说明:
1. 本文基于Spring-Framework 5.1.x版本讲解
2. 建议读者对创建对象部分源码有一定了解
概述
这篇讲讲Spring循环依赖的问题,网上讲循环依赖的帖子太多太多了,相信很多人也多多少少了解一点,那我还是把这个问题自己梳理一遍,主要是基于以下出发点:
1. Spring到底如何解决的循环依赖问题,有没有’黑科技‘;
2. 有时项目会因为循环依赖问题导致启动失败,由于不了解其机制,排查耗费时间
3. 网上众说风云,没有形成自己的思考
还有其他文章说Spring使用三级缓存是为了解决循环依赖问题,为了解决代理下的循环依赖问题? 那废话不多说,直接开始吧
循环依赖简介
循环依赖的含义: BeanA依赖BeanB,BeanB又依赖BeanA , 如下图
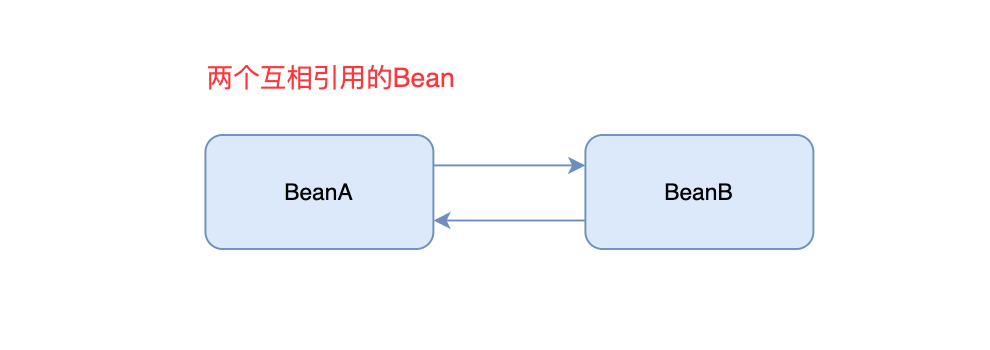
这就是循环依赖, 我们来分析下会有什么问题?
1. 实例化BeanA
2. BeanA在属性注入阶段从容器里面找BeanB
3. 如果BeanB已经在容器里面创建好,那万事大吉,没循环依赖的问题
4. 如果BeanB还没有在容器里面创建好,这时候Spring会创建BeanB
5. 创建BeanB的时候又发现依赖BeanA,但此时BeanA也没有创建完,在没有开启循环依赖开关的情况下就会报错:Requested bean is currently in creation: Is there an unresolvable circular reference?
从软件代码分层结构来讲,如果分层合理,这种情况一般可以避免掉,但是避免不了同一个层次中的Bean互相引用,好那既然循环依赖肯定会出现,我们自己先来思考下,如果是我们自己写一个IOC容器,这个问题如何解决?
如何解决循环依赖?
