目录
- 1.char varchar 长度是字符数还是字节数 编码格式
- 2.整型数据类型
- 3.decimal及其实现
- 4.慢查询
- 5.索引失效
- 6.explain
- 7.for foreach性能差异
- 8.数据库事务隔离级别
- 9.binlog redolog 二阶段提交
- 10.redis数据类型
- 11.redis实现消息队列
- 12.mybatis传参方法
- 13.insert返回主键
1.char varchar 长度是字符数还是字节数 编码格式
CHAR和VARCHAR数据类型的长度是以字节数为单位来计算的。
编码格式:UTF-8
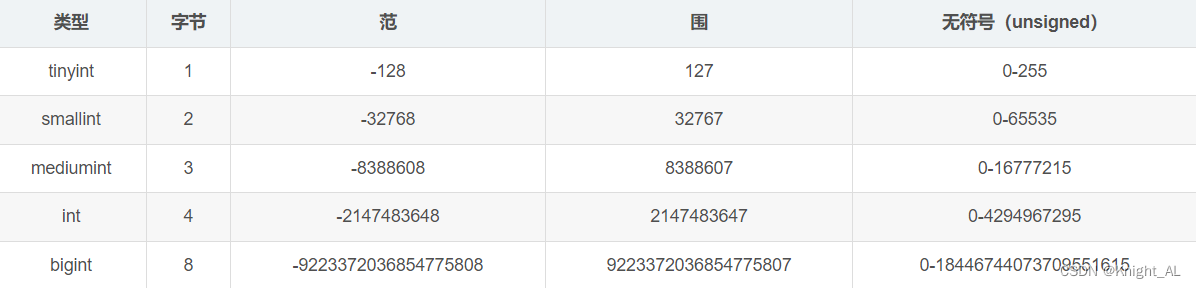
2.整型数据类型
3.decimal及其实现
在MySQL中,DECIMAL是一种用于存储精确数字的数据类型。它可以存储固定精度的小数,即指定小数点前后的位数。DECIMAL类型的语法如下:
DECIMAL(M, D)
其中,M表示数字的总位数,D表示小数点后的位数。例如,DECIMAL(10, 2)可以存储10位数字,其中小数点后有2位。
4.慢查询
如果不熟悉可以看这篇
Mysql查询截取分析_慢查询日志
开启慢查询
set global slow_query_log=1
设置慢查询的时间
SET GLOBAL long_query_time=0.1;
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
使用mysqldumpslow去分析,查找sql,然后在使用explain进行分析

5.索引失效
最佳左前缀法则
过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
计算、函数导致索引失效
范围条件右边的列索引失效
建议:将可能做范围查询的字段的索引顺序放在最后
不等于(!= 或者<>)索引失效
is not null无法使用索引,is null可使用索引
like以通配符%开头索引失效
6.explain
常用的字段id,type,key_len,rows,extra
7.for foreach性能差异
性能差异需要分情况讨论
1、循环ArrayList时
