1、自定义Interceptor
1、案例需求
使用 Flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。
2、需求分析
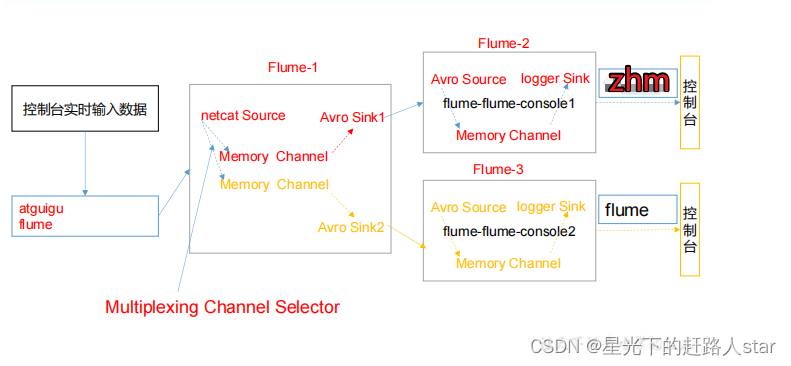
在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到 Flume 拓扑结构中的Multiplexing 结构,Multiplexing的原理是,根据 event 中 Header 的某个 key 的值,将不同的 event 发送到不同的 Channel中,所以我们需要自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值。在该案例中,我们以端口数据模拟日志,以是否包含”zhm”模拟不同类型的日志,我们需要自定义 interceptor 区分数据中是否包含”zhm”,将其分别发往不同的分析系统(Channel)。
3、实现步骤
(1)创建一个Maven项目,并引入以下依赖
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
(2)定义 CustomInterceptor 类并实现 Interceptor 接口。
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TypeInterceptor implements Interceptor {
//声明一个存放事件的集合
private List<Event> addHeaderEvents;
@Override
public void initialize() {
//初始化存放事件的集合
addHeaderEvents = new ArrayList<>();
}
//单个事件拦截
@Override
public Event intercept(Event event) {
//1.获取事件中的头信息
Map<String, String> headers = event.getHeaders();
//2.获取事件中的 body 信息
String body = new String(event.getBody());
//3.根据 body 中是否有"atguigu"来决定添加怎样的头信息
if (body.contains("zhm")) {
//4.添加头信息
headers.put("type", "first");
} else {
//4.添加头信息
headers.put("type", "second");
}
return event;
}
//批量事件拦截
@Override
public List<Event> intercept(List<Event> events) {
//1.清空集合
addHeaderEvents.clear();
//2.遍历 events
for (Event event : events) {
//3.给每一个事件添加头信息
addHeaderEvents.add(intercept(event));
}
//4.返回结果
return addHeaderEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
(3)打包,然后将jar包文件上传到Flume中的lib目录下
(4)编辑flume配置文件
为 hadoop102 上的 Flume1 配置 1 个 netcat source,1 个 sink group(2 个 avro sink),并配置相应的 ChannelSelector 和 interceptor。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =
com.zhm.flume.interceptor.CustomInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.first = c1
a1.sources.r1.selector.mapping.second = c2
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop103
a1.sinks.k1.port = 4141
a1.sinks.k2.type=avro
a1.sinks.k2.hostname = hadoop104
a1.sinks.k2.port = 4242
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
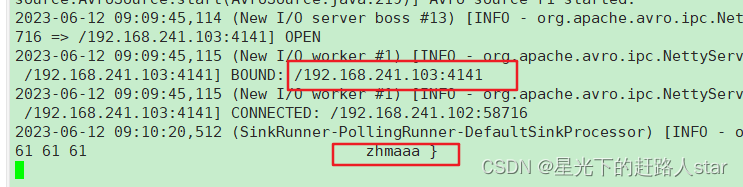
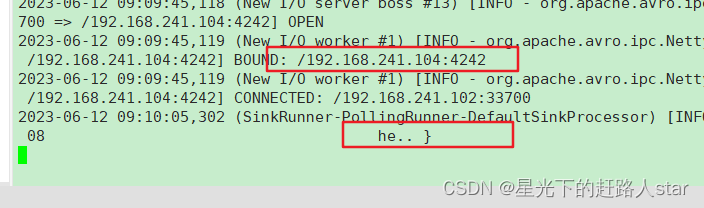
为 hadoop103 上的 Flume4 配置一个 avro source 和一个 logger sink。
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop103
a1.sources.r1.port = 4141
