需求。为了提高图像重建的视觉质量, 我们进一步提出了多隐码和可伸缩反演。前者在反演过程中得到多个隐码,而 则在此基础上进行压缩并传输一个浅压缩 特征以支持视觉重构。实验结果 证明了我们的方法在人类 视觉任务(即图像重建)和机器视觉任务( 包括语义解析和属性预测)中的优越性。
贡献总结如下:
- 我们提出了一种新的压缩框架,它结合了生成模型的功能以及学习的比特率约束和非常低比特率图像/视频压缩的优化。
- 在我们提出的框架中,一个非常紧凑的特征向量首先被压缩并传输到解码器端,它可以以准确和计算高效的方式转换为机器分析结果,以支持协作智能范式。
- 在基线GAN反演框架之外,为了进一步提高人类对全像素重建结果的感知,我们提出了多隐码和可扩展反演,通过合理的比特率绕过流,显著提高了视觉重建质量。
1.2 结论
在本文中,我们开发了一个基于GAN反演的压缩框架,追求紧凑的低维低维自然图像流形用于面部图像压缩。利用 GAN训练的优点,该空间的隐码不仅具有 高判别性,而且能够编码 图像的外观信息。在应用比特率约束后,得到一个紧凑的代码,以非常低的比特率从机器和人类的角度 执行多个任务。我们进一步扩展了隐码 的形式,提出了多个隐码和可扩展的 反演方案,以额外压缩和传输 浅压缩特征,以支持视觉重建,以获得 更好的视觉质量。实验结果证明了我们的方法在人类视觉和机器 视觉任务中的优越性。
2. (arxiv 2023)Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression 探索神经图像压缩中的速率-失真-复杂度优化
2.1 摘要
尽管历史很短,神经图像编解码器已被证明在率失真性能方面优于经典图像编解码器。然而,它们中的大多数都有 显着较长的解码时间,这阻碍了神经图像编解码器的实际 应用。当采用有效但耗时的 自回归上下文模型时,这个问题尤其 明显,因为它会增加熵 解码时间。在本文中,与 大多数先前的作品追求最优RD性能 而暂时忽略编码复杂性不同,我们 系统地研究了神经图像压缩中的速率-失真-复杂性 (RDC)优化。通过量化 解码复杂性作为优化目标中的一个因素,我们 现在能够精确地控制RDC权衡,然后 演示神经图像 编解码器的率失真性能如何适应各种复杂性需求。除了 对RDC优化的研究之外,还设计了一个可变复杂度 神经编解码器,根据工业需求自适应地利用空间依赖性 ,通过平衡RDC权衡来支持细粒度的复杂性调整。通过在一个强大的基本模型中实现该方案,我们 证明了RDC优化 用于神经图像编解码器的可行性和灵活性。
