#某宝评论接口sign参数逆向
1.接口速览
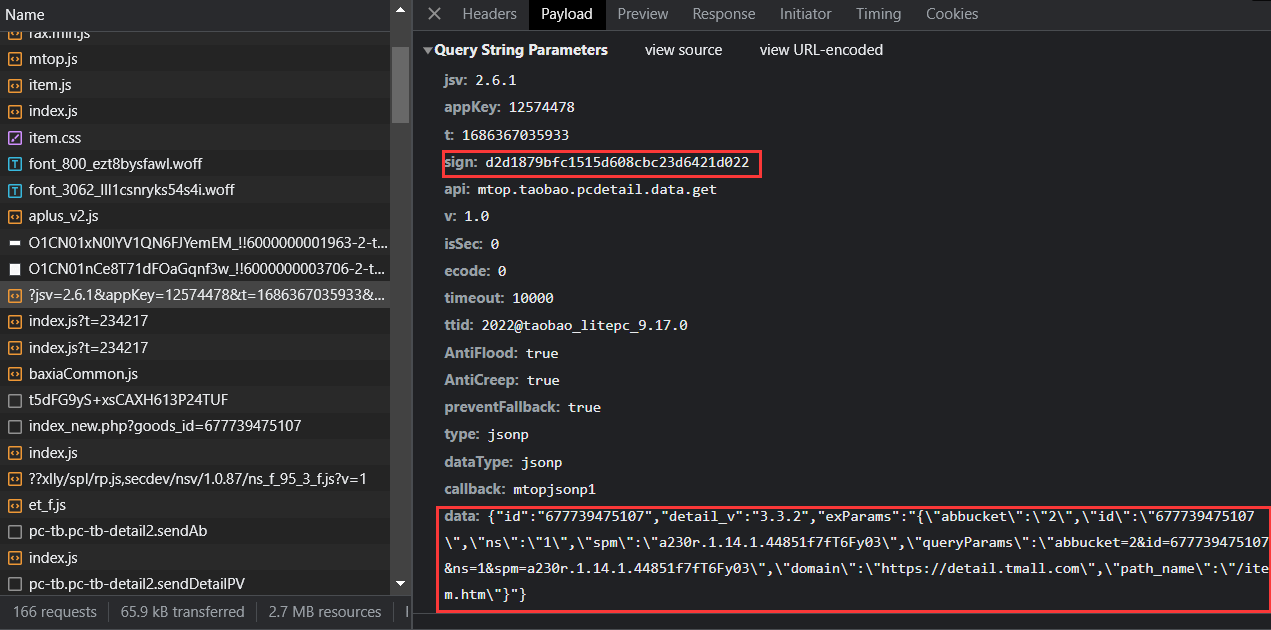
多次请求发现,t为时间戳,sign为加密参数,盲猜和data、t有关,sign为32位,盲猜是字符串的32位的MD5
2.搜索js代码

这里为搜索的是appKey,就找到了sign,然后看上面的加密函数,很像MD5,于是进入调试,看看是不是原生的MD5
3.js调试
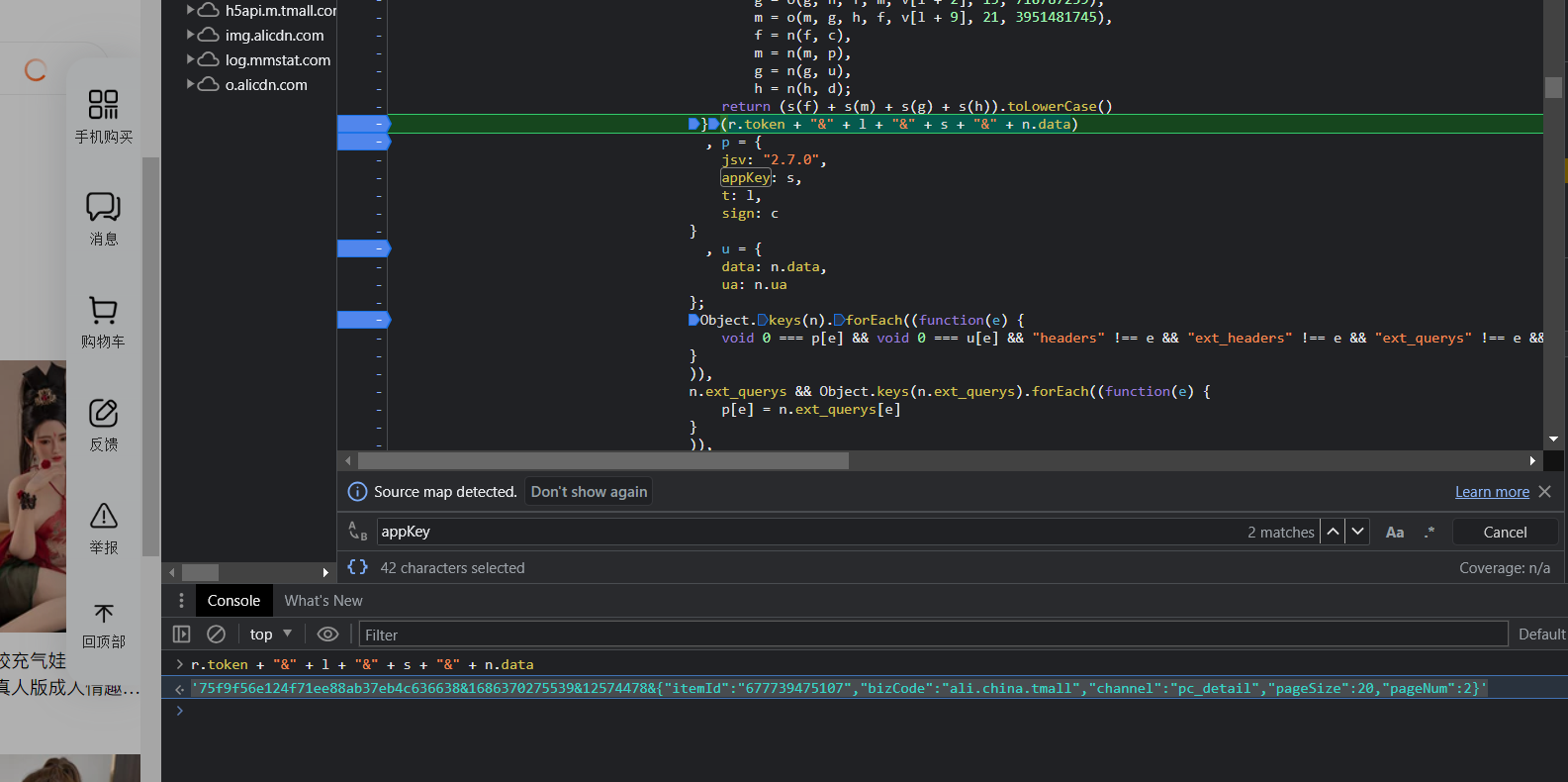
调试时,发现传入MD5(假设就是)的参数是几个参数进行了拼接
var token = '75f9f56e124f71ee88ab37eb4c636638' //固定的
var data = '{"itemId":"677739475107","bizCode":"ali.china.tmall","channel":"pc_detail","pageSize":20,"pageNum":2}' //评论相关的参数,包括商品的ID、评论的页数等
var l = 1686368240577 //(new Date()).getTime() //这个就是时间戳而已
var s = '12574478' //这个参数在js的上面能看到是固定的,多次请求也能发现
var p1 = token + "&" + l + "&" + s + "&" + data //进行拼接
我们把上面的拼接后的值去MD5加密看看,待会和网页产生的一不一样,就能知道,他的加密是不是就是原生的MD5,而没有进行魔改
