目录
- 1. 背景
- 2. 原理
- 3. 通过Trino创建Kudu表
- 4. FlinkKuduTableSinkProject项目
- 4.1 pom.xml
- 4.2 FlinkKuduTableSinkFactory.scala
- 4.3 META-INF/services
- 4.4 FlinkKuduTableSinkTest.scala测试文件
- 5. 查看Kudu表数据
1. 背景
使用第三方的org.apache.bahir » flink-connector-kudu,batch模式写入数据到Kudu会有FlushMode相关问题
具体可以参考我的这篇博客通过Flink SQL操作创建Kudu表,并读写Kudu表数据
2. 原理
Flink的Dynamic table能够统一处理batch和streaming
实现自定义Source或Sink有两种方式:
- 通过对已有的connector进行拓展。比如对connector = jdbc拓展Clickhouse的jdbc连接器
- 继承DynamicTableSourceFactory或DynamicTableSinkFactory,实现一个全新的connector。本节重点讲解这种
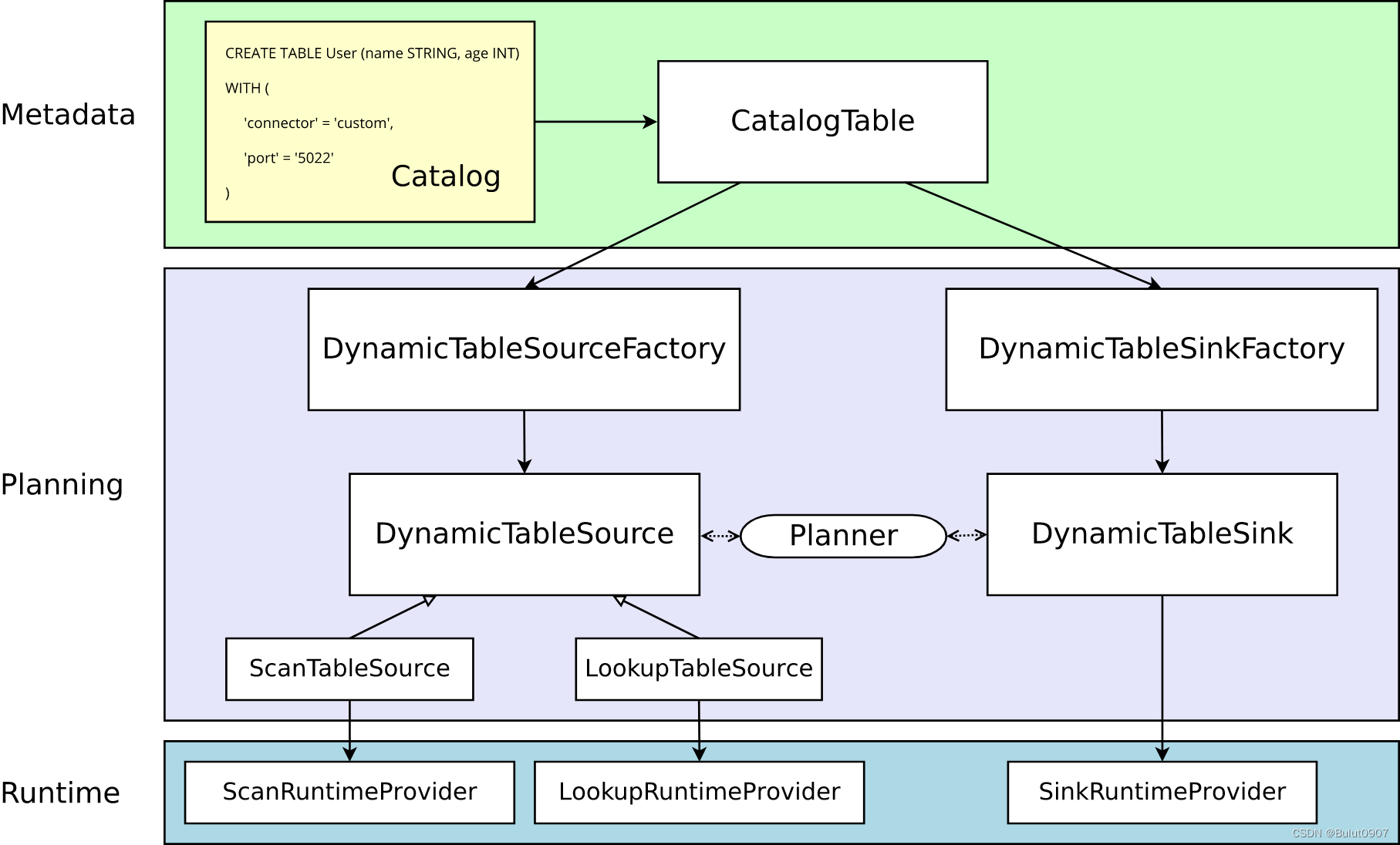
Metadata部分:Flink Catalog已有的Flink Table,或在Flink Catalog进行Flink Table的create sql声明。由CatalogTable实例进行表示
Planning部分:DynamicTableSourceFactory或DynamicTableSinkFactory将CatalogTable的metadata,转换成DynamicTableSource或DynamicTableSink的实例数据
DynamicTableFactory主要验证with子句的各个选项,并解析with子句的各个选项值。with子句的connector值必须和factoryIdentifier一致
DynamicTableFactory通过DynamicTableSource或DynamicTableSink进行runtime操作
runtime部分:Source主要需要实现ScanRuntimeProvider或LookupRuntimeProvider。Sink主要需要实现SinkRuntimeProvider。其中SinkRuntimeProvider有两个子类:
- OutputFormatProvider,可以接收org.apache.flink.api.common.io.OutputFormat
- SinkFunctionProvider,可以接收org.apache.flink.streaming.api.functions.sink.SinkFunction
3. 通过Trino创建Kudu表
trino:default> create table flink_table_test(
-> id int with (primary_key = true),
-> name varchar
-> ) with(
-> partition_by_hash_columns = array['id'],
-> partition_by_hash_buckets = 15,
-> number_of_replicas =1
-> );
CREATE TABLE
trino:default>
4. FlinkKuduTableSinkProject项目
4.1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.mq</groupId>
<artifactId>flinkKuduTableSinkProject</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.15</scala.version>
<flink.version>1.14.4</flink.version>
<kudu.version>1.15.0</kudu.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>${kudu.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.3.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude></exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.RSA</exclude>
<exclude>META-INF/*.DSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.6.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<args>
<arg>-nobootcp</arg>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
</project>
4.2 FlinkKuduTableSinkFactory.scala
定义FlinkKuduTableSinkFactory类,主要包含四个部分
- FlinkKuduTableSinkFactory
- FlinkKuduTableSinkFactory的伴生对象Object
- FlinkKuduTableSink
- FlinkKuduRowDataRichSinkFunction
package org.mq
import org.apache.flink.configuration.ConfigOptions.key
import org.apache.flink.configuration.{ConfigOption, Configuration, ReadableConfig}
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.table.connector.ChangelogMode
