深度学习炼丹大杀器——mlrunner初体验(以mmdetection为例)
自动化炼丹,告别手动运行的烦恼~
0.引言
了解深度学习的人都知道,炼丹是一种很玄学的事,并且还存在以下问题:
效率:在训练模型时,如何更好地利用计算资源,提高训练效率?
认知负载:训练一个模型需要涉及到多个节点,包括数据处理、模型结构、模型参数、训练参数和测试参数等,在调整这些参数时如何避免出错?
可用性:如何有效地管理并区分不同的实验,并快速迁移开发工具到其他项目中?
鲁棒性:当机器宕机时,如何保证已经进行的实验不会白白浪费,而能够快速恢复训练进度?
今天微信公众号推了这篇文章,https://mp.weixin.qq.com/s/kwhx9DxuORDvh0p5vz8oRA,一看觉得还挺方便的,果断拿起mmdetection试试水。
github地址:https://github.com/simtony/runner
1.安装mlrunner
安装其实非常简单,只需一行命令行 pip install mlrunner即可安装成功

2.配置params.yaml
在根目录下新建一个params.yaml的文件,运行mlrunner的时候会自动加载这个配置文件,当然也可以在别的地方建了然后指定目录就行,在params.yaml配置运行超参设置,下面是官方的配置:
---
# 每个实验的所有命令都将填充参数指定为"{param}"或"[param]","{param}"和"[param]"的区别就在于存放是指令还是参数
# {_output} 是自动生成的输出目录,用于保存运行log以及权重文件
template:
train: >
python train.py data-bin/{data} --save-dir {_output} --norm {norm} [moment] [early-stop]
avg: >
python checkpoint_avg.py --inputs {_output} --num 5 --output {_output}/avg.pt
test: >
python generate.py data-bin/{data} --beam 5 --path {_output}/avg.pt
# 默认参数
default:
data: iwslt14
norm: batch
moment: 0.1
early-stop: False
# "CUDA_VISIBLE_DEVICES={}"中需要填写的GPU索引,每一个对应一个worker。如果是单卡就写[0]即可
resource: [ 0, 1, 2, 3 ]
---
# 比较不同归一化层和矩的效果,会排列组合运行,如new-0.1,new-0.05,batch-0.1,batch-0.05
norm: [ new, batch ]
moment: [ 0.1, 0.05 ]
---
# 检查提前停止的效果
norm: [ batch ]
early-stop: [ True, False ]
以下是我使用mmdetection的配置
---
template:
train: >
python tools/train.py configs/ssd/ssd300_coco.py --work-dir {_output} --amp --cfg-options train_dataloader.batch_size={batch_size} train_cfg.max_epochs={max_epochs} optim_wrapper.optimizer.lr={lr}
default:
batch_size: 48
max_epochs: 1
lr: 0.1
resource: [ 0 ]
---
max_epochs: [ 10, 100 ]
lr: [ 0.1, 0.01, 0.001 ]
3.运行配置文件
在终端输入run,即可开启超参数排列组合的运行:
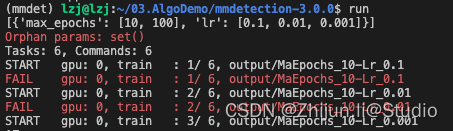
在同级目录下会生成一个output的文件夹,用于存放输出
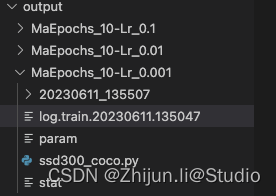
点进log文件,还可以看到本在终端进行的输出:
06/11 13:55:08 - mmengine - INFO -
------------------------------------------------------------
System environment:
sys.platform: linux
Python: 3.9.16 (main, Jan 11 2023, 16:05:54) [GCC 11.2.0]
CUDA available: True
numpy_random_seed: 111621056
GPU 0: NVIDIA GeForce RTX 3060
CUDA_HOME: /usr/local/cuda-11.3
NVCC: Cuda compilation tools, release 11.3, V11.3.58
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
PyTorch: 1.12.1+cu113
PyTorch compiling details: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.6.0 (Git Hash 52b5f107dd9cf10910aaa19cb47f3abf9b349815)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.3
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86
- CuDNN 8.5 (built against CUDA 11.7)
- Built with CuDNN 8.3.2
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.3.2, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.12.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
TorchVision: 0.13.1+cu113
OpenCV: 4.7.0
MMEngine: 0.7.1
Runtime environment:
cudnn_benchmark: False
mp_cfg: {'mp_start_method': 'fork', 'opencv_num_threads': 0}
dist_cfg: {'backend': 'nccl'}
seed: None
Distributed launcher: none
Distributed training: False
GPU number: 1
------------------------------------------------------------
06/11 13:55:08 - mmengine - INFO - Config:
input_size = 300
model = dict(
type='SingleStageDetector',
data_preprocessor=dict(
type='DetDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
bgr_to_rgb=True,
pad_size_divisor=1),
backbone=dict(
type='SSDVGG',
depth=16,
with_last_pool=False,
ceil_mode=True,
out_indices=(3, 4),
out_feature_indices=(22, 34),
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')),
neck=dict(
type='SSDNeck',
in_channels=(512, 1024),
out_channels=(512, 1024, 512, 256, 256, 256),
level_strides=(2, 2, 1, 1),
level_paddings=(1, 1, 0, 0),
l2_norm_scale=20),
bbox_head=dict(
type='SSDHead',
in_channels=(512, 1024, 512, 256, 256, 256),
num_classes=4,
anchor_generator=dict(
type='SSDAnchorGenerator',
scale_major=False,
input_size=300,
basesize_ratio_range=(0.15, 0.9),
strides=[8, 16, 32, 64, 100, 300],
ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2])),
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.0,
ignore_iof_thr=-1,
gt_max_assign_all=False),
sampler=dict(type='PseudoSampler'),
smoothl1_beta=1.0,
allowed_border=-1,
pos_weight=-1,
neg_pos_ratio=3,
debug=False),
test_cfg=dict(
nms_pre=1000,
nms=dict(type='nms', iou_threshold=0.45),
min_bbox_size=0,
score_thr=0.02,
max_per_img=200))
cudnn_benchmark = True
dataset_type = 'CocoDataset'
data_root = 'data/sea/'
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=[123.675, 116.28, 103.53],
to_rgb=True,
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', scale=(300, 300), keep_ratio=False),
dict(type='RandomFlip', prob=0.5),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(type='Resize', scale=(300, 300), keep_ratio=False),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=48,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=None,
dataset=dict(
type='RepeatDataset',
times=5,
dataset=dict(
type='CocoDataset',
data_root='data/sea/',
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=[
dict(type='LoadImageFromFile', backend_args=None),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=[123.675, 116.28, 103.53],
to_rgb=True,
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', scale=(300, 300), keep_ratio=False),
dict(type='RandomFlip', prob=0.5),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(type='PackDetInputs')
],
backend_args=None)))
val_dataloader = dict(
batch_size=32,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='CocoDataset',
data_root='data/sea/',
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=[
dict(type='LoadImageFromFile', backend_args=None),
dict(type='Resize', scale=(300, 300), keep_ratio=False),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
],
backend_args=None))
test_dataloader = dict(
batch_size=32,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='CocoDataset',
data_root='data/sea/',
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=[
dict(type='LoadImageFromFile', backend_args=None),
dict(type='Resize', scale=(300, 300), keep_ratio=False),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
],
backend_args=None))
val_evaluator = dict(
type='CocoMetric',
ann_file='data/sea/annotations/instances_val2017.json',
metric='bbox',
format_only=False,
backend_args=None)
test_evaluator = dict(
type='CocoMetric',
ann_file='data/sea/annotations/instances_val2017.json',
metric='bbox',
format_only=False,
backend_args=None)
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=10, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
param_scheduler = [
dict(
type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
dict(
type='MultiStepLR',
begin=0,
end=24,
by_epoch=True,
milestones=[16, 22],
gamma=0.1)
]
optim_wrapper = dict(
type='AmpOptimWrapper',
optimizer=dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0005),
loss_scale='dynamic')
auto_scale_lr = dict(enable=False, base_batch_size=8)
default_scope = 'mmdet'
default_hooks = dict(
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=50),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(type='CheckpointHook', interval=1),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='DetVisualizationHook'))
env_cfg = dict(
cudnn_benchmark=False,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='DetLocalVisualizer',
vis_backends=[dict(type='LocalVisBackend')],
name='visualizer')
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
log_level = 'INFO'
load_from = None
resume = False
custom_hooks = [
dict(type='NumClassCheckHook'),
dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')
]
launcher = 'none'
work_dir = 'output/MaEpochs_10-Lr_0.001'
06/11 13:55:11 - mmengine - INFO - Distributed training is not used, all SyncBatchNorm (SyncBN) layers in the model will be automatically reverted to BatchNormXd layers if they are used.