从上面的4步可以看出来,问题所在就是BeanB在创建过程中,无法找到正在创建中的BeanA,那我们是不是可以找一个地方把正在创建的BeanA(为了行文方便,把Bean正在创建中的状态称为半状态)先给保存起来,等BeanB用到的时候赋值给它不就行了,这时候步骤如下:
1. 实例化BeanA
2. BeanA在属性注入之前先把自己放到一个Map里面(此时BeanA为半状态)
3. BeanA在属性注入阶段从容器里面找BeanB
4. 如果BeanB还没有在容器里面创建好,这时候Spring会创建BeanB
5. 创建BeanB的时候又发现依赖BeanA,由于BeanA已经在Map里面了(虽然是半状态,但不影响最终使用,反正现在又不暴露给用户使用) ,所以注入成功,BeanB创建完成
6. 由于BeanB已创建完成,意味着BeanA注入BeanB成功,此时从Map中移除BeanA的半状态
7. 容器初始化完成
到这里有什么大的问题没有? 其实是没有的,Bean确实会创建成功 , 容器可以正常启动完成。 那我们在来看下启用动态代理情况下,使用一个Map(一级缓存)会不会有问题? 为了说明简单,我们只生成BeanA的代理对象BeanA_Proxy,BeanB无需创建:
1. 实例化BeanA,并生成BeanA的代理对象BeanA_Proxy ,此时上下文中有BeanA、BeanA_Proxy两个对象
2. BeanA在属性注入之前先把代理对象BeanA_Proxy放到Map里面
3. BeanA在属性注入阶段从容器里面找BeanB
4. 如果BeanB还没有在容器里面创建好,这时候Spring会创建BeanB
5. 创建BeanB的时候又发现依赖BeanA,由于BeanA的代理对象BeanA_Proxy已经在Map里面了,所以把BeanA_Proxy注入BeanB,此时BeanB创建完成
6. 由于BeanB已创建完成,意味着BeanA注入BeanB成功,此时从Map中移除BeanA_Proxy
7. 容器把BeanA_Proxy暴露给用户使用,并初始化完成
从上面可以看出,即使使用代理的情况下,使用一个Map(一级缓存)来解决循环依赖问题也是可以的。
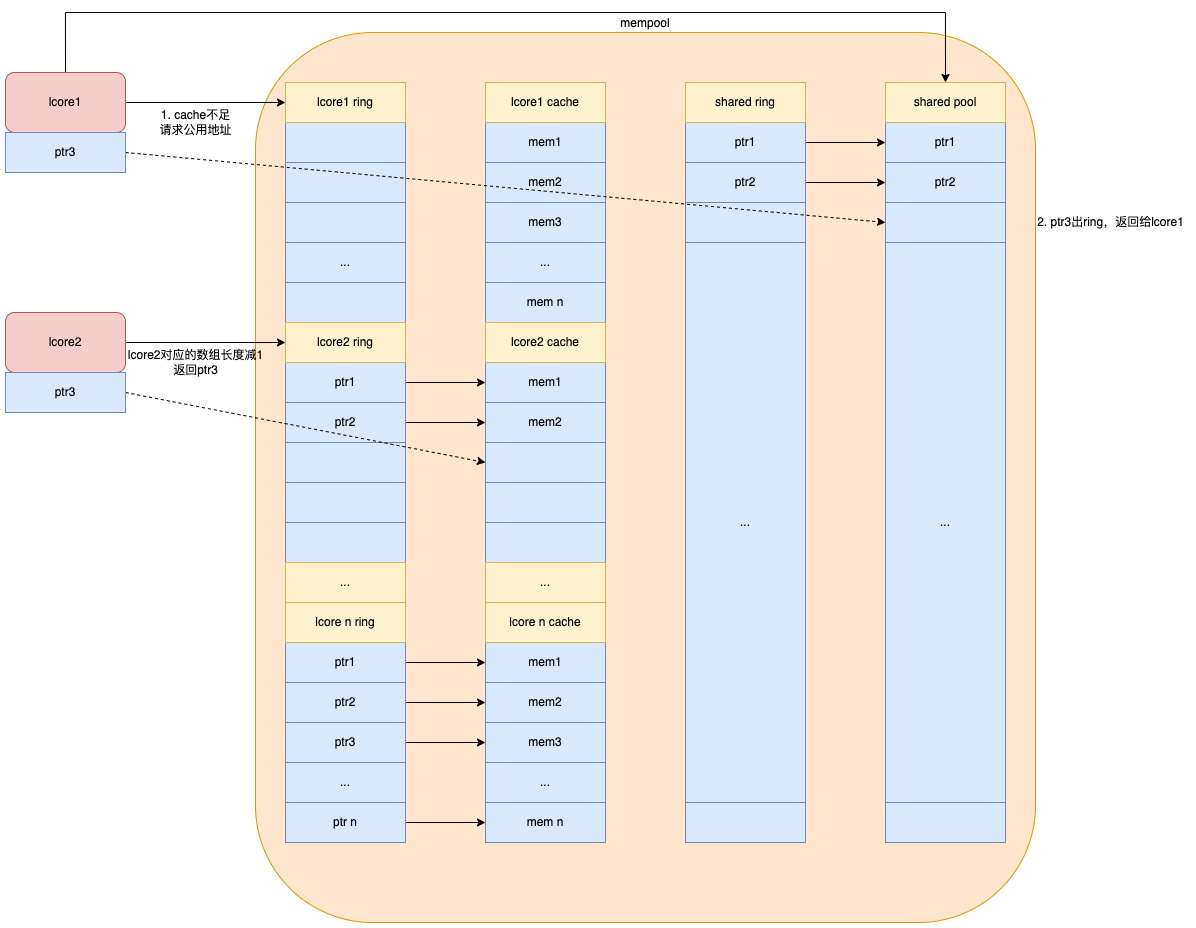
为什么是三级缓存?