import org.apache.flink.table.connector.sink.DynamicTableSink.DataStructureConverter
import org.apache.flink.table.connector.sink.{DynamicTableSink, SinkFunctionProvider}
import org.apache.flink.table.data.RowData
import org.apache.flink.table.factories.{DynamicTableFactory, DynamicTableSinkFactory, FactoryUtil}
import org.apache.flink.table.types.DataType
import org.apache.flink.table.types.logical.RowType
import org.apache.flink.types.{Row, RowKind}
import org.apache.kudu.client.SessionConfiguration.FlushMode
import org.apache.kudu.client._
import java.util
import scala.collection.JavaConverters.asScalaBufferConverter
import scala.collection.mutable.ArrayBuffer
// 由于KuduSqlSinkFactory是Serializable,其属性也应该是Serializable。将属性定义在Object可以实现该功能
object FlinkKuduTableSinkFactory {
val kudu_masters: ConfigOption[String] = key("kudu.masters")
.stringType()
.noDefaultValue()
.withDescription("kudu masters")
val kudu_table: ConfigOption[String] = key("kudu.table")
.stringType()
.noDefaultValue()
.withDescription("kudu table")
}
class FlinkKuduTableSinkFactory extends DynamicTableSinkFactory with Serializable {
import FlinkKuduTableSinkFactory._
// 定义connector的name
override def factoryIdentifier(): String = "kudu"
// 定义with子句中必填的选项
override def requiredOptions(): util.Set[ConfigOption[_]] = {
val requiredSet: util.HashSet[ConfigOption[_]] = new util.HashSet[ConfigOption[_]]()
requiredSet.add(kudu_masters)
requiredSet.add(kudu_table)
requiredSet
}
// // 定义with子句中可填的选项
override def optionalOptions(): util.Set[ConfigOption[_]] = {
new util.HashSet[ConfigOption[_]]()
}
override def createDynamicTableSink(context: DynamicTableFactory.Context): DynamicTableSink = {
// 验证with子句选项,并获取各选项的值
val FactoryHelper: FactoryUtil.TableFactoryHelper = FactoryUtil.createTableFactoryHelper(this, context)
FactoryHelper.validate()
val withOptions: ReadableConfig = FactoryHelper.getOptions()
// 获取各字段的数据类型
val fieldDataTypes: DataType = context.getCatalogTable().getResolvedSchema.toPhysicalRowDataType
// Buffer(id)
val primaryKeys: Seq[String] = context.getCatalogTable().getResolvedSchema.getPrimaryKey
.get().getColumns.asScala.toSeq
new FlinkKuduTableSink(fieldDataTypes, withOptions)
}
}
class FlinkKuduTableSink(fieldDataTypes: DataType,
withOptions: ReadableConfig) extends DynamicTableSink {
// 定义Sink支持的ChangelogMode。insertOnly或upsert
override def getChangelogMode(requestedMode: ChangelogMode): ChangelogMode = {
requestedMode
}
// 调用用户自己定义的streaming sink ,建立sql与streaming的联系
override def getSinkRuntimeProvider(context: DynamicTableSink.Context): DynamicTableSink.SinkRuntimeProvider = {
val dataStructureConverter: DataStructureConverter = context.createDataStructureConverter(fieldDataTypes)