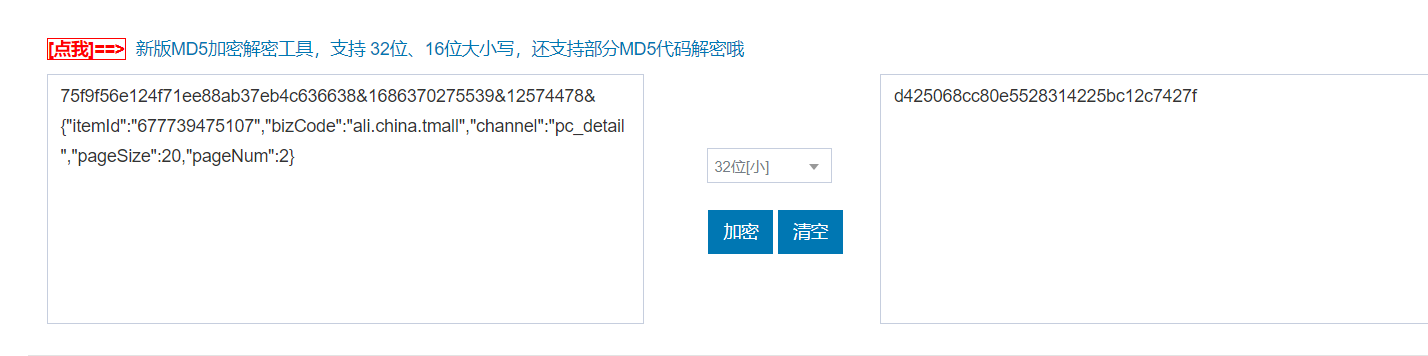
得到d425068cc80e5528314225bc12c7427f,继续步进js调试,可以看到网页生成的sign和原生的md5加密是一样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mSsfAp6B-1686373101298)(null)]
4.模拟请求
import json
import re
import time
import requests
import hashlib
from pygments import highlight, lexers, formatters
def get_sign(string):
return hashlib.md5(string.encode()).hexdigest()
def req(sign,now,data):
cookies = {
#添加你自己的cookies
}
headers = {
'authority': 'h5api.m.tmall.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'referer': 'https://detail.tmall.com/',
'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
params = {
'jsv': '2.7.0',