从上面可以看出,把半状态的Bean或者代理对象无脑的放入一级缓存之后,确实可以解决循环依赖的问题,那为什么Spring要使用三级缓存来解决这个问题呢? 让我们来回忆下Bean的整个生命周期: 1. 实例化Bean 2. 属性注入 3. 初始化Bean 。 这是创建一个Bean必经的几个步骤,而我们上面是为了解决循环依赖问题而强行加了一个往一级缓存里面放对象的步骤,而对于不存在循环依赖的对象,这一步无疑是多余的;还有另外一个问题: 把半状态的Bean和创建完成的Bean对象放入同一个缓存里面也不太好管理,违背单一职能原则
所以这里我们要解决2个问题:
1. 解决循环依赖的代码(也就说生成半状态对象的过程)不能放到创建Bean的主流程中;
2. 半状态的对象需要与创建完成的对象所在的容器隔离开。
为了解决问题一我们可以考虑在检测到有循环依赖的时候才把半状态对象暴露给BeanB使用,就是说说BeanB发现BeanA正在创建的时候,在把半状态BeanA赋值给BeanB。 但是问题又来了:这个半对象BeanA哪来的? 谁创建出来的? 这无疑变成了蛋和鸡的问题, 所以我们还是要在刚开始创建BeanA的时候以最小的代价(这里指执行时间最短) 把半对象给保存起来,BeanB检测到循环依赖的时候,在把BeanA给取出来。那Spring其实就是使用另一个Map保存匿名函数的方式来解决这个问题的, 因为你要考虑直接暴露BeanA的代价(比如说暴露给BeanB是一个代理对象,那要考虑创建BeanA代理对象的执行成本)。 这里我们简单贴下Spring的源码:
/** * 实际生成Bean的核心方法 */protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
// 省略上下文中其他不重要的代码
// 这里注册一个匿名函数,把匿名函数放到一个临时缓存里面(其实就是所谓的三级缓存) addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}
/** * 作用: 获取提前要暴露给其他Bean的引用 * 这个方法只有在Spring检测到有循环引用的情况下才会调进来 */protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 获取要提前暴露的对象,这里有可能产生代理对象以及其他非入参Bean的对象 exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName); } } return exposedObject;}
好,看到这里其实我们已经顺便把上述第二个问题也一起解决掉了,因为保存匿名函数的Map和最终保存对象实例的Map不是同一个,而且保存匿名函数的Map在解决完循环依赖问题之后会清空掉,这样我们就可以以延迟加载的方式解决掉循环依赖的问题。 那在BeanA会产生代理的情况下会不会有问题??? 请你自己思考下
但这里还有一个问题,考虑下面一种场景:

BeanA与BeanB、BeanC的关系是互相引用, 套用我们上面的理论, 在创建BeanA的主流程中我们只是插入了一个获取半状态对象的匿名函数,而不是要暴露给外部的最终对象,当BeanC也需要注入BeanA的时候,还是要执行一次匿名函数来获取最终暴露的对象,这里有两个问题:
1. 匿名函数重复执行,其实是没有必要的。
2. 更为严重的是,有可能每次调用函数返回的是不同的对象,这样会导致注入给BeanB和BeanC的对象不一致,这就是大问题了。 (那有人会问如果保证获取最终暴露对象的接口SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference中返回同一个对象不就行了? 站在解决问题的角度确实是这样的,但是站在容器的角度来讲就不一样了,接口只是一个拓展点,他的执行逻辑是不可控的,所以还是要在容器级别来解决这个问题)
为了解决以上两个问题,Spring采用了第三个缓存,把已经暴露出去的对象给缓存起来,这样问题就完美解决以上两个问题。
getEarlyBeanReference
在上面我们已经解释了为什么要用三级缓存来解决循环依赖的问题,我们在简单说下SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference接口,其实这个接口没有什么高深的地方,只是为了获取循环依赖下需要提前暴露给其他Bean的对象,这里要注意一下:仅仅在检测到有循环依赖的情况下才会调进来,我们看下接口定义