贡献总结如下:
- 通过将熵解码的复杂性量化为优化,我们第一次能够很好地控制神经图像编解码器的速率-失真-复杂性权衡。
- 我们引入了一种统一的变复杂度图像压缩模型,该模型可以在单个模型内将解码复杂度调整到较细的粒度。
- 我们在一个强大的基础模型中实现了可变复杂度方案,并进行了全面的实验,验证了RDC优化在神经图像压缩中的潜力。
2.2 结论
本文系统地研究了神经图像 压缩中的RDC优化问题。我们首次通过量化 并将解码复杂性纳入优化中,实现了对速率-失真-复杂性权衡的宝贵控制。此外,提出了一种可变复杂度神经编解码器 支持细粒度复杂度调整,该编解码器自适应 控制上下文 模型中的空间依赖关系建模。我们的综合实验结果证明了 神经 图像编解码器RDC优化的可行性和灵活性。
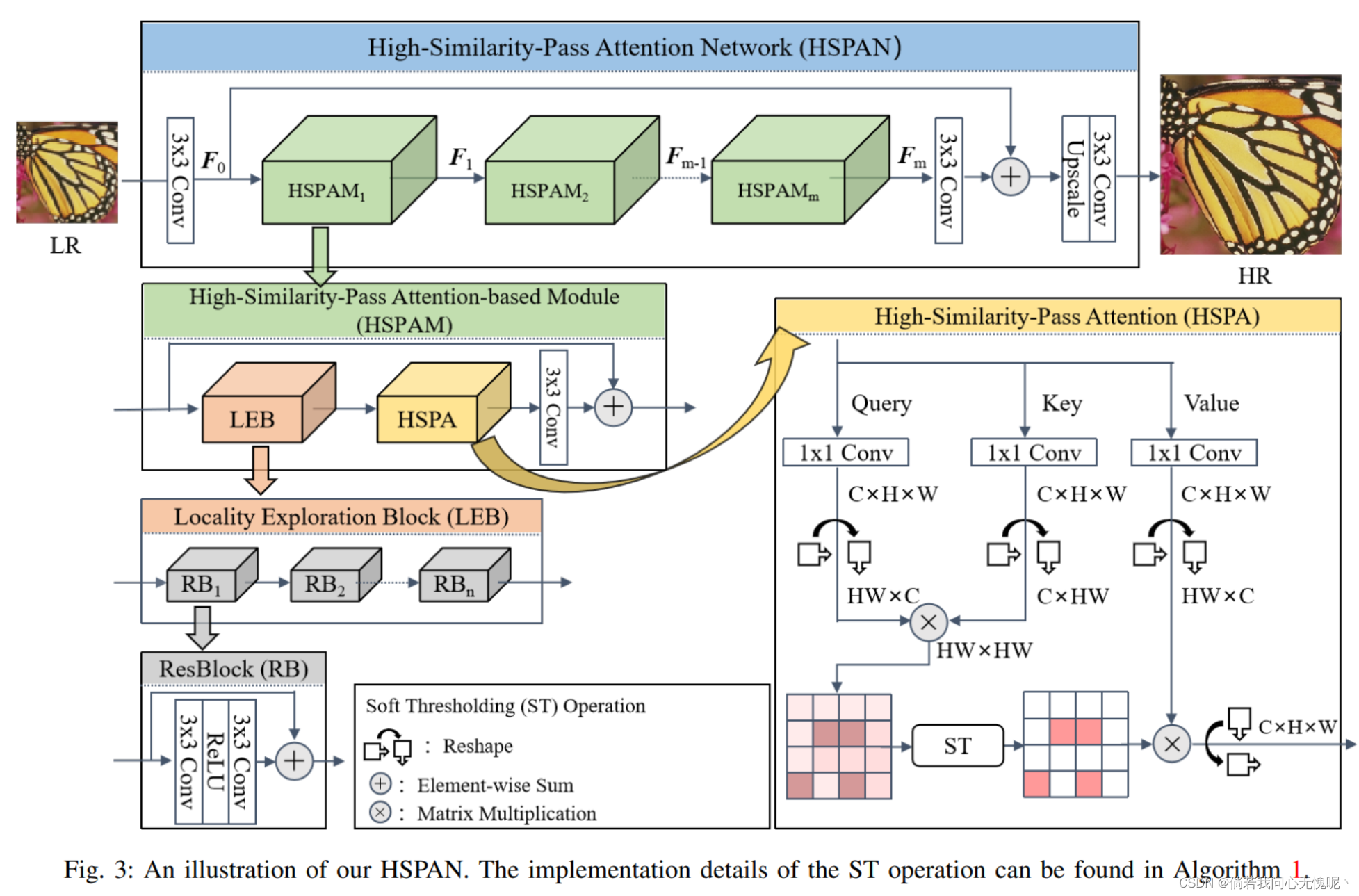
3.(arxiv 2023)High-Similarity-Pass Attention for Single Image Super-Resolution 单幅图像超分辨率的高相似度传递注意
3.1 摘要
非局部注意(NLA)领域的最新发展引起了人们对基于自相似性的单图像超分辨率(SISR)的新兴趣。研究者通常使用 NLA来探索SISR中的非局部自相似(NSS), 获得了令人满意的重建结果。然而,一个令人惊讶的现象,即标准 NLA的重建性能与随机选择区域的NLA相似 ,激发了我们重新审视NLA的兴趣。在本文中,我们首先 从不同的 角度分析了标准NLA的注意图,发现得到的概率分布总是完全支持每个局部特征,这意味着对不相关的非局部特征赋值是一种统计浪费,特别是对于需要用大量冗余的非局部特征来建模远程依赖的SISR。基于这些发现,我们引入了一种简洁但 有效的软阈值操作来获得高相似度传递注意力(HSPA),这有利于生成 更紧凑和可解释的分布。此外,我们 推导了软阈值操作 的一些关键属性,使我们能够以端到端方式训练HSPA。 HSPA可以作为一个 高效的通用构件集成到现有的深度SISR模型中。此外,为了验证HSPA的 有效性,我们将几个HSPA整合到 一个简单的骨干网络中,构建了一个深度高相似通道关注网络(HSPAN)。广泛的实验结果表明 HSPAN在 定量和定性评估上都优于最先进的方法。
