DPDK全程是Intel Data Plane Development Kit,是一个数据平面开发集。
DPDK的主要思想
- 绕过内核,实现Zero Copy
- 使用UIO驱动屏蔽硬中断,并采用PMD主动轮询,减少Cache Miss和切换上下文的开销
- 使用大页内存,减少TLB Miss
- 减少共享,降低锁竞争产生的开销
- 数据主动预加载,在访问随机数据前将其主动推送至Cache,降低Cache Miss。
- 为线程绑定固定的CPU,提高CPU亲和性。避免任务切换的开销。
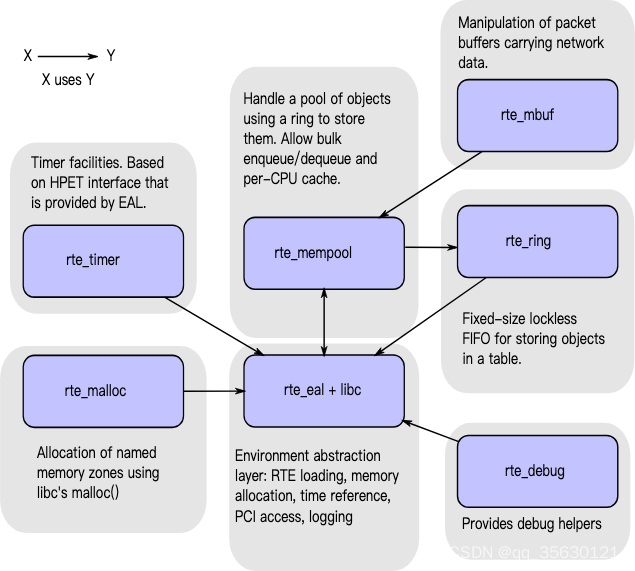
DPDK整体架构及依赖关系
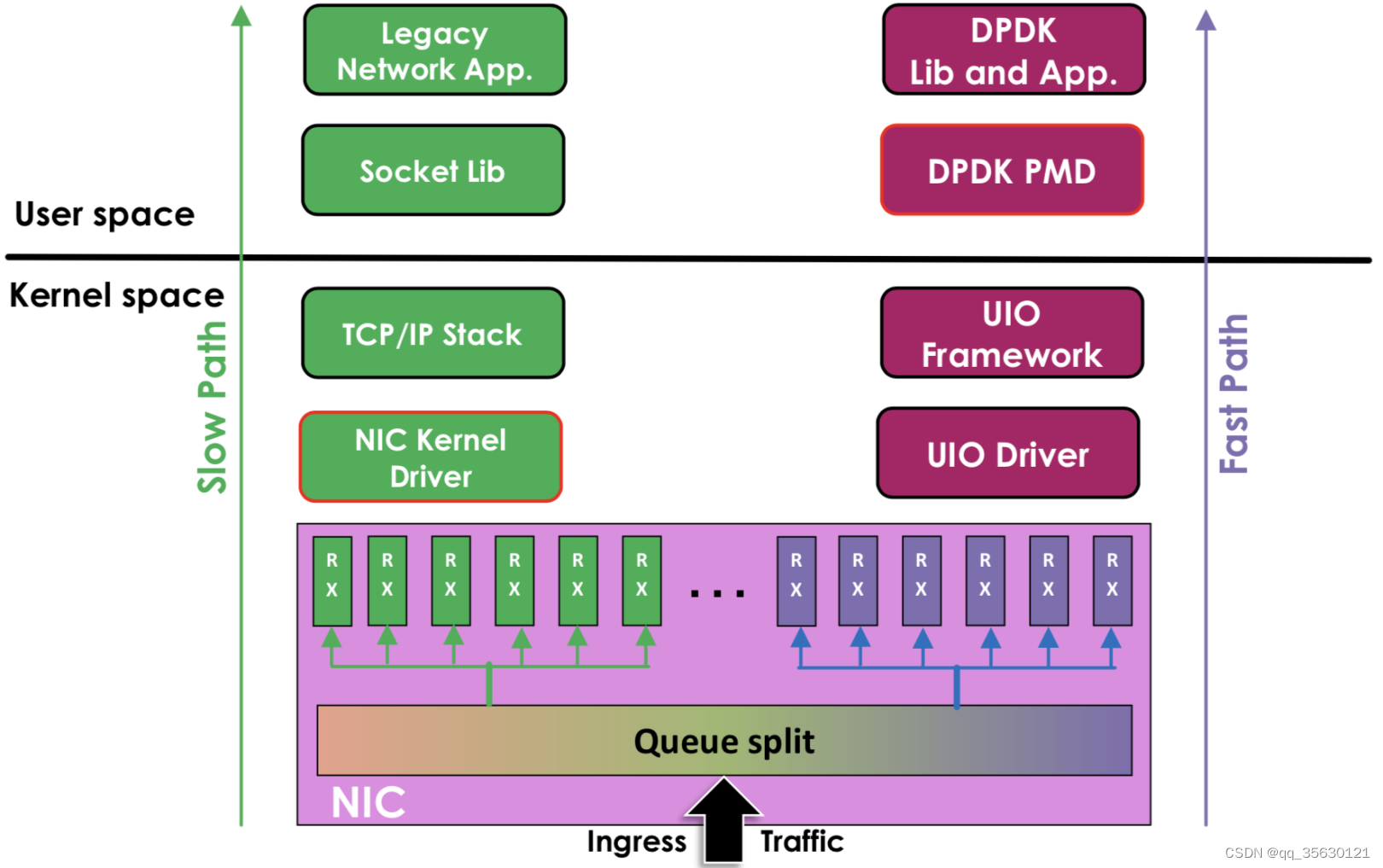
EAL
EAL(Environment Abstraction Layer),环境抽象层。在使用dpdk之前,需要指定其使用的具体环境,根据环境编译对应的库文件。是所有DPDK组件实现的基础。
应该可以这样理解,EAL的作用就是将许许多多底层资源的操作以及一些常用的功能例如日志、计数器等抽象包装成一个个接口,以实现调用。
在程序开始运行之前,所有硬件资源都会围绕core构成一个个unit,每个unit都可以完成数据包处理操作。
整个程序中不支持调度,即不支持中断,因为这回显著降低效率。所有任务都通过poll方式实现。
DPDK为使用人员提供了两种处理模型,一种是RTC模型,一种是pipeline模型。
pipeline模型中核分为rx核和tx核,rx核负责从网卡收包、初步解析、以及分发给对应的tx核。
rtc模型则是一个数据包从收取到发送全部使用同一个核。
TGW EIP使用的是RTC模型,因为EIP是无状态网关,不需要保留连接信息,所有数据包被每个核处理都是等价的,使用RTC模型效率更高。
