目录
一:前言:
二:更快,更强
网络结构图
其他基础操作:
Darknet53的由来
三:最明显的特点:
四:多scale
五: 为什么vgg越深效果反而越差了?
六:Softmax的改进
七:数据的标注
一:前言:
Yolov3是2018年发明提出的,这成为了目标检测one-stage中非常经典的算法,包含Darknet-53网络结构、anchor锚框、FPN等非常优秀的结构。
以下是YOLOv3的主要改进和特点:
-
多尺度预测:YOLOv3引入了三种不同尺度的检测层,分别用于检测不同大小的目标。这使得YOLOv3能够有效地检测不同尺寸的目标,从小物体到大物体都能有较好的表现。
-
Darknet-53骨干网络:YOLOv3采用了一个称为Darknet-53的更深的骨干网络作为特征提取器。相比于之前的版本,Darknet-53具有更多的层和更深的网络结构,可以提取更高层次的语义特征,从而提高目标检测的准确性。
-
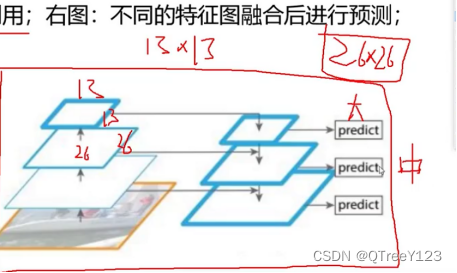
使用多尺度特征融合:YOLOv3通过在不同层次的特征图上进行特征融合,可以融合不同尺度的特征信息。这种多尺度特征融合有助于检测不同大小的目标,并提高目标检测的准确性。
-
更精细的边界框预测:YOLOv3对边界框的预测进行了改进,引入了不同大小的锚框,并使用卷积层来预测边界框的偏移量。这使得YOLOv3可以更准确地预测目标的边界框。
-
使用多尺度训练和推理:YOLOv3在训练和推理阶段都使用了多尺度的策略。在训练时,YOLOv3会在不同尺度的输入图像上进行训练,以增强模型对不同大小目标的适应能力。在推理时,YOLOv3可以接受不同尺度的输入图像,并生成相应尺度的预测结果。
二:更快,更强

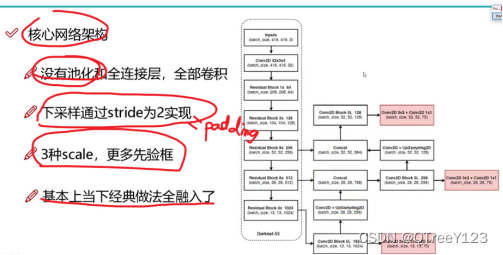
网络结构图

上图三个蓝色方框内表示Yolov3的三个基本组件:
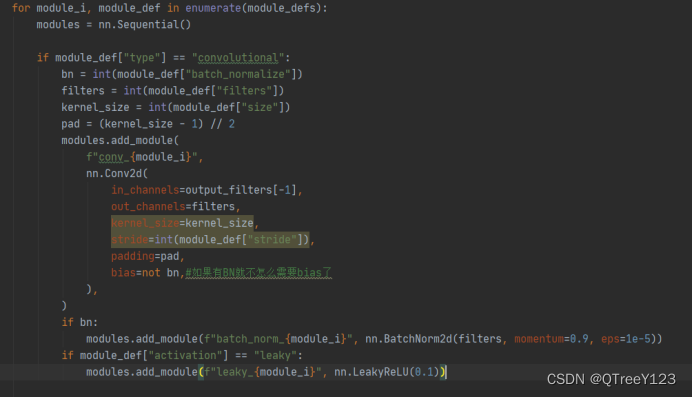
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
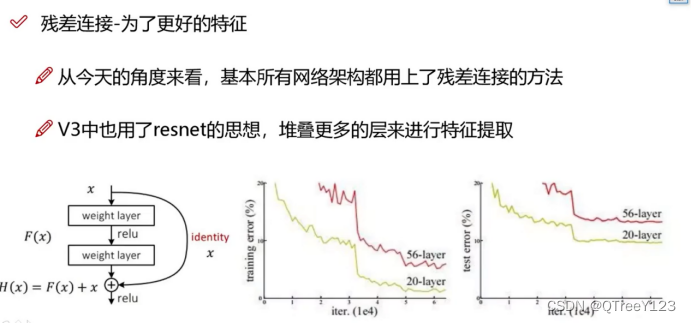
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
- Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。
- add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
Darknet53的由来
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
三:最明显的特点:
1、特征做的更细致,融入多持续特征图信息来预测不同规格物体
2、先验框更丰富了,3种scale,每种3个规格,一共9种
3、 softmax改进,预测多标签任务
四:多scale
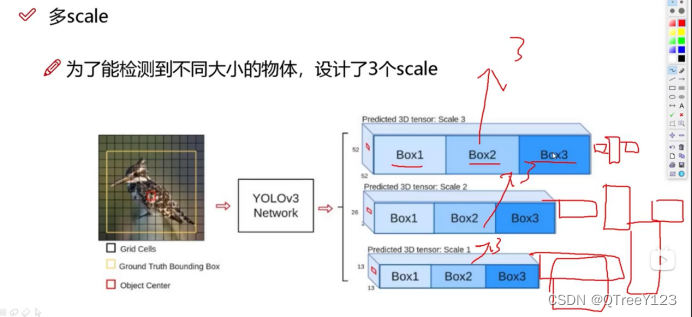
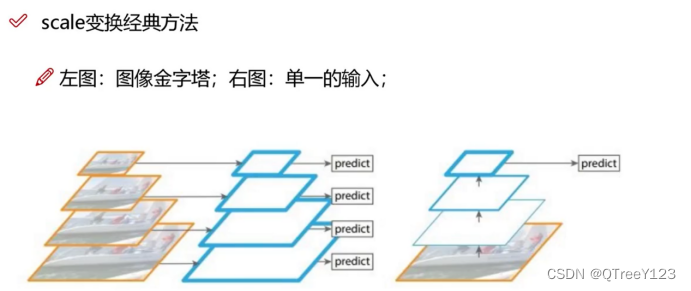
经典的特征金字塔: 第一个计算量太大速度太慢了,第二个也就是右边那个可以当作yolov1版本
13岁能做的好,但是23,56岁的人未必能玩的好。。

