告警效果
一、编写alertmanager.yml
创建个目录存放alertmanager.yml文件
mkdir -p /data/alertmanager
vi alertmanager.yml
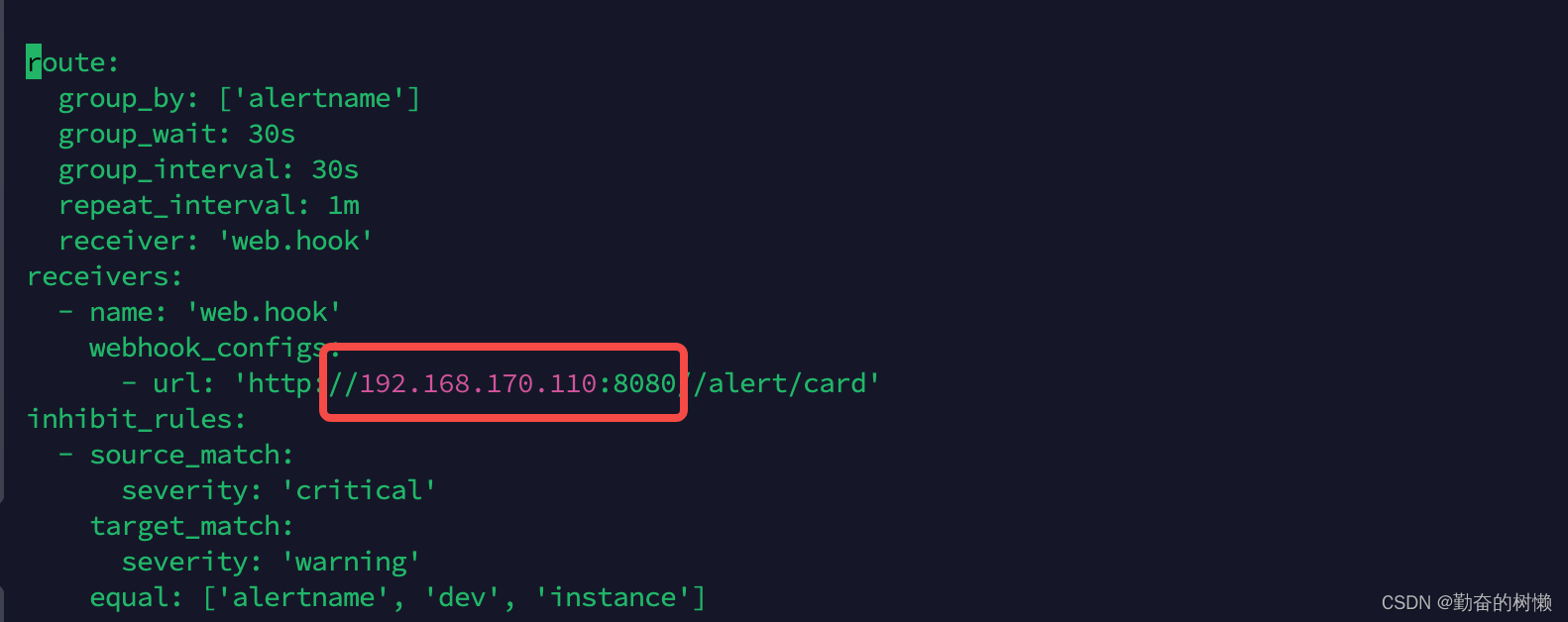
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 30s
repeat_interval: 1m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://192.168.170.110:8080//alert/card'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
挂载存放配置文件的目录
映射端口
docker run -d -p 9093:9093 --name=alertmanager --restart=always \
-v /data/alertmanager/:/etc/alertmanager/ \
prom/alertmanager
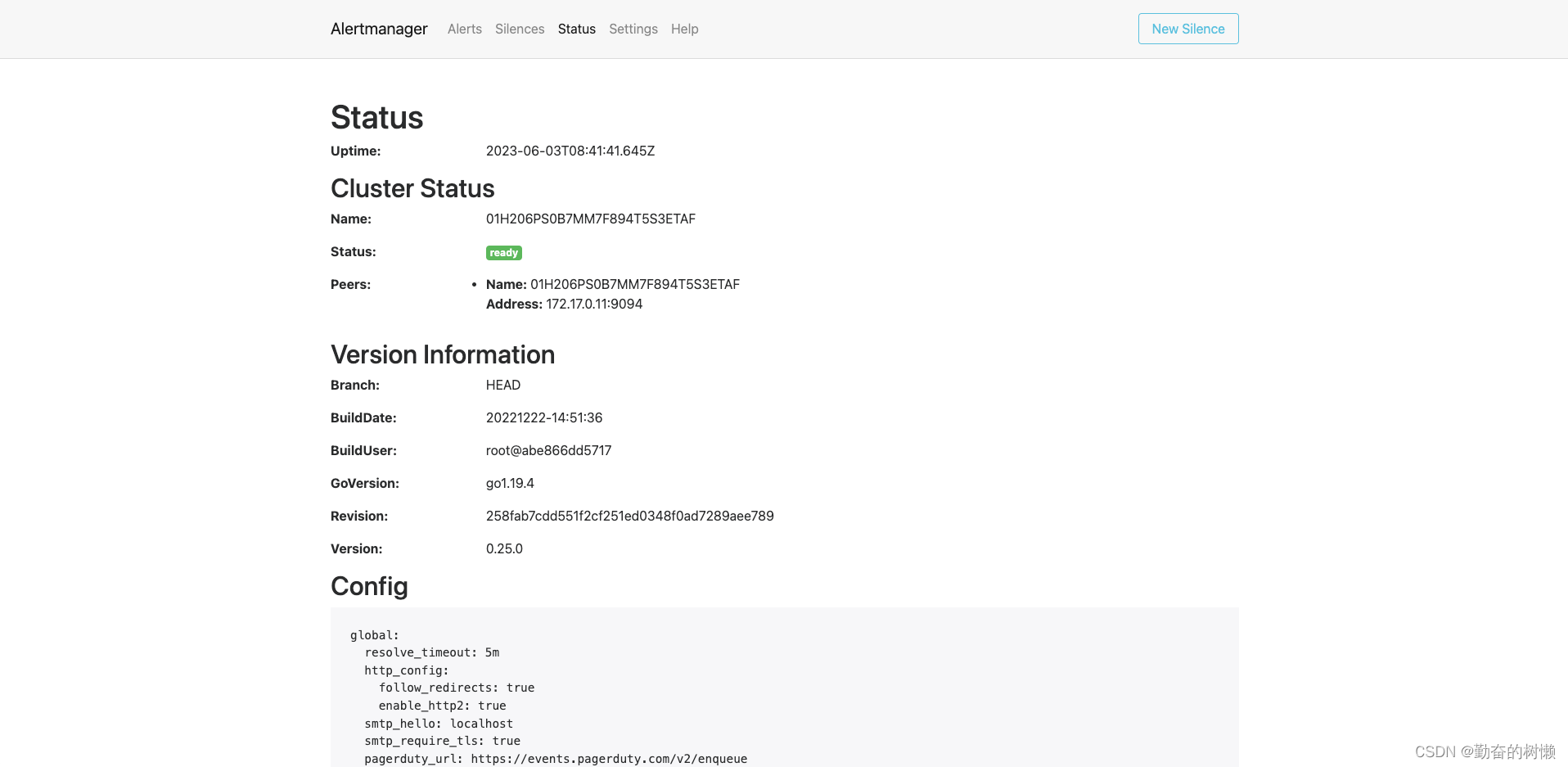
http://服务器地址:9093访问alertmanager web界面,默认首页就是显示是否检测到告警,可以查看状态和配置
二、修改prometheus配置
vi /data/prometheus/prometheus.yml
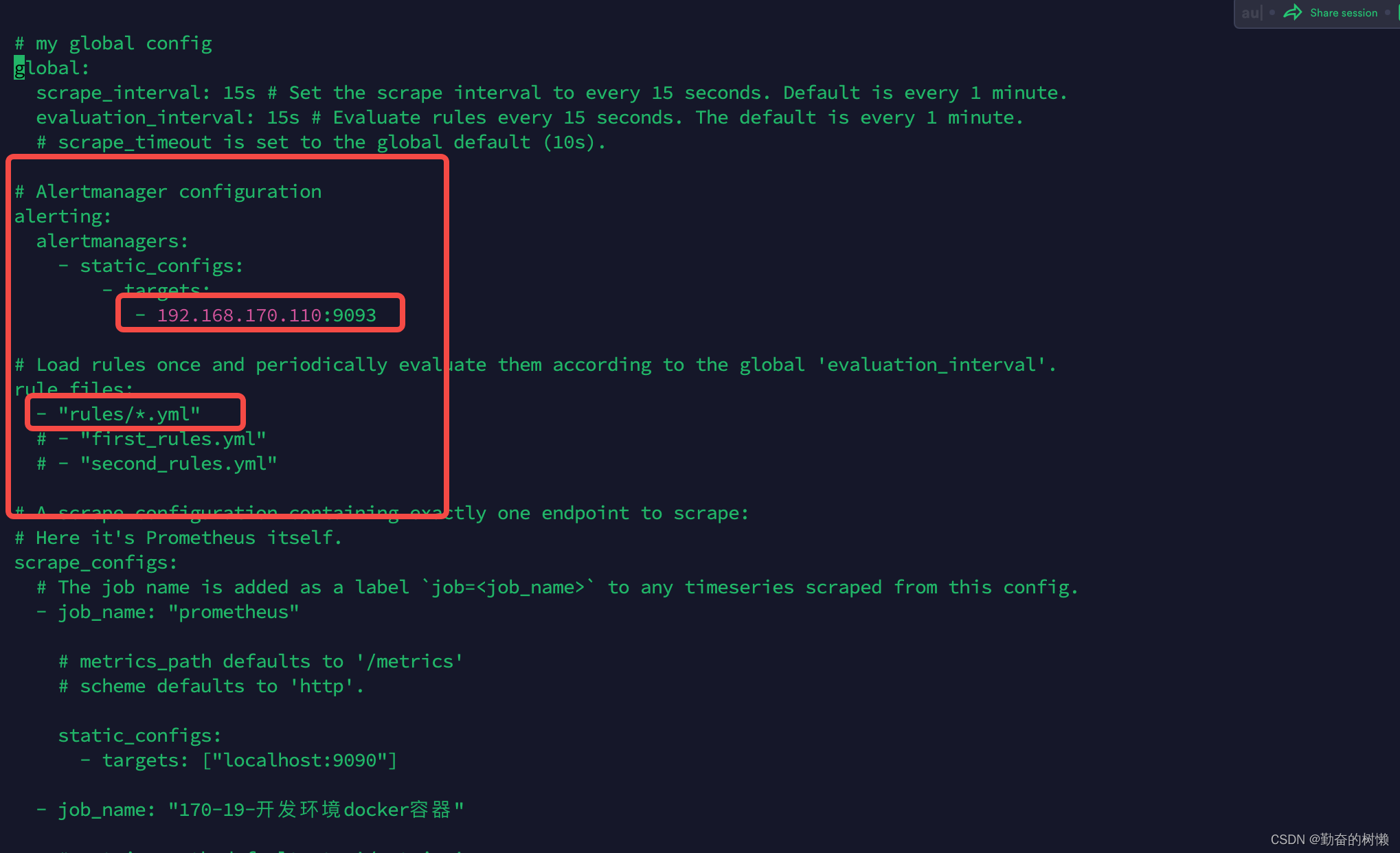
将注释去掉,启用Alertmanager
指定你部署的Alertmanager地址:端口
还有指定你存放的告警配置文件目录,这里指定rules下所有的yml配置文件
mkdir -p /data/prometheus/rules
