海量数据下如何提升es的操作性能
.filesystemcache
os cache操作系统缓存
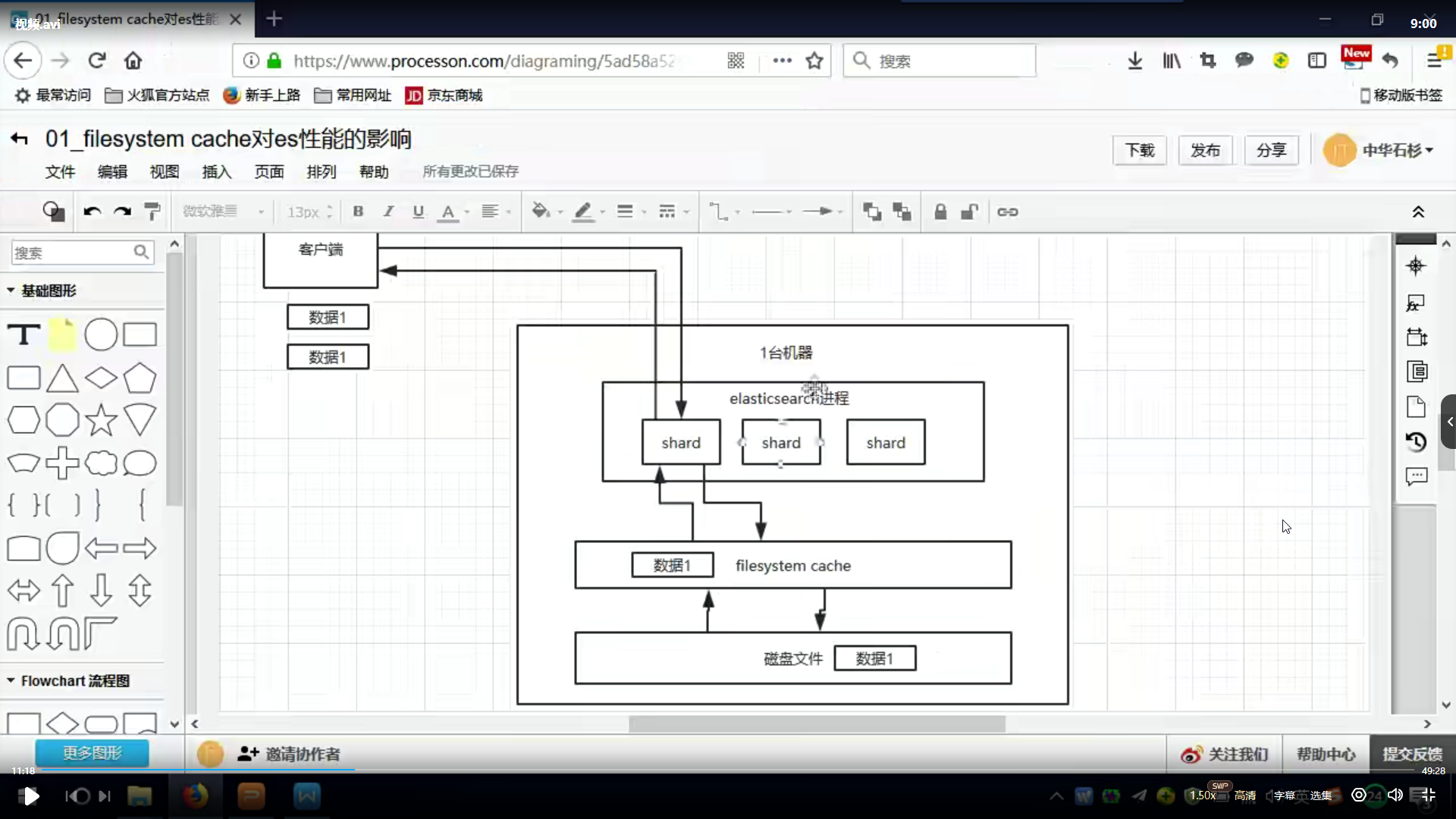
es中的数据,实际上写入磁盘,磁盘文件的操作系统,实际上会将数据写入到oscache中
es的搜索引擎严重依赖于底层的filesystemcache
如果filesystemcache的内存足够大,可以容纳所有的index segmentfile索引数据文件,那么搜索的时候,基本上都是走的内存,实际上的消耗非常少,性能会非常高.