贡献总结如下:
- 我们对NLA在基于自相似性的深度SISR方法中的局限性提出了新的见解,并认为NLA中的softmax变换对于长序列的SISR存在不可克服的缺陷。(如图1、图2所示)
- 我们形式化了一个简洁而有效的软阈值操作,并探索了它的关键属性,这使得在深度SISR中端到端优化我们的高相似性传递注意力成为可能。
- 利用基于HSPAN的模块设计了一个深度高相似度注意网络(HSPAMs),并取得了最先进的定量和定性结果。
3.2 结论
在本文中,我们对在SISR问题中使用 的NLA提供了新的见解,并发现作为NLA的一个 关键组成部分的softmax变换不适合探索远程信息。为了克服这个缺点,我们设计了一个灵活的高相似度传递注意(HSPA),使我们的 深度高相似度注意网络(HSPAN)专注于 更有价值的非局部纹理,同时去除不相关的纹理。此外,我们探索了 提出的软阈值(ST)操作的一些关键特性,以端到端方式训练我们的HSPA 。据我们所知,这 是第一次尝试分析和解决 在低级视觉问题中利用softmax变换进行远程序列 建模的局限性。此外,广泛的 实验表明,我们的HSPA和ST操作可以 集成为现有的深度 SISR模型中有效的通用构建单元。
4. (arxiv 2023)Reconstruction Distortion of Learned Image Compression with Imperceptible Perturbations 具有不可察觉扰动的学习图像压缩的重建失真
4.1 摘要
学习图像压缩(LIC)由于其显著的性能成为近年来图像传输的趋势技术 。尽管它很受欢迎,但LIC在图像重建质量方面的稳健性仍然未得到充分探索。在本文中,我们引入了一种难以察觉的攻击方法 ,旨在有效地降低LIC的重建质量,导致重建图像受到噪声的严重干扰,其中重建图像中的任何物体几乎都不可能。更具体地说,我们通过引入基于Frobenius范数的损失函数来生成对抗示例,以最大化原始图像与重建的对抗示例之间的差异。此外,利用高频组件对人类视觉的不敏感性,我们引入了不可感知约束(IC)以确保扰动保持不明显。在柯达数据集 上使用各种LIC模型进行的实验证明了有效性。此外,我们提供 一些发现和建议,以设计未来的防御。