TGW LD使用的是pipeline模型,因为LD需要保存连接信息,同一个流的出入包需要被同一个转发核处理,而TGW使用的是GRE封装,连接信息可能在外层IP、内层IP、甚至在GRE头中,目前的智能网卡分流无法满足我们的需求,因此需要rx核进行分流,再由tx核进行转发。
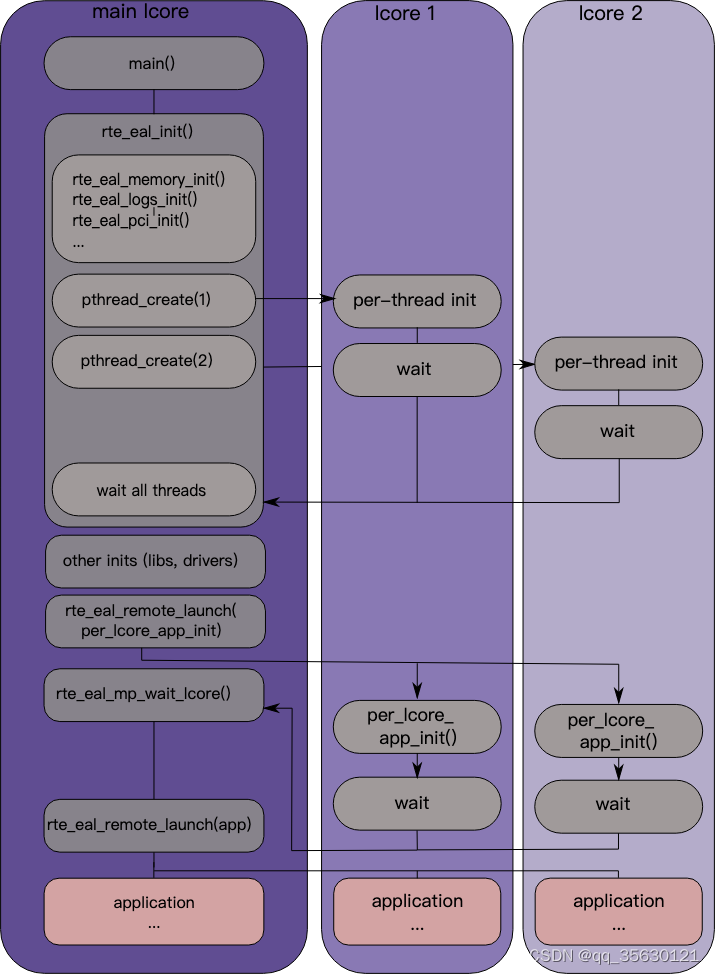
DPDK初始化及启动流程
内存分配:动态分配和传统分配两种模式,其中动态模式只在Linux中支持。动态模式使用rte_malloc分配内存,并在使用后通过rte_free释放。
日志:
lcore是一个EAL线程的另一种称呼,一个lcore可以绑定一个或多个CPU,为了提高运行效率,lcore与CPU通常为一对一绑定关系,因此一个lcore_id也可以视为一个CPU id。
lcore与CPU的绑定:
–lcores=’<lcore_set>[@cpu_set] [ ,<lcore_set> [@cpu_set], …] ’
例如:
–lcores=‘1,2@(5-7),(3-5)@(0,2),(0,6),7-8’ which means start 9 EAL thread;
lcore 0 runs on cpuset 0x41 (cpu 0,6);
lcore 1 runs on cpuset 0x2 (cpu 1);
lcore 2 runs on cpuset 0xe0 (cpu 5,6,7);
lcore 3,4,5 runs on cpuset 0x5 (cpu 0,2);
lcore 6 runs on cpuset 0x41 (cpu 0,6);
lcore 7 runs on cpuset 0x80 (cpu 7);
lcore 8 runs on cpuset 0x100 (cpu 8).