1、描述一下你们公司的性能测试流程?
1)分析性能需求(用户使用最频繁的场景进行测试)确定性能指标(例如:事务通过率100%,top99%是5秒,最大并发是2000,CPU和内存都是70%以下);
2)制定性能测试计划,明确测试时间、测试环境和测试工具;
3)编写测试用例
4)搭建测试环境,准备测试数据、编写测试脚本;
5)测试脚本优化:设置检查点,参数化,关联,集合点,事务,调整思考时间等;
6)设计测试场景,运行测试脚本和监控服务器;
7)分析测试结果,收集相关日志提单给开发;
8)回归测试;
9)编写测试报告。
Python自动化测试学习交流群:全套自动化测试面试简历学习资料获取点击链接加入群聊【python自动化测试交流】:![]() http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628

2、如果确定系统最大负载?
通过负载测试,不断增加用户数,随着用户数的增加,各项性能指标也会相应产生变化,当出现了拐点,如:当用户数达到某个数量级时,响应时间突然增长,那这个拐点就是系统的最大用户数。
3、并发数是怎么确定的?
1)先上线一段时间,根据收集到的用户访问数据进行预估;
2)根据需求来确定(使用高峰期,登录用户数,响应时间)。
4、性能测试在什么环境执行?
我们一般会搭建一套独立的性能测试环境进行测试
5、性能测试什么时候执行?
功能测试之后,系统比较稳定的时候做性能测试
6、性能测试需求的来源?
1)客户提供需求;
2)开发提供需求。
** 7、如何实现300用户的并发?**
绝对并发:在脚本对应的请求后添加集合点;
相对并发:线程组设置300线程数。
8、什么情况下要做关联,关联是怎么做的?
当脚本的上下文有联系则用关联;如:登录的token关联,增删改查主键ID。
9、有验证码的功能,怎么做性能测试?
1)将验证码暂时屏蔽,完成性能测试后,再恢复;
2)使用万能的验证码。
10、性能测试指标有哪些?分别是什么含义?
tps:每秒事务量,代表了系统的处理能力,tps越高,性能越好
响应时间:从发出请求到接受到系统响应数据所花费的时间,响应时间越短,性能越好
吞吐量:网络上行和下行流量的总和,吞吐量是网络瓶颈定位的重要指标
错误率:在压测过程中系统出现错误的比例
11、如果判断系统瓶颈?
从TPS指标分析,TPS即系统单位内处理事务的数量,观察当随着用户数的增长期系统每秒可处理的事务数是否也会增长。
12、如何分析性能测试结果?
首先看事务通过率,然后分析响应时间、CPU、内存等指标是否满足需求,如果结果不可信,则分析异常原因并复测
确定性能结果可信之后,如发现以下问题,按下面思路来定位问题:
1)响应时间不达标:首先看事务所消耗的时间主要是在网络传输还是服务器,如果是网络,就需要结合网络吞吐量图,计算宽带是否存在瓶颈,如果存在就需要考虑增加宽带;如果不存在则有可能是网络不稳定导致的。如果是服务器,就要分别查看web服务器和数据库服务器的CPU、内存的使用率是否过高,因为过高的CPU,内存必定会造成响应时间过长;
2)服务器CPU指标异常:把web服务器对应上对应的用户操作日志取下来,发给开发定位;
3)数据库CPU指标异常:把数据库服务器对应上对应的日期取下来,发给开发定位;
4)内存泄漏:把内存的heap数据取下来,分析是那个对象消耗内存最多,然后发给开发定位;
5)程序在单用户场景下运行成功,多用户运行失败,提示连不上服务器:程序可能是单线程处理机制。
13、你在性能测试中遇到哪些性能问题?
响应时间过长、tps过低、内存溢出、CPU使用率过高
14、性能测试如何防止数据污染?
生产数据备份、数据隔离、挡板
15、怎么根据线下环境评估线上环境的性能?
1)首先线下必须有专门的性能测试环境;
2)线下环境单台机器配置和线上不能相差很大,可以通过单台的机器性能推 算出多台机器性能;
3)如果线下机器配置差,只能测试出程序有无性能问题,这样搞线下测试处后来的数据对线上没有太大参考意义;
4)如果想获取比较准确的线上性能情况,建议最好做线上的性能测试。
Python自动化测试学习交流群:全套自动化测试面试简历学习资料获取点击链接加入群聊【python自动化测试交流】:![]() http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628