贡献总结如下:
- 我们对LIC的鲁棒性进行了系统的研究,通过发起一系列攻击,通过引入Frobenius 基于范数的IC损失来破坏图像重建过程。
- 我们的实验表明,我们提出的攻击可以破坏LIC ,同时保持诱导扰动的不可感知性。
- 基于我们的实验,我们提供了几个有趣的发现和关于设计健壮的LIC的潜在见解。
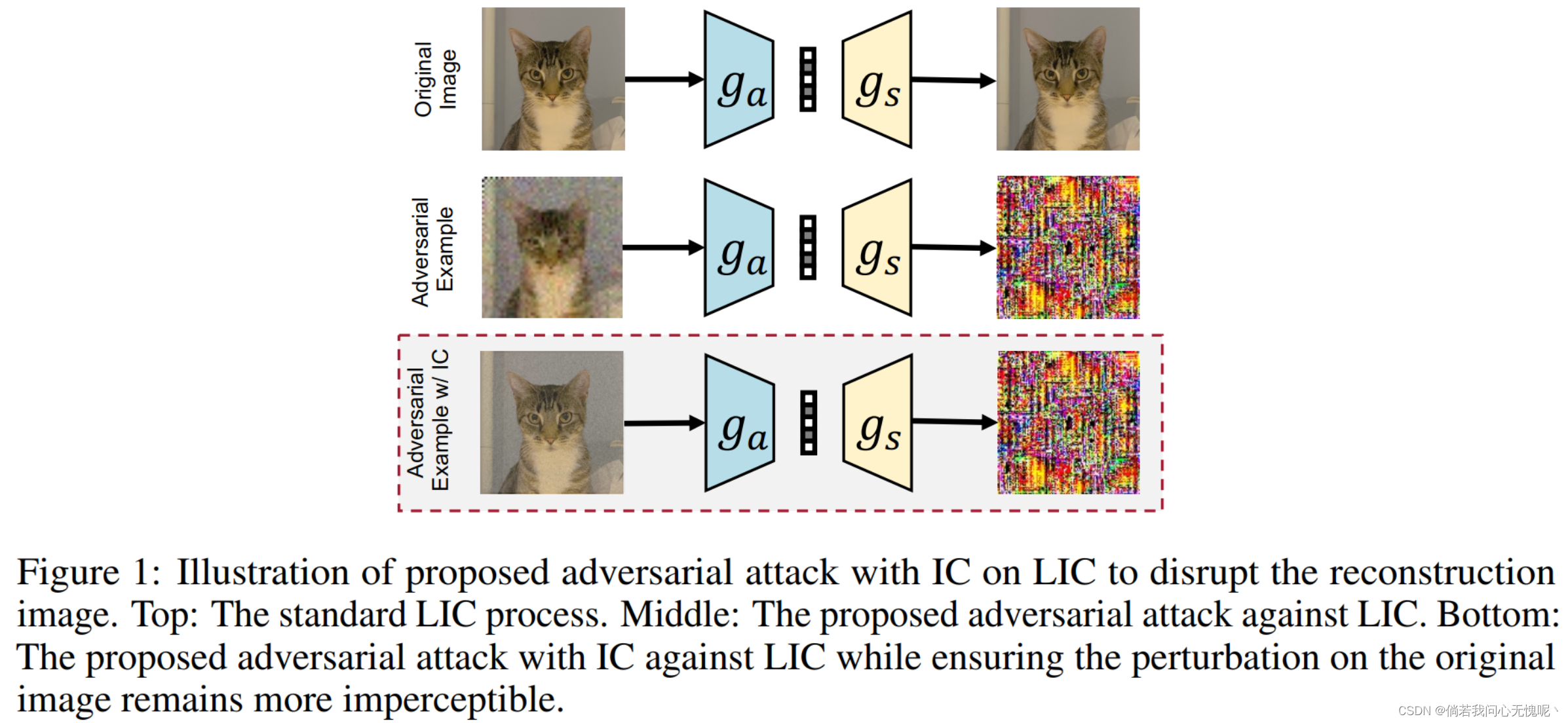
4.2 发现
我们的实验得出了几个有趣的观察结果:(1)除了任意噪声外, 产生的对抗性扰动还包含某些不规则模式。例如,可以在图3中观察到,在每个产生的扰动中都有小的方形图案。我们假设这些特定区域可能对重建质量有重大影响。未来的工作可能会研究设计检测和防御对抗性攻击的对策利用这些模式。(2)不同的LIC模型表现出不同程度的鲁棒性。从无花果。2、我们发现Hyperprior和Joint似乎比其他方法更健壮。基于此,我们假设具有更高质量重建能力的LIC模型也具有更好的鲁棒性。

4.3 结论
在本文中,我们通过发起基于 Frobenius范数损失函数的对抗性质量攻击来探索LIC的鲁棒性,以创建使原始图像和重建图像之间偏差最大化的对抗性示例,并引入IC以确保扰动 对人类感知不可见。对柯达数据集和各种LIC模型的实验说明了 的有效性,并揭示了有趣的发现,包括不规则的扰动模式和 不同LIC模型的鲁棒性水平。
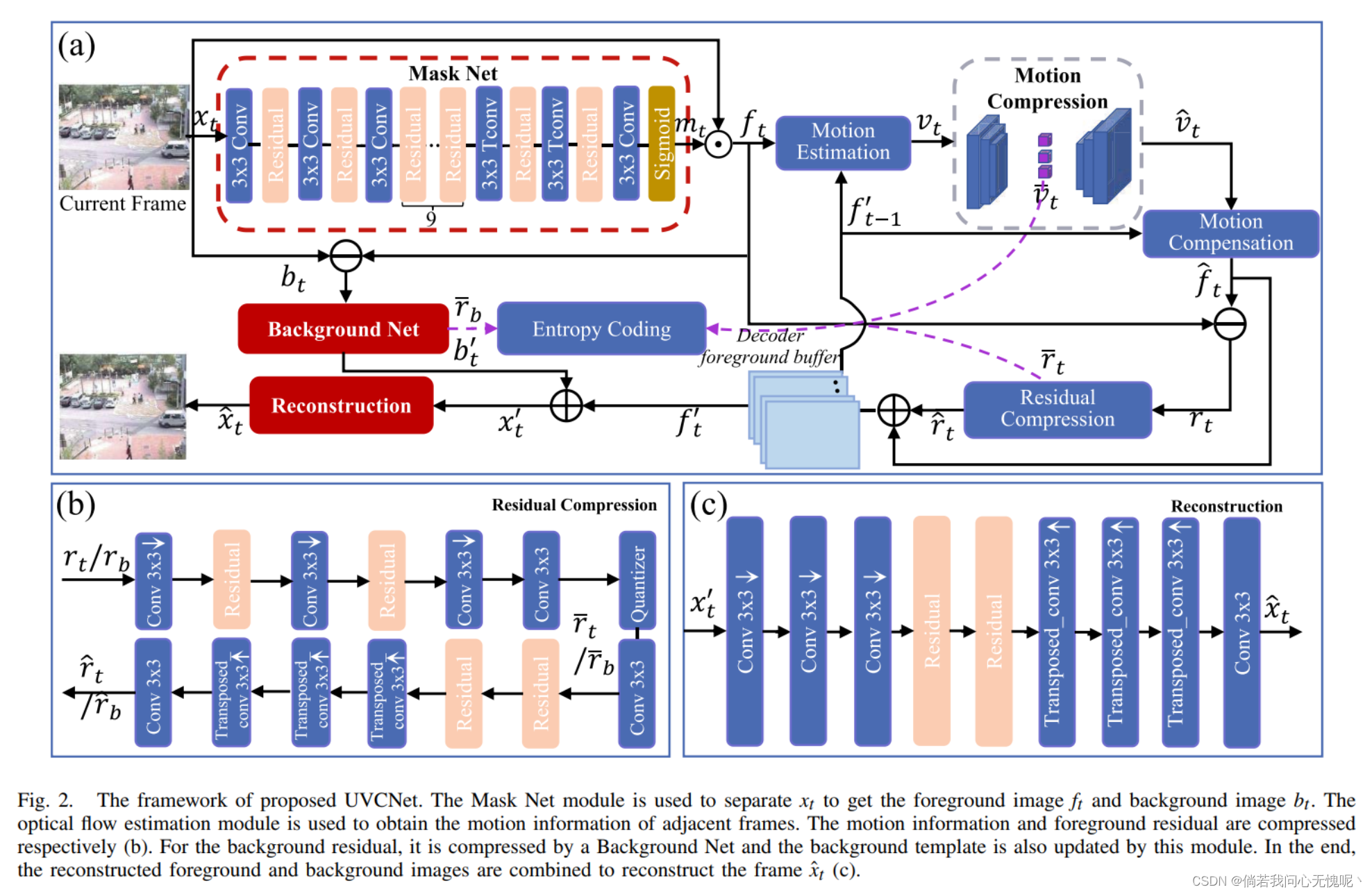
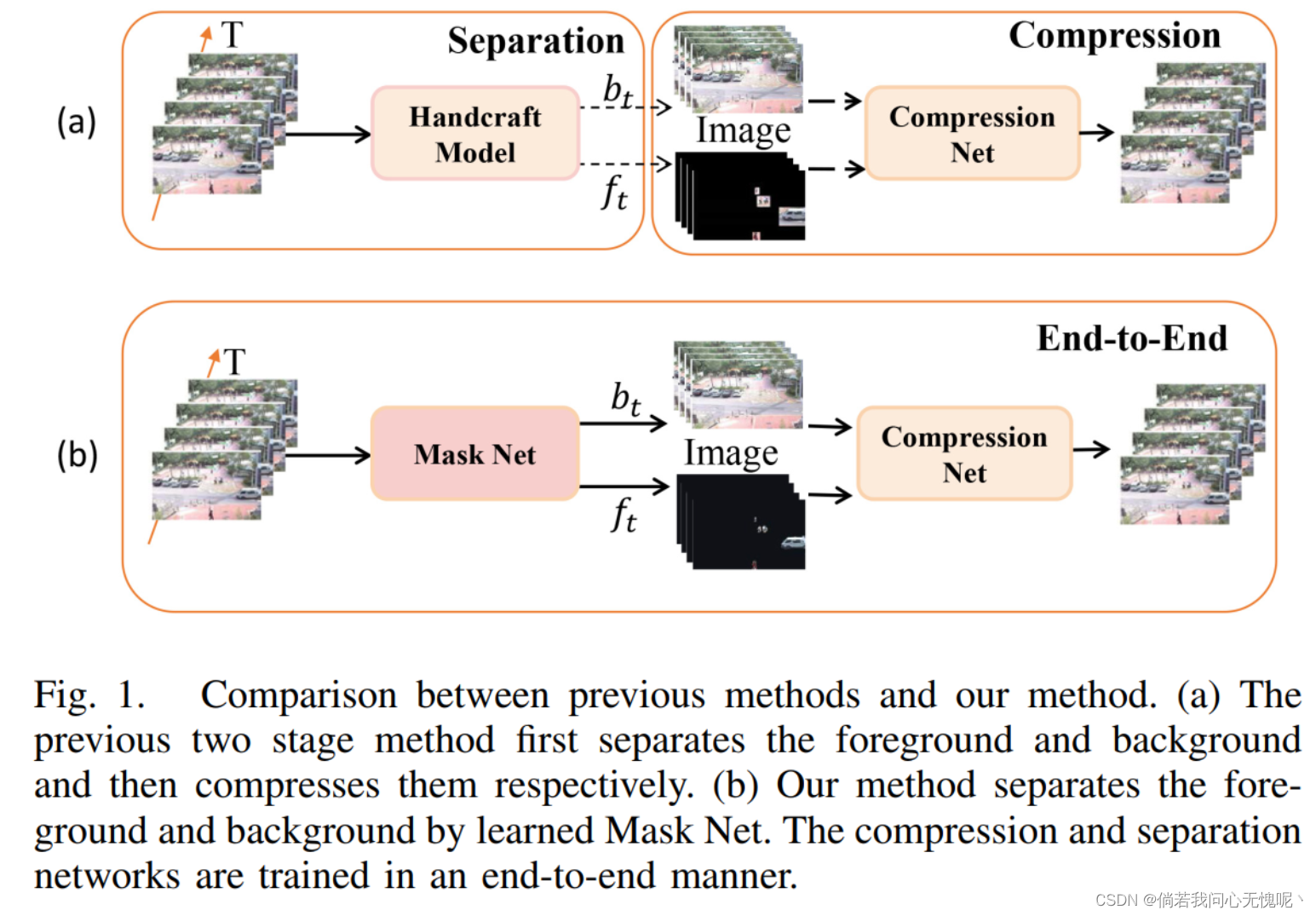
5. (IEEE T-BC 2023)End-To-End Compression for Surveillance Video With Unsupervised Foreground-Background Separation 具有无监督前景-背景分离的监控视频的端到端压缩
5.1 摘要
