本文属于基础篇幅,不会涉及过深入的原理,主要还是如何用好 Pinot
背景
单独讲 Table 概念可能有些许单薄,本文会扩展场景,讲解表的部分原理,表与表之间的相互影响,租户是怎么作用到表的,增加字段和修改字段需要注意什么,扩容和调整表的物理磁盘要怎么操作更加合理。
场景
表刚创建的时候,其实问题都不会很大,但是随着业务的增长,数据的增多和需求的变更,会导致很多类型不一致,资源不够的情况。简单描述的话大概如下:
- 表数据量不大,但是在同一个租户中表的数量很多,导致慢
- 表数据很大,又涉及到很多明细数据的计算(其实很多人说自己数据虽然大但是查询又很快,主要原因还是因为他们是从大表里面找小部分数据,你让他们大表里面找大部分数据,该慢还是得慢,因为硬件的上限在这儿,你再怎么优化软件,也就是达到硬件的上限罢了)
- 业务做了变更,导致原表字段不符合业务需求,需要根据业务场景加减字段
其实就是资源争抢和数据过大需要做调整优化。要解决上面两个问题,就得根据问题做具体分析。那么首先需要对 Pinot 的 Tenant、Index 和 Segment 要有一定的了解。上一篇我粗略的讲解了 Segment 是什么,本文就不在继续讲述,接下来就讲解一下 Tenant 和 Index。
Tenant
Tenant 在 Pinot 中就是租户的概念,他是逻辑上面的隔离,来个例子就死就是你设置了两个租户,然后租户是同一台机器,其实他们的资源还是共享的,除非自己通过某种方式把底层资源隔离,他们才不会相互影响。
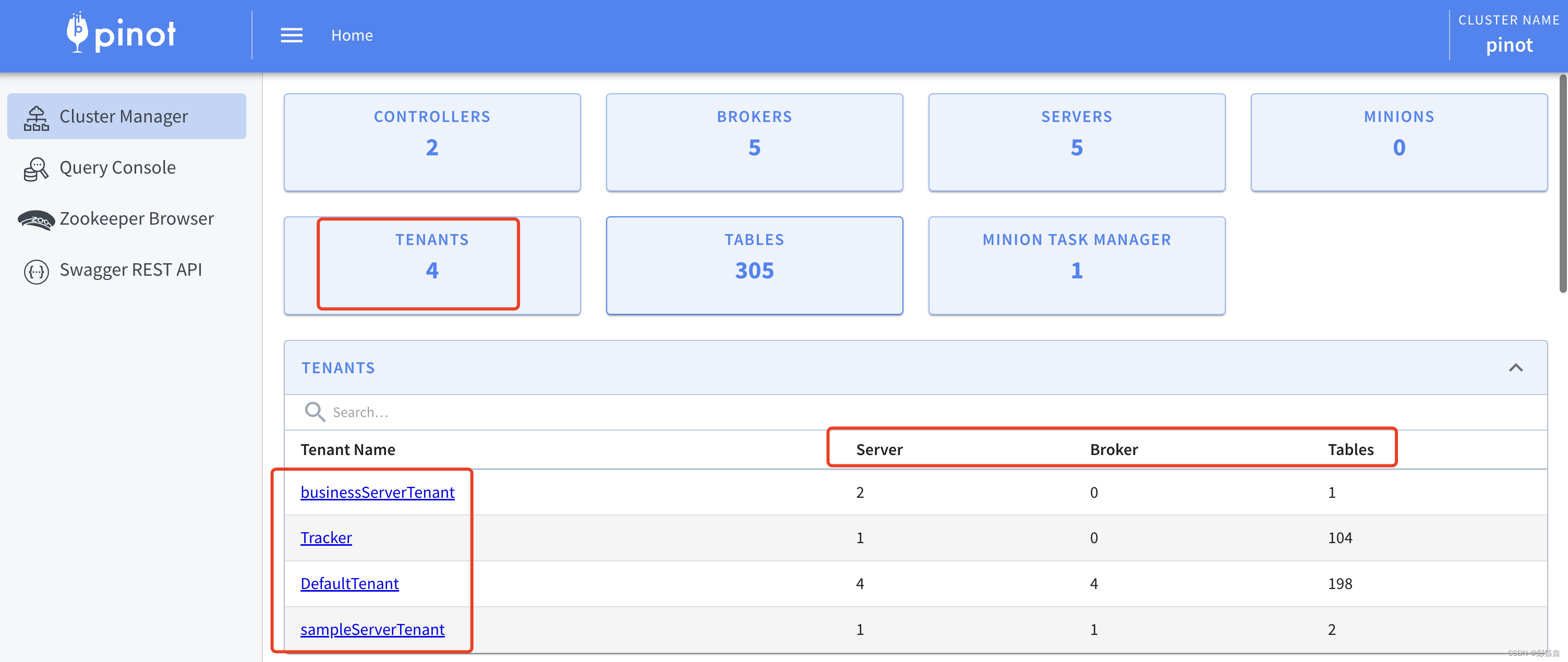
从图中我们可以看出来,这个 Pinot 集群有 4个租户,租户作用于 Server,Broker。 Tables 是因为设置表的时候需要指定 Tenant,创建成功之后 Table 会出现在对应的 Tenant 里面。笔者把核心配置贴在下面
{
"REALTIME": {
"tableName": "",
"tableType": "REALTIME",
"segmentsConfig": {
"timeType": "MILLISECONDS",
"schemaName": "",
"replicasPerPartition": "1",
"timeColumnName": "time",
"minimizeDataMovement": false
},
"tenants": {
"broker": "DefaultTenant",
"server": "businessServerTenant"
},
...