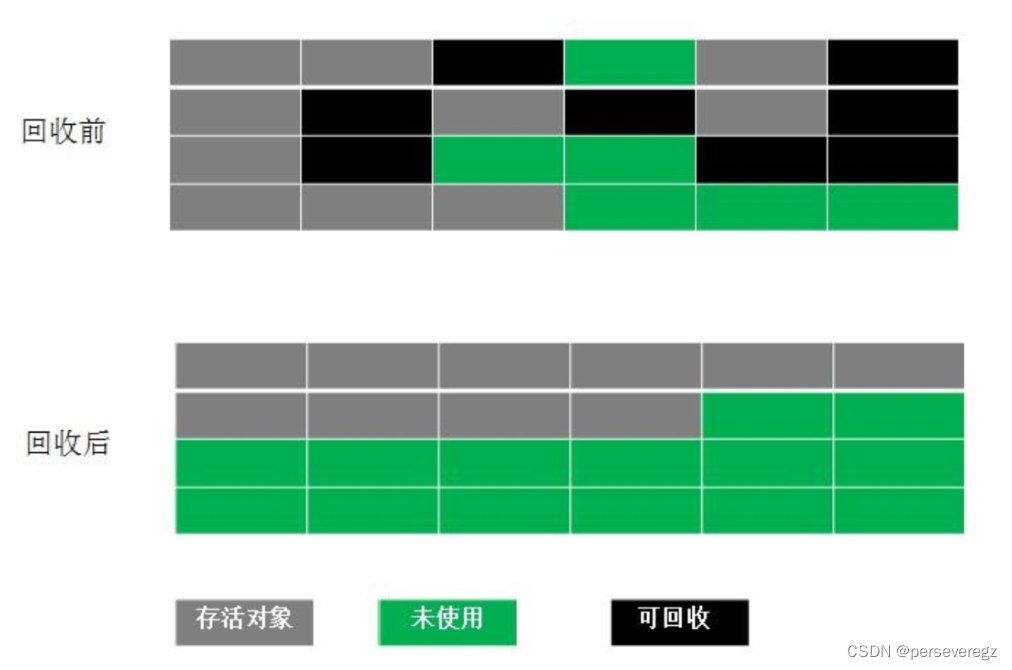
16、出现内存泄露的根本原因是什么?你是怎么定位内存泄露原因的?
原因:内存泄漏的根本原因是jvm中老年代中存在着大量存活的对象,这些对象不能被GC回收掉,从而占满了整个老年代,造成jvm一直处于FGC的状态,程序没有响应,服务器报oom错误;
定位问题:主要通过分析老年代中占用空间最大的类都有哪些,然后去代码中找对应的类的创建。通常可以使用jdk提供的jvisualvm和jmap进行堆内存的分析。
17、tps压不上去,可能有哪些方面的原因?
1)压力机本身性能瓶颈;
2)网络IO瓶颈;
3)中间件(tomcat/nginx/mysql)连接数限制;
4)JAVA线程的阻塞、等待;
5)本系统资源的瓶颈(cpu、内存、磁盘、网络等)。
18、性能场景怎么设计?一般都有哪些性能场景?
基本的场景包括:基准测试、单交易测试、混合测试、稳定性测试、高可用性测试、异常测试等
19、什么是集合点,什么场景下需要用集合点?
集合点是测试脚本中的一个标记,当每个虚拟用户执行到标记处时,会停留在标记处等待其他的虚拟用户,当达到预期设置的并发数时,标记处的所有用户同时启动执行后续的请求
集合点会产生瞬间高并发,但是也会降低平均压力。所以在压测过程中,如果有要求瞬间高并发的业务,就需要使用集合点,比如抢购,秒杀之类的业务
20、服务器的cpu使用率和load是什么关系?
通常情况下,cpu使用率和load值是正比关系,即cpu使用率越高,load值越高。但是在一些特殊情况下,也会出现cpu使用率不高,但是load值较高的情况,比如某系统只能使用CPU中的单核运行,它可以占用单核cpu100%,但从整体cpu使用率来看,只是使用了一小部分。而随着并发的增大,单核CPU的任务队列会越来越长,造成了load值较高
21、性能测试脚本中为什么要做参数化?
参数化把测试脚本中的请求数据动态化,避免使用单一固定参数进行压测。这也是为了更加真实的模拟用户的请求
22、性能脚本中的乱码问题怎么解决?
1)如果在脚本中不使用或不判断乱码部分的数据,那可用忽略此问题,因为乱码并不影响性能;
2)如果需要使用乱码数据,可以通过压测工具提供的一些方法进行编码转换。
23、在性能测试工具中,使用线程和进程压测有什么区别,Loadrunner和JMETER分别使用什么进行发压?
1)Loadrunner同时支持进程和线程发压。当选择进程时,每个虚拟用户单独启动一个进程,当选择线程时,每50个线程启动一个进程;
2)Jmeter只支持线程发压,进程和线程的主要区别为,进程之间是独享内存的,线程之间是共享内存的。使用进程压测占用的资源会大一些。在高并发下,会减少压测工具自身的异常情况。
24、性能测试脚本中,定义事务的原则是什么?
在测试脚本中,事务定义的业务流程越短越好。同时脚本中不要写过多复杂的逻辑,对于一个复杂的场景,可以考虑把脚本拆解成多个简单的脚本。
25,怎么进行性能场景设计?
1)单接口测试场景;
2)混合接口测试场景;
3)高可用性场景(集群情况下);
4)网络异常场景;
5)稳定性场景;
6)其他业务相关场景。
总结:
感谢每一个认真阅读我文章的人!!!
我个人整理了我这几年软件测试生涯整理的一些技术资料,包含:电子书,简历模块,各种工作模板,面试宝典,自学项目等。欢迎大家点击下方链接加入群聊免费领取,群聊里有大佬帮忙解决问题,千万不要错过哦。
Python自动化测试学习交流群:全套自动化测试面试简历学习资料获取点击链接加入群聊【python自动化测试交流】:![]() http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=DhOSZDNS-qzT5QKbFQMsfJ7DsrFfKpOF&authKey=eBt%2BF%2FBK81lVLcsLKaFqnvDAVA8IdNsGC7J0YV73w8V%2FJpdbby66r7vJ1rsPIifg&noverify=0&group_code=198408628










![P2[1-2]STM32简介(stm32简介+ARM介绍+片上外设+命名规则+系统结构+引脚定义+启动配置+最小系统电路+实物图介绍)](https://img-blog.csdnimg.cn/83b9ac2eb8a342b59391756331150525.png)