正确的做法:
五: 为什么vgg越深效果反而越差了?
14年,Vgg到了19层后就最好了,后面越深越差!!!!因为没有resnet那样特征融合,而darknet其实就是resnet的版本
整体网络介绍。。Darknet-53网络结构中并没有使用池化(pooling)层和全连接层。相反,Darknet-53主要使用卷积层和残差连接(shortcut)(residual connections)来构建网络。
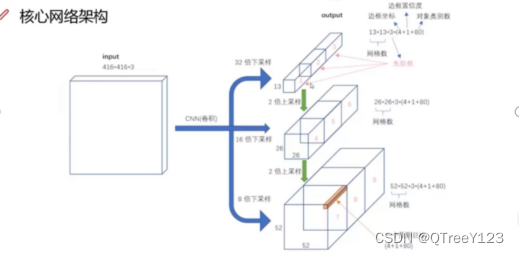
与V2不一样,V2是不管你的尺度,我都用聚类生成5个锚框,但是V3是先写成特征图,然后根据不同的感受野生成对应的尺度的候选框。

六:Softmax的改进
之前是如果你预测的类被是猫,那么就在这20个类别里面找到猫,然后计算他们的损失。但是在这里猫的种类有很多种,猫,大猫,小猫........
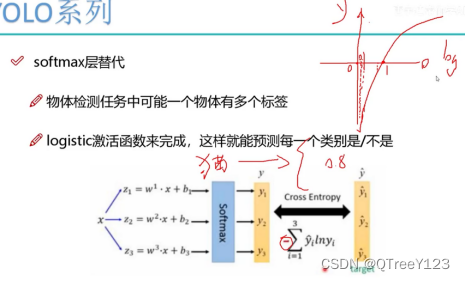
那么改进的softmax就是设置阈值,取出多标签的目标:

先存起来
七:数据的标注
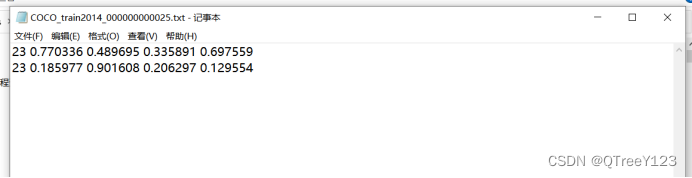
以后也是,每次标注的时候,也已经把坐标归一化了,归一化可以提高数值稳定性:在一些数值计算中,较大或较小的数值范围可能导致数值不稳定性,例如出现溢出或下溢的情况。通过归一化,可以将数值范围缩放到更稳定的区间,有助于数值计算的稳定性和数值精度。也可以加速模型收敛:某些优化算法(例如梯度下降)对输入数据的尺度敏感。如果数据的尺度差异较大,优化算法可能需要更多的迭代才能达到收敛,而归一化可以加速模型的收敛过程,减少训练时间。
不是层,而是组合
代码实现:遍历了第一个模块
看看数据