06/11 13:55:11 - mmengine - INFO - Hooks will be executed in the following order:
before_run:
(VERY_HIGH ) RuntimeInfoHook
(BELOW_NORMAL) LoggerHook
--------------------
before_train:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(VERY_LOW ) CheckpointHook
--------------------
before_train_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(NORMAL ) DistSamplerSeedHook
(NORMAL ) NumClassCheckHook
--------------------
before_train_iter:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
--------------------
after_train_iter:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
(VERY_LOW ) CheckInvalidLossHook
--------------------
after_train_epoch:
(NORMAL ) IterTimerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
--------------------
before_val_epoch:
(NORMAL ) IterTimerHook
(NORMAL ) NumClassCheckHook
--------------------
before_val_iter:
(NORMAL ) IterTimerHook
--------------------
after_val_iter:
(NORMAL ) IterTimerHook
(NORMAL ) DetVisualizationHook
(BELOW_NORMAL) LoggerHook
--------------------
after_val_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
--------------------
after_train:
(VERY_LOW ) CheckpointHook
--------------------
before_test_epoch:
(NORMAL ) IterTimerHook
--------------------
before_test_iter:
(NORMAL ) IterTimerHook
--------------------
after_test_iter:
(NORMAL ) IterTimerHook
(NORMAL ) DetVisualizationHook
(BELOW_NORMAL) LoggerHook
--------------------
after_test_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
--------------------
after_run:
(BELOW_NORMAL) LoggerHook
--------------------
loading annotations into memory...
Done (t=0.04s)
creating index...
index created!
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
06/11 13:55:12 - mmengine - INFO - load model from: open-mmlab://vgg16_caffe
06/11 13:55:12 - mmengine - INFO - Loads checkpoint by openmmlab backend from path: open-mmlab://vgg16_caffe
06/11 13:55:12 - mmengine - WARNING - "FileClient" will be deprecated in future. Please use io functions in https://mmengine.readthedocs.io/en/latest/api/fileio.html#file-io
06/11 13:55:12 - mmengine - WARNING - "HardDiskBackend" is the alias of "LocalBackend" and the former will be deprecated in future.
06/11 13:55:12 - mmengine - INFO - Checkpoints will be saved to /home/lzj/03.AlgoDemo/mmdetection-3.0.0/output/MaEpochs_10-Lr_0.001.
06/11 13:56:35 - mmengine - INFO - Epoch(train) [1][ 50/486] lr: 9.9098e-05 eta: 2:13:20 time: 1.6634 data_time: 0.7856 memory: 5018 loss: 15.6497 loss_cls: 11.7071 loss_bbox: 3.9427
06/11 13:57:50 - mmengine - INFO - Epoch(train) [1][100/486] lr: 1.9920e-04 eta: 2:04:48 time: 1.4829 data_time: 0.6475 memory: 5018 loss: 9.6245 loss_cls: 6.4323 loss_bbox: 3.1922
06/11 13:59:12 - mmengine - INFO - Epoch(train) [1][150/486] lr: 2.9930e-04 eta: 2:05:11 time: 1.6379 data_time: 0.8031 memory: 5018 loss: 8.1894 loss_cls: 5.0955 loss_bbox: 3.0939
06/11 14:00:24 - mmengine - INFO - Epoch(train) [1][200/486] lr: 3.9940e-04 eta: 2:01:09 time: 1.4557 data_time: 0.6219 memory: 5018 loss: 7.0464 loss_cls: 4.1351 loss_bbox: 2.9113
06/11 14:01:35 - mmengine - INFO - Epoch(train) [1][250/486] lr: 4.9950e-04 eta: 1:57:32 time: 1.4089 data_time: 0.5690 memory: 5018 loss: 6.7643 loss_cls: 4.0253 loss_bbox: 2.7390
06/11 14:02:48 - mmengine - INFO - Epoch(train) [1][300/486] lr: 5.9960e-04 eta: 1:55:23 time: 1.4612 data_time: 0.6168 memory: 5018 loss: 6.3747 loss_cls: 3.7409 loss_bbox: 2.6338
06/11 14:04:04 - mmengine - INFO - Epoch(train) [1][350/486] lr: 6.9970e-04 eta: 1:54:06 time: 1.5170 data_time: 0.6746 memory: 5018 loss: 6.3341 loss_cls: 3.7404 loss_bbox: 2.5938
心动不如行动,还不快试试~