/** * Extension of the {@link InstantiationAwareBeanPostProcessor} interface, * adding a callback for predicting the eventual type of a processed bean. * * <p><b>NOTE:</b> This interface is a special purpose interface, mainly for * internal use within the framework. In general, application-provided * post-processors should simply implement the plain {@link BeanPostProcessor} * interface or derive from the {@link InstantiationAwareBeanPostProcessorAdapter} * class. New methods might be added to this interface even in point releases. * * @author Juergen Hoeller * @since 2.0.3 * @see InstantiationAwareBeanPostProcessorAdapter */public interface SmartInstantiationAwareBeanPostProcessor extends InstantiationAwareBeanPostProcessor { default Object getEarlyBeanReference(Object bean, String beanName) throws BeansException { return bean; }}
从类注释中”This interface is a special purpose interface, mainly for internal use within the framework“可以看到,这个接口仅仅是Spring内部为了解决某些问题提供的接口,并不希望暴露给上层用户使用,所以我们在实际工作中一般用不到的
但是我们要特别注意一个坑: 我们知道在Bean后置处理接口BeanPostProcessor中也有可能返回代理对象,如果这里返回的对象和循环依赖暴露出去的对象不一致的话就会报以下错误:
Error creating bean with name 'serviceA': Bean with name 'serviceA' has been injected into other beans [serviceB] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'serviceA': Bean with name 'serviceA' has been injected into other beans [serviceB] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example. at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:622) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:866) at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:878) at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:550) at test.circle_ref.CircleRefTests.run(CircleRefTests.java:13)
从逻辑上来讲报错也是合理的,因为既然提前暴露出去的Bean,像是一种承诺,后续就不能修改了,修改意味着Spring容器中Bean的’状态‘是不一致的。 所以在有循环依赖的情况下,一定要保证getEarlyBeanReference和BeanPostProcessor 返回的Bean是同一个。
小结
本篇文章介绍了Spring为什么用三级缓存才解决循环依赖问题,并且介绍了SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference接口的含义以及在实际情况中可能遇到的坑,那我们总结下Spring的三级缓存的作用:
一级缓存: 保存已经创建完的Bean对象,我们常用的BeanFactory#getBean方法就是从这里获取;
二级缓存: 缓存在循环依赖中暴露给其他Bean的半状态对象,防止注入对象不一致的问题;
三级缓存: 缓存获取提前暴露的Bean的匿名函数 ,为的是以最小的代价减少对Spring创建对象主干流程的影响
关于循环依赖的问题就介绍到这,不得不说Spring考虑问题真是的非常全面,设计相当合理。如有疑问,欢迎交流

git已merge到master分支代码且被同事代码覆盖如何回退](https://img-blog.csdnimg.cn/e0c0c948ce6d400d89a3fb15eae00e8e.png)