这个是coco数据集的先验框的标准,如果你的任务的目标比较大或小,可以自己写个聚类,使用不同的先验框。

spp:
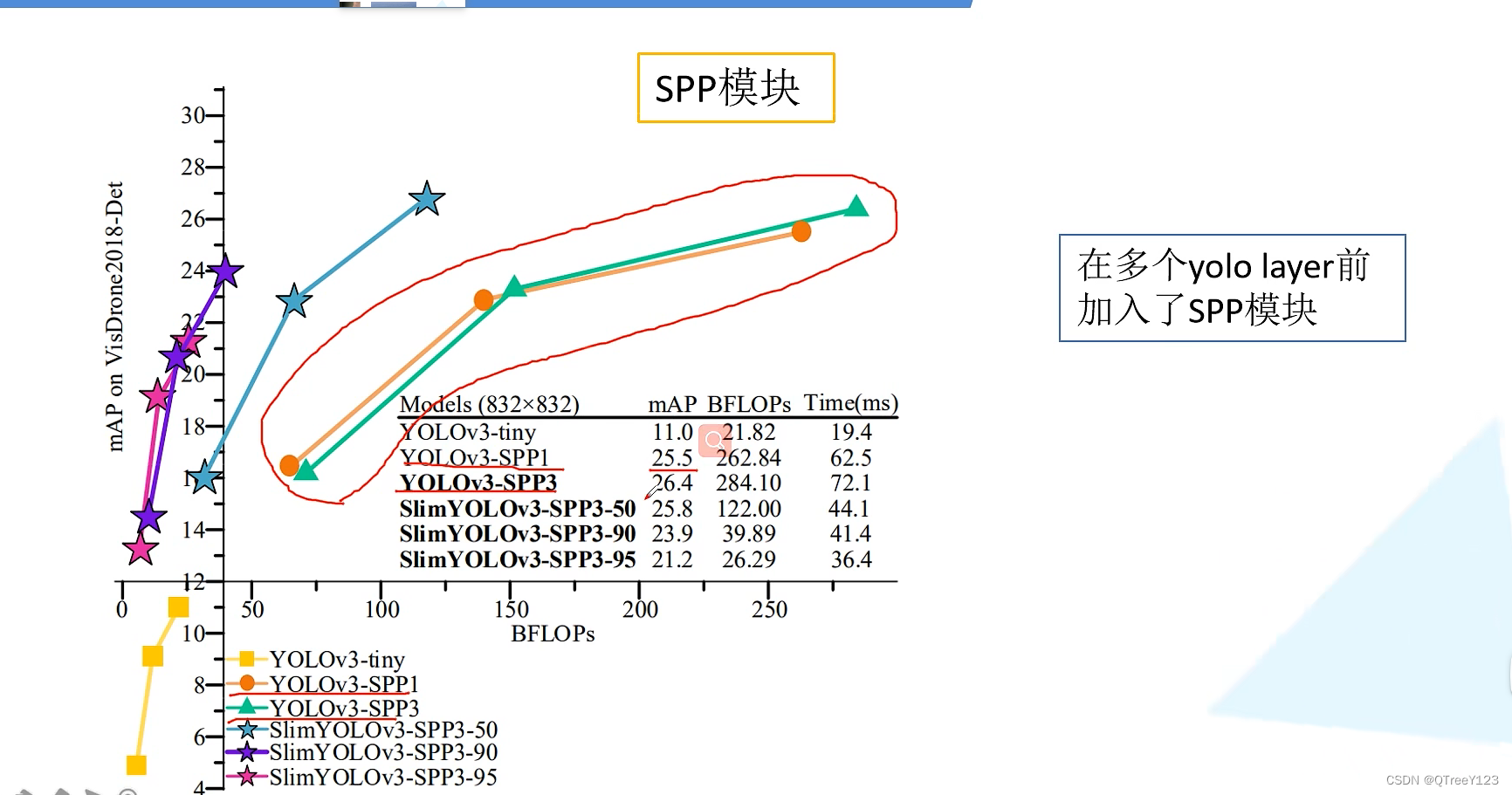
SPP结构参杂在对CSPdarknet53的最后一个特征层的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。
SPP能够极大地增加感受野,分离出最显著的上下文特征。
为什么只在预测特征图小的物体的层添加spp模块,为什么不在其他预测层加?
结果测试,如果3个预测特征层都进行SPP结构的话,虽然MAP增加了0.9但是推理速慢了,而且MAP也不是增加很多,所以作者就只在16*16的时候使用了SPP结构





![QtXlsxWriter make报错:[Makefile:45:sub-xlsx-make_first] 错误](https://img-blog.csdnimg.cn/a9b417c058e34fcfb318e743ced3678a.png)