1.元素袋:将自然文本转换为扁平向量
1.1 词袋
词袋将一个文本文档转换为一个扁平向量。之所以说这个向量是“扁平”的,是因为它
文本数据:扁平化、过滤和分块|35不包含原始文本中的任何结构。原始文本是一个单词序列,但词袋中没有任何序列,它只记录每个单词在文本中出现的次数。
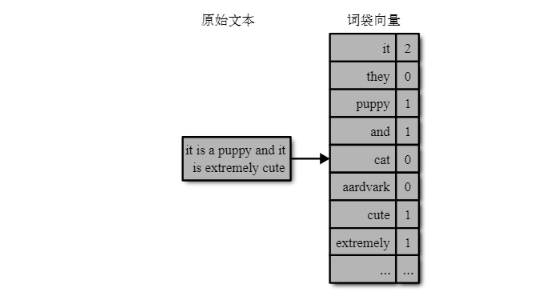
在词袋特征化中,一篇文本文档被转化为一个计数向量。(向量就是n个数值的集合。)这个计数向量包含词汇表中所有可能出现的单词。如果某个单词(比如“aardvark”)在文档中出现了3次,那么特征向量在对应于这个单词的位置就有一个计数值3。如果词汇表中的某个单词没有出现在文档中,那么它的计数值就是0。例如,文本“it is a puppy and it is extremely cute”
1.2 n元词袋
n元词袋(bag-of-n-grams)是词袋的一种自然扩展。n-gram(n元词)是由n个标记(token)组成的序列。1-gram就是一个单词(word),又称为一元词(unigram)。经过分词(tokenization)之后 ,计数机制会将单独标记转换为单词计数,或将有重叠的序列作为n-gram进行计数。例如,句子“Emma knocked on the door”会生成n-gram“Emma knocked”“knocked on”“on the”和“the door”。
import pandas as pd
import json
from sklearn.feature_extraction.text import CountVectorizer
# 加载前10 000条点评
f = open(r'../data/yelp_academic_dataset_review.json')
js = []
for i in range(10000):
js.append(json.loads(f.readline()))
f.close()
review_df = pd.DataFrame(js)
review_df
# 创建一元词、二元词和三元词的特征转换器。
# 默认情况下,会忽略单字母词,这非常有实际意义,
# 因为会除去无意义的词。但在这个例子中,
# 出于演示的目的,我们会显式地包含这些词。
bow_converter = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
bigram_converter = CountVectorizer(ngram_range=(2,2),token_pattern='(?u)\\b\\w+\\b')
trigram_converter = CountVectorizer(ngram_range=(3,3),token_pattern='(?u)\\b\\w+\\b')
# 拟合转换器,查看词汇表大小
bow_converter.fit(review_df['text'])#一元
words = bow_converter.get_feature_names_out()
bigram_converter.fit(review_df['text'])#二元
bigrams = bigram_converter.get_feature_names_out()
trigram_converter.fit(review_df['text'])#三元
trigrams = trigram_converter.get_feature_names_out()
print (len(words), len(bigrams), len(trigrams))
# 看一下n-gram
print(words[:10])
print(bigrams[-10:])
print(trigrams[:10])
2.用过滤获取清洁特征
何通过单词将文本中的信号和噪声准确地区分开呢?使用过滤,那些通过原始分词和计数来生成单词或n-gram列表的技术将变得更有用。
主要有以下几种:
2.1停用词
分类和提取通常不要求对文本进行深入的理解。例如,在句子“Emma knocked on the door”中,单词“on”和“the”并不能改变这个句子是关于一个人和一扇门这样的事实。在像分类这样的粗粒度任务中,代词、冠词和介词没有什么价值。但在情感分析中,情况就完全不同了,它需要对语义进行细粒度的深刻理解。
Python中通用的NLP包NLTK中包含了一个由语言学家定义的停用词列表,适用于多种语言。(你需要先安装NLTK,并运行nltk.download()来获取完整功能。)在网上也可以找到各种停用词列表。
例如,下面是英语停用词列表中的一些词:
a, about, above, am, an, been, didn't, couldn't, i'd, i'll, itself, let's, myself,
our, they, through, when's, whom, ...