SinkFunctionProvider.of(new FlinkKuduRowDataRichSinkFunction(dataStructureConverter, withOptions, fieldDataTypes))
}
// sink可以不用实现,主要用来source的谓词下推
override def copy(): DynamicTableSink = {
new FlinkKuduTableSink(fieldDataTypes, withOptions)
}
// 定义sink的汇总信息,用于打印到控制台和log
override def asSummaryString(): String = "kudu"
}
// 同flink streaming的自定义sink ,只不过处理的是RowData
class FlinkKuduRowDataRichSinkFunction(dataStructureConverter: DataStructureConverter,
withOptions: ReadableConfig,
fieldDataTypes: DataType) extends RichSinkFunction[RowData] {
import FlinkKuduTableSinkFactory.{kudu_masters, kudu_table}
private val serialVersionUID: Long = 1L
private val fieldNameDatatypes: ArrayBuffer[(String, String)] = ArrayBuffer()
private var kuduClient: KuduClient = _
private var kuduSession: KuduSession = _
private var kuduTable: KuduTable = _
// 进行各种参数的初始化
override def open(parameters: Configuration): Unit = {
super.open(parameters)
val rowFields: util.List[RowType.RowField]
= fieldDataTypes.getLogicalType.asInstanceOf[RowType].getFields
rowFields.asScala.foreach(rowField => {
val rowFieldDatatype: String = rowField.getType.asSummaryString()
.split(" ").apply(0).split("\\(").apply(0)
fieldNameDatatypes += ((rowField.getName, rowFieldDatatype))
})
kuduClient = new KuduClient.KuduClientBuilder(withOptions.get(kudu_masters)).build()
kuduSession = kuduClient.newSession()
kuduSession.setFlushMode(FlushMode.AUTO_FLUSH_BACKGROUND)
kuduTable = kuduClient.openTable(withOptions.get(kudu_table))
}
// 对每个rowData进行具体的处理
override def invoke(rowData: RowData, context: SinkFunction.Context): Unit = {
val rowKind: RowKind = rowData.getRowKind()
val row: Row = dataStructureConverter.toExternal(rowData).asInstanceOf[Row]
// 处理insert和upsert
if (rowKind.equals(RowKind.INSERT) || rowKind.equals(RowKind.UPDATE_AFTER)) {
// 插入一条数据
val upsert: Upsert = kuduTable.newUpsert()
val partialRow: PartialRow = upsert.getRow()
fieldNameDatatypes.foreach(fieldNameDatatype => {
val fieldName: String = fieldNameDatatype._1
val fieldDatatype: String = fieldNameDatatype._2
fieldDatatype match {
case "INT" => {
var partialRowValue: Int = row.getFieldAs[Int](fieldName)
if (partialRowValue == null) partialRowValue = 0
partialRow.addInt(fieldName, partialRowValue)
}
case "BIGINT" => {
var partialRowValue: Long = row.getFieldAs[Long](fieldName)
if (partialRowValue == null) partialRowValue = 0L
partialRow.addLong(fieldName, partialRowValue)
}
case "FLOAT" => {
var partialRowValue: Float = row.getFieldAs[Float](fieldName)
if (partialRowValue == null) partialRowValue = 0.0F
partialRow.addFloat(fieldName, partialRowValue)
}
case "DOUBLE" => {
var partialRowValue: Double = row.getFieldAs[Double](fieldName)