结果:普通for循环比foreach循环花费的时间要少一点
原因:使用下标访问效率本身很高.foreach内部的循环直接封装下标,自己实现的for比foreach更直接,效率稍高些,但差别不会太大,仍然在一个数量级上。
2、循环LinkList时
结果:普通for循环比foreach循环花费的时间要多很多。
原因:如果使用插入和删除效率高的LinkedList,for基于下标访问会每次从头查询,效率会很低.foreach循环子使用高效的地址运算,效率会高.其差距将很大,完全不在一个数量级别.如果数组很大,差别可能会几百甚至上千倍
8.数据库事务隔离级别
-
未提交读(Read uncommitted):是最低的隔离级别,允许一个事务读取另一个事务未提交的数据。这种隔离级别会导致脏读、不可重复读和幻读等问题。
-
已提交读(Read committed):是大多数数据库的默认隔离级别。它允许一个事务读取另一个事务已经提交的数据,避免了脏读的问题。但是,不可重复读和幻读问题仍然可能出现。
-
可重复读(Repeatable read):保证在一个事务执行期间,多次读取同一数据时,其值不会发生改变。这种隔离级别避免了脏读和不可重复读的问题,但是仍然可能现幻读问题。
-
串行化(Serializable):是最高的隔离级别,它通过强制事务串行执行来避免脏读、不可重复读和读等问题。但是,这种隔离级别会导致并发性能下降,因为它会对数据进行加锁,从而限制并发访问。
9.binlog redolog 二阶段提交
MySQL事务提交的时候,需要同时完成redolog和binlog的提交,为了保证两个日志的一致性,需要用到两阶段提交(与分布式的两阶段提交不同,这里的两阶段提交是发生在数据库内部)
数据库两阶段提交的流程
假设执行一条SQL语句:
update T set c=c+1 where ID=2;
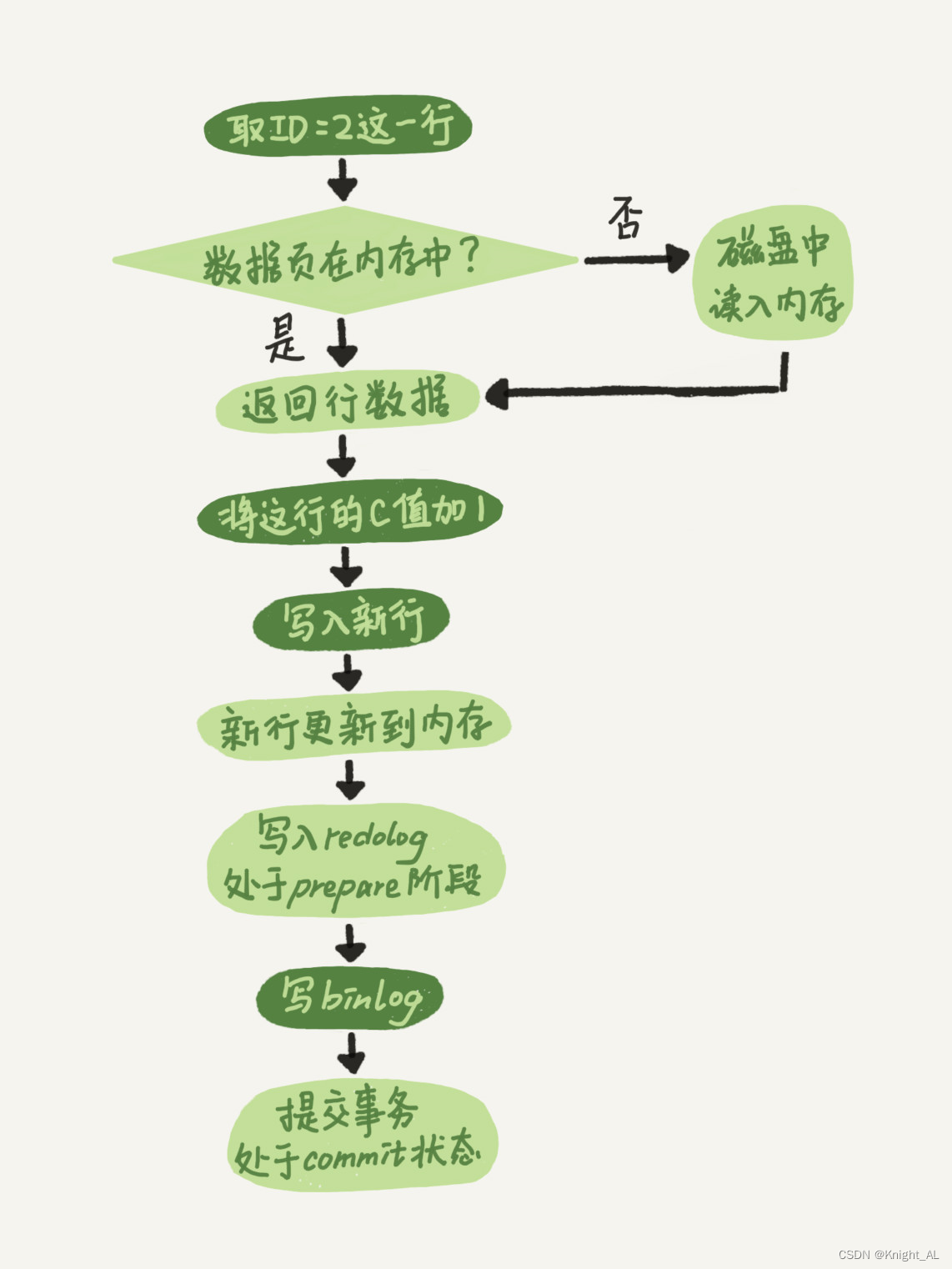
两阶段流程
从图中可以看出,在最后提交事务的时候,需要有3个步骤:
- 写入redo log,处于prepare状态
- 写binlog
- 修改redo log状态为commit
ps: redo log的提交分为prepare和commit两个阶段,所以称之为两阶段提交
为什么需要两阶段提交?