注意,这个列表中包含撇号,而且单词是小写的。如果想直接使用这个列表,分词过程就
不能忽略撇号,而且要将单词转换为小写。
2.2基于频率的过滤
停用词列表是一种剔除形成无意义特征的单词的方法。还有一些更具统计性的方法可以找出这些没有实际意义的单词。在搭配提取方法中,有一些依赖人工定义的方法,也有一些运用统计学的方法。在单词过滤中,我们可以应用同样的思想,也可以使用频率统计。
2.2.1高频词
频率统计是一种非常强大的过滤技术,既可以过滤语料库专用的常见单词,也可以过滤通用的停用词。例如,短语“New York Times”以及其中的每个单词在纽约时报注释语料库数据集(New York Times Annotated Corpus dataset)中都频繁出现。同样,单词“house”频繁出现在英国议会演讲语料库(Hansard corpus)中的短语“House of Commons”中,这个语料库中的加拿大议会辩论数据集常用于统计机器翻译,因为它包括所有文件的英文和法文版本。这些单词一般来说是有意义的,但在特定语料库中则不然。典型的停用词列表会包括通用的停用词,但不包括语料库专用的停用词。
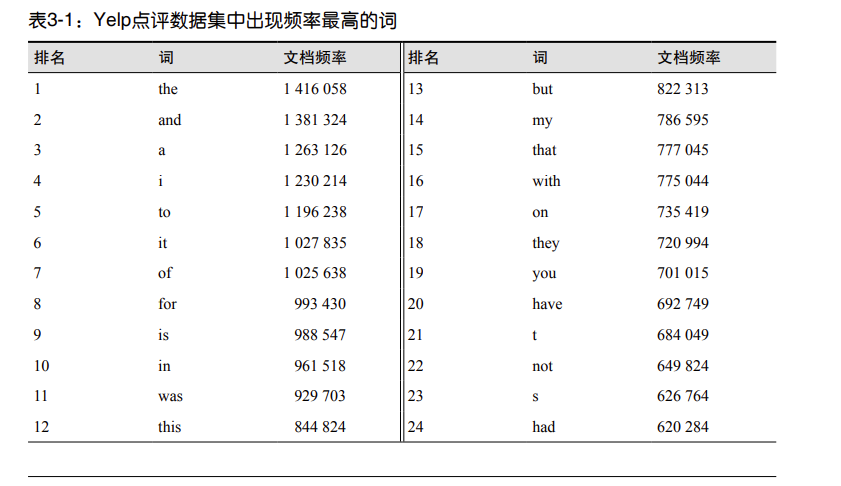
检查一下出现频率最高的单词,可以发现文本解析时的问题,并能标记出那些碰巧在语料
库中出现多次的通常有用的词。举例来说,表 3-1 列出了 Yelp 点评数据集中出现频率最高
的 40 个词。这里的频率指的是包含这个词的文档(点评)数,并不是它在一篇文档中出
现的次数。正如我们所看到的,这个列表中有很多停用词。我们还有一些意外的发现,列
表中有“s”和“t”,这是因为我们使用了撇号作为分词的分隔符,于是像“Mary’s”或
“didn’t”这样的词就被解析为“Mary s”和“didn t”。此外,“good”“food”和“great”都
出现在了大约三分之一的点评中,但我们要保留它们,因为它们在像情感分析和商家分类
这样的任务中是非常有用的。
2.2.2罕见词
根据任务的不同,有时还需要过滤掉罕见词。罕见词可能是真正的生僻词,也可能是拼写错误的普通词。对于统计模型来说,只在一两篇文档中出现的词更像是噪声,而不是有用信息。例如,假设我们的任务是基于Yelp点评数据对商家进行分类,而且只有一条点评中包含“gobbledygook”这个词。那么基于这么一个词,怎么能辨别出这个商家是餐馆、美发沙龙,还是酒吧呢?在这种情况下,即使知道这个商家是个酒吧,如果将包含“gobbledygook”这个词的其他点评划分为酒吧,也很可能是个错误。
罕见词不仅无法作为预测的凭据,还会增加计算上的开销。Yelp点评数 据集中有160万条点评数据,包括357 481个单词(根据空格和标点符号进行分词),其中有189 915个单词只出现在一条点评中,有41 162个单词出现在两条点评中。词汇表中60%以上的词都是罕见词。这就是所谓的重尾分布,在实际数据中这种分布屡见不鲜。很多统计机器学习模型的训练时间是随着特征数量线性增长的,但有些模型则是平方增长或更糟糕。罕见词带来了很大的计算和存储成本,却收效甚微。
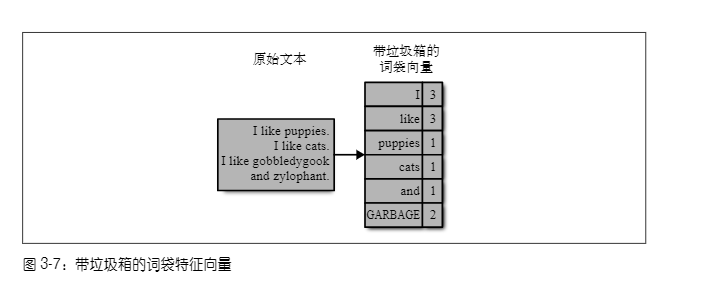
在单词数量统计的基础上,可以轻松地识别并清理罕见词。或者,也可以将罕见词的数量累加到一个特殊的垃圾箱内,作为一个附加特征。图3-7使用一个简短文档演示了这种方法,文档中有一些常见词,以及两个罕见词“gobbledygook”和“zylophant”。常见词使用它们本身的计数,可以进一步通过停用词列表或其他基于频率的方法进行过滤。对于罕见词,则不做区分,统一放到垃圾箱特征中。
因为在对整个语料库进行计数统计之前,不知道哪些词是罕见的,所以垃圾箱特征只能在后处理阶段进行收集。罕见性这个概念也可以应用在数据点上。如果一个文本文档非常短,那么它很可能不会包含什么有价值的信息,在训练模型时不应该使用它。但是,在应用这条原则时一定要小心。Wikipedia dump语料库中有很多页还是未完成状态,过滤掉这些页应该是很安全的。推文则是另一种情况,它天生简短,需要专门的特征化和建模技巧。
2.3词干提取
文本的简单解析有一个问题,就是同一个单词的各种变体会被视为不同的词而分别计数。例 如 ,“flower”和“flowers”在技术上是两个不同的标记,“swimmer”“swimming”和“swim”也是一样的情况,尽管它们的含义非常相近。如果这些不同变体能映射为同一单词,那文本解析的效果会更好。
词干提取是一种将每个单词转换为语言学中的基本词干形式的NLP技术。词干提取有多种方法,有的基于语言学规则,有的基于统计观测。有一种算法子类综合了词性标注和语言规则,这种处理过程称为词形还原。