随着监控视频的指数级增长,对高效视频编码方法的需求越来越大。基于学习的方法要么直接使用通用的视频 压缩框架,要么分离前景和背景,然后分两个阶段压缩它们。然而,它们没有考虑到监控视频相对静态的背景事实 ,或者在离线模式下简单地分离前景和背景,这降低了分离性能 ,因为它们没有很好地考虑时域相关性 。在本文中,我们提出了一个端到端的无监督前景背景分离视频压缩神经网络,称为UVCNet。我们的方法主要由三部分组成。首先,Mask Net在线无监督地分离前景和背景,这充分利用了时间相关先验 。然后,将传统的基于运动估计的残差编码模块应用于前景压缩。同时,利用背景压缩模块对背景残差进行压缩,充分利用相对静态的特性对背景进行更新。与之前的方法相比,我们的方法不需要提前分离前景和背景,而是端到端 的方式。因此我们不仅可以利用相对静态的背景 属性来节省比特率,还可以实现端到端的在线 视频压缩。实验结果表明, 所提出的UVCNet与 现有方法相比,具有更好的性能。具体来说,UVCNet可以实现 峰值信噪比 (PSNR)在监控数据集上比H.265平均提高了2.11 dB。
贡献总结如下:
- 我们是第一个提出端到端无监督监控视频压缩框架UVCNet。与之前的研究不同,该框架可以在线上分离前景和背景,并在整个网络中进行端到端训练 。
- 提出了一种新的自适应背景更新策略。一旦背景变化超过一定阈值参考背景将被更新。与以往的静态或固定间隔 更新不同,我们的自适应更新策略使参考背景更加准确,从而进一步降低了背景残差。
- 大量的实验证实了该框架的有效性。在Ewap_eth数据集 和Ewap_hotel数据集上,与最先进的方法相比,所提出的方法在BD-PSNR方面分别获得了0.8 dB和0.34 dB的增益。
5.3 结论
本文通过观察和总结监控视频的特点,提出了一种端到端监控视频编码方法,命名为UVCNet (Unsupervised 基于前景背景分离的视频压缩 神经网络)。简而言之,本文提出了自监督方法 来训练一个前景背景分离网络 (Mask Net),该网络可以细粒度地分析帧中变化较小的背景部分。在背景压缩模块(背景网)中,提出了一种简单的在线背景更新方法,利用相对静态的特性对背景残差进行了高效压缩。实验上常用的有三种监控视频数据集表明,我们的结果超越了 现有方法,成为一种新的SOTA。
6. (arxiv 2023)Improving Position Encoding of Transformers for Multivariate Time Series Classification 改进用于多元时间序列分类的 Transformer 的位置编码