注意:创建的rules目录是和prometheus.yml配置处于同一级,当然可以根据自身存放的位置修改rule_files指定即可。
三、飞书告警推送
编写告警规则
前面指定了告警目录位置,告警规则文件名称任意放在rules下的所有yml文件都会生效
vi /data/prometheus/rules/alert.yml
详细如下
# 相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)
groups:
# 组名。报警规则组名称
- name: 内存预警
rules:
- alert: 内存使用率预警
# expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 >= 80
# for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
for: 40s # for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。(for 表示告警持续的时长,若持续时长小于该时间就不发给alertmanager了,大于该时间再发。for的值不要小于prometheus中的scrape_interval,例如scrape_interval为30s,for为15s,如果触发告警规则,则再经过for时长后也一定会告警,这是因为最新的度量指标还没有拉取,在15s时仍会用原来值进行计算。另外,要注意的是只有在第一次触发告警时才会等待(for)时长。)
# labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
labels:
# severity: 指定告警级别。有三种等级,分别为 warning, critical 和 emergency 。严重等级依次递增。
severity: critical
# annotations: 附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
annotations:
title: "内存使用率预警"
serviceName: "{{ $labels.job }}"
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
btn: "点击查看详情 :撇嘴:"
link: "http://escctv.hkeasyspeed.com/d/ov0oEgdik/linux?orgId=1&refresh=5s&var-host=192.168.170.110:9100&var-job=${serviceName}"
template: "**${serviceName}**(${instance}) 内存使用率已经超过阈值 **80%**, 请及时处理!\n\n当前值: ${value}%"
- name: 磁盘预警
rules:
- alert: 磁盘使用率预警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 >= 80
for: 1m
labels:
severity: critical
annotations:
title: "磁盘使用率预警"
serviceName: "{{ $labels.job }}"
instance: "{{ $labels.instance }}"
# mountpoint: "{{ $labels.mountpoint }}"
value: "{{ $value }}"
btn: "点击查看详情 :撇嘴:"
link: "http://escctv.hkeasyspeed.com/d/ov0oEgdik/linux?orgId=1&refresh=5s&var-host=192.168.170.110:9100&var-job=${serviceName}"