注意:词形还原不是万能的
多数词干提取工具都将英语作为重点,但针对其他语言的工具也在蓬勃发展。Porter stemmer 是应用最为广泛的免费英语词干提取工具。虽然最初的程序是用 ANSI C 开发的, 但有很多程序包对其进行了包装,提供了各种语言接口。
下面是一个通过 Python 的 NLTK 包运行 Porter stemmer 的例子。正如你看到的,它适用于 很多情况,但不是万能的。“goes”被映射到了“goe”,而“go”被映射到了它本身。
import nltk
stemmer = nltk.stem.porter.PorterStemmer()
stemmer.stem('flowers')
print(stemmer.stem('zeroes'))
print(stemmer.stem('stemmer'))
print(stemmer.stem('sixties'))
print(stemmer.stem('sixty'))
print(stemmer.stem('goes'))
print(stemmer.stem('go'))
词干提取确实有一些计算成本,最终的收益能否超过成本要视具体应用而定。值得注意的
是,使用词干提取可能得不偿失。“new”和“news”具有非常不同的意义,但都会被提取
为“new”。同样的例子还有不少。基于这个原因,词干提取并不是非做不可。
3.从单词、n元词到短语
3.1解析与分词
当字符串不只包含纯文本时,解析就是必须的。例如,如果原始数据是网页、电子邮件或某种日志,那么其中就含有其他结构。需要确定如何处理标记、头部和尾部,以及日志中不感兴趣的部分。如果文档是个网页,那么解析程序还需要处理URL。如果文档是封电子邮件,那么像发件人、收件人和标题这些域都需要特殊处理,否则这些头信息在最终计数中就会和普通词一样,也就失去作用了。
经过简单解析之后,就可以对文档的纯文本部分进行分词了,这会将字符串——一个字符序列——转换为一个标记序列。每个标记都可以作为一个单词来计数。分词程序需要知道哪些字符表示一个标记已经结束而且另一个标记已经开始了。空格通常是一个非常好的分隔符,标点符号也是一样。有时候,分析需要在句子上而不是整个文档上进行。例如,n元词(n-gram)是单词概念的一个推广,它就不能超过句子的边界。像word2vec这样比较复杂的文本特征化方法也是工作在句子或段落上的。在这种情况下,我们需要先将文档解析为句子,然后再对每个句子进行分词,得到单词。
3.2通过搭配提取进行短语检测
通过标记序列可以立刻得到单词和n元词列表。但是,从语义上说,我们更习惯于理解短语,而不是n元词。在计算机自然语言处理(NLP)中,有用短语的概念被称为搭配(collocation)。 用Manning和Schütze的话来说:“搭配是一种表达方式,它由两个或两个以上的单词组成,并对应于某种约定俗成的事物说明。”搭配非常适合用作特征。
3.2.1 基于频率的方法
一种简单方法是查看那些出现频率最高的n元词。这种方法的思想和问题是最常出现的词不一定是最有用的。
3.3.3文本分块和词性标注
文本分块要比找出 n 元词复杂一些,复杂之处在于,它要使用基于规则的模型并基于词性生成标记序列。
举例来说,或许我们最感兴趣的是找出一个问题中的所有名词短语,即这个问题中的实体(在下面的例子中是文本标题)。为了找出这些短语,我们先切分出所有带词性的单词,然后检查这些标记的邻近词,找出按词性组合的词组,这些词组又称为“块”。将单词映射到词性的模型通常与特定的语言有关。一些开源的 Python 程序库(比如 NLTK、spaCy 和TextBlob)中带有适用于多种语言的模型。
使用 spaCy 和 TextBlob 通过判断词性来找出名词短语。
(1)使用TextBlob
import pandas as pd
import json
f = open(r'../data/yelp_academic_dataset_review.json')
js = []
for i in range(10):
js.append(json.loads(f.readline()))
f.close()
review_df = pd.DataFrame(js)
# TextBlob中的默认标记器使用PatternTagger,在这个例子中是没有问题的。还可以指定使用NLTK标记器,它对于不完整的句子效果更好。
from textblob import TextBlob
blob_df = review_df['text'].apply(TextBlob)
blob_df[4].tags
输出内容:
[('General', 'NNP'),
