一、论文简述
1. 第一作者:Rui Chen、Songfang Han
2. 发表年份:2019
3. 发表期刊:ICCV
4. 关键词:MVS、深度学习、点云、迭代改进
5. 探索动机:很多传统方法通过多视图光度一致性和正则化优化迭代更新,但是需要繁琐的手动超参数调优;3D CNN的实现对于模型内存是立方级的增长,这可能潜在影响性能;近期一种新型的深度网络体系结构可以直接处理点云,而不需要将点云转换为体素网格。与基于体素的方法相比,这种架构集中在点云数据上,节省了不必要的计算。同时,在这个过程中保持了空间的连续性。
6. 工作目标:是否可以基于点云的结构,结合迭代优化以及3DCNN的优势,提出一种新的更高效的结构呢?
3D代价体的优势:The key advantage of 3D cost volume is that the 3D geometry of the scene can be captured by the network explicitly, and the photometric matching can be performed in 3D space, alleviating the influence of image distortion caused by perspective transformation and potential occlusions, which makes these methods achieve better results than 2D learning based methods.
7. 核心思想:提出了一种全新的基于点云的多视图立体网络,将目标场景直接处理为点云,在分辨率较高的情况下是一种更有效的表示方法。该方法以从粗到细的方式预测深度。首先生成一个粗深度图,将其转换为点云,并通过估计当前迭代深度与真实深度之间的残差来迭代改进点云。该网络结合了三维几何先验和二维纹理信息,将它们融合成一个特征增强的点云,并对点云进行处理,估计每个点的三维流。这种基于点的结构比基于代价体的结构具有更高的精度、计算效率和更大的灵活性。
8. 实验结果:在DTU和Tanks and Temples数据集上与最先进的方法相比,该方法达到了最好的性能,在完整性和整体质量方面都取得了更好的结果,显著提高了重建质量。此外,该方法还有潜在应用,如视点渲染(foveated)深度推理。
9. 论文下载:
https://openaccess.thecvf.com/content_ICCV_2019/papers/Chen_Point-Based_Multi-View_Stereo_Network_ICCV_2019_paper.pdf
https://github.com/callmeray/PointMVSNet
二、实现过程
1. Point-MVSNet概述
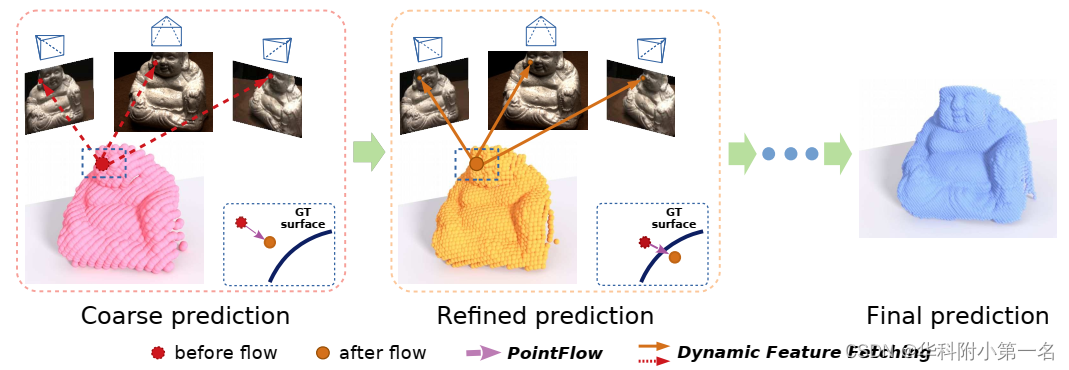
该结构主要分为两部分,第一是粗糙深度预测,第二是迭代深度改进。首先通过现有的MVSNet(分辨率设置较低,计算资源消耗较低)预测出较为粗糙的深度图作为初始深度图,并将基于假设点将其反投影为点云。针对每个点,算法从多视角图像中动态的抽取特征,并将2D图像特征与3D几何先验相关联,构成2D-3D特征,最后利用PointFlow基于这些特征来增强点云的精度,估计出当前深度图与GT间的残差,不断迭代优化深度图。

