前言:
pytorch.nn是专门为神经网络设计的模块化接口. nn构建于autograd之上,可以用来定义和运行神经网络.是所有类的父类.
目录:
- 基本结构
- 常用模块
- container(容器)
- CPU,GPU 部署
- train-test 环境切换
- flatten
- MyLinear
一 基本结构

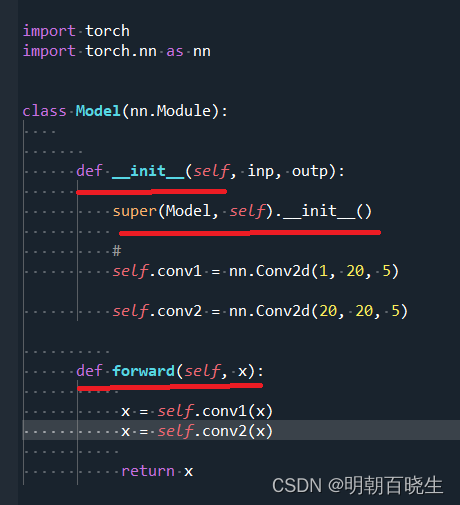
1 继承 nn.Module
2 super
super类的作用是继承的时候,调用含super的各个的基类__init__函数,
如果不使用super,就不会调用这些类的__init__函数,除非显式声明。
而且使用super可以避免基类被重复调用。
3 forward
前向传播
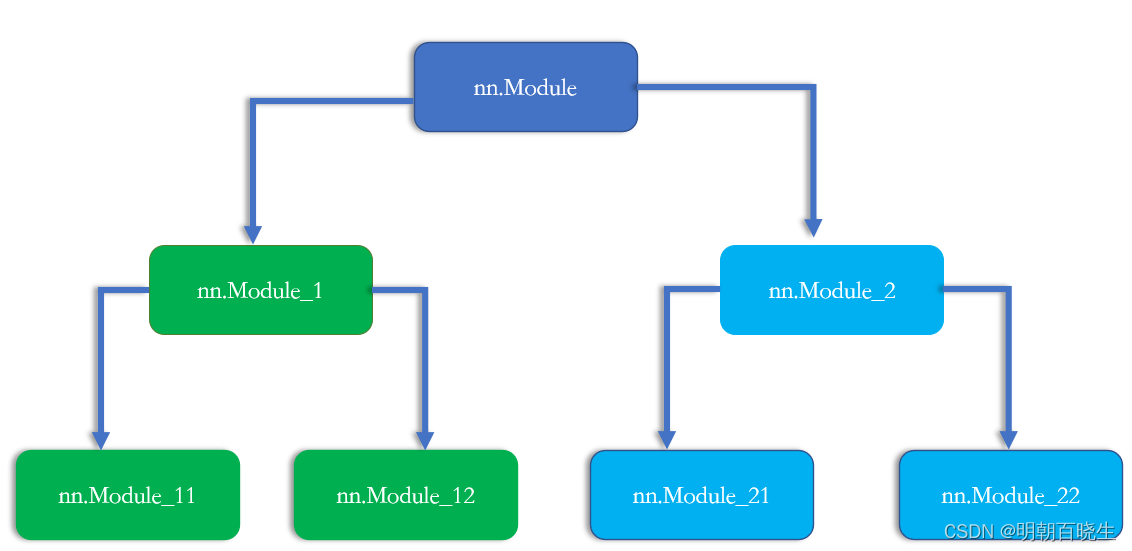
nn.Module nested in Module
可以通过嵌套方式,构建更加复杂的模型
二 常用模块

nn.Module 包含了深度学习里面常用的一些函数
2.1 torch.nn.Linear(in_features, # 输入的神经元个数
out_features, # 输出神经元个数
bias=True # 是否包含偏置)
功能:
2.2 torch.nn.BatchNorm2d(num_features,
eps=1e-05, momentum=0.1,
affine=True,
track_running_stats=True,
device=None, dtype=None)
功能:
对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次。

2.3 nn.Conv2d
torch.nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros',
device=None,
dtype=None)
功能:
图像卷积操作
三 container(容器)
通过容器功能,PyTorch 可以像搭积木一样的方式,组合各种模型.