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1
为 hadoop104 上的 Flume3 配置一个 avro source 和一个 logger sink。
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop104
a1.sources.r1.port = 4242
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1
(5)分别在 hadoop102,hadoop103,hadoop104 上启动 flume 进程,注意先后顺序。
## Hadoop103
bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume-source-avro-sink-logger -Dflume.root.logger=INFO,console
##Hadoop104
bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume-source-avro-sink-logger -Dflume.root.logger=INFO,console
##Hadoop102
bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume1-source-netcat-sink-avro
(6)在 hadoop102 使用 netcat 向 localhost:44444 发送字母和数字。

(7)观察 hadoop103 和 hadoop104 打印的日志。
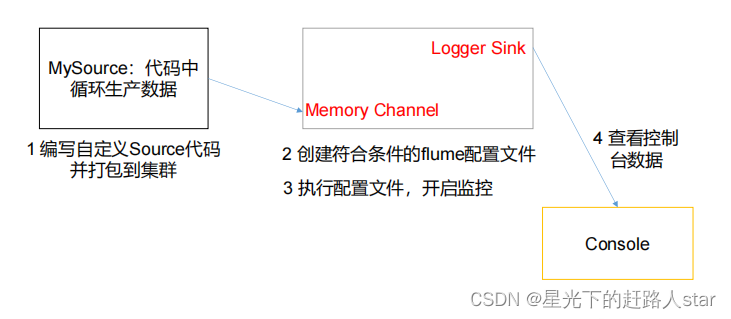
2、自定义Source
1、介绍
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling、directory、netcat、sequence generator、syslog、http、legacy。官方提供的 source 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 source。
2、需求
使用 flume 接收数据,并给每条数据添加前缀,输出到控制台。前缀可从 flume 配置文件中配置。
3、需求分析
4、案例实现
(1)导入 pom 依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
(2)编写代码
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.util.HashMap;
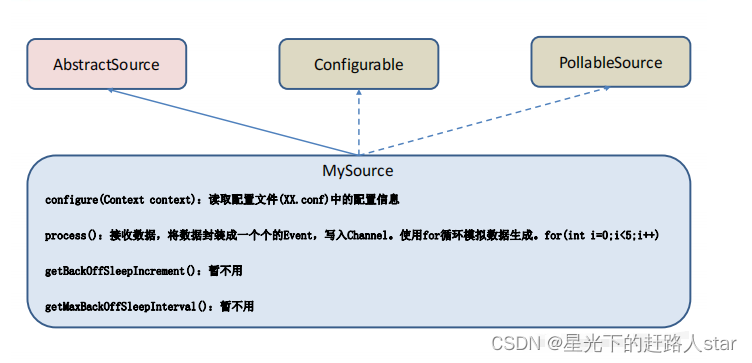
public class MySource extends AbstractSource implements
Configurable, PollableSource {
//定义配置文件将来要读取的字段
private Long delay;
private String field;
//初始化配置信息
@Override
public void configure(Context context) {
delay = context.getLong("delay");
field = context.getString("field", "Hello!");
}
@Override
public Status process() throws EventDeliveryException {
try {
//创建事件头信息
HashMap<String, String> hearderMap = new HashMap<>();
//创建事件
SimpleEvent event = new SimpleEvent();
//循环封装事件
for (int i = 0; i < 5; i++) {
//给事件设置头信息
event.setHeaders(hearderMap);
//给事件设置内容
event.setBody((field + i).getBytes());
//将事件写入 channel
getChannelProcessor().processEvent(event);
Thread.sleep(delay);
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
}
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
}
(3)将写好的代码打包,并放到 flume 的 lib 目录(/opt/module/flume)下。
(4)配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = com.zhm.MySource
a1.sources.r1.delay = 1000
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(5)开启任务