}
需要关注的就是 Tenants,意思就是 Server 属于 businessServerTenant,Broker 属于 DefaultTenant。点开一个 Tenant,你就可以看到这个租户包含哪几台机器了。比较直观,就不啰嗦了。
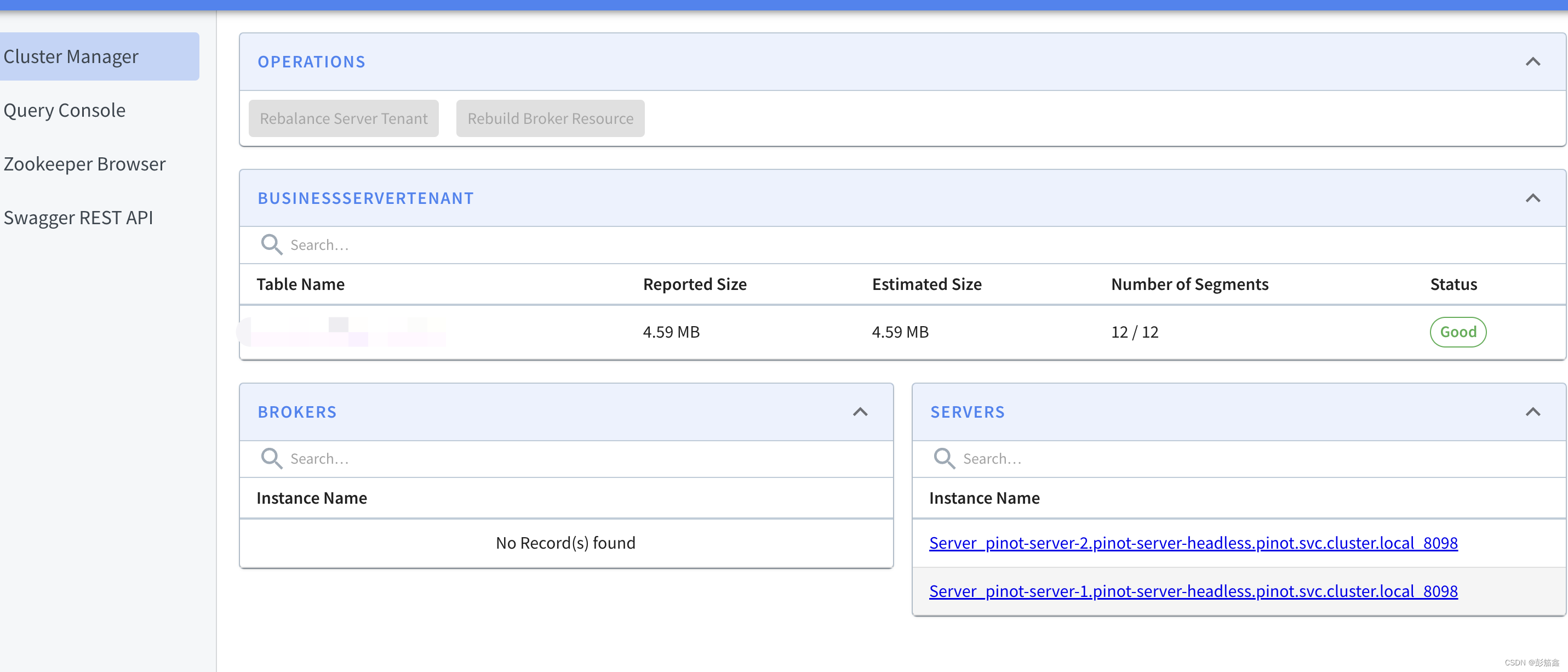
那么其实就是说这个 Table 的 Segment 会被持久化到 Server-1 和 Server-2 这两台机器上。
如何解决问题一的逻辑
从上面的表达大家应该知道我们可以合理的规划资源来解决不同业务的数据查询问题。比较紧急的任务分配资源好的机器并且给这台机器一个比较特殊的 Tenant,核心业务都归属到这个 Tenant 上面。不太重要,但是吃资源的业务就丢到陌生的角落,让他自己细化场景,根据场景做预聚合来解决自己的业务量的问题。从这个点,我们就可以直接了解到 Pinot 的 Tenant 是怎么做到 isolation 的。