-
模型容器
作用
nn.Sequential
顺序性,各网络层之间严格按顺序执行,常用于block构建
nn.ModuleList
迭代性,常用于大量重复网构建,通过for循环实现重复构建
nn.ModuleDict
索引性,常用于可选择的网络层
3.1 nn.Sequential
一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。除此之外,一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中。利用nn.Sequential()搭建好模型架构,模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
例子
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 9 13:46:07 2023
@author: chengxf2
"""
import torch
from torch import nn
from collections import OrderedDict
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
常用技巧
list(net.named_parameters())[0]
dict(net.named_parameters()).items()
optimezer = optim.SGD(net.parameters(),lr=1e-3)
3.2 nn.ModuleList
nn.ModuleList,它是一个存储不同module,并自动将每个module的parameters添加到网络之中的容器。但nn.ModuleList并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 9 14:02:48 2023
@author: chengxf2
"""
"""
Created on Fri Jun 9 13:46:07 2023
@author: chengxf2
"""
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(3,4) for i in range(3)] )
def forward(self, x):
for m in self.linears:
x = m(x)
return x
net = MyNet()
print("\n net ")
print(net)
print("\n parameters ")
print(list(net.parameters()))
输出:通过ModuleList 构建了一个小模型,该模型由三个 线性层 组成
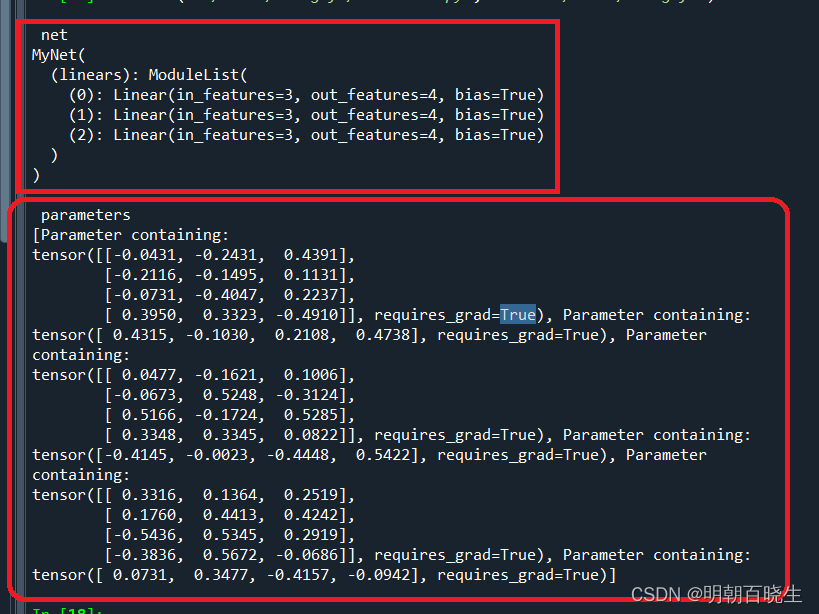
如下 相对于Sequential, ModuleList 模块之间并没有什么先后顺序可言
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 9 14:02:48 2023
@author: chengxf2
"""
"""
Created on Fri Jun 9 13:46:07 2023
@author: chengxf2
"""
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10,20), nn.Linear(20,30), nn.Linear(5,10)])
def forward(self, x):
x = self.linears[2](x)
x = self.linears[0](x)
x = self.linears[1](x)
return x
net = MyNet()
print(MyNet)
# net3(
# (linears): ModuleList(
# (0): Linear(in_features=10, out_features=20, bias=True)
# (1): Linear(in_features=20, out_features=30, bias=True)
# (2): Linear(in_features=5, out_features=10, bias=True)
# )
# )
input = torch.randn(32, 5)
print(net(input).shape)
# torch.Size([32, 30])
3.3 nn.ModuleDict
将所有的子模块放到一个字典中。
ModuleDict 可以像常规 Python 字典一样进行索引,但它包含的模块已正确注册,所有 Module 方法都可以看到。ModuleDict 是一个有序字典。
参数:
modules (iterable, optional)– 一个(string: module)映射(字典)或者可迭代的键值对。
方法:
clear():清空ModuleDict
• items():返回可迭代的键值对(key-value pairs)
• keys():返回字典的键(key)
• values():返回字典的值(value)
• pop():返回一对键值,并从字典中删除
例
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 9 14:02:48 2023
@author: chengxf2
"""
"""
Created on Fri Jun 9 13:46:07 2023
@author: chengxf2
"""
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(in_channels=3,out_channels= 10, kernel_size=3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict([
['relu', nn.LeakyReLU()],
['prelu', nn.PReLU()]
])
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = MyModule()
img = torch.randn((1, 3, 8, 8))
output = net(img, 'conv', 'relu')
print(output.shape)
一个完整的例子
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 12 14:17:19 2023
@author: chengxf2
"""
import torch
import torch.nn as nn
class BasicNet(nn.Module):
def __init__(self):
super(BasicNet,self).__init__()
self.net = nn.Linear(in_features =4, out_features=3)
def forward(self,x):
out = self.net(x)
return out
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Sequential(BasicNet(),
nn.ReLU(),
nn.Linear(in_features=3, out_features=2)
)
def forward(self,x):
out = self.net(x)
return out
if __name__ == "__main__":
data = torch.rand((2,4))
model = Net()
out = model(data)
print(out)
parame = list(model.parameters())
print("\n parameters \n",parame)
name_parame = list(model.named_parameters())
print("\n name_parame \n",name_parame)四 CPU,GPU 部署

五 save and load
为了防止意外情况,我们每训训练一些次数后,需要把当前的参数
保存到本地磁盘中,后面再次训练后,可以通过磁盘文件直接加载
#保存已经训练好的参数到 net.mdl
torch.save(net.state_dict(), 'net.mdl')
#模型开始的时候加载,通过net.mdl 里面的值初始化网络参数
net.load_state_dict(torch.load('net.mdl'))5.1 通过torch.save保存模型,
torch.save函数将序列化的对象保存到磁盘。此函数使用Python的pickle进行序列化。通过pickle可以保存各种对象的模型、张量和字典。
5.2 torch.load加载模型。
torch.save和torch.load函数的实现在torch/serialization.py文件中。
torch.load函数使用pickle的unpickling将pickle对象文件反序列化到内存中
torch.nn.Module的state_dict函数:
在PyTorch中,torch.nn.Module模型的可学习参数(即weights和biases)包含在模型的参数中(通过model.parameters函数访问)。
state_dict只是一个Python字典对象,它将每一层映射到其参数张量(tensor)。
注意:只有具有可学习参数的层(卷积层,线性层等)和注册缓冲区(batchnorm’s running_mean)在模型的state_dict中有条目( Note that only layers with learnable parameters (convolutional layers, linear layers, etc.) and registered buffers (batchnorm’s running_mean) have entries in the model’s state_dict)。
优化器对象(torch.optim)也有一个state_dict,其中包含有关优化器状态的信息,以及使用的超参数。因为state_dict对象是Python字典,所以它们可以很容易地保存、更新、更改和恢复。
六 train-test 环境切换
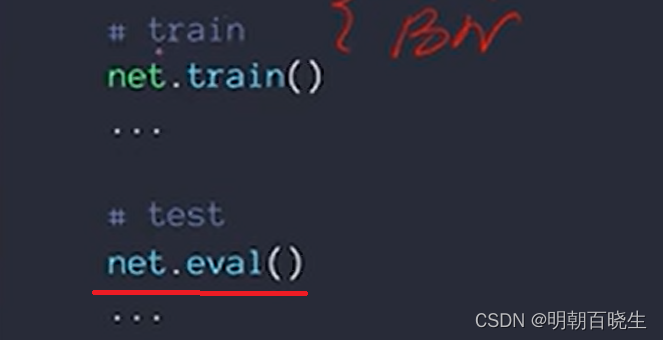
train 结束后,test 之前 必须加上 torch.eval
model的eval方法主要是针对某些在train和predict两个阶段会有不同参数的层。
比如Dropout层和BN层
Dropout:
train阶段: 随机选择神经元,
test 阶段 : 使用全部神经元并且要乘一个补偿系数
BN层
输出Y与输入X之间的关系是:Y = (X - running_mean) / sqrt(running_var + eps) * gamma + beta,其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias),
train 阶段 :训练时通过反向传播更新;而running_mean、running_var则是在前向时先由X计算出mean和var,再由mean和var以动量momentum来更新running_mean和running_var。所以在训练阶段,running_mean和running_var在每次前向时更新一次;
test 阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变。
六 flatten
我们在通过某些网络后得到的张量需要打平,得到一个[1,n] 维的张量, 输入到全连接网络里面去训练.
可以通过flatten 处理

实现原理如下:
假设类型为 torch.tensor 的张量 a 的形状如下所示:(2,4,3,5,6),则 torch.flatten(a, 1, 3).shape 的结果为 (2, 60, 6)。 将索引为 start_dim 和 end_dim 之间(包括该位置)的数量相乘,其余位置不变。
也可以通过如下方式,进行Flatten.
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 9 14:59:06 2023
@author: chengxf2
"""
import torch
from torch import nn
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, input):
return input.view(input.size(0),-1) #[b,n]
class TestNet(nn.Module):
def __init__(self):
super(TestNet, self).__init__()
self.net = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3),
nn.MaxPool2d(2,2),
Flatten(),
nn.Linear(in_features=1*14*14, out_features=10))
def forward(self, x):
return self.net(x)
七 MyLinear

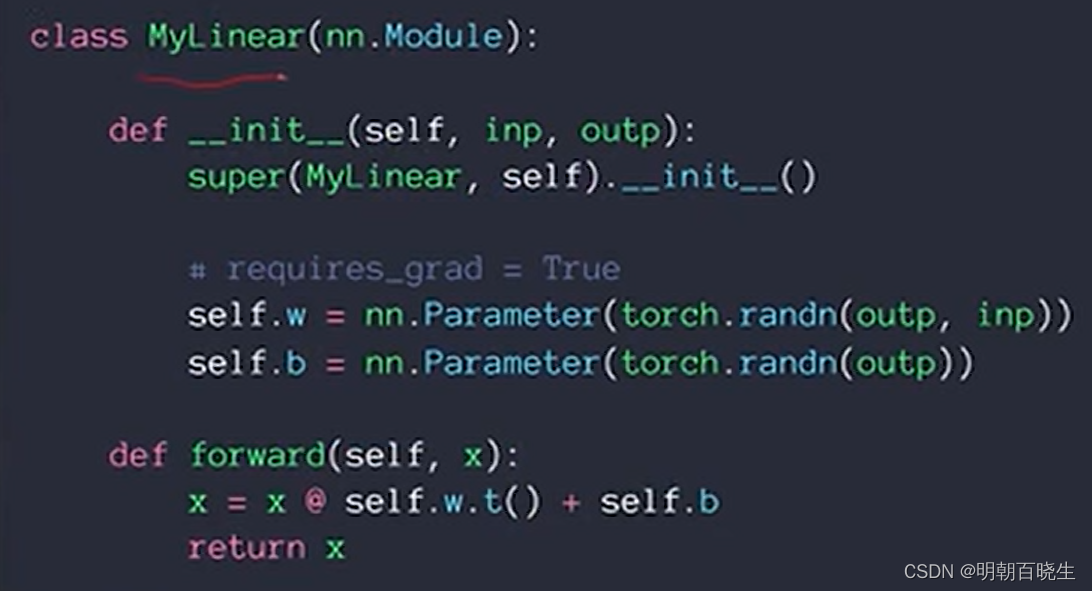
当自己定义某些张量时候,必须加载到nn.Parameter方法中管理,会自动的加上reuire_grad =True属性,可以被SGD 优化。
如果不写nn.Parameter ,必须加上require_grad=True,但是管理不方便.
原文链接:
参考:
pytorch小记:nn.ModuleList和nn.Sequential的用法以及区别_慕思侣的博客-CSDN博客
https://blog.csdn.net/fengbingchun/article/details/125706670