cd Flume目录下
bin/flume-ng agent -c conf/ -f job/mysource.conf -n a1 -Dflume.root.logger=INFO,console
(6)结果展示
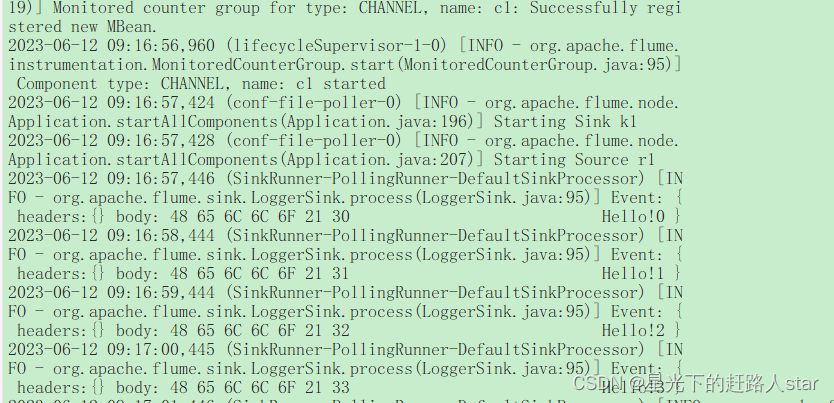
3、自定义Sink
1、介绍
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。官方提供的 Sink 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 Sink。
2、需求
使用 flume 接收数据,并在 Sink 端给每条数据添加前缀和后缀,输出到控制台。前后缀可在 flume 任务配置文件中配置。
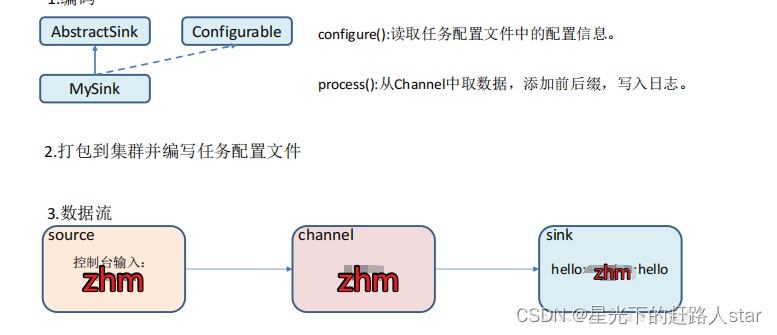
3、编码
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MySink extends AbstractSink implements Configurable
{
//创建 Logger 对象
private static final Logger LOG =
LoggerFactory.getLogger(AbstractSink.class);
private String prefix;
private String suffix;
@Override
public Status process() throws EventDeliveryException {
//声明返回值状态信息
Status status;
//获取当前 Sink 绑定的 Channel
Channel ch = getChannel();
//获取事务
Transaction txn = ch.getTransaction();
//声明事件
Event event;
//开启事务
txn.begin();
//读取 Channel 中的事件,直到读取到事件结束循环
while (true) {
event = ch.take();
if (event != null) {
break;
}
}
try {
//处理事件(打印)
LOG.info(prefix + new String(event.getBody()) +
suffix);
//事务提交
txn.commit();
status = Status.READY;
} catch (Exception e) {
//遇到异常,事务回滚
txn.rollback();
status = Status.BACKOFF;
} finally {
//关闭事务
txn.close();
}
return status;
}
@Override
public void configure(Context context) {
//读取配置文件内容,有默认值
prefix = context.getString("prefix", "hello:");
//读取配置文件内容,无默认值
suffix = context.getString("suffix");
}
}
4、打包
将写好的代码打包,并放到 flume 的 lib 目录(/opt/module/flume)下。
5、配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
尚硅谷大数据技术之 Flume
—————————————————————————————
# Describe the sink
a1.sinks.k1.type = com.zhm.MySink
a1.sinks.k1.suffix = :zhm
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
7、开启任务
bin/flume-ng agent -c conf/ -n a1 -f job/groupSink/mysink.conf -Dflume.root.logger=INFO,console
8、结果展示


4、额外知识
1、Flume的事务机制
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责Source到Channel,以及从Channel到Sink的事件传递。
比如Spooling Directory Source为文件的每一行创建一个事件,一旦事务中所以事件全部传递到Channel且提交成功,那么事务将会回滚。且所以得事件都会保持到Channel中,等待重新传递。
2、Flume采集数据会丢失吗?
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel储存数据已满,导致Source不再写入,未写入的数据丢失。
Flume不会丢失数据,但是可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接受到响应,Sink会再次发生数据,此时可能会导致·数据的重复。