Code:https://github.com/Navidfoumani/ConvTran
6.1 摘要
Transformer在许多 深度学习应用中表现出了出色的性能。当应用于时间序列数据时,变压器需要有效的位置编码来捕获 时间序列数据的顺序。位置编码在时间序列分析中的有效性还没有得到很好的研究,并且仍然存在争议,例如, 是注入绝对位置编码还是相对位置编码更好,还是两者结合更好。为了清楚这一点,我们首先回顾了在时间序列分类中应用时现有的绝对位置和相对位置编码方法。然后,我们提出了一种新的用于时间序列数据的绝对位置编码方法,称为时间绝对位置编码(tAPE)。我们的新方法在绝对位置编码中结合了序列长度和输入嵌入维数。此外,我们提出了计算效率相对位置编码(eRPE)的实现,以提高时间序列的通用性。然后,我们提出了一种新的多元时间序列分类(MTSC)模型,该模型结合了tAPE/eRPE和基于卷积的输入编码,称为ConvTran,以改善时间序列数据的位置和数据嵌入。本文提出的绝对位置 和相对位置编码方法简单有效。它们 可以很容易地集成到变压器块中,并用于下游任务,如预测、外部回归和异常检测。在32个多变量时间序列数据集上进行了广泛的实验,表明我们的模型比最先进的卷积和基于Transformer的模型要准确得多。
6.2 结论
本文首次研究了位置编码对时间序列的重要性 ,并对现有的绝对位置编码和相对位置编码 方法在时间序列分类中的应用进行了综述。基于目前 时间序列位置编码的局限性,我们提出了两种新的时间序列绝对位置编码和相对位置编码,分别称为tAPE和eRPE 。然后,我们将我们提出的两个位置编码集成到Transformer莫夸哦中,并将它们与卷积层结合起来,提出了一个 用于多变量时间序列分类(ConvTran)的新型深度学习框架。大量实验表明,ConvTran受益于位置信息,在深度学习文献中实现了最先进的多元时间序列分类性能。未来,我们将在其他基于变压器的TSC模型和 其他下游任务(如异常检测)中研究我们的新变压器块的有效性。
7. (arxiv 2023)Unsupervised haze removal from underwater images 从水下图像中去除无监督的雾霾
7.1 摘要