if (partialRowValue == null) partialRowValue = 0.0
partialRow.addDouble(fieldName, partialRowValue)
}
case "DECIMAL" => {
val partialRowValue: java.math.BigDecimal =
row.getFieldAs[java.math.BigDecimal](fieldName)
partialRow.addDouble(fieldName,
if (partialRowValue == null) {
0.0
} else {
partialRowValue.doubleValue()
})
}
case "STRING" => {
var partialRowValue: String = row.getFieldAs[String](fieldName)
if (partialRowValue == null) partialRowValue = ""
partialRow.addString(fieldName, partialRowValue)
}
case "TIME" => {
val partialRowValue: java.time.LocalTime =
row.getFieldAs[java.time.LocalTime](fieldName)
partialRow.addString(fieldName,
if (partialRowValue == null) {
""
} else {
partialRowValue.toString
})
}
case "DATE" => {
val partialRowValue: java.time.LocalDate =
row.getFieldAs[java.time.LocalDate](fieldName)
partialRow.addDate(fieldName,
if (partialRowValue == null) {
new java.sql.Date(0L)
} else {
java.sql.Date.valueOf(partialRowValue)
})
}
case "TIMESTAMP" => {
val partialRowValue: java.time.LocalDateTime =
row.getFieldAs[java.time.LocalDateTime](fieldName)
partialRow.addTimestamp(fieldName,
if (partialRowValue == null) {
new java.sql.Timestamp(0L)
} else {
// 注意是否有时区的8小时偏差
java.sql.Timestamp.valueOf(partialRowValue.plusHours(8L))
})
}
case "BYTES" => {
val partialRowValue: Array[Byte] =
row.getFieldAs[Array[Byte]](fieldName)
partialRow.addBinary(fieldName, partialRowValue)
}
}
})
kuduSession.apply(upsert)
// 也可以手动调用flush
// kuduSession.flush()
}
}
// 进行各种资源的关闭
override def close(): Unit = {
super.close()
kuduSession.close()
}
}
4.3 META-INF/services
- 在项目的resource目录下,新建META-INF/services目录
- 在services目录下新建文件:org.apache.flink.table.factories.Factory
- Factory文件添加DynamicTableSinkFactory的全路径:org.mq.FlinkKuduTableSinkFactory
4.4 FlinkKuduTableSinkTest.scala测试文件
package org.mq
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object FlinkKuduTableSinkTest {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(senv)
tEnv.executeSql(
"""
|create table flink_table_test(
|id int,
|name string,
|primary key (id) not enforced
|) with (
|'connector' = 'kudu',
|'kudu.masters' = '192.168.8.112:7051,192.168.8.113:7051',
|'kudu.table' = 'flink_table_test'
|)
|""".stripMargin
)
tEnv.executeSql("insert into flink_table_test(id, name) values(2, 'li_si2')")
}
}
执行程序,然后查看Kudu表数据
5. 查看Kudu表数据
trino:default> select * from flink_table_test;
id | name
----+-----------
1 | zhang_san
(1 row)
Query 20220517_095005_00109_i893r, FINISHED, 2 nodes
Splits: 19 total, 19 done (100.00%)
0.22 [1 rows, 20B] [4 rows/s, 90B/s]
trino:default>




![对数组的“reg [7:0] a_tmp[32:0]”理解](https://img-blog.csdnimg.cn/img_convert/9f4db2f1c190cf9d43982793d1973f7b.png)