'appKey': '12574478',
't': now,
'sign': sign,
'api': 'mtop.alibaba.review.list.for.new.pc.detail',
'v': '1.0',
'isSec': '0',
'ecode': '0',
'timeout': '10000',
'ttid': '2022@taobao_litepc_9.17.0',
'AntiFlood': 'true',
'AntiCreep': 'true',
'preventFallback': 'true',
'type': 'jsonp',
'dataType': 'jsonp',
'callback': 'mtopjsonp3',
'data': data,
}
response = requests.get(
'https://h5api.m.tmall.com/h5/mtop.alibaba.review.list.for.new.pc.detail/1.0/',
params=params,
cookies=cookies,
headers=headers,
)
json_str = re.findall(r'mtopjsonp3\((.*?)\)',response.text)
content = json.loads(json_str[0])
formatted_json = json.dumps(content, indent = 4, ensure_ascii = False, sort_keys = True)
colorful_json = highlight(formatted_json, lexers.JsonLexer(), formatters.TerminalFormatter())
print(colorful_json)
def get_time_13():
return int(time.time()*1000)
if __name__ == "__main__":
token = '换成你自己的token'
pageNum = 1 #1-6页能爬取
data = f'{"itemId":"677739475107","bizCode":"ali.china.tmall","channel":"pc_detail","pageSize":20,"pageNum":{pageNum}}'
l = get_time_13()
s = '12574478'
p1 = token + "&" + str(l) + "&" + s + "&" + data
print(p1)
sign = get_sign(p1)
req(sign=sign,now=l,data=data)
运行结果如下图:
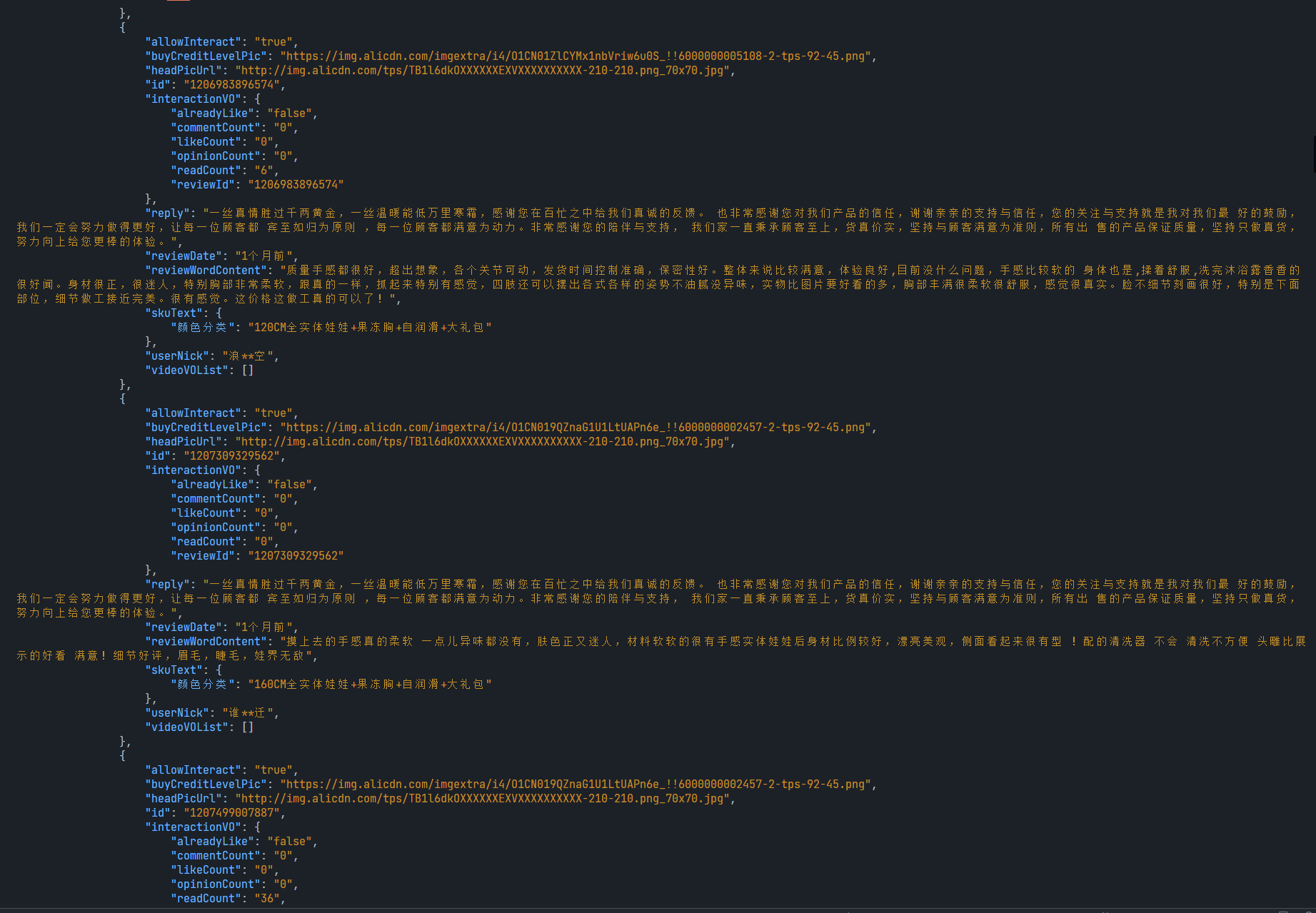
(sign=sign,now=l,data=data)
运行结果如下图:
[[外链图片转存中...(img-sotFdP7B-1686373096567)]](https://imgse.com/i/pCEohhq)
`qq讨论群:529528142`