注意点
这块我们其实只看到了一个租户,其实上他的租户你在某些特殊情况下会看到 _O 和 _R , 前者代表 OFFLINE,后者代表 REALTIME,也就是说他一个租户是会根据实时离线拆分两个小 Tag。比如下图
省略掉部分参数,这边展示的 Server可以看到说 _R 和 _R 。
segments(queried/processed/matched/consuming/unavailable) inot-server-0_R=1,18,261,0,-1;pinot-server-1_R=3,5,261,0,-1
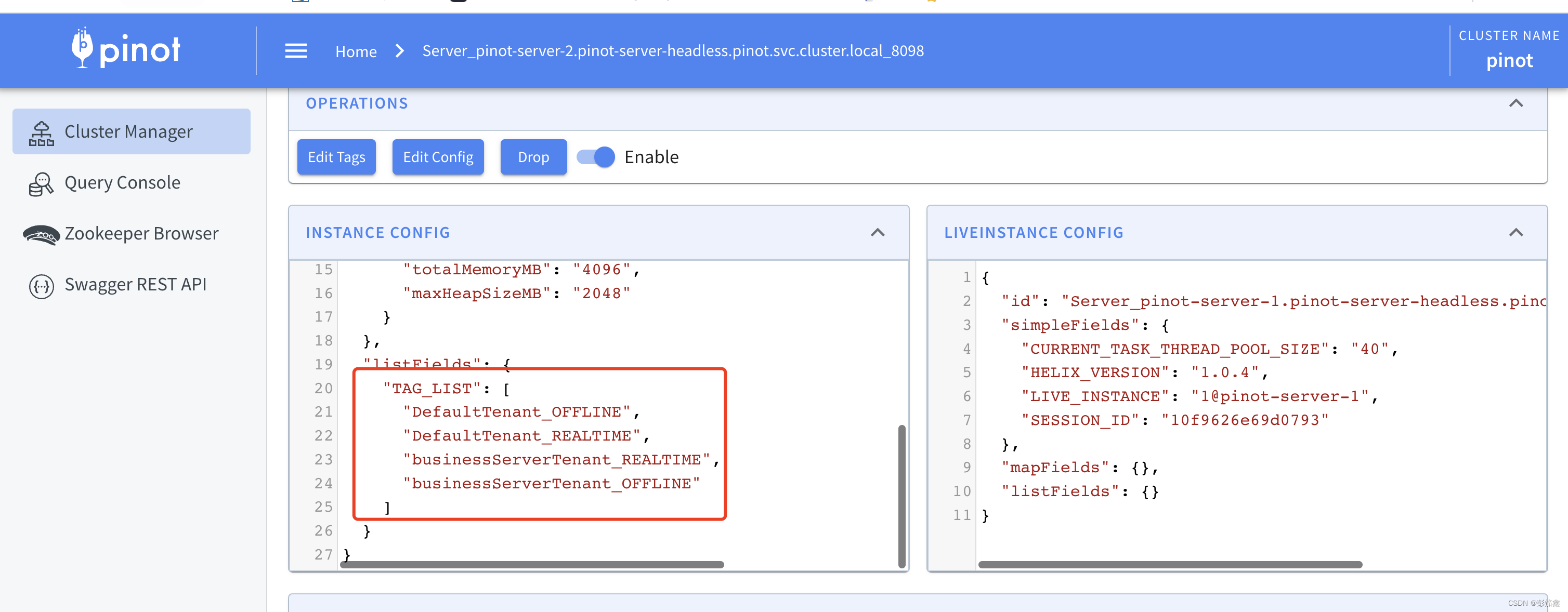
这个图就比较明显,这是点击 Server 之后进去的一些属性数据,能看到这个 Tag List 包含了哪些 Tag。Pinot 这边命名的情况比较多,可能是历史遗留的问题,刚开始看的确会有些蒙蔽,所以特意拿出来讲了一下。
Tenant 迁移