template: "**${serviceName}**(${instance}) 服务器磁盘设备使用率超过 **70%**, 请及时处理!\n\n当前值: ${value}%!"
- name: 实例存活报警
rules:
- alert: 实例存活报警
expr: up == 0
for: 30s
labels:
severity: emergency
annotations:
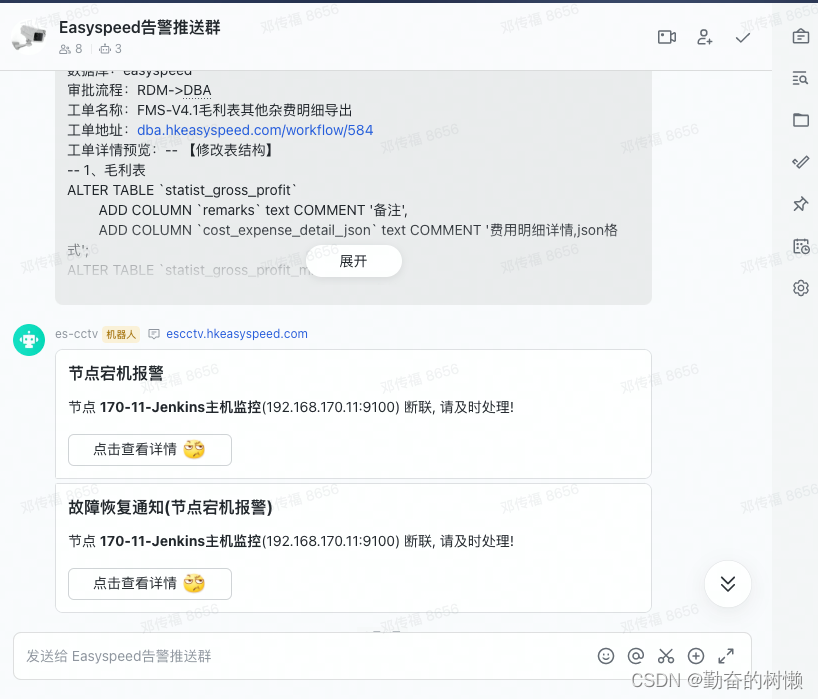
title: "节点宕机报警"
serviceName: "{{ $labels.job }}"
instance: "{{ $labels.instance }}"
btn: "点击查看详情 :撇嘴:"
link: "http://192.168.170.110:9090/targets"
template: "节点 **${serviceName}**(${instance}) 断联, 请及时处理!"
启用飞书告警容器
使用javafamily在docker公共仓库开源分享的prometheus-webhook-feishu
FEISHU_TOKEN:token是webhook最后那一段值
docker run -d --name prom-alert-feishu -p 8080:8080 --restart=always \
-e FEISHU_TOKEN=xxxxxxxxxxxxxx \
javafamily/prometheus-webhook-feishu:2.3.2-SNAPSHOT
注意:确认你的alertmanager配置的webhook地址是你部署prometheus-webhook-feishu的地址和端口(/data/alertmanager/alertmanager.yml)