('Manager', 'NNP'),
('Scott', 'NNP'),
('Petello', 'NNP'),
('is', 'VBZ'),
('a', 'DT'),
('good', 'JJ'),
('egg', 'NN'),
('Not', 'RB'),
('to', 'TO'),
('go', 'VB'),
('into', 'IN'),
('detail', 'NN'),
('but', 'CC'),
('let', 'VB'),
('me', 'PRP'),
('assure', 'VB'),
('you', 'PRP'),
('if', 'IN'),
('you', 'PRP'),
('have', 'VBP'),
('any', 'DT'),
('issues', 'NNS'),
('albeit', 'IN'),
('rare', 'NN'),
('speak', 'NN'),
('with', 'IN'),
('Scott', 'NNP'),
('and', 'CC'),
('treat', 'VB'),
('the', 'DT'),
('guy', 'NN'),
('with', 'IN'),
('some', 'DT'),
('respect', 'NN'),
('as', 'IN'),
('you', 'PRP'),
('state', 'NN'),
('your', 'PRP$'),
('case', 'NN'),
('and', 'CC'),
('I', 'PRP'),
("'d", 'MD'),
('be', 'VB'),
('surprised', 'VBN'),
('if', 'IN'),
('you', 'PRP'),
('do', 'VBP'),
("n't", 'RB'),
('walk', 'VB'),
('out', 'RP'),
('totally', 'RB'),
('satisfied', 'JJ'),
('as', 'IN'),
('I', 'PRP'),
('just', 'RB'),
('did', 'VBD'),
('Like', 'IN'),
('I', 'PRP'),
('always', 'RB'),
('say', 'VBP'),
('.....', 'JJ'),
('Mistakes', 'NNS'),
('are', 'VBP'),
('inevitable', 'JJ'),
('it', 'PRP'),
("'s", 'VBZ'),
('how', 'WRB'),
('we', 'PRP'),
('recover', 'VBP'),
('from', 'IN'),
('them', 'PRP'),
('that', 'WDT'),
('is', 'VBZ'),
('important', 'JJ'),
('Thanks', 'NNS'),
('to', 'TO'),
('Scott', 'NNP'),
('and', 'CC'),
('his', 'PRP$'),
('awesome', 'JJ'),
('staff', 'NN'),
('You', 'PRP'),
("'ve", 'VBP'),
('got', 'VBN'),
('a', 'DT'),
('customer', 'NN'),
('for', 'IN'),
('life', 'NN'),
('..........', 'NN'),
('^', 'NN')]
(2)使用spaCy
pip install spacy -i https://pypi.tuna.tsinghua.edu.cn/simple
首选安装该模块之后,进行下载语言模型:
conda install -c conda-forge spacy-model-en_core_web_sm
更多语言模型下载的地址:https://github.com/explosion/spacy-models/tags
import spacy
# 预先加载语言模型
nlp = spacy.load('en_core_web_sm')
# 我们可以创建一个spaCy nlp变量的Pandas序列
doc_df = review_df['text'].apply(nlp)
# spaCy可以使用(.pos_)提供细粒度的词性,
# 使用(.tag_)提供粗粒度的词性
for doc in doc_df[4]:
print([doc.text, doc.pos_, doc.tag_])
![[starrocks BE] 启动报错问题记录](https://img-blog.csdnimg.cn/9dde11cd9ce8411cb4f2632c41b1fecd.png)