es中中需要存储少数的记几个需要用于检索的数据信息.而不需要把所有的数据都写入es否则,大量的非检索数据徒徒占用空间而无任何作用
一般建议使用es+hbase这样子的架构
hbase的特点是海量数据在线存储,不要做复杂的搜索动作,就是做简单的id或者范围检索
从es中根据name或者是age 去检索,拿到的结果可能有20个doc id然后根据es检索到的内容信息作为第二次检索的索引去hbase中进行查询,然后再返回给前端
写入到数据最好是略微大于es的filesystem cache的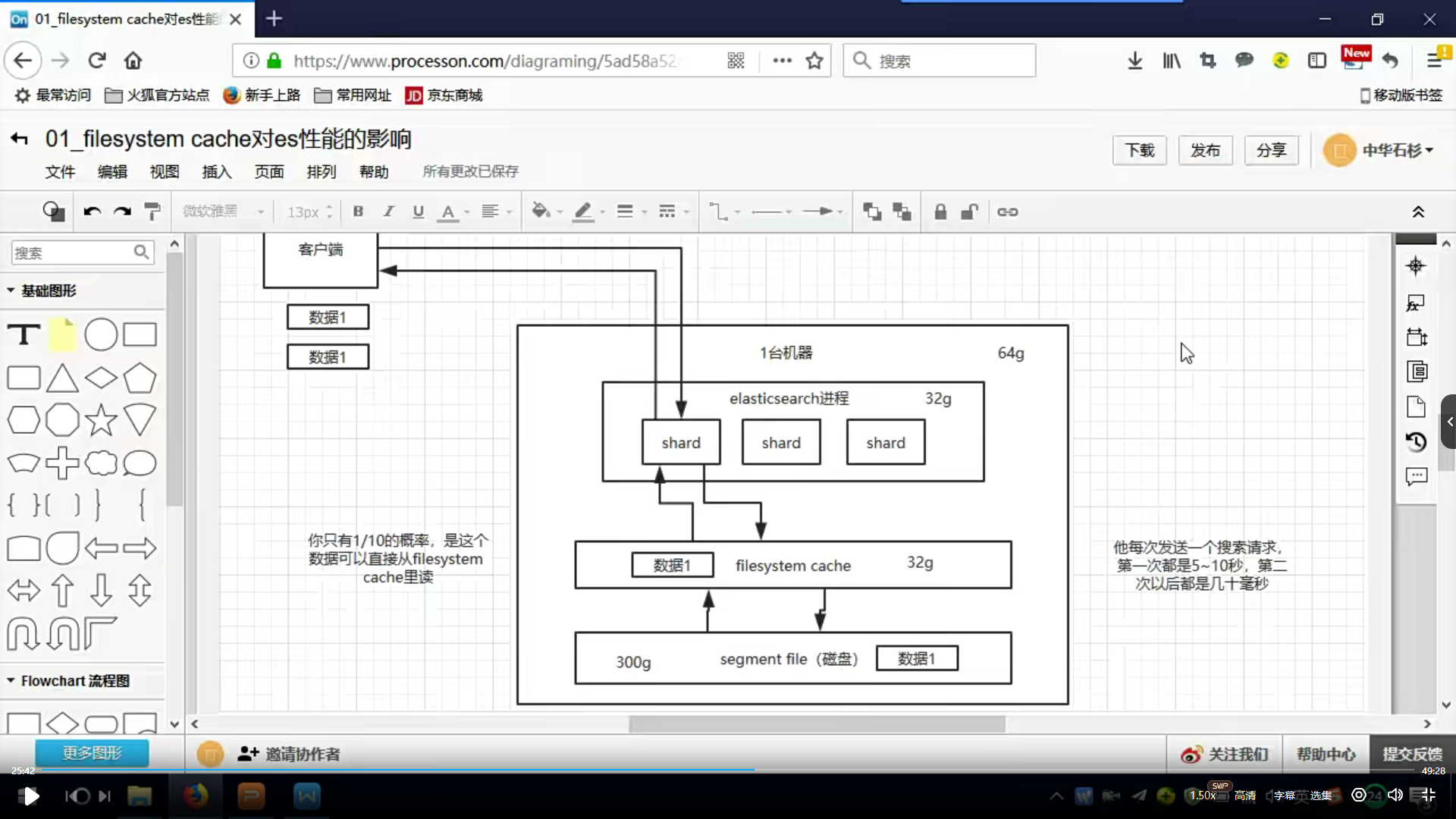](https://img-blog.csdnimg.cn/de7c971ee16144a69cbd7b3dcd14e93a.png)
数据预热
自己去自动检索一些使用量较高的数据,从而将之存入缓冲中,达到二次检索高效的目的
冷热分离
es做类似于mysql的一个水平差分,将放访问低的数据单独建立一个索引,访问量大的数据单独建一个索引,达到一宗冷热分离了的目的,可以避免冷数据将filesystem cache的位置占用
document模型的设计
es里面的复杂查询尽量不要使用,否则会极大的影响性能.一般性能不大好.
分页性优化
es的分页性能较差,比较坑
es需要将你查询的数据位置之前那的数据都整理到一个shard节点,然后才能获取你要查询的那一条数据
这样就需要对es做一些要求
1.不允许深度分页/默认深度分页性能很差
2.类似与app中的下拉页拉出来的一页一页,可以使用scroll api
scroll会一次性直接生成所有数据的快照,然后会根据不同的游标定位到不同的资源,这样的性能很快比起es的翻页高效很多
无论返多少页,性能都是毫秒级别的
但是scroll api只能往后翻,不可以跳跃,所以只能用于类似微博那种应用