1. Series的运算
适用于NumPy的数组运算也适用于Series。
# 基本算术运算
s + 100
s - 100
s * 100
s / 100
s // 2
s ** 2
s % 2Series之间的运算:
在运算中自动对齐索引;如果索引不对应,则补NaN;Series没有广播机制。
s3 = pd.Series(np.random.randint(10, 100, size=3))
s4 = pd.Series(np.random.randint(10, 100, size=4))
display(s3, s4)
# 对应索引的值进行运算
s3 + s4

注意:要想保留所有的index,则需要使用.add()函数
s3.add(s4, fill_value=0)
0 77.0
1 63.0
2 104.0
3 15.0
dtype: float642. DataFrame的运算
2.1 算术运算
DataFrame和标量之间的运算:
df1 + 100
df1 - 100
df1 * 100
df1 / 100
df1 % 10
df1 ** 2DataFrame之间的运算:
在运算中自动对齐不同索引的数据;如果索引不对应,则补NaN;DataFrame没有广播机制
Series与DataFrame之间的运算:
使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效。
类似于NumPy中二维数组与一维数组的运算,但可能出现NaN。
使用Pandas操作函数:axis=0:以列为单位操作(参数必须是列),对所有列都有效。
axis=1:以行为单位操作(参数必须是行),对所有行都有效。
df1
s = pd.Series([100, 10, 1], index=df1.columns)
s
df1 + s
df1.add(s)
# axis : {0 or 'index', 1 or 'columns'}
df1.add(s, axis='columns') # 列
df1.add(s, axis=1) # 列
df1.add(s, axis=0) # 行
df1.add(s, axis='index') # 行



2.2 逻辑运算
data["open"] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
# 逻辑判断的结果可以作为筛选的依据
data[data["open"] > 23].head()# 完成多个逻辑判断
data[(data["open"] > 23) & (data["open"] < 24)].head()逻辑运算函数:query(expr) expr:查询字符串,通过query使得刚才的过程更加方便简单。
data.query("open<24 & open>23").head()
isin(values) 例如:判断'open'是否为23.53和23.85
# 可以指定值进行一个判断,从而进行筛选操作
data[data["open"].isin([23.53, 23.85])]2.3 统计运算
describe综合分析: 能够直接得出很多统计结果:count 、mean、std、min、max 等
# 计算平均值、标准差、最大值、最小值
data.describe()Numpy当中已经详细介绍,在这里我们演示min(最小值)、max(最大值)、mean(平均值)、
median(中位数)、var(方差)、std(标准差)、mode(众数)结果:

对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行
“index” 需要指定(axis=1) 。
# max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果
data.max(0)
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
my_price_change 3.41
dtype: float64# std()、var()
# 方差
data.var(0)
open 1.545255e+01
high 1.662665e+01
close 1.554572e+01
low 1.437902e+01
volume 5.458124e+09
price_change 8.072595e-01
p_change 1.664394e+01
turnover 4.323800e+00
my_price_change 6.409037e-01
dtype: float64
# 标准差
data.std(0)
open 3.930973
high 4.077578
close 3.942806
low 3.791968
volume 73879.119354
price_change 0.898476
p_change 4.079698
turnover 2.079375
my_price_change 0.800565
dtype: float64median():中位数。中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间
数,取中间两个数的平均值。
df = pd.DataFrame({'COL1' : [2,3,4,5,4,2],
'COL2' : [0,1,2,3,4,2]})
df.median()
COL1 3.5
COL2 2.0
dtype: float64idxmax()、idxmin():
# 求出最大值的位置
data.idxmax(axis=0)
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
my_price_change 2015-07-10
dtype: object
# 求出最小值的位置
data.idxmin(axis=0)
open 2015-03-02
high 2015-03-02
close 2015-09-02
low 2015-03-02
volume 2016-07-06
price_change 2015-06-15
p_change 2015-09-01
turnover 2016-07-06
my_price_change 2015-06-15
dtype: object
累计统计函数:
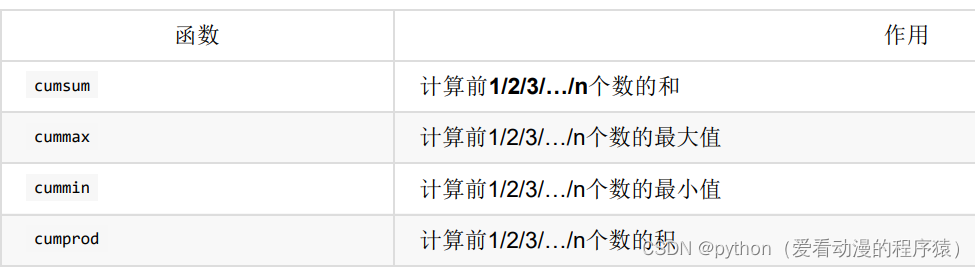
排序:
# 排序之后,进行累计求和
data = data.sort_index()
stock_rise = data['p_change']
stock_rise.cumsum()2.4 自定义运算
apply(func, axis=0)
func:自定义函数;axis=0:默认是列,axis=1为行进行运算;定义一个最大值-最小值的函数
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0)
open 22.74
close 22.85
dtype: float64