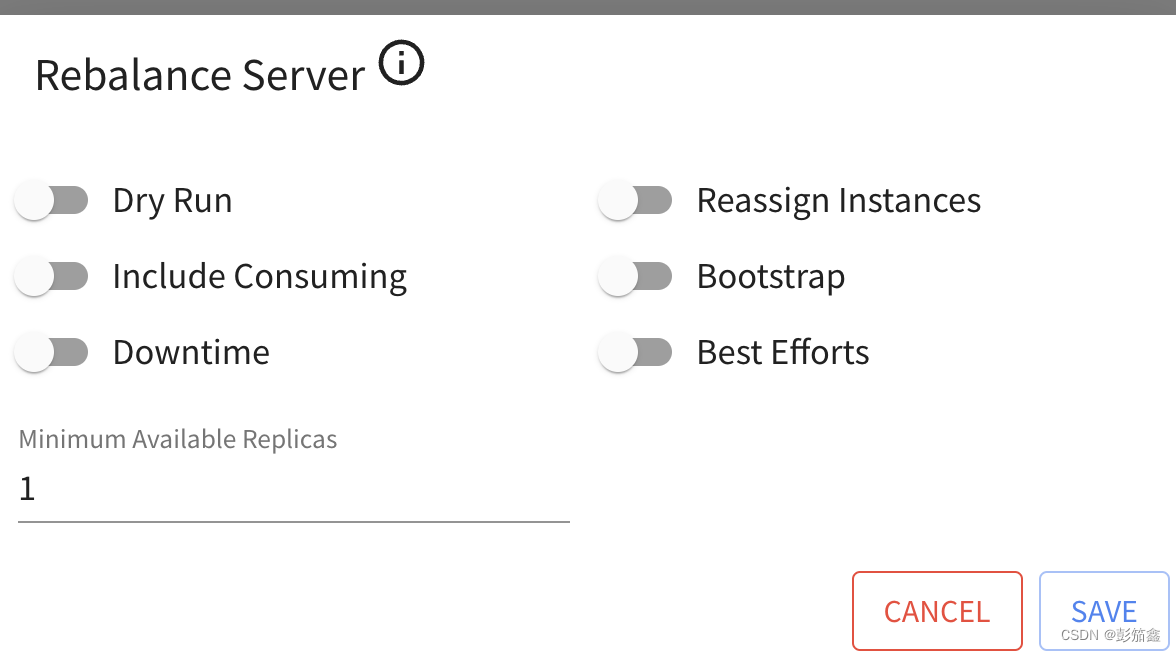
如果需要迁移自己的 Table,其实也不复杂,就是修改自己的租户并且 Rebalance Server,在图里面显示如下。
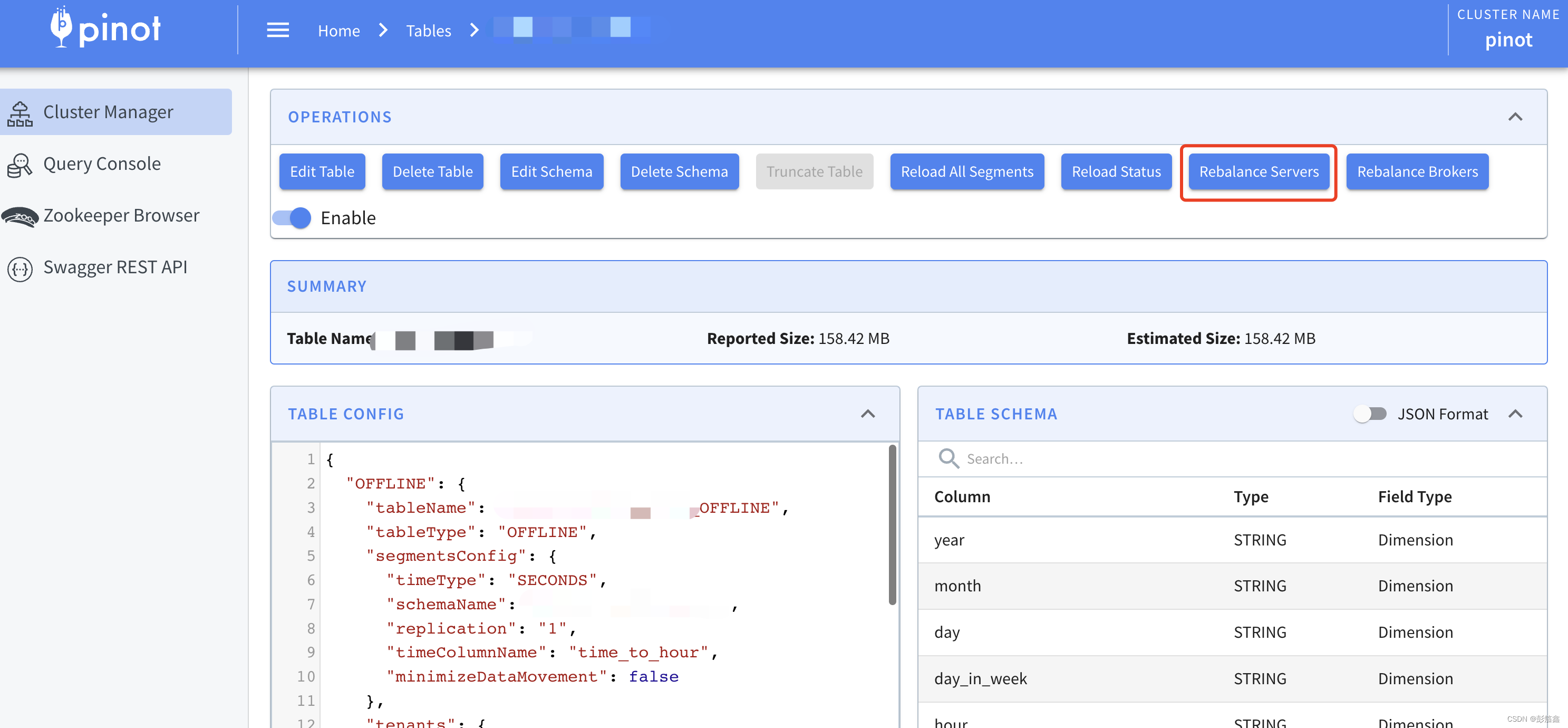
Rebalance 的时候注意一下参数就行,下面就是 Rebalance Server 的参数,Dry Run 就是看一下最后会迁移到哪个 Server 上,但是他没有真正执行,如果要真实执行则不要勾选上他。(后续在讲 Rebalance 之后,原始数据怎么办,是否会影响上层查询)
Index
索引在这里不详细讲了,简单讲就是加速查询的特性。Pinot 包含比较多类型的索引。不同版本支持的索引类型不一样,需要根据自己的版本去找对应的问题。 Pinot 速度最快的是 StarTree 索引,做合适的场景下能发挥非常大的功效,但是占用的磁盘也比较大。是一把双刃剑。后面在开坑详细讲解一下。
