在上一篇文章中:
《python基于轻量级CNN模型开发构建手写藏文数字识别系统》
开发实现了轻量级的藏文手写数字识别系统,这里主要是想基于前文的数据,整合目标检测模型来进一步挖掘藏文手写数字数据集的可玩性,基于yolov5n开发构建轻量级的藏文手写数字检测识别系统,首先来看效果图:

共仿真生成了3000的样本数据集,接下来简单看下:

YOLO格式标注文件如下所示:
实例标注内容如下:

VOC格式标注文件如下所示:
实例标注内容如下所示:
<annotation>
<folder>JiaGuWen</folder>
<filename>JPEGImages/0a48304e-c797-4686-9c2a-09eeb029404d.jpg</filename>
<source>
<database>The JiaGuWen Database</database>
<annotation>JiaGuWen</annotation>
<image>JiaGuWen</image>
</source>
<owner>
<name>CGB</name>
</owner>
<size>
<width>640</width>
<height>640</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>0</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>590</xmin>
<ymin>14</ymin>
<xmax>618</xmax>
<ymax>42</ymax>
</bndbox>
</object>
<object>
<name>7</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>392</xmin>
<ymin>98</ymin>
<xmax>448</xmax>
<ymax>154</ymax>
</bndbox>
</object>
<object>
<name>1</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>145</xmin>
<ymin>134</ymin>
<xmax>187</xmax>
<ymax>176</ymax>
</bndbox>
</object>
<object>
<name>1</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>380</xmin>
<ymin>352</ymin>
<xmax>408</xmax>
<ymax>380</ymax>
</bndbox>
</object>
</annotation>模型文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
训练数据配置文件如下:

默认100次epoch的迭代计算,结果详情如下:
【标签类别数据可视化】
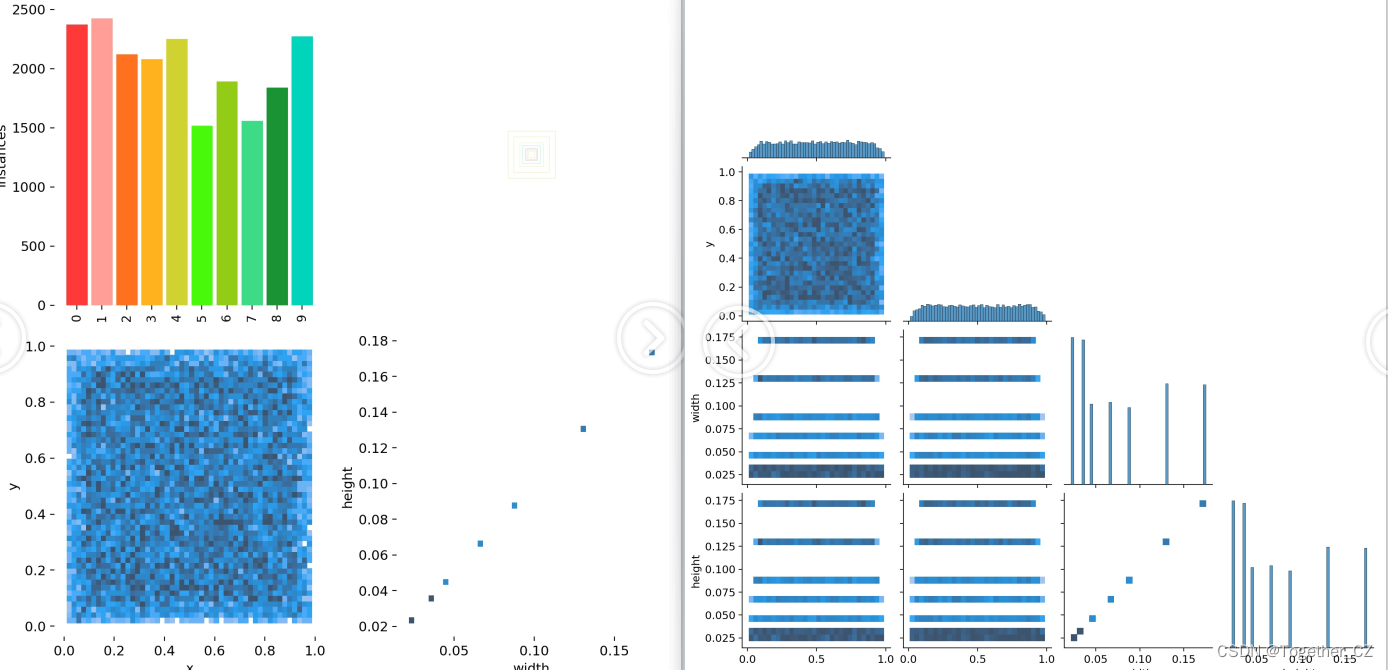
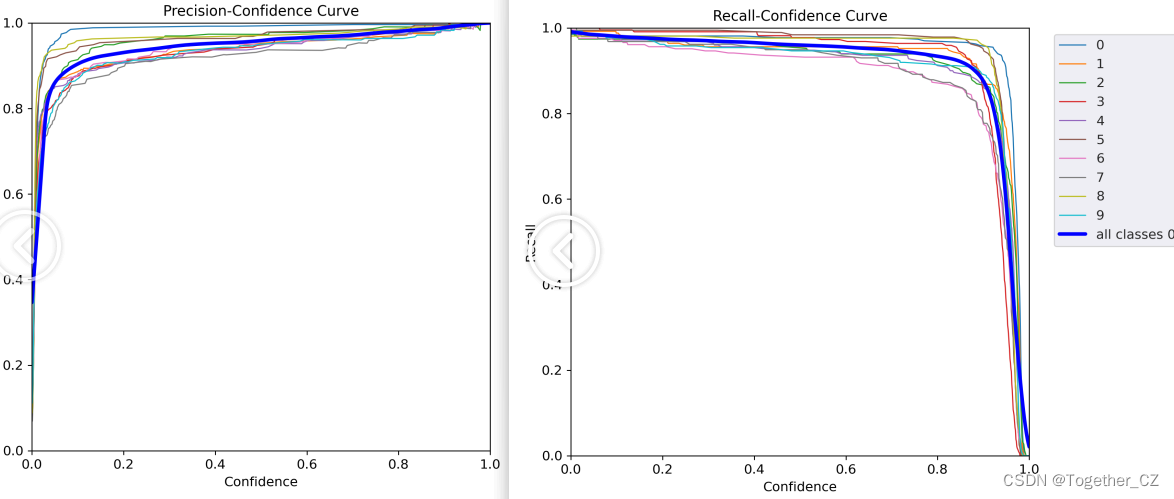
【PR曲线和F1值曲线】
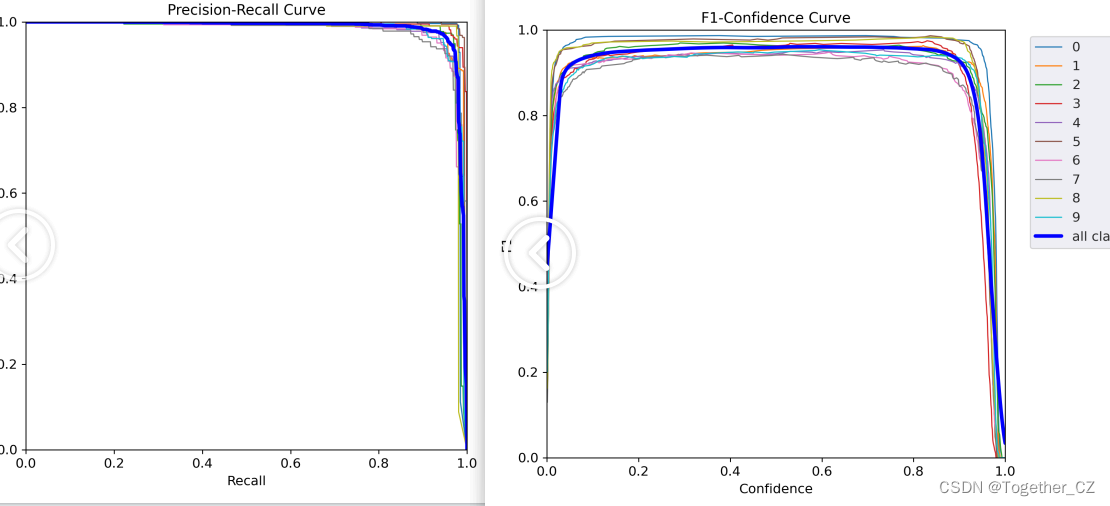
【精确率和召回率曲线】
batch计算实例如下:

从整体评估指标效果上来看:模型虽然很轻量级但是效果还是很不错的了。
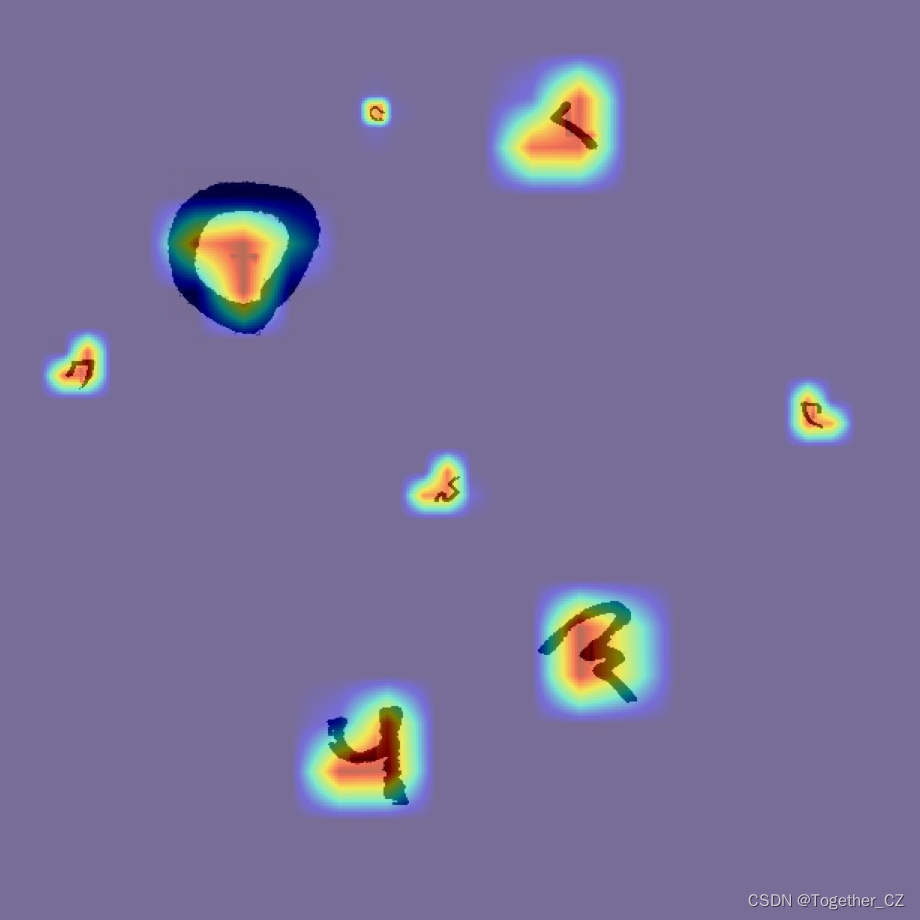
如果想要进一步对模型进行分析,可以加入热力图功能,如下所示:
推理实例如下:
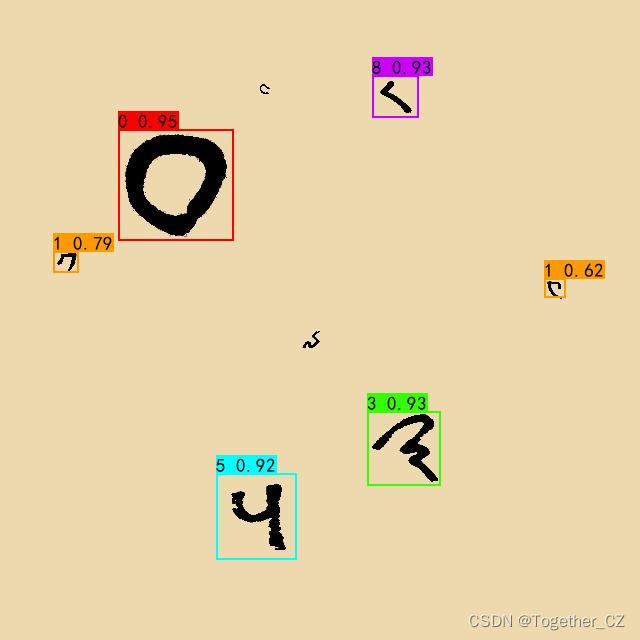
热力图如下: