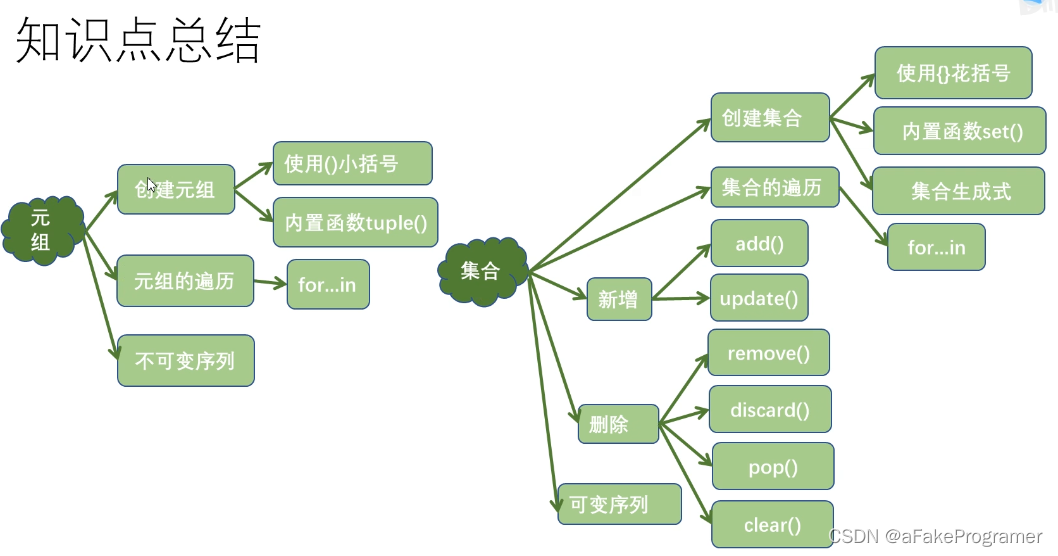
学习目标:
学习目标如下:
- SQL语句执行顺序
学习内容:
基本 SQL 命令:`
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- AGG_FUNC
- WITH
- HAVING
- SELECT 从数据库中提取数据
- UNION
- DISTINCT
- ORDER BY 排序
- LIMIT
重要的sql命令:
1、SELECT - 从数据库中提取数据
2、UPDATE - 更新数据库中的数据
3、DELETE - 从数据库中删除数据
4、INSERT INTO - 向数据库中插入新数据
5、CREATE DATABASE - 创建新数据库
6、ALTER DATABASE - 修改数据库
7、CREATE TABLE - 创建新表
8、ALTER TABLE - 变更(改变)数据库表
9、DROP TABLE - 删除表
10、CREATE INDEX - 创建索引(搜索键)
11、DROP INDEX - 删除索引
sql约束:
1、NOT NULL - 指示某列不能存储 NULL 值。
2、UNIQUE - 保证某列的每行必须有唯一的值。
3、PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
4、FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
5、CHECK - 保证列中的值符合指定的条件。
6、DEFAULT - 规定没有给列赋值时的默认值。
总结:
- 一、SQL语句执行顺序:FROM、ON 、JOIN、WHERE、GROUP BY、AGG_FUNC、WITH、HAVING、SELECT、UNION、DISTINCT 、ORDER BY、LIMIT。
在实际执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的数据。
1、FROM:选择FROM后面跟的表,产生虚拟表1。
2、ON:ON是JOIN的连接条件,符合连接条件的行会被记录在虚拟表2中。
3、JOIN:如果指定了LEFT JOIN,那么保留表中未匹配的行就会作为外部行添加到虚拟表2中,产生虚拟表3。如果有多个JOIN链接,会重复执行步骤1~3,直到处理完所有表。
4、WHERE:对虚拟表3进行WHERE条件过滤,符合条件的记录会被插入到虚拟表4中。
5、GROUP BY:根据GROUP BY子句中的列,对虚拟表4中的记录进行分组操作,产生虚拟表5。
6、AGG_FUNC:常用的 Aggregate 函数包涵以下几种:(AVG:返回平均值)、(COUNT:返回行数)、(FIRST:返回第一个记录的值)、(LAST:返回最后一个记录的值)、(MAX: 返回最大值)、(MIN:返回最小值)、(SUM: 返回总和)。
7、WITH 对虚拟表5应用ROLLUP或CUBE选项,生成虚拟表 6。
8、HAVING:对虚拟表6进行HAVING过滤,符合条件的记录会被插入到虚拟表7中。
9、SELECT:SELECT到一步才执行,选择指定的列,插入到虚拟表8中。
10、UNION:UNION连接的两个SELECT查询语句,会重复执行步骤1~9,产生两个虚拟表9,UNION会将这些记录合并到虚拟表10中。
11、DISTINCT 将重复的行从虚拟表10中移除,产生虚拟表 11。DISTINCT用来删除重复行,只保留唯一的。
12、ORDER BY: 将虚拟表11中的记录进行排序,虚拟表12。
13、LIMIT:取出指定行的记录,返回结果集。
- 二、查询数据
(1)基本查询
SELECT * FROM <表名>;
(2)投影查询
SELECT column_name,column_name
FROM table_name;
(3)查询结果返回唯一值
SELECT DISTINCT column_name,column_name
FROM table_name;
(4)条件查询
SELECT * FROM <表名> WHERE <条件表达式>;
(5)排序
SELECT column_name,column_name
FROM table_name
ORDER BY column_name,column_name ASC|DESC;
(6)分页查询
SELECT column_name(s)
FROM table_name
LIMIT number OFFSET 起始值;
(7)聚合查询
1、COUNT()统计一张表的数据量
SELECT COUNT(*) FROM <表名> WHERE <条件表达式>;
2、SUM() 计算某一列的合计值,该列必须为数值类型
SELECT SUM(*) FROM <表名> WHERE <条件表达式>;
3、AVG() 计算某一列的平均值,该列必须为数值类型
SELECT AVG(*) FROM <表名> WHERE <条件表达式>;
4、MAX() 计算某一列的最大值
SELECT MAX(*) FROM <表名> WHERE <条件表达式>;
5、MIN() 计算某一列的最小值
SELECT MIN(*) FROM <表名> WHERE <条件表达式>;
6、GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
7、HAVING 子句可以让我们筛选分组后的各组数据。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
(8)多表查询(笛卡尔查询)
SELECT * FROM <表1> <表2>;
(9)连接查询
SELECT … FROM tableA JOIN tableB ON tableA.column1 = tableB.column2;
(10)合并查询
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
(11)AND & OR 运算符用于基于一个以上的条件对记录进行过滤。
(12)WHERE 子句用于过滤记录。
(13)ORDER BY 关键字用于对结果集进行排序。
(14)LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
(15)通配符可用于替代字符串中的任何其他字符。(%:替代 0 个或多个字符,_:替代一个字符)
(16)IN 操作符允许您在 WHERE 子句中规定多个值。
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1,value2,…);
IN 与 = 的异同
相同点:均在WHERE中使用作为筛选条件之一、均是等于的含义
不同点:IN可以规定多个值,等于规定一个值
(17)BETWEEN 操作符用于选取介于两个值之间的数据范围内的值。
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
(18)别名
列的别名写法:
SELECT column_name AS alias_name
FROM table_name;
表的别名写法:
SELECT column_name(s)
FROM table_name AS alias_name;
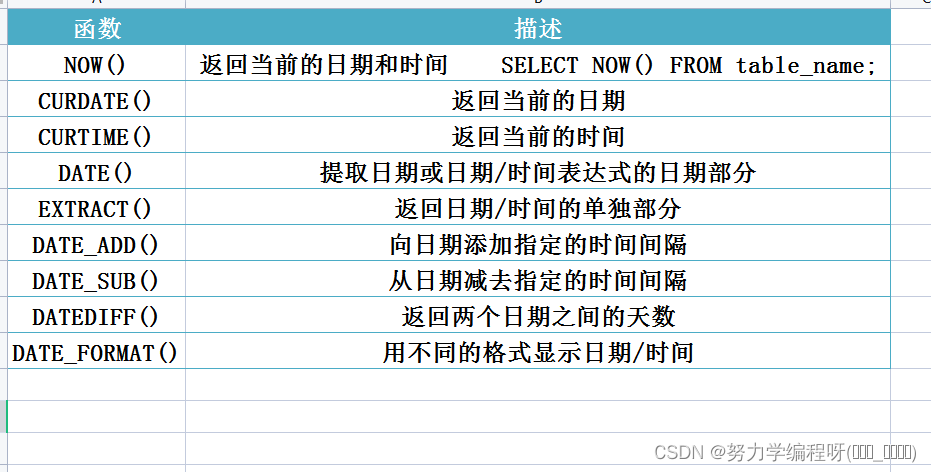
(19)MySQL Date 函数
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
DATE - 格式:YYYY-MM-DD
DATETIME - 格式:YYYY-MM-DD HH:MM:SS
TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
YEAR - 格式:YYYY 或 YY
MySQL 中最重要的日期函数 如下图 表格中所示:
我们了解的 sql 语句的执行顺序后 ,在写 sql 查询语句时 结合 sql 语句的执行顺序 ,就会提高 sql 语句的查询效率。