2. 粗糙深度预测
延续MVSNet方法构建低分辨率的代价体。考虑到内存和时间,分辨率由1/4减至1/8,深度采样数由256减少至48或96,代价体的内存减小为原先的1/20。然后通过多尺度3D CNN和soft argmin回归得到参考视图的初始深度图。
3. 迭代深度改进
3.1. 2D-3D特征挖掘(2D-3D feature lifting)
网络中的点云特征是由从特征金字塔输出的三个尺度下提取出来的图像2D特征和归一化的3D坐标组成的,这就是所谓的2D-3D特征。
图像特征金字塔:为了在多个尺度上赋予点更大的上下文信息的感受野,该网络构建了3层的特征金字塔。采用步幅为2的2D卷积网络对为N张原始视图进行3次下采样,提取下采样前的每一层特征图,构造3个不同层级的特征图Fi=[Fi1,Fi2,Fi3],形成最终的特征金字塔(参数共享)。图像特征金字塔的特征用于后续的迭代优化。
动态特征提取(Dynamic Feature Fetching):
由于迭代优化深度图,即推断出新的深度图之后会利用它生成新的点云(unprojected点和它同方向上产生的hypothesized点,下文会讲),然后再次执行该步骤为其中每个点找到2D特征,新的点云中的点3D坐标会发生变化,各点对应的图像上的特征也会随之变化,因此被称为动态特征提取(dynamic feature fetching)。由于每个unprojected点、和它同方向上产生的hypothesized点对应的各视图上对应的2D特征是一样的,因此实际是找点云X中每个点的2D特征。
已知相机参数,可以利用可微反投影法(unprojection)从多视点特征图中提取点云中每个3D点的2D坐标,进而找出图像外观特征。由于特征Fi1,Fi2,Fi3在不同的图像分辨率上,因此,在变化过程中需要缩放每一层级的相机内参。对于每个3D点的2D特征点的特征,延续MVSNet,使用基于方差的代价度量,即不同视图之间的特征方差,以聚合来自任意数量视图的变化后的特征。对于第 j 层的金字塔特征,N个视图的方差度量为定义如下:
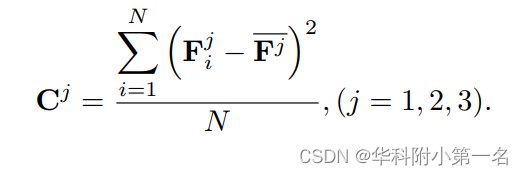
此时点云中每个点Xp都对应了2D方差特征Cp j(j=1,2,3)。为了得到每个3D点上的特征,连接2D特征和归一化点坐标[Cp,Xp],得到特征增强点,即后文PointFlow模块的输入,此时点云上每个点的特征都是2D-3D的,公式表述为

该部分为每个3D点构造特征表示向量,传统的3D点p可表示为Xp(x,y,z)包含了空间几何位置的先验信息,而论文又使用卷积网络提取了多个视角下图片的2D高级视觉特征,并通过方差法来提取属于点P的多视角2D特征Cp,两者做连接[Cp,Xp]即构成了所谓的2D-3D特征。
3.2. PointFlow模块
动机:For each point, we aim to estimate its displacement to the ground truth surface along the reference camera direction by observing its neighboring points from all views, so as to push the points to flow to the target surface.
PointFlow是论文中的核心模块,首先将深度图投影为3D点云,即为unprojected point点(通过深度图外加相机参数,通过反投影的方式生成的点),并生成一系列假设点,利用这些点构造出一个有向图,进行多层边缘卷积进一步提取邻域特征,然后经过MLP判断unprojected point的位移概率,最终算加权和得到各点的位移向量。
3.2.1. 生成假设3D点集
这一步包括深度图反投影到3D点云变换和假设点生成。
由于透视变换,2D特征图的上下文信息无法反应3D欧几里得空间的邻域点的距离。利用1中所得的初始深度图,可以通过反投影的方式来生成初始的空间点云X=[X1,X2,…,Xn],其中点云中点数目n为图像像素点数即H/8xW/8,每个点Xp包含了其3D特征[x,y,z]。对该初始空间点云X,我们称这些点为unprojected点,接下来要生成与这些点沿着参考相机的方向一致、但存在深度位移的假设点(hypothesized point),具体如下图所示:

该图可以看作一个俯视图,红色点p是初始unprojected点,连接参考相机和红点这条射线称为归一化参考相机方向,s表示单位位移步长。在每个红点前后m个位移间隔处设置蓝色hypothesized点p’ ,此时每个unprojected点的假设点集{p~k}表述如下:
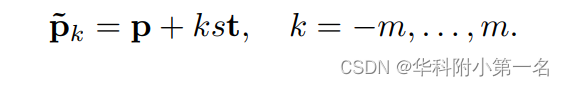
此时的点云X’包含了原始的unprojected点(n个)和每个unprojected点对应的2m个hypothesized点,即共计n*(2m+1)个。
3.2.2. 边缘卷积
动机:Classical MVS methods have demonstrated that local neighborhood is important for robust depth prediction.
没有理解:such that local geometric structure information could be used for the feature propagation of points.使得局部几何结构信息可用于点的特征传播。就是说信息聚合了?
本文采用DGCNN的策略来聚合相邻点之间的特征丰富点云信息,即使用中心点的特征和中心点与领域点的“残差特征”。使用k最近领域为点云中的点构造有向图(kNN),使得局部几何结构信息可用于点的特征传播。特征增强点云表示为Cp~={Cp~1,…, Cp~n},也就是上文提到的2D-3D特征。则边卷积定义为:

其中hΘ是由Θ参数化的可学习的非线性函数,而□是通道对称聚合操作(聚合函数),所谓对称是指输入的顺序并不影响结果。聚合方式包括最大池化、平均池化和加权和。总的含义是点p与最邻近的k个点计算边缘特征并进行聚合。调参后发现最大池化和平均池化有相似的性能。此时的Cp’即为对中心点边缘卷积后的新特征点,其包含了该点的局部几何信息。
参考:https://blog.csdn.net/qq_41794040/article/details/127917341?spm=1001.2014.3001.5502
3.2.3. 流预测
流预测的网络架构如下图所示。输入为特征增强点云,输出为深度残差图。
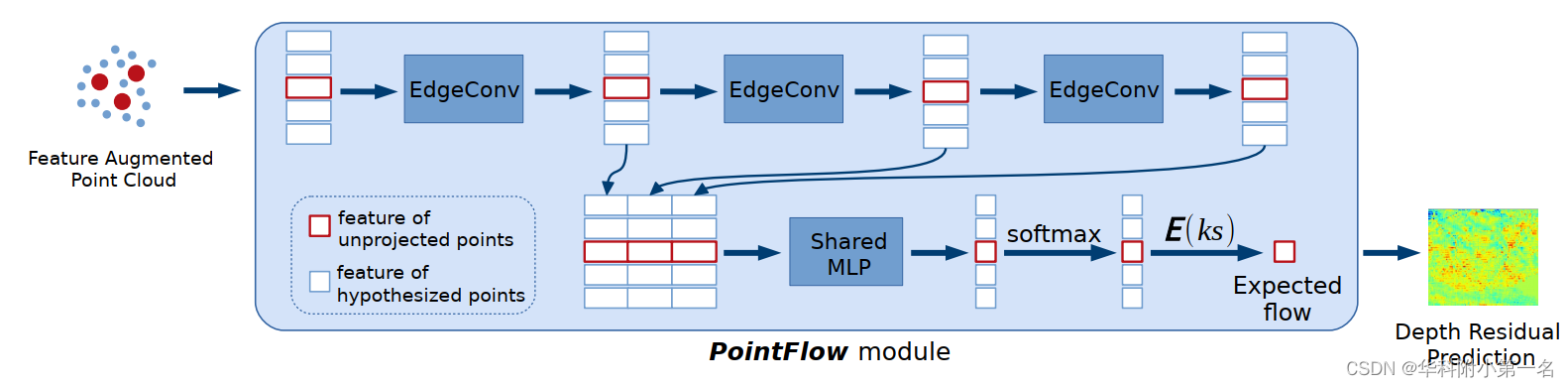
a) 使用3个边缘卷积(EdgeConv层)在不同尺度上聚合邻域的局部特征,并将每一层输出短连接(shortcut connect)来作为局部点特征;
b) 包含各unsample点多尺度局部2D-3D特征的边缘卷积的结果输入至共享参数的多层感知器MLP,进行点向特征变换,通过softmax输出unprojected点的各个假设点(2m+1个)的概率标量;
c) softmax之后的2m+1个概率标量代表了各假设点为真实表面上点的概率,unprojected点的预测位移为所有假设点位移的概率加权和:

这个操作是可微的。随后将各点的位移投影回去,输出深度残差图,并将其与初始输入深度图相加得到改进的深度图。
3.2.4. 上采样迭代改进
优势:Because of the flexibility of our point-based network architecture, the flow prediction can be performed iteratively, which is much harder for 3D cost-volume-based methods, because the space partitioning is fixed after the construction of cost volume.
对于粗预测的或前面残差预测得到的深度图D(i),可以先利用最近邻上采样到更高的空间分辨率,然后进行流预测得到D(i+1)。此外,随着迭代进行反投影点和假设点之间的深度间隔s渐减小,从而通过从更近的假设点获取更详细的特征来预测更准确的位移,以达到更高精度的深度预测。
3.2.5. 总结迭代深度改进,该过程可分:
- 通过粗糙代价体,得到初始深度图
- 初始深度图反投影出点云
- 构造假设点生成3D点云集
- 为点云集提取2D-3D特征得到特征增强点云
- 输入pointFlow模块
- 进行边缘卷积聚合点的局部特征
- 输入共享参数的MLP回归得到残差图
- 残差图与初始深度图相加得到优化后的深度图
- 优化后的深度图反投影出点云......
4. 训练损失
与MVSNet类似,将深度预测看作一个回归问题,使用L1损失来预测深度图和真实深度图间的绝对差值,由于是迭代进行优化,通过设置权重参数考虑初始深度图和迭代改进深度图的损失:
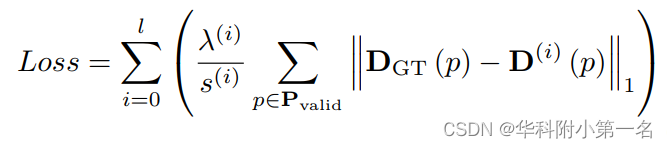
其中,Pvalid表示有效的groundtruth像素集,l为迭代次数。训练时将权重λ(i)设为1.0。s(i)为第i次迭代中单位位移。s(i)作为分母随着迭代进行不断减小,则该次迭代损失权重会增大,即让高分辨率的深度预测比重增加。
5. 实验
5.1. DTU数据集
5.2. 实现细节
训练:使用DTU数据集训练,训练图像大小设置为W × H = 640 × 512,输入视图数N = 3,深度假设的采样范围为425mm至921mm,D = 48。对于深度改进步骤,我们设置流迭代次数 l = 2,深度间隔分别为8mm和4mm。最近邻点数= 16。先对粗预测网络进行单独训练4个epoch,再对模型进行端到端训练12epoch。batch size为4,在4个NVIDIA GTX 1080Ti显卡上训练。RMSProp作为优化器,学习率设置为0.0005,每2epoch下降0.9。
评估:初始深度预测时,深度采样数D = 96,并设置流迭代次数l = 3进行深度改进。输入视图数N = 5。使用MVSNet相同后处理将所有深度图融合成点云。我们在两种不同的输入图像分辨率下评估了我们的方法:1280 × 960(Ours)和1600 × 1152(Ours-HiRes)
5.3. 在DTU数据集上进行基准测试
accuracy 、completeness、overall score

顶部:整个点云。下:放大局部区域的法线可视化。Point-MVSNet比MVSNet生成具有更多的高频分量的细节点云。特别是在边缘区域,可以获得更多高频几何特征。

5.4. PointFlow迭代
目的:Because of the continuity and flexibility of point representation, the refinement and densification can be performed iteratively on former predictions to give denser and more accurate predictions.
方式:For each iteration, we upsample the point cloud and decrease the depth interval of point hypotheses simultaneously, enabling the network to capture more detailed features.

5.5. 消融实验
Edge Convolution
Euclidean Nearest Neighbour
使用参考图像中相邻像素点来构造有向图,效果很差。原因是:for images of 3D scenes, near-by pixels may correspond to distant objects due to occlusion. Therefore, using neighboring points in the image space may aggregate irrelevant features for depth residual prediction, leading to descending performance.
Feature Pyramid
5.6. 对初始深度图的依赖
实验表明,该方法在一定范围内对噪声初始深度估计具有鲁棒性。我们在初始深度图中加入不同尺度的高斯噪声,并评估重建误差。从图中可以看出,在6mm噪声范围内,误差增长缓慢,小于MVSNet。AVG表示平均池化,MAX表示最大池化

5.7. 与点云上采样的比较
引入了流机制,使得点云上采样的效果比PU-Net 更为出色。
5.8. Foveated深度推理
最后这种基于点云的方法可以处理任意数目的点云,对于不同的密度都可以有效处理。对于感兴趣区域(ROI)可以实现更为精细的重建,下图中显示了三种不同的点云密度预测结果:

5.9. PointFlow模块的泛化性
Tanks and Temples,效果很好。



![[附源码]计算机毕业设计JAVA音乐网站](https://img-blog.csdnimg.cn/3a7a6d483e2a4ec69776c32766f0e9d3.png)