假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
如何完成崩溃恢复
流程中崩溃可能导致问题如下图:
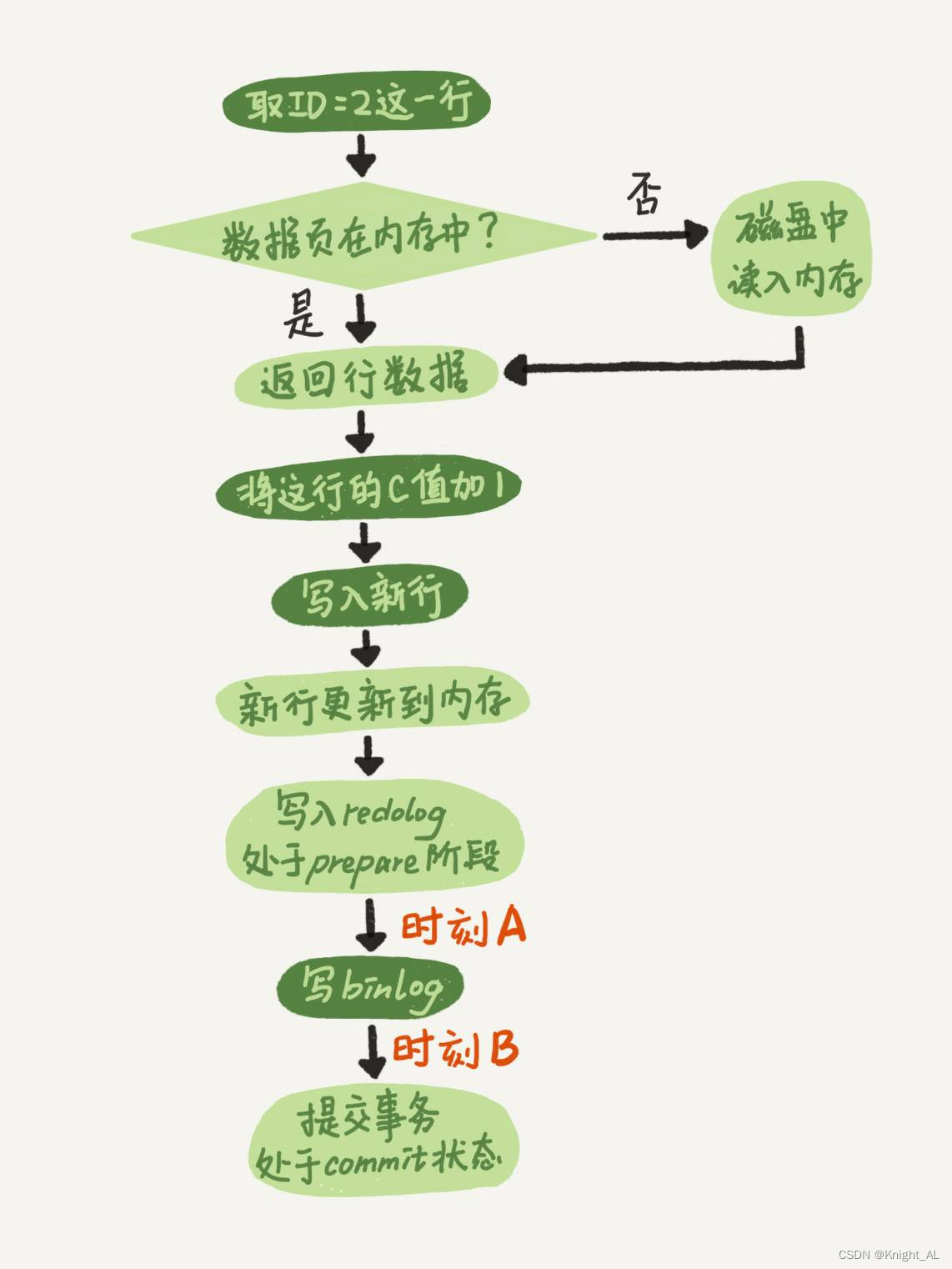
崩溃恢复
如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了崩溃(crash),由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库。
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
10.redis数据类型
String
List
Hash
Set
ZSet
11.redis实现消息队列
Redis 实现 MQ 主要有三种方案:
(1)List 结构;
(2)Pub/Sub 模式;
(3)Stream 结构。
12.mybatis传参方法
第一种情形,传入单个参数 userId
第二种情况,传入多个参数 userId,sex 使用索引对应值(不建议)
第三种情形,传入多个参数 userId,sex 使用注解@Param
第四种情形,传入多个参数 使用User实体类传入
第五种情形,传入多个参数 使用Map类传入
13.insert返回主键
使用useGeneratedKeys属性和keyProperty属性来获取自动生成的主键值。以下是一个例子:
<insert id="insertUser" parameterType="User" useGeneratedKeys="true" keyProperty="id">
INSERT INTO users (username, password) VALUES (#{username}, #{password})
</insert>