存在一些监督网络,它们使用配对数据集和 逐像素损失函数从水下图像中去除雾霾 信息。然而,训练这些网络需要大量的配对数据,这是繁琐的、复杂和耗时的。此外,直接使用对抗性 和循环一致性损失函数进行无监督学习是不准确的,因为从干净图像到水下图像的底层映射是一对多的,导致对循环一致性损失的约束不准确。为了解决这些问题, 我们提出了一种新的方法来去除雾霾从水下 图像使用不成对的数据。我们的模型使用雾霾解纠缠网络(HDN)从水下图像中解纠缠雾霾和内容信息。解纠缠内容由恢复网络使用对抗损失生成干净的图像。然后将解纠缠雾霾用作水下图像再生的引导,从而对周期一致性损失产生强烈的约束,并提高了性能增益。不同消融实验表明,水下图像中的雾霾和内容被有效分离。详细的实验表明,精确的循环一致性约束和所提出的网络结构在生成优异结果中发挥了重要作用。在UFO-120、UWNet、 UWScenes和UIEB水下数据集上的实验表明, 方法的结果在视觉和数量上都优于现有技术。
贡献总结如下:
- 据我们所知,这是第一个基于学习的方法,在水下图像中使用正确的循环一致性损失来去除不成对的雾霾。
- 在不同水下数据集上的详尽实验表明,与先前的无监督方法相比,精确的周期一致性匹配结合解纠缠内容的恢复网络可以获得高质量的去雾结果。
在我们的方法中,HDN使用特征正则化、特征对抗和循环损失来从输入图像中解耦雾霾和内容信息。不同的消融实验提供了水下图像中雾霾和内容信息的可视化结果。在不同的公开数据集上的详尽实验表明,精确的循环一致性约束结合
G
c
G_c
Gc的解纠缠内容与先前的无监督方法相比具有更好的结果。
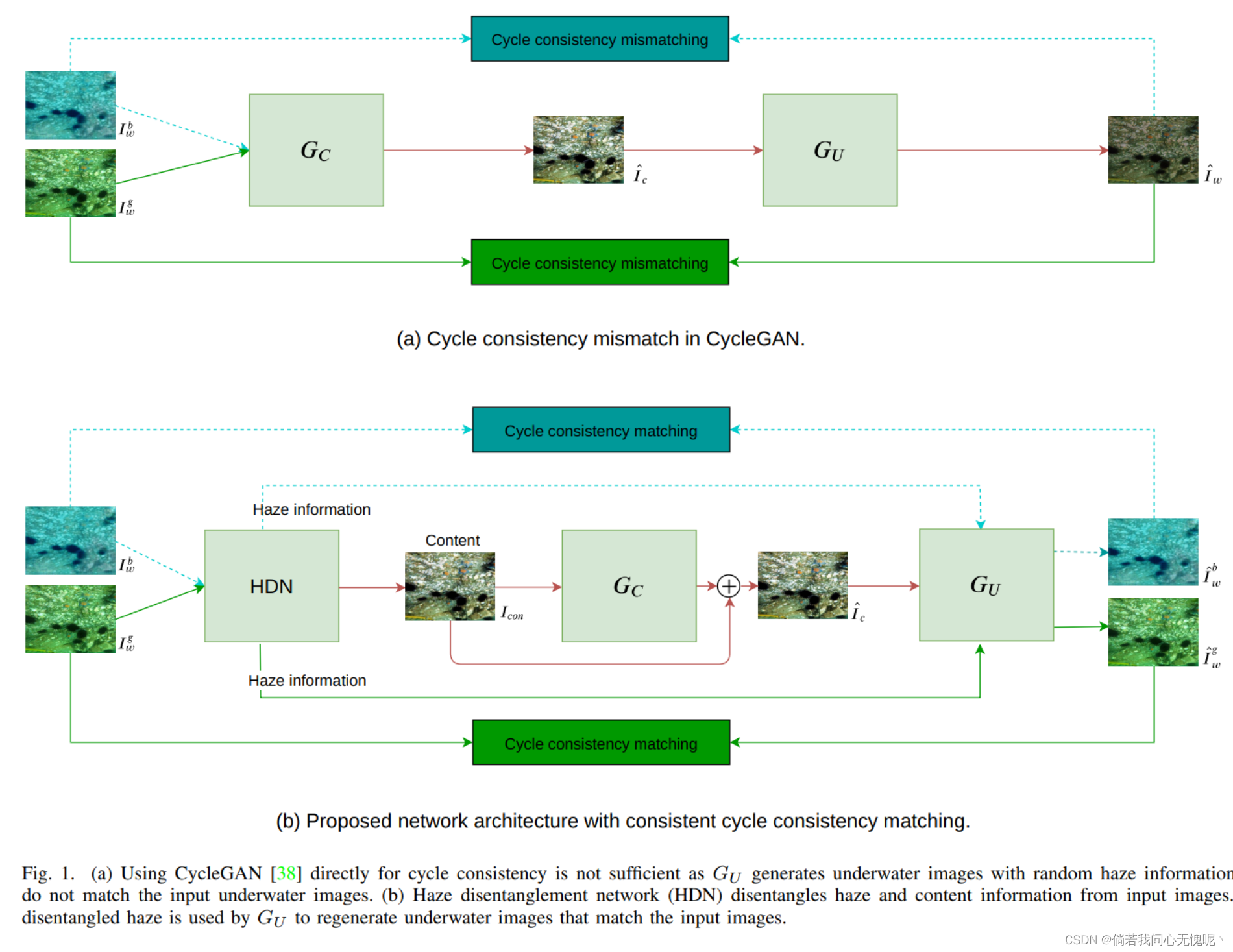
7.2 结论
我们提出了一种基于雾霾解纠缠网络 (HDN)和恢复模块的水下图像的无监督雾霾去除算法。HDN用于从UW图像中分离雾霾和内容。而解纠缠内容作为恢复模块的输入, 雾霾信息用于“一致”周期一致性。不同的消融研究表明,提出的HDN 网络成功地解耦了水下图像的雾和内容。相比于之前的方法,我们的方法在视觉比较和定量指标上都取得了提高。我们相信本文提出的损失函数和网络架构将有助于进一步提高无监督网络的性能。
8. (arxiv 2023)Human-imperceptible, Machine-recognizable Images 人类无法察觉、机器可识别的图像
Code:https://github.com/FushengHao/PrivacyPreservingML
这个大哥怎么在论文里把点号也算到超链接里去了,特么的点进去就是Page not found。
8.1 摘要
收集大量与人类相关的数据来训练神经网络,用于计算机 视觉任务。对于软件工程师来说,在更好地开发人工智能系统和远离敏感的训练数据之间存在一个主要的冲突。为了 调和这种冲突,本文提出了一种有效的隐私保护学习范式,其中图像首先通过两种加密策略之一加密为“人类无法察觉, 机器可识别”:(1)随机排列成一组大小相等的补丁;(2)混合图像的子补丁。然后,对视觉转换器进行最小的调整,使其能够学习加密图像上的视觉任务,包括图像分类和对象检测。在ImageNet和COCO上的大量实验表明,所提出的范式与竞争方法的准确率相当。解密加密图像需要解决NP-hard拼图或不适定逆问题,经验表明难以被各种攻击者恢复 ,包括强大的基于视觉变换的攻击者。因此,我们表明,所提出的范式可以确保加密图像在保留机器可识别信息的同时成为人类无法感知的。
贡献总结如下:
- 我们提出了一种有效的保护隐私的学习范式,可以确保加密图像在保留机器可识别信息的同时变得不可感知。
- RS(随机排列)是专用于基于ViT的标准图像分类。通过将基于参考的位置编码替换为原始的位置编码,ViT能够对经过RS加密的图像进行学习。
- 通过进一步设计MI(混合),隐私保护学习范式可以扩展到位置敏感任务,如对象检测,我们只需要调整图像补丁的嵌入方式。
- 大量的实验证明了所提出的隐私保护学习范式的有效性。

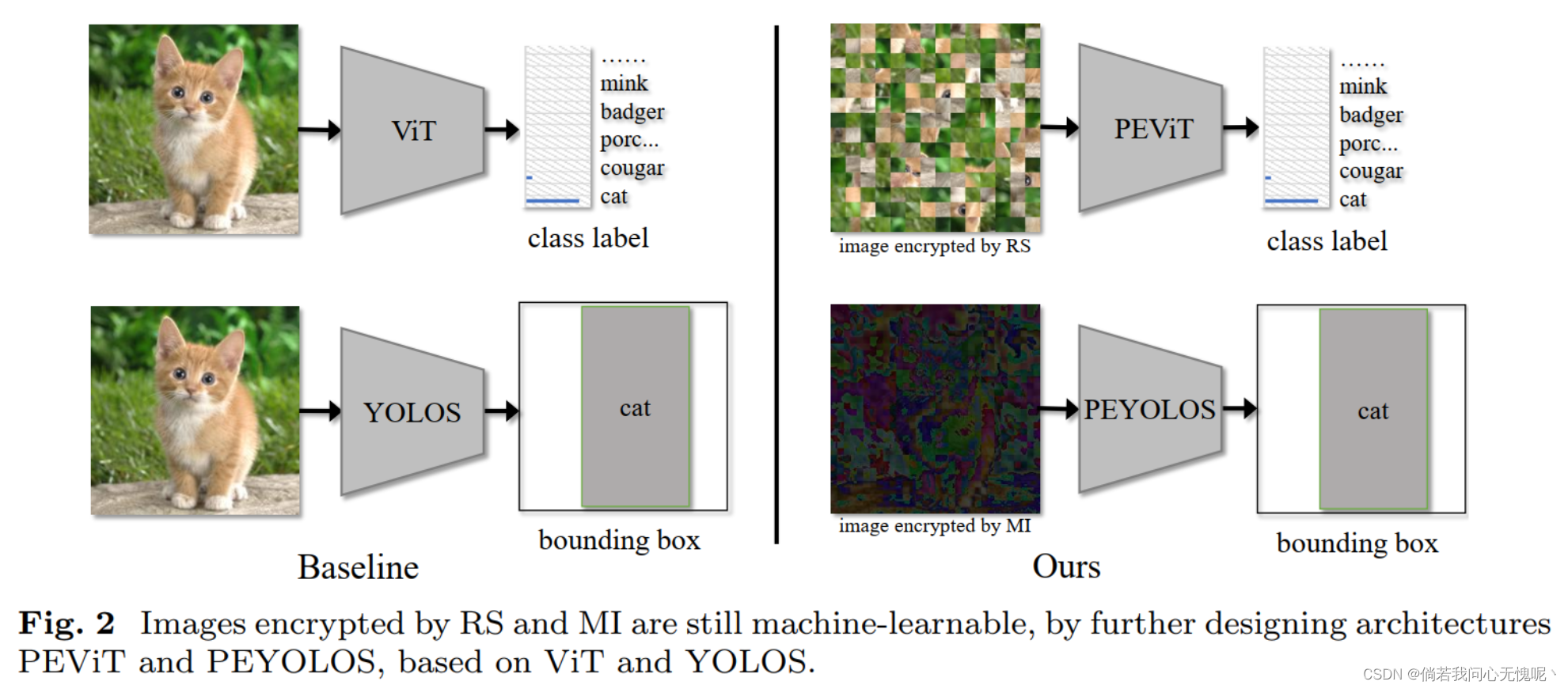
8.2 结论
在本文中,我们提出了一种有效的隐私保护学习范式,该范式可以破坏人类可识别的内容,同时保留机器可学习的信息。我们范例的关键见解是通过置换不变性将加密算法与网络优化解耦。提出了两种加密策略:随机洗牌到一组大小相等的图像补丁和混合图像补丁是具有排列不变性的。通过对ViT和YOLOS 进行最小的调整,它们可以(部分地)实现排列不变性,并且 能够处理加密的图像。在ImageNet和COCO 上的大量实验表明,所提出的范式与竞争对手 方法的准确率相当,同时破坏了人类可识别的内容。