Table
表在 Pinot 是一个逻辑抽象的概念,是由行和列组成。他字段的类型定义是在 Schema 中,一个表会在 Helix 当作一个 Resource,他的每个 Segment 作为 Helix 的分区。
REALTIME
从 MQ 中获取数据,并且根据 TableConfig 里面的配置去生成对应的 Segment。基本是根据时间或者量的大小去拆分 Segment。
OFFLINE
从外部存储中摄取并且构建 Segment。离线表做的优化会比实时表更多一些,因为已经持久化的数据可以更好的构建对应的数据信息。
Hybrid
混合表,是实时离线表同时存在的一种状态。Broker 在查询的时候会根据查询的时候去拆分查询,比如查了7天的数据,实时表是最新的一天数据,剩余6天会从离线表里面获取。需要注意的是查几天是实时表跟配置有关系,1 并不是固定的数值,就是我举的例子而已。
配置
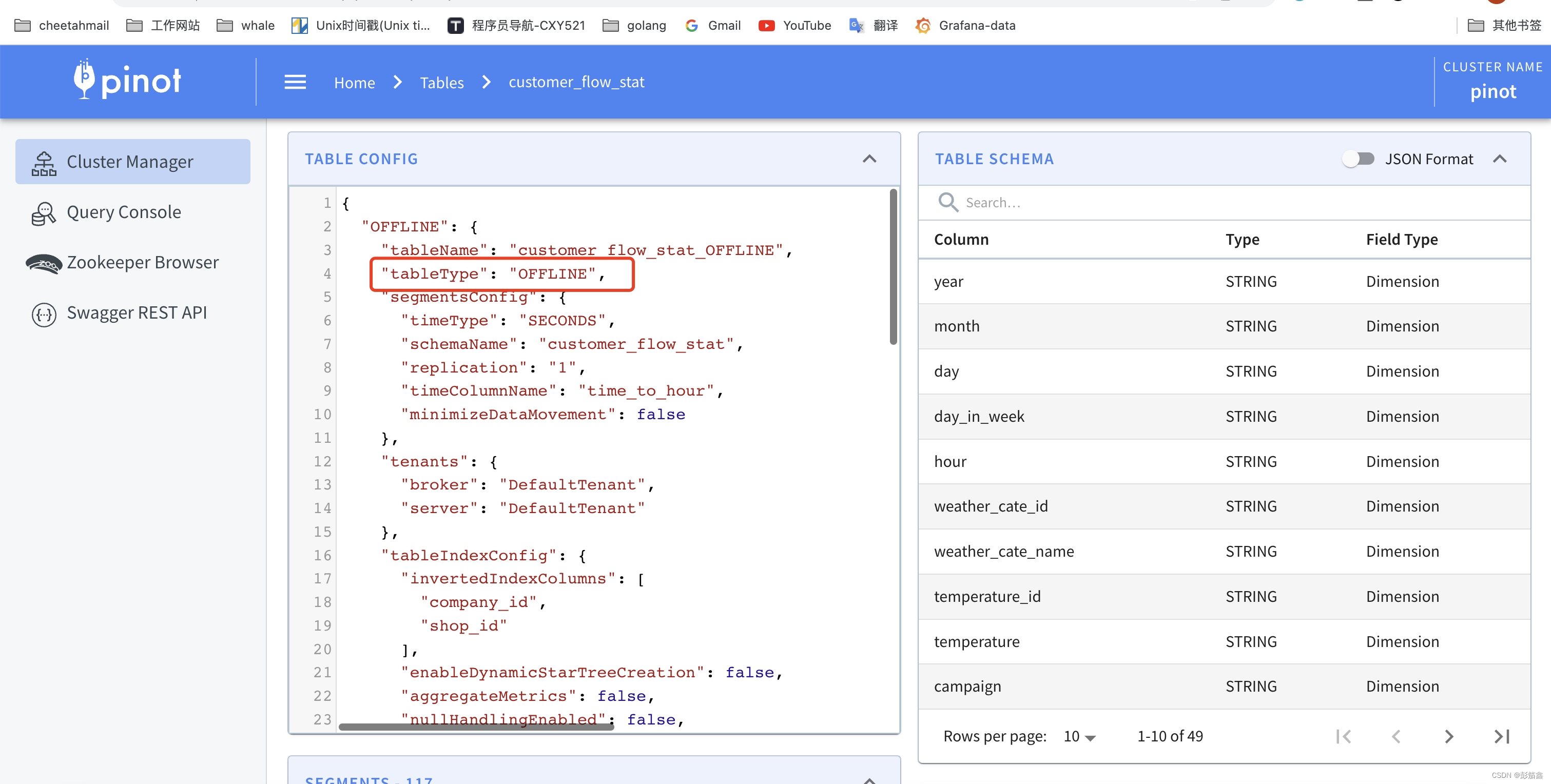
