独家揭秘:Kotlin K2编译器的前世今生
也许您已经观看了最近的 KotlinConf 2023 主题演讲,关于 K2 编译器的更新。什么是 K2 编译器?
在搞清楚这个问题之前,我们需要了解Kotlin 使用的不同种类的编译器及其差异,以及编译过程中可能发生的不同种类的数据转换的简要概述。
基础知识
源代码通过Kotlin编译器提交,将可读的人类源代码转换为针对任何指定机器的可执行机器代码。
如果我们粗略地过度简化编译器,我们可以将编译器视为执行两个任务:编译和降级。编译将一种数据格式更改为另一种数据格式,而降级通常简化/优化现有的数据格式。

当 Kotlin 代码编译时,会选择一组配置来运行 Kotlin 编译器,例如决定在哪个环境上运行(如 CLI、Analysis API、处理器选项),选择要连接到编译器的插件,以及选择前端和后端。
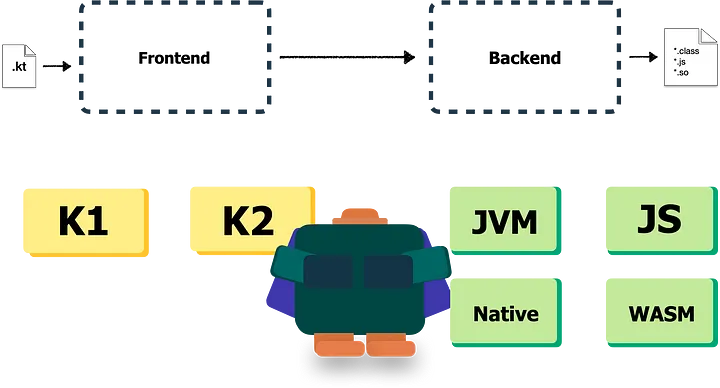
Kotlin编译器有两个前端:K1和K2,以及四个后端:JVM、JS、本地和实验性的WASM。
K1/K2前端
Kotlin编译器有两个前端:K1前端(在源代码中用Fe10-表示)和K2前端(有时称为FIR前端,在源代码中有时用Fir-表示)。选择前端决定向后端发送哪些信息以进行IR生成和后续目标生成。
K1和K2前端在开始阶段共享类似的阶段,只不过FIR(前端中间表示)前端在将转换后的代码发送到后端之前,会引入一种附加的数据格式 —— 后端将立即将该数据格式更改为IR(中间表示)以进行进一步处理。
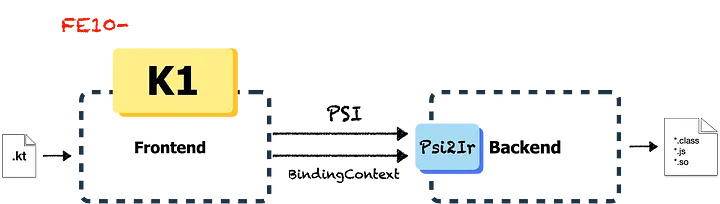
K1前端
K1前端(Fe10-)接受人类可读的源代码,将文本分解为词法令牌,创建PSI树,并进行解析来创建附加的数据结构,如描述符和BindingContext,然后将其发送到后端。

PSI代表“程序结构接口”,它是在IntelliJ中的层,有助于解析文件,并在编译后创建语法/语义代码模型。
对于K1前端,解析在PSI树上执行以生成描述符和BindingContext,它们全部被发送到后端,以转换为IR。
- 根据元素类型,描述符可能包含上下文,作用域,包含信息,覆盖,伴随对象等等。
BindingContext是一个大映射,其中PSI是映射到描述符和其他信息的关键字,以后可用于对代码进行推断。
然而,像这样发送PSI和BindingContext已经导致编译器性能问题。
根据Dmitriy Novozhilov在Kotlinlang的Slack中的解释,解析结果也存储在BindingContext中,因此CPU无法快速缓存对象。所有描述符都是惰性的,这导致编译器在代码不同部分之间跳跃,杀死了许多JIT优化。
K2(FIR)前端编译器
旨在提高编译器性能。JetBrains创建了这个新的编译器前端(有时也称为FIR前端),来替换现有的前端编译器。它不仅仅是将PSI和BindingContext发送到前端,还会生成额外的数据格式,以卸载后端本来要完成的一部分工作。
K2前端将原始PSI作为输入,生成原始FIR,并在不同的阶段对其进行转换,填充语义信息树。然后,解析后的FIR将被发送到后端。
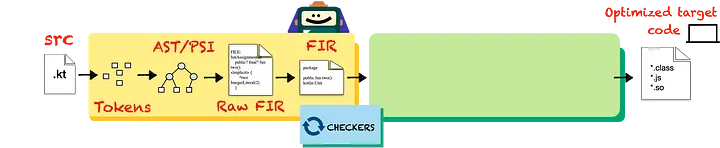
FIR是一个可变树,由解析器的结果——生成的PSI树建立而来。建立原始FIR之后,可以通过多个处理器进行操作,这些处理器将解析代码并代表编译器管道的不同阶段。
最后,会运行一个检查器阶段,它会使用FIR并报告警告和错误的不同诊断信息。如果有错误,则编译会停止,因为没有必要将有错误的代码发送到后端。如果没有错误,解析后的FIR将转换为后端IR。

Kotlin编译器后端
我们已经进入后端了!记住,我们可以选择4个后端:JVM、JS、Native和新的实验性WASM。本文将讨论更稳定的后端——JVM、JS和Native。
Sletvana Isavoka的演讲《关于新的Kotlin K2编译器,每个人都必须知道的事情》最好地解释了后端的工作原理:
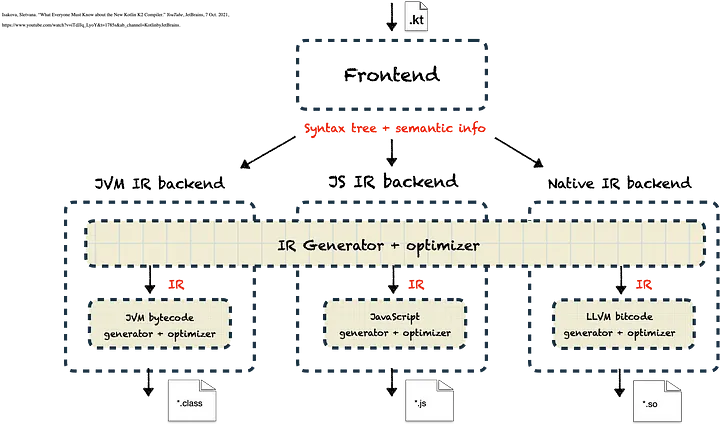
需要注意的重要事项是,无论选择哪个后端,IR生成器和优化器始终是后端处理的相同起点。然后选择的配置将运行所需的代码生成模式:
- JVM IR 后端使用 JVM 字节码生成器 + 优化器 来生成 .class 文件
- JS IR 后端使用 JavaScript 生成器 + 优化器 来生成 .js 文件
- Native IR 后端使用 LLVM 位码生成器 + 优化器 来生成 .so 文件
假设我们将之前的 K2 示例发送到后端,我们可以继续使用这个示例作为数据格式:

前端:源代码 → 令牌 → 抽象语法树/程序结构接口 → 原始 FIR → FIR | 后端:IR → 降级的IR → 目标代码
发送已解决的FIR回到后端后,FIR被转换为IR,即中间表示形式。IR作为CPU级架构的另一种抽象表示形式生成。对IR进行控制流和调用堆栈的分析,并执行机器相关的优化以创建Lowered IR。通常,这意味着简化操作(即3^2可能变为3*3),提高生成的机器码的性能和质量,并做出资源和存储决策。
最终生成目标代码,并对生成的目标代码进行优化,以便将其优化后的目标代码发送到任何机器以执行。这是一个超高层次的概述,但我希望这篇文章对我们继续深入学习Kotlin编译器的速成课程有所帮助!