bigquant选股模型一般常见的有七种,即多因子模型、风格轮动模型、行业轮动模型、资金流模型、动量反转模型、一致预期模型、趋势追踪模型等方面。不过要想样样都学会精通也是需要花费时间,以及精力等,那么,小编就从最基本的多因子选股模型来说说,跟大家一起学习,一起探讨量化投资的要点。
我们常见的多因子模型是应用最广泛的一种选股模型,基本原理是采用一系列的因子作为选股标准,满足这些因子的股票则被买入,不满足的则卖出。
小编举一个简单的例子:如果有一批人参加马拉松,想要知道哪些人会跑到平均成绩之上,那只需在跑前做一个身体测试即可。那些健康指标靠前的运动员,获得超越平均成绩的可能性较大。多因子模型的原理与此类似,我们只要找到那些对企业的收益率最相关的因子即可。因为各种多因子模型核心的区别第一是在因子的选取上,第二是在如何用多因子综合得到一个最终的判断。一般而言,多因子选股模型有两种判断方法,一是打分法,二是回归法
打分法就是根据各个因子的大小对股票进行打分,然后按照一定的权重加权得到一个总分,根据总分再对股票进行筛选。回归法就是用过去的股票的收益率对多因子进行回归,得到一个回归方程,然后再把最新的因子值代入回归方程得到一个对未来股票收益的预判,然后再以此为依据进行选股。多因子选股模型的建立过程主要分为候选因子的选取、选股因子有效性的检验、有效但冗余因子的剔除、综合评分模型的建立和模型的评价及持续改进等5个步骤。
1、候选因子的选取
bigquant选股模型候选因子的选择主要依赖于经济逻辑和市场经验,但选择更多和更有效的因子无疑是增强模型信息捕获能力,提高收益的关键因素之一。
同样的持有时间段,也是一个重要的参数指标,到底是持有一个月,还是两个月,或者一年,对最终的收益率影响很大。
2、选股因子有效性的检验
一般检验方法主要采用排序的方法检验候选因子的选股有效性。例如:可以每月检验对于任意一个候选因子,在模型形成期的第一个月初开始计算市场中每只正常交易股票的该因子的大小, 按从小到大的顺序对样本股票进行排序,并平均分为n个组合,一直持有到月末,在下月初再按同样的方法重新构建n个组合并持有到月末,每月如此,一直重复到模型形成期末。
上面的例子就已经说明了这种检验的方法,同样的可以隔N个月检验,比如2个月,3个月,甚至更长时间。还有一个参数是候选组合的数量,是50支,还是100支,都是非常重要的参数。具体的参数最优的选择,需要股票数据接口用历史数据进行检验。
就比如股票数据接口实现的功能就有包括十档行情的获取,或者说五档行情数据的获取;
批量数据获取字段:
| 字段名 | 类型 | 备注 |
| stock_exchange | uint32 | 证券市场,1-SH,2-SZ |
| stock_code | string | 证券代码 |
| created_at | int64 | 委托日期时间戳(毫秒) |
| bid1_price | uint32 | 买 1 价 |
| bid1_quantity | uint32 | 买 1 笔数 |
| ask1_price | uint32 | 卖 1 价 |
| ask1_quantity | uint32 | 卖 1 笔数 |
| bid_volume_detail | repeated uint32 | 委托买入数量明细 |
| ask_volume_detail | repeated uint32 | 委托卖出数量明细 |
StockQuoteRecord(十档行情快照):
| 字段名 | 类型 | 备注 |
| stock_exchange | uint32 | 证券市场,见数据字典 |
| stock_code | string | 证券代码 |
| created_at | int64 | 快照日期时间戳(毫秒) |
| status | uint32 | 状态:0-开盘前,1-开盘集合竞价,2-集合竞价至连续竞价,3-连续竞价, 4-中午休市,5-收盘集合竞价,6-闭市 |
| prev_close_price | uint32 | 前收盘价 |
| open_price | uint32 | 开盘价 |
| latest_price | uint32 | 最新价 |
| high_price | uint32 | 最高价 |
| low_price | uint32 | 最低价 |
| limit_up_price | uint32 | 涨停价 |
| limit_down_price | uint32 | 跌停价 |
| order_quantity | uint32 | 成交笔数 |
| volume | uint64 | 成交数量 |
| amount | uint64 | 成交金额 |
| bid_volume | uint64 | 委托买入数量 |
| bid_price | uint32 | 委托买入加权平均价 |
| ask_volume | uint64 | 委托卖出数量 |
| ask_price | uint32 | 委托卖出加权平均价 |
| bid_price_detail | repeated uint32 | 委托买入价格明细(十档) |
| bid_volume_detail | repeated uint32 | 委托买入数量明细(十档) |
| ask_price_detail | repeated uint32 | 委托卖出价格明细(十档) |
| ask_volume_detail | repeated uint32 | 委托卖出数量明细(十档) |
3、有效但冗余因子的剔除
不同的选股因子可能由于内在的驱动因素大致相同等原因,所选出的组合在个股构成和收益等方面具有较高的一致性,因此其中的一些因子需要作为冗余因子剔除, 而只保留同类因子中收益最好,区分度最高的一个因子。例如成交量指标和流通量指标之间具有比较明显的相关性。流通盘越大的,成交量一般也会比较大,因此在选股模型中,这两个因子只选择其中一个。
bigquant选股模型中需要冗余因子剔除的方法:假设需要选出k 个有效因子,样本期共m 月,那么具体的冗余因子剔除步骤为:
(1)先对不同因子下的n个组合进行打分,分值与该组合在整个模型形成期的收益相关,收益越大,分值越高
(2)按月计算个股的不同因子得分间的相关性矩阵;
(3)在计算完每月因子得分相关性矩阵后,计算整个样本期内相关性矩阵的平均值
(4)设定一个得分相关性阀值 MinScoreCorr,将得分相关性平均值矩阵中大于该阀值的元素所对应的因子只保留与其他因子相关性较小、有效性更强的因子,而其它因子则作为冗余因子剔除。
4、综合评分模型的建立和选股
综合评分模型选取去除冗余后的有效因子,在模型运行期的某个时间开始,例如每个月初,对市场中正常交易的个股计算每个因子的最新得分并按照一定的权重求得所有因子的平均分。最后,根据bigquant选股模型所得出的综合平均分对股票进行排序,然后根据需要选择排名靠前的股票。例如,选取得分最高的前20%股票,或者选取得分最高的 50 到 100 只股票等等。
举个例子:可以构建一个多因子模型为(PE,PB,ROE),在月初的时候,对这几个因子进行打分,然后得分最高的50个股票作为投资组合,在下个月按照同样的方法进行轮换替换。持续一段时间后,考察该投资组合的收益率是否跑赢比较基准,这就是综合评分模型的建立和后验过程。
5、模型的评价及持续改进
一方面,由于量化选股的方法是建立在市场无效或弱有效的前提之下,随着使用多因子选股模型的投资者数量的不断增加,有的因子会逐渐失效,而另一些新的因素可能被验证有效而加入到模型当中;另一方面,一些因子可能在过去的市场环境下比较有效,而随着市场风格的改变,这些因子可能短期内失效,而另外一些以前无效的因子会在当前市场环境下表现较好。
另外,计算综合评分的过程中,各因子得分的权重设计、交易成本考虑和风险控制等都存在进一步改进的空间。因此在综合评分选股模型的使用过程中会对选用的因子、bigquant选股模型本身做持续的再评价和不断的改进以适应变化的市场环境。
多因子的模型最重要是两个方面:一个是有效因子,另外一个是因子的参数。例如到底是PE有效还是ROE有效;到底是采用1个月做调仓周期还是3个月做调仓周期。这些因子和参数的获取只能通过历史数据回测来获得。但是在回测过程中,要注意,不能过度优化,否则结果可能反而会不好。
策略源码例如:
today_str = datetime.today().strftime('%Y-%m-%d')
print('today:{}'.format(today_str))
data_alla = THS_DP('block', '{};001005010'.format(today_str), 'date:Y,thscode:Y,security_name:Y')
if data_alla.errorcode != 0:
print('error:{}'.format(data_alla.errmsg))
else:
stock_list = data_alla.data['THSCODE'].tolist()
indi_list = ['close', 'high', 'low', 'volume']
lock = Lock()
btime = datetime.now()
l = []
for eachlist in [stock_list[i:i + int(len(stock_list) / 10)] for i in
range(0, len(stock_list), int(len(stock_list) / 10))]:
nowstr = ','.join(eachlist)
p = Thread(target=work, args=(nowstr, lock, indi_list))
l.append(p)
for p in l:
p.start()
for p in l:
p.join()
etime = datetime.now()
print(etime-btime)
pd.options.display.width = 320
pd.options.display.max_columns = None
def reportDownload():
df = THS_ReportQuery('300033.SZ','beginrDate:2021-08-01;endrDate:2021-08-31;reportType:901','reportDate:Y,thscode:Y,secName:Y,ctime:Y,reportTitle:Y,pdfURL:Y,seq:Y').data
print(df)
for i in range(len(df)):
pdfName = df.iloc[i,4]+str(df.iloc[i,6])+'.pdf'
pdfURL = df.iloc[i,5]
r = requests.get(pdfURL)
with open(pdfName,'wb+') as f:
f.write(r.content)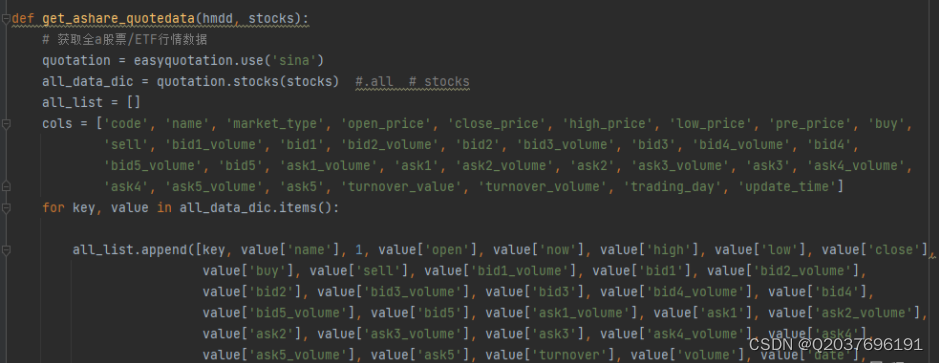
因此,交易者就可以通过当前的bigquant选股模型来获取更加精准的股票,但是也不能把股票数据接口简单的当作一种普通的应用软件系统,要学会适当的采用,才能帮助更多的投资者精准选股,提高量化选股的盈利概率。大家有需要的话,也可以加入下方Q提供简单的试用,让交易得简单起来。


![[附源码]计算机毕业设计JAVA疫情期间回乡人员管理系统](https://img-blog.csdnimg.cn/0316479663cb4f87a28e8e8079264770.png)