笔者把目前自己使用的表都配置贴了出来,简单讲解几个比较重要的概念。
| 字段 | 含义 |
|---|---|
| tableType | 主要是表的类型 |
| segmentConfig | Table 对应的 Schema 信息,并且找到需要拆分的时间字段 |
| tenants | 租户信息 |
| tableIndexConfig | 表的配置信息,其中包含了索引和读取数据的部分配置 |
| metadata | upsert表相关的配置 |
| isDImTable | 是否维度表 |
从上面的表格中我们大概可以知道一个 Table 里面包含了哪些配置。以及每个字段是做什么的。维度表和 Upsert 表下次在讲,因为他会涉及到查询里面的一些注意点。这次需要讲解一下 SegmentConfig 里面的信息。
SegmentConfig
replication 是副本,缺点就是占用磁盘,优点能让查询提速,并且提供高可用
retention 是清理数据的逻辑,他主要是根据配置会清理部分老的 Segment。
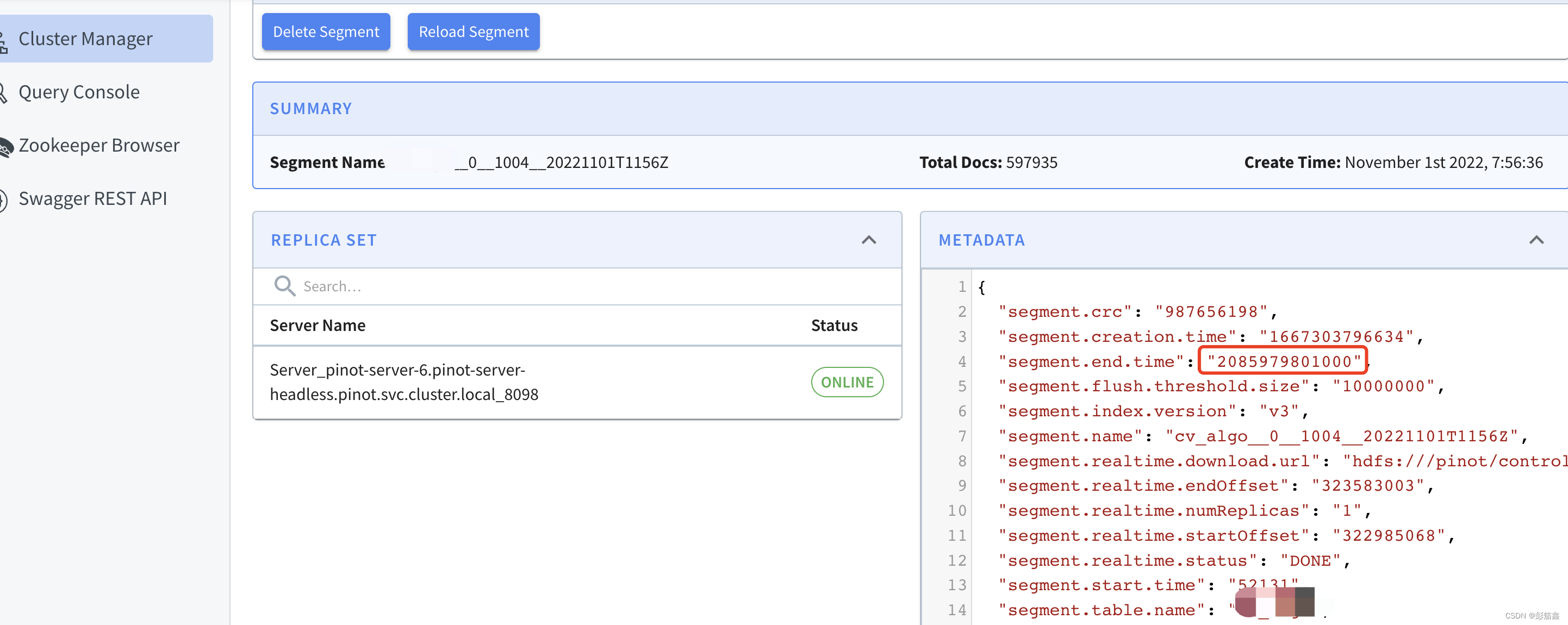
retention 需要注意的是他的回收机制是根据 Segment 的时间来,写入未来的数据可能会导致段不会被清理。我把 Segment 的信息也贴进来给大家看看。

我贴出 Segment 的一些信息,根据我框起来的信息,这个是从数据里面拿的时间值,也就是说 retention 会跟这个数值比较来判断是否需要删除。反例如下。
tableIndexConfig
实时表中主要设置读取数据的配置信息和索引的配置信息,我这块还没做很多尝试,等我做更多实验在开坑写给大家。这块只要根据自己的查询情况,配置好是 rangeIndex 还是 invertIndex 等就行。
表结构调整
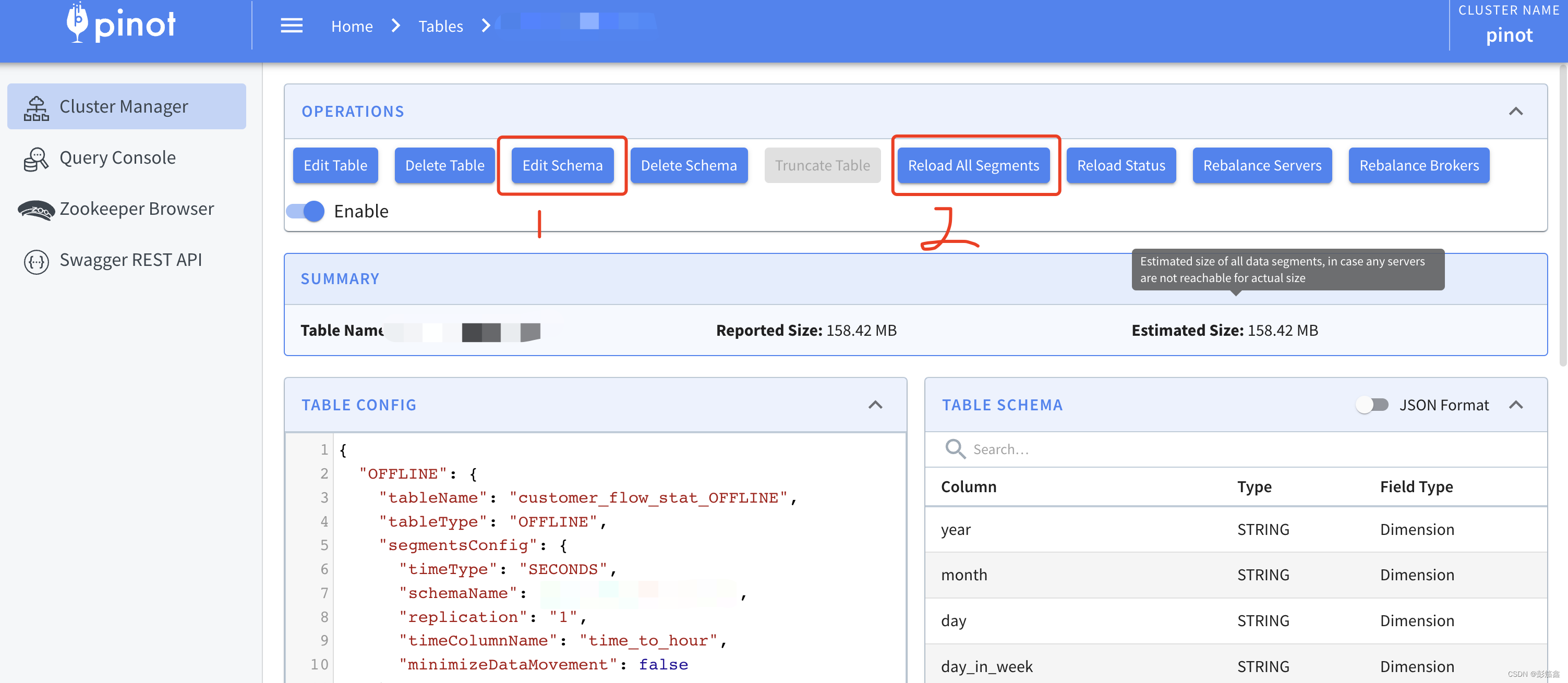
Pinot 里面如果设置好了字段类型就不能被修改,否则会出现奇奇怪怪的异常。你可以新增字段,但是不要修改原有的字段 加粗两次表达重要。操作流程也很简单,一种是在 Table 界面操作,只要执行两部,Edit Schema 然后在 Reload All Segment。执行顺序贴在图里面。
如果真的需要修改字段类型,只能先删除整个Table,然后再做一次重建,这样就可以达到自己想要的效果,去除字段也是一样的逻辑。所以你在做类型变更和减少字段的时候一定要思考好这样做行不行。
总结
不得不说,Pinot 在添加字段,迁移数据的时候体感很好,上层不会有很明显的感知,这块是我用起来比较舒服的点。简单总结一下上面三个问题的解决方法。
- 如果需要减少或者变更字段,那么建议删表重建
- 如果是表数据不多,由于其他业务影响则做资源隔离
- 如果数据很大,则思考场景是做预聚合还是增加索引
另外我不想在一篇文章写的太多,让人感觉到内容太多反而不了解他们是什么,尽量一个文章只讲一块逻辑。